Amazon Web Services ブログ
AWS Lake Formation – 一般公開へ
企業がデジタル形式のデータを持つようになるとすぐに、データウェアハウスを構築し、顧客関係管理 (CRM) やエンタープライズリソースプランニング (ERP) システムなどの運用システムからデータを収集し、この情報を使用してビジネス上の意思決定をサポートできるようになりました。
ストレージコストの削減と、Amazon S3 などのサービスによって大量のデータ管理の複雑さを大幅に削減することが可能になり、企業は、ログ、画像、ビデオやスキャンされたドキュメントといった構造化されていない生データなど、より多くの情報を保持できるようになりました。
これは、すべてのデータを 1 つの集中リポジトリに任意の規模で保存するという、データレイクの考え方です。このアプローチの採用は、Netflix、Zillow、NASDAQ、Yelp、iRobot、FINRA、Lyft などのお客様に見られます。単純な集計から複雑な機械学習アルゴリズムまで、このより大きなデータセットで分析を実行することで、データのパターンをより適切に発見し、ビジネスをよりよく理解できます。
昨年の re:Invent で AWS Lake Formation のプレビューを紹介しました。これは、データの取り込み、クリーニング、カタログ化、変換、セキュリティ保護を容易にし、分析や機械学習で利用できるようにするサービスです。 今日、Lake Information が一般公開されたことをお伝えできることをうれしく思います。
Lake Formation には、データベースやログなどの複数のソースからデータレイクにデータを移動するジョブを設定するなど、データレイクを管理するための中央コンソールがあります。このように大量の多様なデータがあると、適切なアクセス許可を設定することも非常に重要になってきます。 Lake Formation で定義された詳細なデータアクセスポリシーの単一セットを使用して、Glue Data Catalog のメタデータおよび S3 に保存されたデータへのアクセスを保護できます。これらのポリシーを使用すると、テーブルおよびカラムナレベルのデータアクセスを定義できます。
Lake Formation で最も気に入っている点の 1 つは、すでに S3 にあるデータで動作するところです! Lake Formation に既存のデータを簡単に登録でき、データを S3 にロードする既存のプロセスを変更する必要はありません。データはアカウントに残っているため、完全に制御できます。
Glue ML Transforms を使用して、データを簡単に重複排除することもできます。重複排除は、必要なストレージの量を減らすために重要ですが、オーバーヘッドも同じデータを 2 回見るという混乱もないため、データの分析をより効率的に行うためにも重要です。重複レコードが一意のキーで識別できる場合、この問題はささいですが、「あいまい一致」を行う必要がある場合は非常にやっかいになります。 レコードの連結にも同様のアプローチを使用できます。たとえば、一意のキーを共有しない 2 つのデータベースの「ファジー結合」を行うなど、異なるテーブルで類似のアイテムを探している場合です。
このように、ゼロからデータレイクを実装する方がはるかに高速で、データレイクを管理する方がはるかに簡単で、これらのテクノロジーをより多くのお客様が利用できます。
データレイクの作成
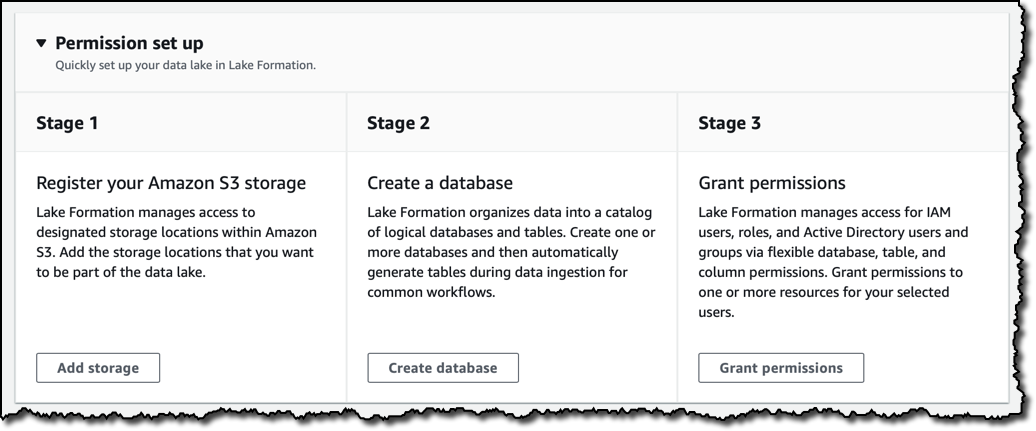
Lake Formation コンソールを使用してデータレイクを構築してみましょう。 まず、データレイクの一部となる S3 バケットを登録します。次に、データベースを作成し、データレイクを管理するために使用する IAM ユーザーとロールにアクセスを許可します。データベースは Glue Data Catalog に登録され、データの取り込み中に自動的に生成されるテーブルの構造などの生データの分析に必要なメタデータを保持します。
アクセス許可の管理は、データレイクの最も複雑なタスクの 1 つです。たとえば、データレイクの一部になり得る膨大な量のデータ、一部のデータの機密性が高くミッションクリティカルな性質、それにデータが存在できるさまざまな構造化、半構造化、非構造化形式を考えてみてください。Lake Formation は、1 か所から IAM ユーザー、ロール、グループ、および Active Directory ユーザーに (フェデレーション経由で) データベース、テーブルへのアクセスを許可し、オプションでテーブル内の特定の列へのアクセスを許可または拒否できるようにしてアクセス許可の管理を容易にします。
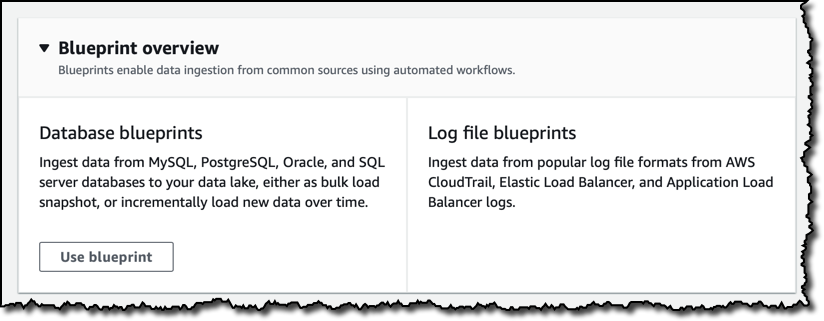
データの取り込みを簡素化するために、AWS Glue で一般的なユースケースに必要なワークフロー、クローラー、およびジョブを作成するブループリントを使用できます。 ワークフローは、トリガー、クローラー、ジョブなどの Glue エンティティ間の依存関係を構築することにより、データ読み込みワークロードのオーケストレーションを可能にし、コンソール上のワークフローのさまざまなノードのステータスを視覚的に追跡できるため、進行状況の監視と問題のトラブルシューティングが容易になります。
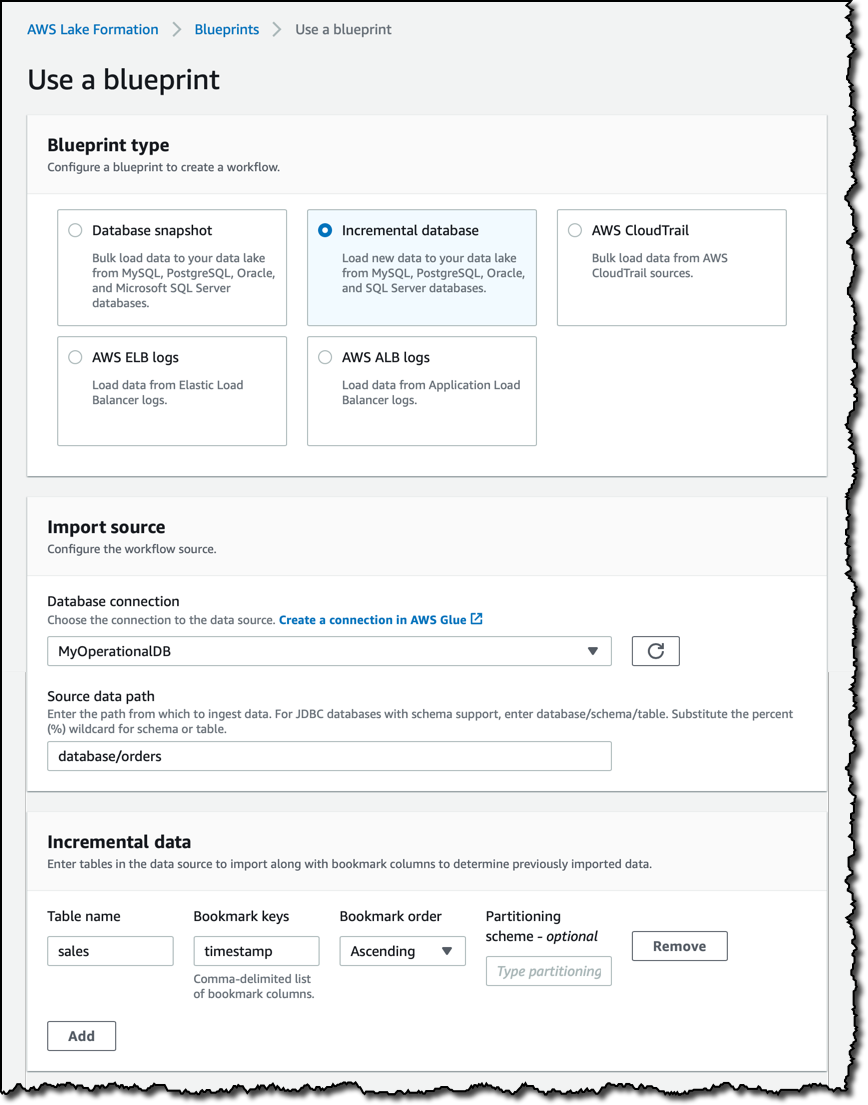
データベースブループリントは、運用データベースからデータをロードするのに役立ちます。たとえば、e コマースウェブサイトがある場合、すべての注文をデータレイクに取り込むことができます。既存のデータベースから完全なスナップショットをロードするか、新しいデータを段階的にロードできます。段階的なロードの場合、テーブルとその 1 つ以上の列をブックマークキー (たとえば、注文のタイムスタンプ) として選択して、以前にインポートしたデータを決定できます。
ログファイルブループリントは、Application Load Balancers、Elastic Load Balancers、および AWS CloudTrail で使用するロギング形式の取り込みを簡素化します。それがどのようにより機能するかを詳しく見てみましょう。
セキュリティは常に最優先事項であり、アカウント全体のすべての管理操作のフォレンジックログを取得できるようにするため、CloudTrail ブループリントを選択します。ソースとして、すべてのリージョンから CloudTrail ログを S3 バケットに収集するトレイルを選択します。このようにして、AWS インフラストラクチャ全体のアカウントアクティビティをクエリできるようになります。 これは、複数の AWS アカウントを持っている大規模な組織でも同様に機能します。CloudTrial コンソールでトレイルを設定するときに、そのトレイルを組織全体に適用するだけです。
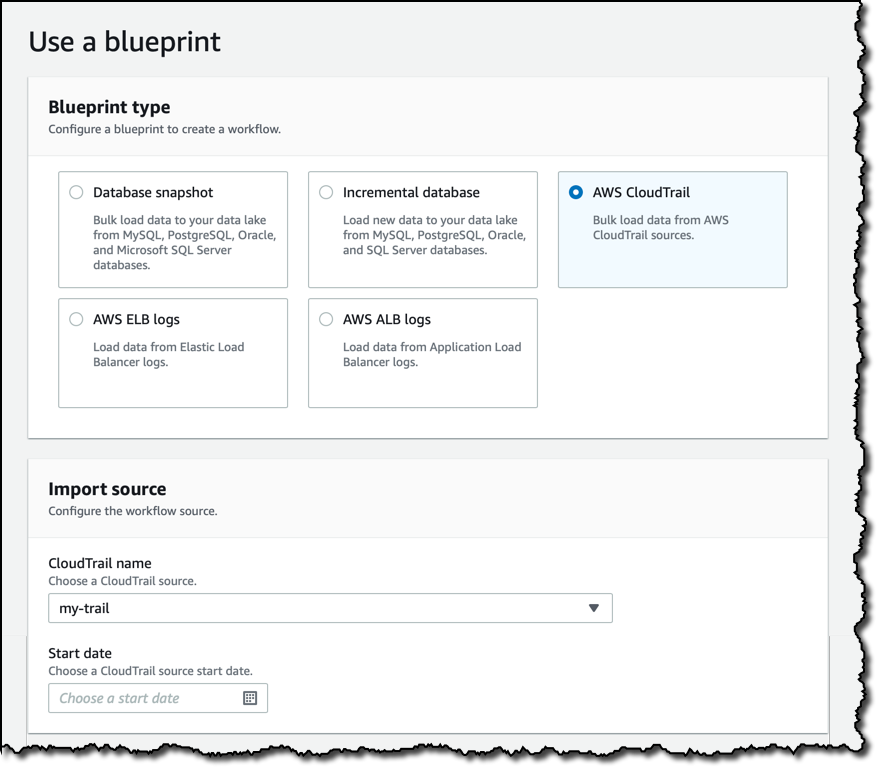
次に、ターゲットデータベースを選択し、データレイクの S3 の場所を選択します。データ形式として、Parquet を使用します。これは、データのクエリをより高速で安価にするカラムナのストレージ形式です。 インポートの頻度は 1 時間ごとから 1 か月ごとで、曜日と時刻を選択するオプションがあります。ここでは、オンデマンドでワークフローを実行します。たとえば AWS SDK や AWS Command Line Interface (CLI) を使用して、コンソールから、またはプログラムでそれを行うことができます。
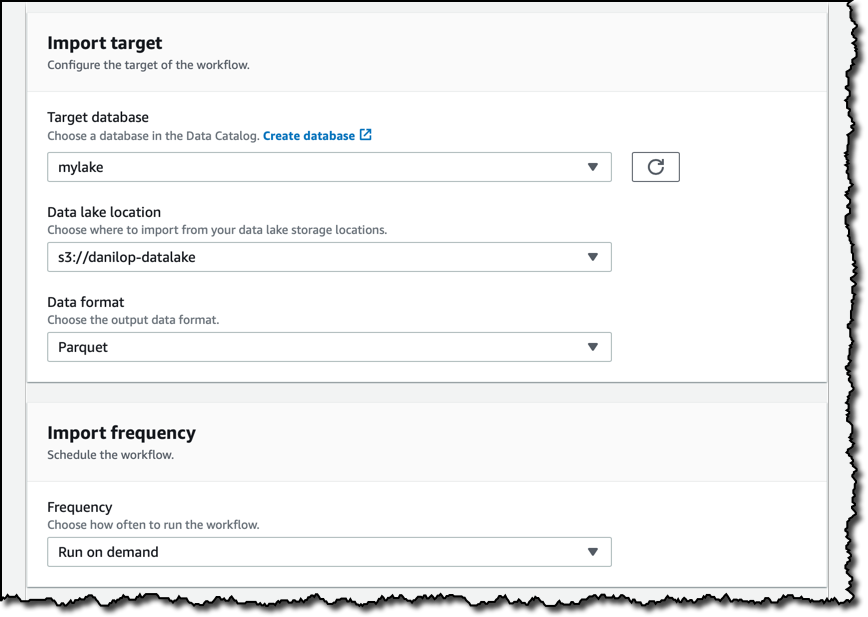
最後に、ワークフローに名前、実行中に使用する IAM ロール、およびこのワークフローによって自動的に作成されるテーブルのプレフィックスを付けます。
Lake Formation コンソールからワークフローを開始し、ワークフローグラフの表示を選択します。これにより AWS Glue コンソールが開き、ワークフローのステップを視覚的に確認し、この実行の進行状況を監視できます。

ワークフローが完了すると、データレイクデータベースで新しいテーブルが使用可能になります。ソースデータは CloudTrail の S3 バケット出力にログとして残りますが、現在はデータレイクの S3 の場所で統合し、Parquet 形式で日付ごとにパーティション分割されています。コストを最適化するために、安全な時間が経過するとソース S3 バケット内のデータを自動的に期限切れにする S3 ライフサイクルポリシーを設定できます。
データレイクへのアクセスの保護
Lake Formation は、IAM ポリシーを強化する新しい許可および許可の取り消しモデルを介して、データレイク内のデータストアへの安全かつきめ細かいアクセスを提供します。コンソールを使用するなどして、これらのアクセス許可を簡単に設定できます。

アクセスを許可する IAM ユーザーまたはロールを選択するだけです。次に、データベースを選択し、オプションでアクセスを提供するテーブルと列を選択します。提供するアクセスの種類を選択することもできます。このデモでは、単純な選択権限で十分です。
データレイクへのアクセス
これで、Amazon Athena や Amazon Redshift などのツールを使用してデータをクエリできるようになりました。たとえば、Athena コンソールでクエリエディターを開きます。まず、新しいデータレイクを使用して、AWS アカウントアクティビティで最も一般的なソース IP アドレスを調べます。
SELECT sourceipaddress, count(*)
FROM my_trail_cloudtrail
GROUP BY sourceipaddress
ORDER BY 2 DESC;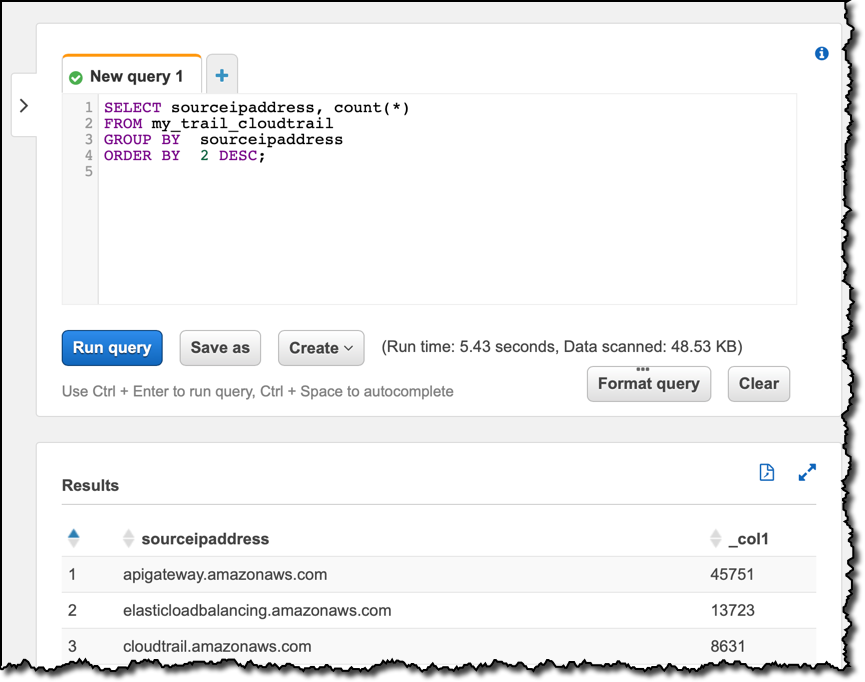
クエリの結果を見ると、最も使用している AWS API エンドポイントを確認できます。次に、どのユーザー ID タイプが使用されているかを確認します。この情報は、いずれかの列内に JSON 形式で保存されています。Amazon Athena で利用可能な JSON 関数のいくつかを使用して、SQL ステートメントでその情報を取得します。
SELECT json_extract_scalar(useridentity, '$.type'), count(*)
FROM "mylake"."my_trail_cloudtrail"
GROUP BY json_extract_scalar(useridentity, '$.type')
ORDER BY 2 DESC;
ほとんどの場合、AWS のサービスはトレイルでアクティビティを作成しているサービスです。これらのクエリは一例にすぎませんが、AWS アカウントで何が起こっているかをすばやくより深く理解することができます。
お客様のビジネスに同じ様なインパクトを残せるものは何かを考えてみてください! データベースとログのブループリントを使用して、組織内の複数のソースからデータを取り込むワークフローをすばやく作成し、収集された情報にアクセスできる適切な権限をカラムナレベルで設定し、機械学習トランスフォームを使用してデータをクリーンアップおよび準備し、Amazon Athena、Amazon Redshift、Amazon QuickSight などのツールを使用して情報を関連付けて視覚化することができます。
カラムナレベルのアクセス許可でデータアクセスをカスタマイズする
データプライバシーガイドラインの遵守とコンプライアンスのために、データレイクに格納されているミッションクリティカルなデータは、社内のさまざまな利害関係者向けにカスタムビューを作成する必要があります。AWS アカウントの 2 人の IAM ユーザーの可視性を比較してみましょう。1 人はテーブルに対する完全なアクセス許可があり、もう 1 人は同じテーブルの列のサブセットへ選択的にアクセスできるのみです。
CloudTrail データを含むテーブルに完全にアクセスできるユーザーが既にいて、danilop と呼ばれています。新しい limitedview IAM ユーザーを作成し、Athena コンソールへのアクセスを許可します。Lake Formation コンソールでは、この新しいユーザーに 3 つの列の選択権限のみを与えます。
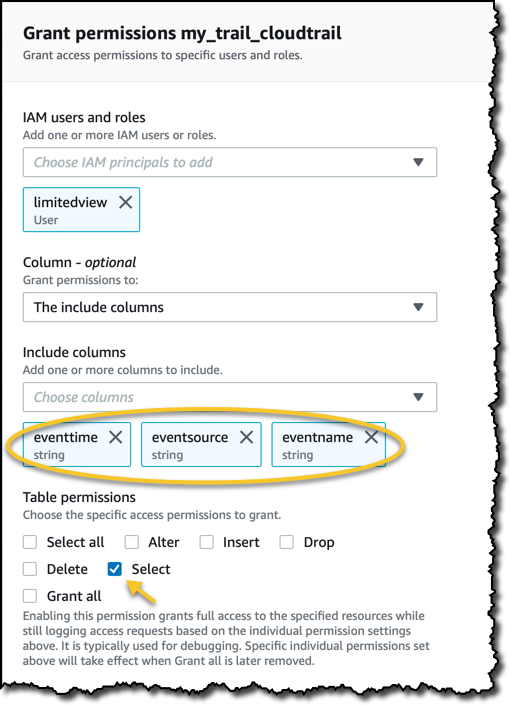
テーブル内のデータへの異なるアクセスを確認するには、一度に 1 人のユーザーでログインし、Athena コンソールに移動します。左側では、ログインしているユーザーが Glue データカタログで見ることができるテーブルと列を確認できます。次に、2 人のユーザーを並べて比較します。
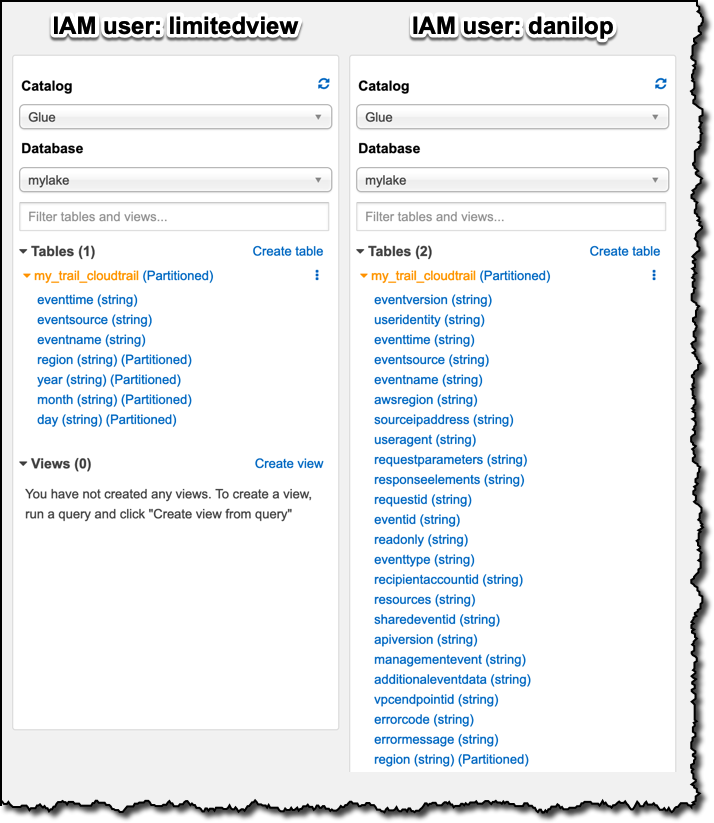
制限ユーザーは、明示的に構成した 3 つの列、およびデータを確認するためにアクセスが必要なテーブルのパーティション化に使用する 4 つの列のみにアクセスできます。limitedview ユーザーとしてログインして、select * SQL ステートメントを使用して Athena コンソールでテーブルをクエリすると、次の 7 つの列のデータのみが表示されます。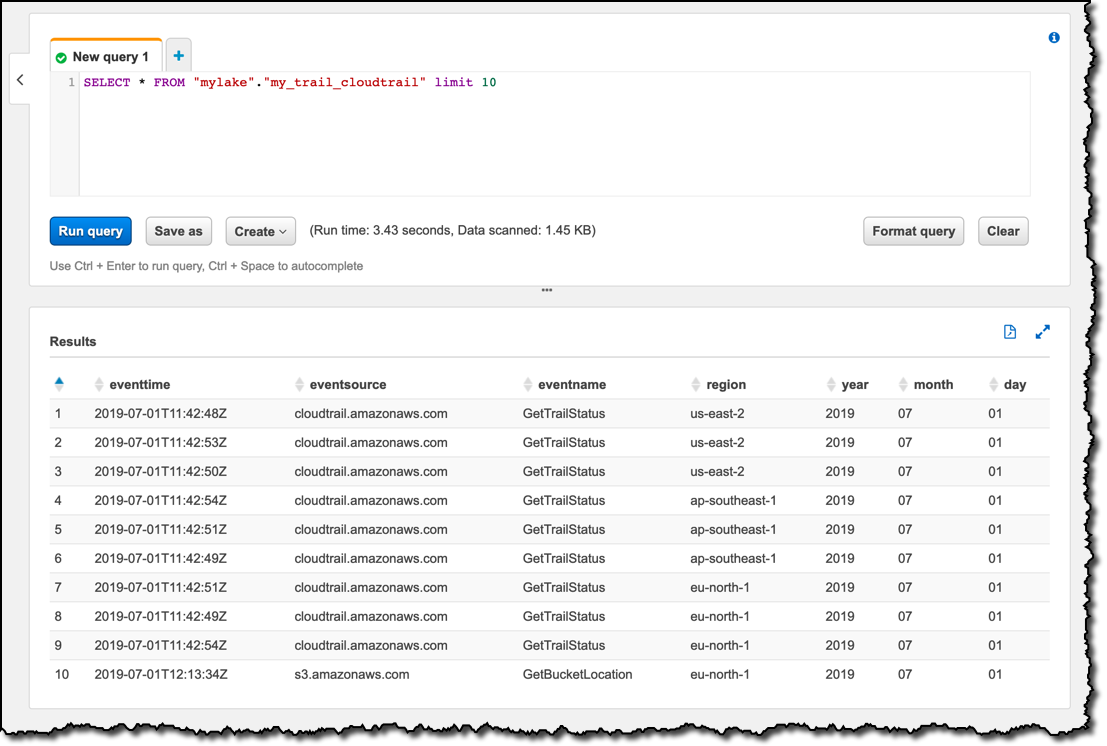
今すぐ利用可能です
AWS Lake Formation を使用するための追加費用はありません。Amazon S3 や AWS Glue などの基礎となるサービスの使用に対して支払います。 Lake Formation の主な利点の 1 つは、導入するセキュリティポリシーです。以前は、データおよびメタデータアクセスを保護するために個別のポリシーを使用する必要があり、これらのポリシーではテーブルレベルのアクセスのみが許可されていました。これで、1 つの場所から、各ユーザーが使用する必要がある列へのアクセスのみを許可できるようになります。
AWS Lake Formation は現在、米国東部 (バージニア北部)、米国東部 (オハイオ)、米国西部 (オレゴン)、欧州 (アイルランド)、および アジアパシフィック (東京) で利用できます。Lake Formation と Redshift の統合には、Redshift クラスターバージョン 1.0.8610 以降が必要です。この記事を読む頃までにクラスターは自動的に更新されているはずです。Amazon EMR による Apache Spark のサポートは、今後数か月にわたって続きます。
この記事では Lake Formation でできることのほんの一部を紹介しました。ビジネスのデータレイクの構築と管理がはるかに簡単になりました。これらの新しい機能をどう使うか、ぜひ教えてください!
— Danilo