Amazon Web Services ブログ
AWS Entity Resolution: 複数のアプリケーションとデータストアからの関連レコードを照合してリンクする
組織が成長するにつれ、顧客、企業、または製品に関する情報を含むレコードは、アプリケーション、チャネル、データストア全体でますます断片化され、サイロ化される傾向があります。情報の収集方法はさまざまであるため、住所 (「5th Avenue」と「5th Ave」) など、異なるが同等であるデータの問題もあります。そのため、関連するレコードをリンクして、統一されたビューを作成し、より良い洞察を得ることは容易ではありません。
例えば、企業は広告キャンペーンを実施して、パーソナライズされたメッセージで複数のアプリケーションやチャネルの消費者にリーチしたいと考えています。企業は、不完全または矛盾する情報を含む異なるデータレコードを処理する必要があることが多く、マッチングプロセスが困難になります。
小売業界では、企業はサプライチェーンと店舗全体で、在庫管理単位 (SKU)、ユニバーサル製品コード (UPC)、独自コードなど、複数の異なる製品コードを使用する製品を調整する必要があります。これにより、情報を迅速かつ総合的に分析することができなくなります。
この問題に対処する 1 つの方法は、複数のデータベースと相互作用する複雑な SQL クエリなどのカスタムデータ解決ソリューションを構築したり、レコードマッチング用の機械学習 (ML) モデルをトレーニングしたりすることです。しかし、これらのソリューションは構築に数か月かかり、開発リソースを必要とし、保守にもコストがかかります。
その手助けとなるよう、7月26日、AWS Entity Resolution をご紹介します。これは、複数のアプリケーション、チャネル、データストア全体で保存されている関連レコードを照合してリンクするのに役立つ ML を利用したサービスです。柔軟かつスケーラブルで、既存のアプリケーションにシームレスに接続できるエンティティ解決ワークフローの設定を数分で開始できます。
AWS Entity Resolution は、ルールベースの照合や機械学習モデルなどの高度なマッチング技術を備えており、関連する顧客情報、製品コード、ビジネスデータコードのセットを正確にリンクさせることができます。例えば、AWS Entity Resolution を使用して、最近のイベント (広告のクリック数、カートの放棄、購入など) を固有のエンティティ ID にリンクさせることで、顧客とのやりとりの統一したビューを作成したり、ストア全体で異なるコード (SKU や UPC など) を使用する商品をより詳細に追跡したりできます。
AWS Entity Resolution を使用すると、既に存在するレコードを読み取るので、データの移動を最小限に抑えながら、マッチングの精度を向上させ、データセキュリティを保護できます。ここで、実際にどのように機能するか見てみましょう。
AWS Entity Resolution の使用
分析プラットフォームの一部として、Amazon Simple Storage Service (Amazon S3) バケットに 100 万の架空の顧客を含むカンマ区切り値 (CSV) ファイルがあります。これらの顧客はロイヤルティプログラムに参加していますが、さまざまなチャネル (オンライン、店舗内、郵送) を通じて申請した可能性があるため、同じ顧客に関する複数の記録が存在する場合があります。
CSV ファイルのデータの形式は次のとおりです。
AWS Glue クローラーを使用してファイルの内容を自動的に判断し、データカタログのメタデータテーブルを最新のものにして分析ジョブに使用できるようにします。これで、AWS Entity Resolution で同じ設定を使用できます。
AWS Entity Resolution コンソールで、[使用開始] を選択して、マッチングワークフローの設定方法を確認します。

マッチングワークフローを作成するには、まずスキーママッピングを使用してデータを定義する必要があります。

[スキーママッピングの作成] を選択し、名前と説明を入力して、AWS Glue からスキーマをインポートするオプションを選択します。また、ステップバイステップのフローや JSON エディタを使用してカスタムスキーマを定義することもできます。
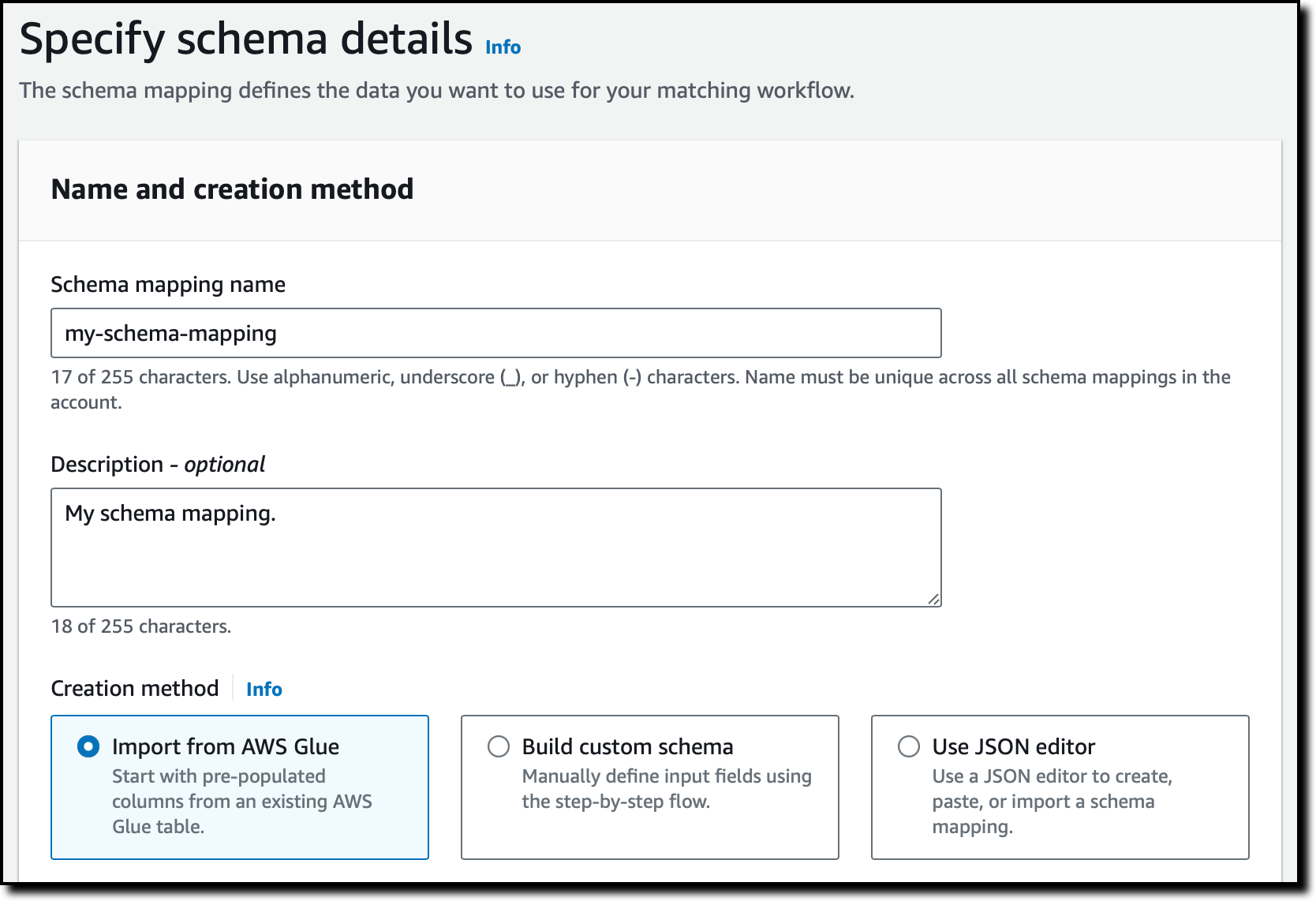
2 つのドロップダウンから AWS Glue データベースとテーブルを選択して列をインポートし、入力フィールドを事前入力します。
ドロップダウンから一意の ID を選択します。一意の IDは、データの各行を明確に参照できる列です。この場合は、CSV ファイル内の loyalty_id です。

照合に使用する入力フィールドを選択します。この場合、複数のレコードが同じ顧客に関連しているかどうかを認識するために使用できる列をドロップダウンから選択します。照合には必要ないが出力ファイルで必要な列がある場合は、オプションでそれらをパススルーフィールドとして追加できます。[次へ] を選択します。

入力フィールドを入力タイプと照合キーにマッピングします。このように、AWS Entity Resolution はこれらのフィールドを使用して類似のレコードを照合する方法を知っています。続行するには、[次へ] を選択します。
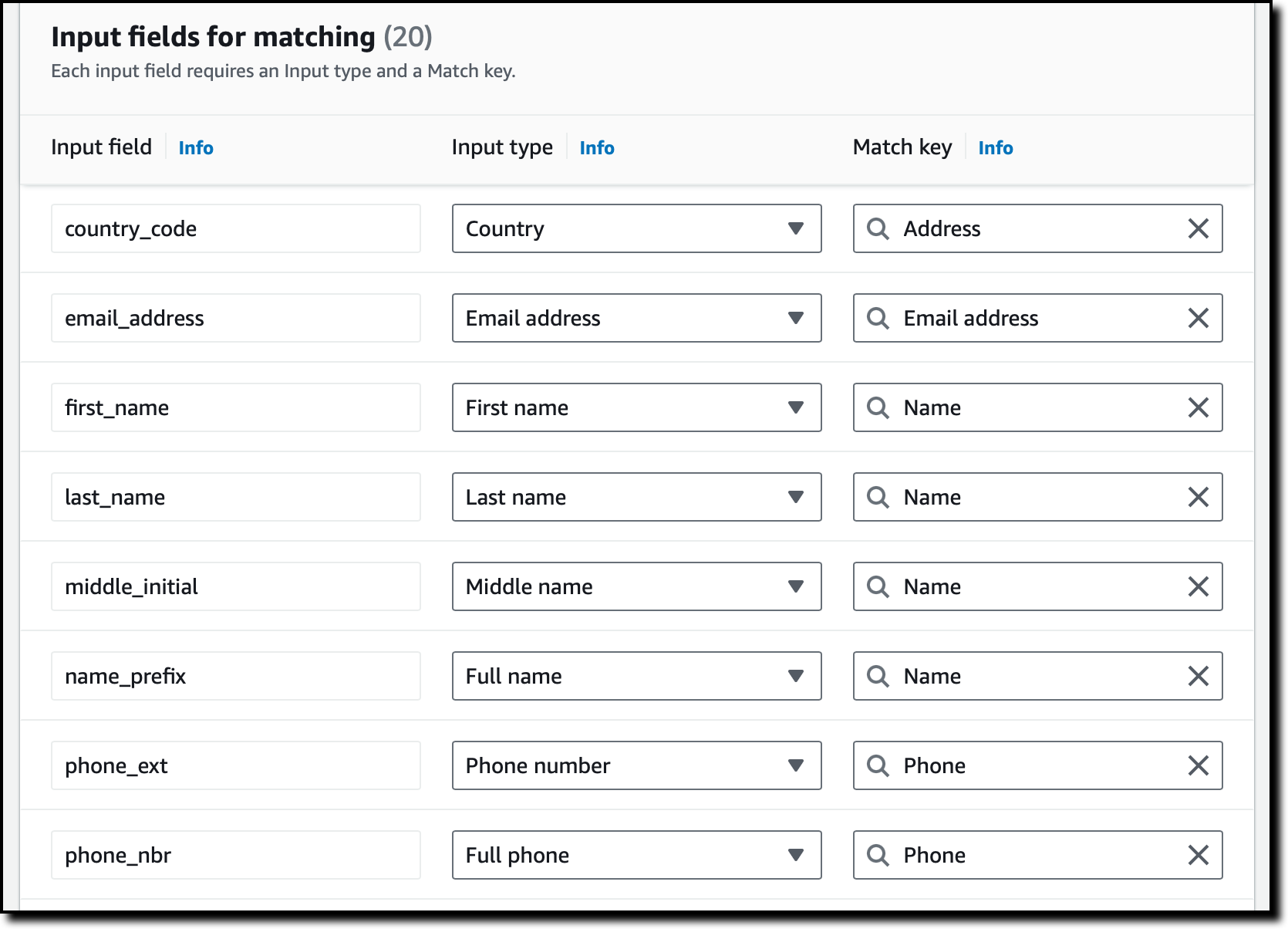
今は、比較したいデータを整理するためにグループ化を使用しています。例えば、[ファーストネーム]、[ミドルネーム]、[ラストネーム] の入力フィールドをグループ化して、[フルネーム] として比較できます。

また、[住所] フィールド用のグループも作成します。

[次へ] を選択し、すべての設定を確認します。次に、[スキーママッピングの作成] を選択します。
スキーママッピングを作成したので、ナビゲーションペインで [マッチングワークフロー] を選択し、[マッチングワークフローの作成] を選択します。

名前と説明を入力します。次に、入力データを設定するために、AWS Glue データベースとテーブルおよびスキーママッピングを選択します。

サービスにデータへのアクセスを提供するには、以前に設定したサービスロールを選択します。サービスロールは、入出力 S3 バケットと AWS Glue データベースとテーブルへのアクセスを提供します。入力または出力バケットが暗号化されている場合、サービスロールはデータの暗号化と復号化に必要な AWS Key Management Service (AWS KMS) キーへのアクセスも提供できます。[次へ] を選択します。

ルールベースのマッチング方法または ML を利用したマッチング方法を使用するオプションがあります。方法に応じて、手動または自動の処理頻度を使用して、マッチングワークフロージョブを実行できます。今は、[処理頻度] に [機械学習マッチング] と [手動] を選択し、[次へ] を選択します。

S3 バケットを出力先として設定します。[データ形式] で [正規化データ] を選択して、特殊文字や余分なスペースを削除し、データを小文字にフォーマットします。

デフォルトの [暗号化] 設定を使用します。[データ出力] では、すべての入力フィールドが含まれるようにデフォルトを使用します。セキュリティ上の理由から、フィールドは非表示にして、マスクしたい出力フィールドやハッシュフィールドから除外できます。[次へ] を選択します。
すべての設定を確認し、[作成して実行] を選択してマッチングワークフローの作成を完了し、ジョブを初めて実行します。
数分後、ジョブは完了します。この分析によると、100 万件のレコードのうち、固有の顧客は 83.5 万件のみです。出力ファイルをダウンロードするには、[Amazon S3 で出力を表示] を選択します。

出力ファイルで、各レコードは元の一意の ID (この場合は loyalty_id) と新しく割り当てられた MatchID を持っています。同じ顧客に関連するマッチングレコードは、同じ MatchID を持っています。ConfidenceLevel フィールドは、対応するレコードが実際に照合している機械学習マッチングの信頼度を表します。
これで、この情報を使用して、ロイヤルティプログラムにサブスクライブしている顧客をより良く理解できるようになりました。
利用可能なリージョンと料金
AWS Entity Resolution は、現在、米国東部 (オハイオ、バージニア北部)、米国西部 (オレゴン)、アジアパシフィック (ソウル、シンガポール、シドニー、東京)、欧州 (フランクフルト、アイルランド、ロンドン) の AWS リージョンで一般提供されています。
AWS Entity Resolution では、ワークフローで処理されたソースレコードの数に基づいて、使用した分のみお支払いいただきます。価格は、機械学習であろうとルールベースのレコードマッチングであろうと、マッチング方法には依存しません。詳細については、「AWS Entity Resolution の料金」を参照してください。
AWS Entity Resolution を使用すると、データがどのようにリンクされているかをより深く理解できます。これにより、顧客レコードの統一されたビューに基づいて、新しい洞察を提供し、意思決定を強化し、顧客体験を向上させることができます。
AWS Entity Resolution を使用すると、アプリケーション、チャネル、データストア間で関連レコードを照合してリンクする方法を簡素化できます。
— Danilo
P.S.私たちは、より良いカスタマーエクスペリエンスを提供するためにコンテンツの改善に注力しており、そのためにはお客様からのフィードバックが必要です。この短いアンケートにご回答いただき、AWS ブログに関するご感想をいただけますと幸いです。なお、このアンケートは外部企業によって実施されているため、リンク先は当社のウェブサイトではありません。AWS は、AWS プライバシー通知に記載されているとおりにお客様の情報を取り扱います。
原文はこちらです。