Amazon Web Services ブログ
AWS Glue がScala をサポートしました
私たちは、AWS Glue の ETL(Extract、Transform、Load)を実行するためのスクリプトにおけるScalaのサポートを発表することに興奮しています。Scala が好きな人達は強力な武器を1つ手に入れることになり喜んでくれるでしょう。AWS Glue では Apache Spark をデータ加工のエンジンとして使用していますが、Scala は Apache Spark のネイティブな言語です。
洗練された言語としての機能が使える以外にも、Glue のスクリプトをScala で書くことはPython で書くことに比べて2つの利点があります。まずは、Python とApache Spark のScala ランタイム(JVM)の間でデータを移す必要がないので、Scala は大量のデータ移動を伴う加工整形処理がより高速です。サードパーティのライブラリで独自の変換を作成したり関数を呼び出すことができます。 次に、Scala はJava と互換性があるように設計されているため、外部Java クラスライブラリの関数をScala から呼び出すことが簡単です。 そのため、Scala のコンパイル結果は Java と同じバイトコードになりますしデータ構造を変換する必要もありません。
これらの利点を説明するために、GitHubアーカイブから入手可能なGitHub パブリックタイムラインの最近のサンプルを分析する例を説明します。このサイトはGitHubサービスへのパブリックリクエストのアーカイブで、コミットとフォークから、イシューとコメントまで35種類以上のイベントタイプを記録しています。
この記事は、タイムラインのネガティブなイシューを特定するScala スクリプト作成の方法を紹介します。このスクリプトではタイムラインサンプルのイシュー イベントを引き出し、Stanford CoreNLPライブラリのセンチメント推定機能を使用してタイトルを分析し、最もネガティブなイシューを浮き彫りにしています。
入門
スクリプトを作成する前に、AWS Glue Crawler を使ってデータ構造と特性を理解します。また、開発エンドポイントとZeppelin ノートブックをセットアップすることで、データをインタラクティブに探索してスクリプトを作成することもできます。
データをクロールする
この例で使われているデータセットは、GitHub アーカイブからAmazon S3 のサンプルデータセットバケットにダウンロードされています。場所は以下の通りです:
s3://aws-glue-datasets-<region>/examples/scala-blog/githubarchive/data/
<region>をあなたの作業中のリージョンに置き換えて最適なフォルダを選択してください。例えばap-northeast-1 などです。AWS Glue Developer Guide に記載されているように、このフォルダをクロールし、結果をAWS Glue Data Catalog のgithubarchive という名前のデータベースに格納します。このフォルダには、2017年1月22日からのタイムラインの12時間が含まれ、年、月、日によって階層的に(つまり、パーティションに分けて)編成されています。
終了したら、AWS Glueコンソールを使用してgithubarchive データベースのdata という名前のテーブルに移動します。 このデータには、各イベントタイプに共通する8つのトップレベルのカラムと、年、月、日に対応する3つのパーティションのカラムがあります。

payloadという名前のカラムを選択すると、クロールされたデータに表われるイベントタイプのpayloadの集合を反映する複雑なスキーマがあることに気づくでしょう。また、クローラはデータのサブセットのみをサンプリングするので、クローラが生成するスキーマが真のスキーマの部分集合であることにも留意してください。
ライブラリ、開発エンドポイント、およびノートブックをセットアップする
次に、テキストのスニペットをセンチメント推定するライブラリのダウンロードとセットアップを行う必要があります。Stanford CoreNLPライブラリには、センチメント予測を含む多くの人間の言語を処理するツールが含まれています。
Stanford CoreNLPライブラリをダウンロードしてください。 .zipファイルを解凍すると、たくさんのjarファイルがあるディレクトリが表示されます。 この例では次のjarが必要です。
- stanford-corenlp-3.8.0.jar
- stanford-corenlp-3.8.0-models.jar
- ejml-0.23.jar
AWS Glueにアクセス可能なAmazon S3パスにこれらのファイルをアップロードし、必要に応じてこれらのライブラリをロードできるようにします。 この例ではS3パスはs3://glue-sample-other/corenlp/にしています。
開発エンドポイントは、データ探索のバックエンドとして使用できる固定的なSparkベースの環境です。ノートブックをこれらのエンドポイントに接続して、コマンドをインタラクティブに実行し、データの探索と分析をすることができます。これらのエンドポイントは、AWS Glueのジョブ実行システムと同じ構成です。したがって、AWS Glueでジョブとして登録して実行すると、そこで動作するコマンドとスクリプトも同じように機能します。
エンドポイントとそのエンドポイントと連携して動作するZeppelinノートブックを設定するには、AWS Glue Developer Guideの指示に従ってください。エンドポイントを作成する場合は、Dependent jars pathに前述のjarファイルの場所をカンマ区切りのリストとして指定してください。そうしないと、ライブラリはロードされません。
ノートブックサーバーをセットアップしたら、AWS Glueコンソールの左側のメニューでDev Endpoints を選択してZeppelinノートブックに移動していきます。作成したエンドポイントをクリックします。 次にNotebook Server のURLをクリックして、Zeppelinサーバーに移動します。 ノートブックの作成時に指定したノートブックのユーザー名とパスワードを使用してログインします。 最後にこの例を試すために新しいノートブックを作成します。
各ノートブックは段落の集まりであり、各段落には一連のコマンドとそのコマンドの出力が含まれています。さらに、各ノートブックは多数のインタプリタを含んでいます。コンソールを使用してZeppelinサーバーをセットアップすると、pyspark(Pythonベース)とSpark(Scalaベース)のインタープリターは新しい開発エンドポイントにすでに接続されています。デフォルトはpysparkです。したがって、この例では段落の先頭に%sparkを追加する必要がありますが、この例では簡潔にするためにこれらを省略しています。
データの操作
このセクションでは、AWS Glue のSpark拡張機能を使ってデータセットを操作します。データの実際のスキーマを見て、分析のために興味深いイベントタイプをフィルタリングします。
必要となるライブラリをインポートするための定型コードから始めましょう:
%spark import com.amazonaws.services.glue.DynamicRecord import com.amazonaws.services.glue.GlueContext import com.amazonaws.services.glue.util.GlueArgParser import com.amazonaws.services.glue.util.Job import com.amazonaws.services.glue.util.JsonOptions import com.amazonaws.services.glue.types._ import org.apache.spark.SparkContext
次に、データの操作に必要なSpark とAWS Glue のコンテキストを作成します。
@transient val spark: SparkContext = SparkContext.getOrCreate() val glueContext: GlueContext = new GlueContext(spark)
Zeppelinで作業するときは、SparkContextに一時的なデコレータが必要です。 それ以外の場合は、コマンド実行時にシリアル化エラーが発生します。
DynamicFrame
このセクションでは、以前にクロールしたテーブルのGitHubレコードを含むDynamicFrameを作成する方法を示します。DynamicFrameはAWS Glue スクリプトの基本的なデータ構造です。データのクリーニングと変換ワークロード用に設計され、最適化されていることを除き、Apache Spark の data frame に似ています。DynamicFrame は、GitHubタイムラインのような半構造化データセットを表現するのに適しています。
DynamicFrame はDynamicRecord の集合です。Spark用語では、DynamicRecordsのRDD(Resilient Distributed Dataset)です。 DynamicRecord は自己記述レコードです。 各レコードはそのカラムと型をエンコードするので、すべてのレコードは動的フレーム内の他のすべてのレコードと異なるスキーマを持つことができます。 これは便利で、GitHubタイムラインのようなデータセットに対して特により効率的です。payloadはあるイベントタイプと別のイベントタイプとで大幅に異なる可能性があります。
以下のように、テーブルからgithub_eventsという名前でDynamicFrameを作成します。
val github_events = glueContext .getCatalogSource(database = "githubarchive", tableName = "data") .getDynamicFrame()
getCatalogSource()メソッドは、データカタログ内の特定のテーブルを表すDataSourceを返します。 getDynamicFrame()メソッドは、ソースからDynamicFrameを返します。
クローラは、データのサンプルのみからスキーマを作成したことを思い出してください。次のように、データセット全体をスキャンし、行を数え、完全なスキーマを表示できます。
github_events.count github_events.printSchema()
結果は次のようになります。

データには414,826件のレコードがあります。 前述のように、8つのトップレベルカラムと3つのパーティションのカラムがあることに注意してください。 下にスクロールすると、payloadが最も複雑なカラムであることがわかります。
関数とフィルタレコードを実行する
このセクションでは、独自の関数を作成し、レコードをフィルタリングするためにシームレスに呼び出す方法について説明します。Pythonのlambdaを使用したフィルタリングとは異なり、Scalaスクリプトはレコードをある言語表現から別の表現に変換する必要がないため、オーバーヘッドを減らして実行速度を大幅に向上させることができます。
GitHubタイムラインからIssuesEventsだけを選択する関数を作成しましょう。これらのイベントは、誰かが特定のリポジトリにイシューを投稿するたびに生成されます。 各GitHubイベントレコードには、イベントの種類を示すフィールド「type」があります。 issueFilter()関数は、IssuesEventsであるレコードに対してtrueを返します。
def issueFilter(rec: DynamicRecord): Boolean = {
rec.getField("type").exists(_ == "IssuesEvent")
}
getField()変換メソッドはOption [Any]型を返すので、まずその型をチェックする前にそれが存在することを確認する必要があることに注意してください。
この関数をフィルタ変換に渡すと、各レコードに関数が適用され、渡されたレコードのDynamicFrameが返されます。
val issue_events = github_events.filter(issueFilter)
では、issue_eventsのサイズとスキーマを見てみましょう。
issue_events.count issue_events.printSchema()
サイズはとても小さく(14,063レコード)、payloadのスキーマはそれほど複雑ではなく、イシューのスキーマのみを反映しています。 分析に必要ないくつかのカラムを残し、残りをApplyMapping()変換を使用してドロップします。
val issue_titles = issue_events.applyMapping(Seq(("id", "string", "id", "string"),
("actor.login", "string", "actor", "string"),
("repo.name", "string", "repo", "string"),
("payload.action", "string", "action", "string"),
("payload.issue.title", "string", "title", "string")))
issue_titles.show()
ApplyMapping()変換メソッドは、カラムの名前を変更したり、型をキャストしたり、レコードを再構築するのに非常に便利です。 前のコードスニペットは、タプルの左半分に列挙されているフィールド(またはカラム)を選択し、右半分のフィールドとタイプにマップするようにトランスフォームに指示します。
Stanford CoreNLPを使用したセンチメントの推定
最も重大なイシューに焦点を当てるには、最も否定的な感情を持つレコードを分離したいと思うかもしれません。Stanford CoreNLPライブラリはJavaベースであり、センチメント予測機能を提供します。 Pythonでこれらの関数にアクセスすることは可能ですがかなり面倒です。なので Java側にあるクラスとオブジェクトそれぞれに対して、Pythonの代理クラスとオブジェクトを生成する必要があります。 代わりに、Scalaのサポートでは、これらのクラスとオブジェクトを直接使用してメソッドを呼び出すことができます。 やってみましょう。
まず、分析に必要なライブラリをインポートします。
import java.util.Properties
import edu.stanford.nlp.ling.CoreAnnotations
import edu.stanford.nlp.neural.rnn.RNNCoreAnnotations
import edu.stanford.nlp.pipeline.{Annotation, StanfordCoreNLP}
import edu.stanford.nlp.sentiment.SentimentCoreAnnotations
import scala.collection.convert.wrapAll._
Stanford CoreNLPライブラリには、すべての分析を統制する主なドライバがあります。 ドライバのセットアップは重く、分析全体で共有されるスレッドとデータ構造を設定します。 Apache Sparkは、メインのドライバプロセスと、バックエンドエグゼキュータプロセスの集まりを持つクラスタ上で実行されます。エグゼキュータプロセスは、大部分のデータのヘビーなふるい分けを行います。
Stanford CoreNLP共有オブジェクトはシリアライズできないため、クラスタ全体に簡単に分散させることはできません。 その代わりに、Stanford CoreNLP 共有オブジェクトを必要とするバックエンドのエグゼキュータプロセスごとに一度だけ初期化する必要があります。 これを達成する方法は次のとおりです。
val props = new Properties()
props.setProperty("annotators", "tokenize, ssplit, parse, sentiment")
props.setProperty("parse.maxlen", "70")
object myNLP {
lazy val coreNLP = new StanfordCoreNLP(props)
}
このプロパティは、実行するアノテータと処理する単語の数をライブラリに伝えます。 上記のコードは、遅延評価するフィールドcoreNLPを持つオブジェクトmyNLPを作成します。 このフィールドは、必要な場合にのみ1回だけ初期化されます。 したがって、バックエンドエグゼキュータがレコードの処理を開始すると、各エグゼキュータはStanford CoreNLPライブラリのドライバを1回だけ初期化します。
次は、テキスト文字列のセンチメントを推定する関数です。 最初にStanford CoreNLPを呼び出して、テキストに注釈を付けます。 それから、それは文を引き出し、すべての文全体の平均センチメントを取り出します。 このセンチメントは0.0の最もネガティブな値から4.0の最もポジティブな値。
def estimatedSentiment(text: String): Double = {
if ((text == null) || (!text.nonEmpty)) { return Double.NaN }
val annotations = myNLP.coreNLP.process(text)
val sentences = annotations.get(classOf[CoreAnnotations.SentencesAnnotation])
sentences.foldLeft(0.0)( (csum, x) => {
csum + RNNCoreAnnotations.getPredictedClass(x.get(classOf[SentimentCoreAnnotations.SentimentAnnotatedTree]))
}) / sentences.length
}
課題タイトルのセンチメントを見積もり、計算されたフィールドをレコードの一部として追加しましょう。 これは、動的フレームのmap()メソッドで実現できます。
val issue_sentiments = issue_titles.map((rec: DynamicRecord) => {
val mbody = rec.getField("title")
mbody match {
case Some(mval: String) => {
rec.addField("sentiment", ScalarNode(estimatedSentiment(mval)))
rec }
case _ => rec
}
})
map()メソッドは、ユーザー指定の関数をすべてのレコードに適用します。 この関数は、DynamicRecordを引数として取り、DynamicRecordを返します。 上記のコードはセンチメントを計算し、それをトップレベルのフィールドに追加し、感情をレコードに追加し返します。
センチメントでレコードを数え、スキーマを表示します。 これは、Sparkがライブラリを初期化し、関連付けられているセンチメント分析を実行する必要があるため数分かかります。
issue_sentiments.count issue_sentiments.printSchema()
すべてのレコードが処理され(14,063)、センチメント値がスキーマに追加されたことに注意してください。
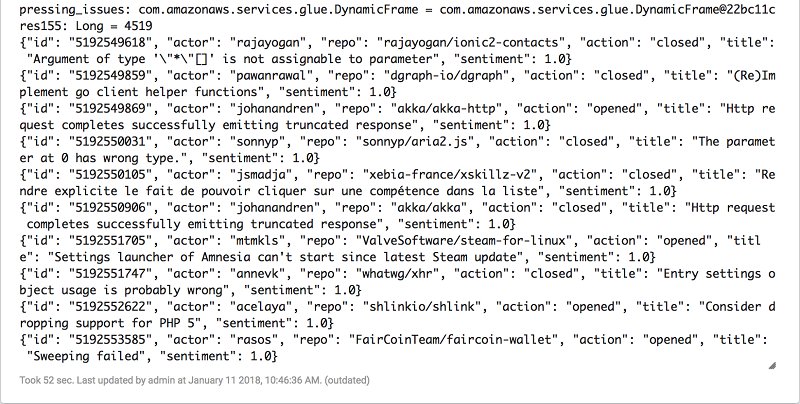
最後に、最低のセンチメント(1.5未満)を持つタイトルを選んでみましょう。 それらを数えサンプルを画面に表示していくつかのタイトルがどのように見えるかを確認します。
val pressing_issues = issue_sentiments.filter(_.getField("sentiment").exists(_.asInstanceOf[Double] < 1.5))
pressing_issues.count
pressing_issues.show(10)
次に、あとで処理できるように、それらをすべてファイルに書き込みます。(出力パスを自分で置き換える必要があります。)
glueContext.getSinkWithFormat(connectionType = "s3",
options = JsonOptions("""{"path": "s3://<bucket>/out/path/"}"""),
format = "json")
.writeDynamicFrame(pressing_issues)
出力パスを見て、出力ファイルを見ることができます。
全て一緒に入れる
前の対話セッションからジョブを作成しましょう。 次のスクリプトは、以前のすべてのコマンドを組み合わせています。 それはGitHubアーカイブファイルを処理し、非常にネガティブなイシューを書き出します
import com.amazonaws.services.glue.DynamicRecord
import com.amazonaws.services.glue.GlueContext
import com.amazonaws.services.glue.util.GlueArgParser
import com.amazonaws.services.glue.util.Job
import com.amazonaws.services.glue.util.JsonOptions
import com.amazonaws.services.glue.types._
import org.apache.spark.SparkContext
import java.util.Properties
import edu.stanford.nlp.ling.CoreAnnotations
import edu.stanford.nlp.neural.rnn.RNNCoreAnnotations
import edu.stanford.nlp.pipeline.{Annotation, StanfordCoreNLP}
import edu.stanford.nlp.sentiment.SentimentCoreAnnotations
import scala.collection.convert.wrapAll._
object GlueApp {
object myNLP {
val props = new Properties()
props.setProperty("annotators", "tokenize, ssplit, parse, sentiment")
props.setProperty("parse.maxlen", "70")
lazy val coreNLP = new StanfordCoreNLP(props)
}
def estimatedSentiment(text: String): Double = {
if ((text == null) || (!text.nonEmpty)) { return Double.NaN }
val annotations = myNLP.coreNLP.process(text)
val sentences = annotations.get(classOf[CoreAnnotations.SentencesAnnotation])
sentences.foldLeft(0.0)( (csum, x) => {
csum + RNNCoreAnnotations.getPredictedClass(x.get(classOf[SentimentCoreAnnotations.SentimentAnnotatedTree]))
}) / sentences.length
}
def main(sysArgs: Array[String]) {
val spark: SparkContext = SparkContext.getOrCreate()
val glueContext: GlueContext = new GlueContext(spark)
val dbname = "githubarchive"
val tblname = "data"
val outpath = "s3://<bucket>/out/path/"
val github_events = glueContext
.getCatalogSource(database = dbname, tableName = tblname)
.getDynamicFrame()
val issue_events = github_events.filter((rec: DynamicRecord) => {
rec.getField("type").exists(_ == "IssuesEvent")
})
val issue_titles = issue_events.applyMapping(Seq(("id", "string", "id", "string"),
("actor.login", "string", "actor", "string"),
("repo.name", "string", "repo", "string"),
("payload.action", "string", "action", "string"),
("payload.issue.title", "string", "title", "string")))
val issue_sentiments = issue_titles.map((rec: DynamicRecord) => {
val mbody = rec.getField("title")
mbody match {
case Some(mval: String) => {
rec.addField("sentiment", ScalarNode(estimatedSentiment(mval)))
rec }
case _ => rec
}
})
val pressing_issues = issue_sentiments.filter(_.getField("sentiment").exists(_.asInstanceOf[Double] < 1.5))
glueContext.getSinkWithFormat(connectionType = "s3",
options = JsonOptions(s"""{"path": "$outpath"}"""),
format = "json")
.writeDynamicFrame(pressing_issues)
}
}
スクリプトは、GlueAppというトップレベルのオブジェクトに入れられています。GlueAppはジョブへのスクリプトのエントリポイントとして働きます。(出力パスを自身のものに置き換える必要があります)必要に応じてAWS Glue がロードできるようにスクリプトをAmazon S3 にアップロードします。
ジョブを作成するには、AWS Glueコンソールを開きます。 左側のメニューでJobsを選択し、Add jobを選択します。 ジョブの名前を入力し、データにアクセスする権限を持つロールを指定します。An existing script that you provideを選択し、言語をScalaを選択します。
Scala class nameは、スクリプトのエントリポイントを示すGlueAppと入力します。 スクリプトのAmazon S3の場所を指定します。
Script libraries and job parametersを選択します。 Dependent jars pathフィールドに、以前のスタンフォードCoreNLPライブラリのAmazon S3の場所をコンマ区切りリスト(スペースなし)として入力します。Nextを選択します。
このジョブに接続する必要はありませんので、もう一度Nextを選択します。
ジョブのプロパティを確認し、Finishを選択します。 最後に、Run jobを選択してジョブを実行します。
スクリプトの入力テーブルと出力パスを編集するだけで、どんなGitHubタイムラインデータセットを使ってもこのジョブを実行することができます。
まとめ
この記事では、ScalaによるAWS Glue ETLスクリプトをノートブックで書く方法と、それらをジョブとして実行する方法を示しました。Scala はSparkランタイムのネイティブな言語であるという利点があります。Scalaを使用すると、ScalaやJava関数、および解析用にサードパーティのライブラリを呼び出すことが簡単にできます。さらに、ある言語ランタイムから別のランタイムにコードを変換する必要がないため、Scalaではデータ処理が高速になります。
Scalaスクリプトのサンプルは、GitHubのサンプルリポジトリhttps://github.com/awslabs/aws-glue-samplesにあります。 Scalaスクリプトを試すのをお勧めします、共有したい興味深いETLフローについて私達にお知らせください。
Happy Glue-ing!
About the Authors
 Mehul Shah is a senior software manager for AWS Glue.
Mehul Shah is a senior software manager for AWS Glue.
彼の情熱はクラウドを活用してよりスマートで効率的で使いやすいデータシステムを構築することです。彼は女の子が3人いるのでまったく余裕がありません。

Ben Sowell is a senior software development engineer at AWS Glue
彼はETLシステムで5年以上働き、ユーザーがデータのポテンシャルを発揮できるよう支援しています。自由な時間はベイエリアで読書や探索を楽しんでいます。

Vinay Vavili is a software development engineer for AWS Glue.
彼の情熱は、顧客のニーズをヒアリングして理解し、変換、データコネクタおよびユーティリティを開発することによって、データサイエンティストによって最高のETLを提供することです。自由な時間はテニスの技術を磨くことやアメリカの国立公園の探索などを好んでいます。
翻訳は上原が担当しました(原文はこちら)