Amazon Web Services ブログ
クライアントのデジタルマーケティング成果の向上を助けるために Amazon Redshift を使用する Bannerconnect
Bannerconnect は、望ましいタイミングと場所で適切な人に広告を見てもらうことによって、アドバタイザーが注意と顧客を惹きつけることができるようにするプログラム的なマーケティングソリューションを使用しています。データ主導の洞察は、大規模アドバタイザー、トレードデスク、およびエージェンシーがブランド認知を促進し、デジタルマーケティングの成果を最大化するために役立ちます。ログデータの適宜を得た分析は、顧客行動における動的変化に応答し、マーケティングキャンペーンを迅速に最適化して、競争優位性を得るために必要不可欠です。
AWS と Amazon Redshift への移行により、当社クライアントはほぼリアルタイムの分析を簡単に得ることができるようになりました。このブログ記事では、オンプレミスのレガシーデータウェアハウスで直面した課題について説明し、Amazon Redshift への移行によって得たメリットについてお話します。現在 Bannerconnect では、データをよりすばやく取り込み、より高度な分析を行って、クライアントがそのデジタルマーケティングを改善するためにより迅速なデータ主導の判断を行えるよう援助することができます。
レガシーオンプレミス状況と課題
当社のオンプレミスのレガシーインフラストラクチャは、IBM PureData System をログレベルのデータウェアハウスとした構成で、MySQL データベースを使用してメタデータと分析データのすべてを保存しました。この仮想化されていない物理的な環境では、データの増加に対応するために、容量をかなり前から注意深く計画する必要がありました。アップグレード、メンテナンス、およびバックアップの管理と、ワークロードとクエリパフォーマンスの日常的な管理を行うためには、かなりの人数のチームが必要でした。
数多くの課題にも直面しました。ログレベルのデータのデータウェアハウスへのロードに利用できる帯域幅は 1 ギガバイトしかありませんでした。ピークロード時には、ETL (extract/transform/load) サーバーがフル稼働状態になり、帯域幅がボトルネックになって、データが分析用に利用できるようになる時間を遅らせました。データウェアハウスに対するソフトウェアとファームウェアのアップグレードはスケジュールしておかなければならず、メンテナンスのダウンタイムは完了までに 8 時間かかることもありました。このインフラストラクチャは脆弱でもありました。すべての事をひとつの PureData System で実行しており、別個の開発/テスト環境はありませんでした。当社の本番環境に直接アクセスできるクライアントは、不正確な SQL クエリを発行してデータウェアハウス全体をダウンさせる可能性がありました。
私たちはログレベルのデータから集約を作成し、それらを MySQL に保存しました。インデックスはロードプロセスを大幅に減速させました。実行したかった集約のいくつかは、どう見ても実行不可能でした。200 ギガバイトの圧縮されていない行ベースのデータに対するアドホック (一回限りの) クエリは、完了にとても長い時間がかかりました。ダッシュボードクエリの多くは 10~15 分、またはそれ以上かかり、最終的にはキャンセルされました。ユーザーが不満を抱いていたため、私たちが全面的に、応答性が高いソリューションに進化しなければならないことは明白でした。Bannerconnect は、データウェアハウスのために AWS と Amazon Redshift を選びました。
Amazon Redshift への移行
当社のレガシーソフトウェアはクラウドでの実行向けに設計されていなかったため、私たちは利用できるすべての AWS コンポーネントを使用してアプリケーションを再構築することに決定しました。そうすることによって、移行プロセスの煩わしさが省かれ、AWS の可能性を最大限に生かすようにアプリケーションを設計することができました。
当社の新しいインフラストラクチャは、ログレベルのデータのウェアハウスとして Amazon Redshift を使用します。本番プロセスには 40 ノードの ds2.xlarge クラスターを使用しています。ここで、分析クラスターのためにデータを集約するログレベルのクエリを実行し、毎日何千ものクエリを行って当社のマーケティングキャンペーンを最適化します。
クライアントのアクセスには、別途 30 ノードの ds2.xlarge Amazon Redshift クラスターをセットアップしました。ログレベルのデータをこのクラスターにレプリケートして、クライアントがここで当社の本番プロセスを危険にさらすことなくクエリを実行できるようにしています。当社のクライアントは、このクラスター内のデータに対してデータサイエンスクエリを実行します。
また、高機能クエリ用に 24 ノードの dc2.large クラスターも作成し、このクラスターは他のクラスターで実行されている大規模で複雑なクエリに影響されません。このクラスターは、当社の API 経由で利用可能になる、集約されたデータでのアドホック分析用に使用します。
メインデータストアには、無限のストレージを提供してくれる Amazon S3 を使用しています。ETL プロセス、API、およびいくつかのその他アプリケーションをホストするのは Amazon EC2 です。
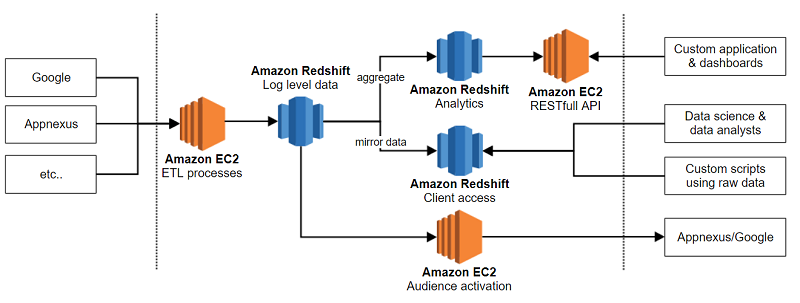
Bannerconnect のアーキテクチャ。シンプル化のため、フローチャートには Amazon S3 が追加されていませんが、S3 はチャートにあるほとんどすべての矢印上に追加できます。
獲得した最大の利益
AWS および Amazon Redshift での次世代ソリューションの作成は、私たちに多くのメリットをもたらします。当社では、Amazon Redshift ドキュメントに記載されているベストプラクティスのみに従っています。
- マネージドサービス: 私たちは、インフラストラクチャの管理とメンテナンスではなく、私たちが得意とするソフトウェアの開発に焦点を当てたいと考えていました。Amazon Redshift を使用することにより、ソフトウェアの更新やファームウェアのアップグレードを行ったり、故障したハードウェアに対処したりする必要がなくなりました。何か月も前から容量を計画したり、環境への新規サーバーの統合に対応したりする必要もありません。Amazon Redshift は、データの増加に合わせたスケーリングを含め、これらすべてを完全に自動化してくれるため、クライアントにより良いサービスを提供するためのデータと分析に集中することができます。
- 分離された完全な開発/テスト環境: 現在、当社には分離された Amazon Redshift クラスター (シングルノード) があり、このクラスターで、本番環境を壊すことを心配せずに実行、開発、およびテストを行うことができます。当社のオンプレミス設定にも開発データベースがありましたが、それは常に本番インフラストラクチャ上にありました。さらに、テスト環境には全インフラストラクチャそのままのコピーがあります (もちろんすべてが小規模で Small タイプのインスタンスです)。これは、デプロイメントごとに自動化されたテストを実行して、すべてのデータフローが期待通りに機能することを検証できるようにしてくれます。
- 無限大の拡張性: 必要な容量にすぐさまスケールすることができます。Amazon S3 は無限のストレージを提供し、Amazon Redshift のコンピューティング性能は、ほんの数クリックでスケールすることができます。
- 分離されたクラスター: クライアントが当社の本番プロセスを危険にさらす可能性はなくなりました。クライアントは今でも不正確な SQL クエリを書き込みますが、Amazon Redshift でクエリモニタリングルールを使用することにより、これらのクエリを特定し、Amazon Redshift を使ってこれらを自動的に停止することができます。不正クエリは一瞬の間クライアントクラスターに影響を及ぼすかもしれませんが、本番プロセスにはまったく影響しません。
- より迅速なアドホック分析: Amazon Redshift の超並列処理、データ圧縮、および列ベースのストレージ機能により、MySQL では不可能だった集約を作成することができます。パフォーマンスに関しては、比較に適切な数字を出すことは困難です。小規模な集約に対するクエリの実行では、MySQL でのインデックスの使用のほうが早い場合もあります。しかし、当社のクエリの大部分は、Amazon Redshift での実行するほうが大幅に早くなります。例えば、当社で最も大規模な集約テーブルには約 200 億のレコードと 500 GB のデータ (圧縮済み) が含まれています。MySQL はこれに対応できませんでしたが、Amazon Redshift の結果は数秒以内で取得されます。MySQL での大規模で複雑なクエリには長い時間がかかりましたが、Amazon Redshift はこれらを数十秒、またはそれ以下で完了します。
マルチクラスター環境の構築
このセクションでは、AWS CloudFormation テンプレートを使ってマルチクラスター設定を構築する簡単なオプションについて説明します。このテンプレートを使用することにより、VPC 内で、異なるアベイラビリティーゾーンにあるプライベートサブネットとパブリックサブネット両方に複数の Amazon Redshift クラスターを起動できます。プライベートサブネットは、Amazon Redshift クラスターとやり取りするための ETL プロセスを実行してデータを更新する内部アプリケーション (EC2 インスタンスなど) を有効化します。外部のクライアントツールとスクリプトには、Amazon Redshift のパブリッククラスターを使用できます。この設定のアーキテクチャは以下のとおりです。

では、構成を詳しく見ていきましょう。デモ用に、ここではプライベートサブネットとパブリックサブネット内にある 2 つの Amazon Redshift クラスターのみを使用していますが、これらのステップを変更して、さらに多くの並列クラスターを追加できます。この構成は、最初にネットワークスタックを作成し、その後これらのスタック内で Amazon Redshift クラスターを起動する 2 ステッププロセスです。このプロセスは以下を作成します。
- VPC と関連するサブネット、セキュリティグループ、およびルート
- S3 から Amazon Redshift にデータをロードする IAM ロール
- Amazon Redshift クラスター (ひとつ、または複数)
手順
ステップ 1 – ネットワークスタックの作成
- AWS マネジメントコンソールにサインインして CloudFormation に移動し、以下を実行します。
- スタックを起動させる AWS リージョン (米国東部 (オハイオ) など) を選択します。
- [スタックの作成] を選択します。
- [Amazon S3 テンプレート URL の指定] を選択します。
- テキストボックスにこの URL をコピー & ペーストします: https://s3.amazonaws.com/salamander-us-east-1/Bannerconnect/networkstack.json
- [次へ] を選択して以下の情報を入力します。
- スタックの名前:使いやすい任意の名前でスタックに名前を付けます。
- CIDR Prefix:クラス B CIDR プレフィックス (例: 168、10.1、または 172.16) を入力します。
- Environment Tag:リソースにタグ付けするため、使いやすい任意の名前で環境に名前を付けます。
- Key Name:EC2 インスタンスへのアクセスを許可する EC2 キーペアです。まだキーペアがない場合は、EC2 ドキュメントの「Amazon EC2 のキーペア」を参照してください。
- その他すべてのパラメータにはデフォルト値を使用して、[作成] をクリックします。
- スタックの起動には 10 分かかり、その後ネットワークスタックの準備が整います。
- 起動が完了したらスタックの出力を確認し、作成されたリソースの名前をメモします。
ステップ 2 – Amazon Redshift クラスターの作成
- CloudFormation のコンソールに戻って、以下を実行します。
- [スタックの作成] を選択します。
- [Amazon S3 テンプレート URL の指定] を選択します。
- テキストボックスにこの URL をコピー & ペーストします: https://s3.amazonaws.com/salamander-us-east-1/Bannerconnect/reshiftstack.json
- [次へ] を選択して以下の情報を入力します。
- スタックの名前:使いやすい任意の名前でスタックに名前を付けます。
- Cluster Type:マルチノードまたはシングルノードのクラスターを選択します。
- Inbound Traffic:この CIDR 範囲からのクラスターへのインバウンドトラフィックを許可します。
- Master Username:作成中のクラスターのマスターユーザーアカウントに関連付けられているユーザー名です。デフォルトは adminuser です。
- Master User Password:作成中のクラスターのマスターユーザーアカウントに関連付けられているパスワードです。
- Network Stack Name:ステップ 1 で作成したアクティブな CloudFormation スタックの名前で、これにはサブネットおよびセキュリティグループなどのネットワーキングリソースが含まれています。
- Node Type:Amazon Redshift クラスター用にプロビジョニングされるノードのタイプです。
- Number Of Nodes:Amazon Redshift クラスター内のコンピューティングノードの数です。
- クラスタータイプがシングルノードとして指定されている場合、この値は 1 になります。
- クラスタータイプがマルチノードとして指定されている場合、この値は 1 を超える値になります。
- Port Number:クラスターが受信接続を受け入れるポートの番号です。デフォルトは 5439 です。
- Public Access:Amazon Redshift クラスターへのパブリックアクセスで、true または false になります。この値が true の場合、クラスターはパブリックサブネットで起動されます。この値が false の場合、クラスターはプライベートサブネットで起動されます。
- その他すべてのパラメータにはデフォルト値を使用して、[作成] をクリックします。
- クラスターの起動には 10 分かかり、その後 Amazon Redshift クラスターがネットワークスタック内に起動されます。
- 起動が完了したらスタックの出力を確認し、Amazon Redshift クラスター用に作成されたリソースの名前をメモします。
- このネットワークスタックにさらに多くの Amazon Redshift クラスターを追加するには、ステップ 5~8 を繰り返します。
AWS CloudFormation テンプレートを使ったこの簡単なデプロイメントで、マルチクラスター設定に必要なリソースのすべてを数回クリックするだけで起動できます。
まとめ
Amazon Redshift への移行と、AWS でのデータウェアハウスのセットアップは、私たちが拡張性の高い切り離されたアプリケーションを構築し、異なるユースケースのために異なるクラスターを使用することを可能にしました。運用面では、複雑なデータワークフローを実装するための管理が簡単な、堅牢な開発システム、テストシステム、および本番システムを単独で構築することができました。
当社では最近、Amazon Redshift Spectrum を使って、Amazon Redshift にデータをロードする必要なく Amazon S3 からのデータを直接クエリし始めました。これは、ロード時間を節約し、分析時間を短縮するため、たくさんの新たな可能性が生み出されました。Amazon Redshift Spectrum を使用することによって、異なるフォーマットと列を持つ動的データのロードがはるかに容易になります。
著者について
 Bannerconnect で 10 年間勤務してきた Danny Stommen 氏は、現在ソリューションアーキテクトの役割を担っており、ほとんどの時間を CORE ソリューションに費やしています。仕事以外では、家族と充実した時間を過ごし、サッカーを活発に楽しんでいます。
Bannerconnect で 10 年間勤務してきた Danny Stommen 氏は、現在ソリューションアーキテクトの役割を担っており、ほとんどの時間を CORE ソリューションに費やしています。仕事以外では、家族と充実した時間を過ごし、サッカーを活発に楽しんでいます。
 Thiyagarajan Arumugam はアマゾン ウェブ サービスのビッグデータソリューションアーキテクトで、大規模なデータを処理するためのカスタマーアーキテクチャを設計しています。AWS に参加する前は、Amazon.com でデータウェアハウスソリューションを構築していました。余暇には、野外スポーツを楽しみ、インドの伝統的な太鼓であるムリダンガムを練習しています。
Thiyagarajan Arumugam はアマゾン ウェブ サービスのビッグデータソリューションアーキテクトで、大規模なデータを処理するためのカスタマーアーキテクチャを設計しています。AWS に参加する前は、Amazon.com でデータウェアハウスソリューションを構築していました。余暇には、野外スポーツを楽しみ、インドの伝統的な太鼓であるムリダンガムを練習しています。