Amazon Web Services ブログ
AWS Clean Rooms ML は、お客様やパートナーが未加工データを共有せずに ML モデルを適用するのに役立ちます (プレビュー)
11月29日は、AWS Clean Rooms ML (プレビュー) を紹介します。この製品は、AWS Clean Rooms の新機能です。これにより、お客様とパートナーは、生データを互いにコピーしたり共有したりすることなく、集合データに機械学習 (ML) モデルを適用できます。この新機能により、機密データを引き続き保護しながら、ML モデルを使用して予測インサイトを生成できます。
このプレビュー中に、AWS Clean Rooms ML は、企業がマーケティングユースケース用の類似セグメントを作成するのを支援することに特化した最初のモデルを発表します。AWS Clean Rooms ML Looke では、独自のカスタムモデルをトレーニングできます。また、パートナーを招待してレコードの小さなサンプルを共同で作成してもらい、全員の基盤となるデータを保護しながら、同様のレコードを拡張して生成できます。
今後数か月以内に、AWS Clean Rooms ML はヘルスケアモデルをリリースする予定です。これは、AWS Clean Rooms ML が来年にサポートする多くのモデルのうちの最初のモデルとなります。

AWS Clean Rooms ML は、インサイトを生み出すためのさまざまな機会を開くのに役立ちます。例:
- 航空会社は、忠実な顧客に関するシグナルを受け取ったり、オンライン予約サービスと連携したり、似たような特徴を持つユーザーにプロモーションを提供したりできます。
- 自動車貸し手や自動車保険会社は、既存のリース所有者と特徴を共有する見込みのある自動車保険の顧客を特定できます。
- ブランドやパブリッシャーは、市場にいる顧客の類似セグメントをモデル化し、関連性の高い広告体験を提供できます。
- 研究機関や病院ネットワークは、既存の臨床試験参加者と同様の候補者を見つけて、臨床研究を加速させることができます (近日公開予定)。
AWS Clean Rooms ML Looke Modeling を利用すると、各コラボレーションでトレーニングされた AWS マネージドですぐに使えるモデルを適用して、数回のクリックで類似データセットを生成できるため、独自のモデルを構築、トレーニング、調整、デプロイするための開発作業を数か月も節約できます。
AWS Clean Rooms ML を使用して予測インサイトを生成する方法
今日は、AWS Clean Rooms ML で類似モデリングを使用する方法を示します。パートナーとのデータコラボレーションがすでに設定されていることを前提としています。その方法を知りたい場合、「AWS Clean Rooms が一般公開されました — ローデータを共有せずにパートナーと協力しましょう」の投稿をご覧ください。
AWS Clean Rooms コラボレーションで収集したデータを使用して、パートナーと協力して ML 類似モデリングを適用し、類似セグメントを生成できます。データから代表的なレコードを少量抽出して機械学習 (ML) モデルを作成し、そのモデルを適用してビジネスパートナーのデータから類似レコードの拡張セットを特定します。
次のスクリーンショットは、AWS Clean Rooms ML を使用するための全体的なワークフローを示しています。
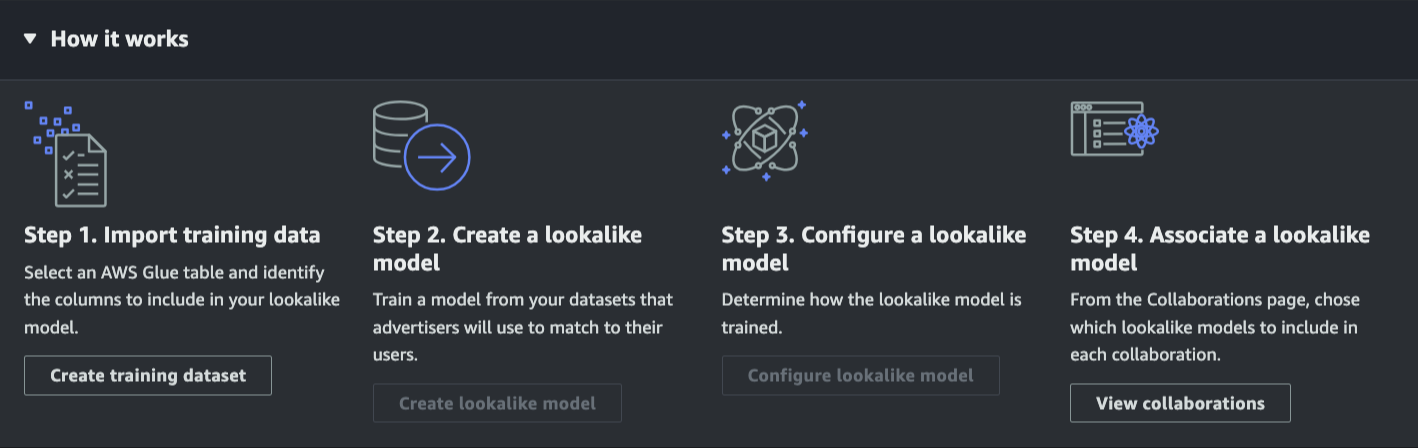
AWS Clean Rooms ML を使用することで、複雑で時間のかかる ML モデルを自分で構築する必要がなくなります。AWS Clean Rooms ML は、カスタムのプライベート ML モデルをトレーニングします。これにより、データを保護しながら何か月もの時間を節約できます。
データを共有する必要性を排除
ML モデルはサービス内でネイティブに構築されるため、AWS Clean Rooms ML は ML モデルを構築するためにデータを共有する必要がないため、データセットと顧客の情報を保護するのに役立ちます。
トレーニングデータセットは、ユーザーアイテムのインタラクションを含む AWS Glue データカタログテーブルを使用して指定できます。
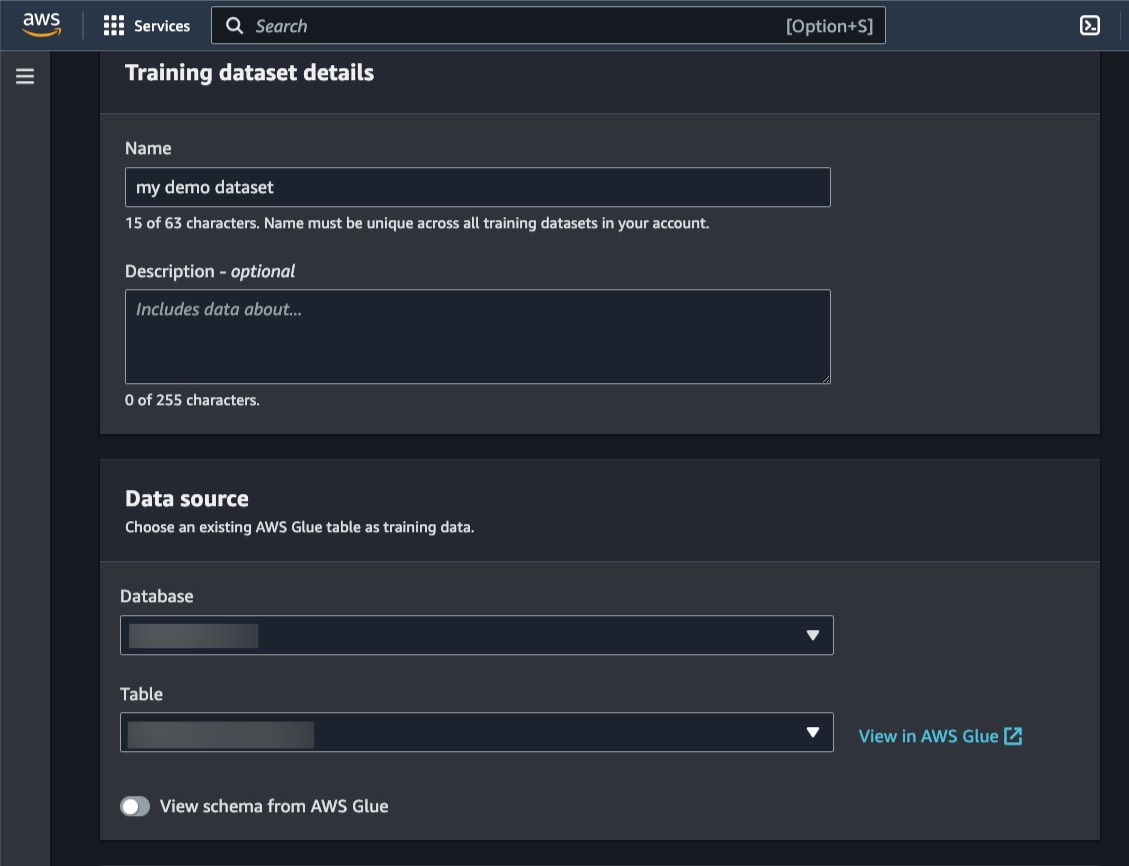
[トレーニングする追加列] で、数値データとカテゴリデータを定義できます。これは、動画の視聴にかかった秒数、記事のトピック、e コマース商品の商品カテゴリなど、データセットにさらに機能を追加する必要がある場合に役立ちます。

カスタムトレーニング済みの AWS 構築モデルの適用
トレーニングデータセットを定義したら、類似モデルを作成できます。類似モデルとは、パートナーのデータセットから類似のプロファイルを見つけるために使用される機械学習モデルで、いずれの当事者も基礎となるデータを互いに共有する必要はありません。
類似モデルを作成するときは、トレーニングデータセットを指定する必要があります。1 つのトレーニングデータセットから、多くの類似モデルを作成できます。また、相対範囲または絶対範囲を使用して、トレーニングデータセットの日付ウィンドウを柔軟に定義できます。これは、ユーザーが読んだ記事など、AWS Glue 内で常に更新されるデータがある場合に役立ちます。
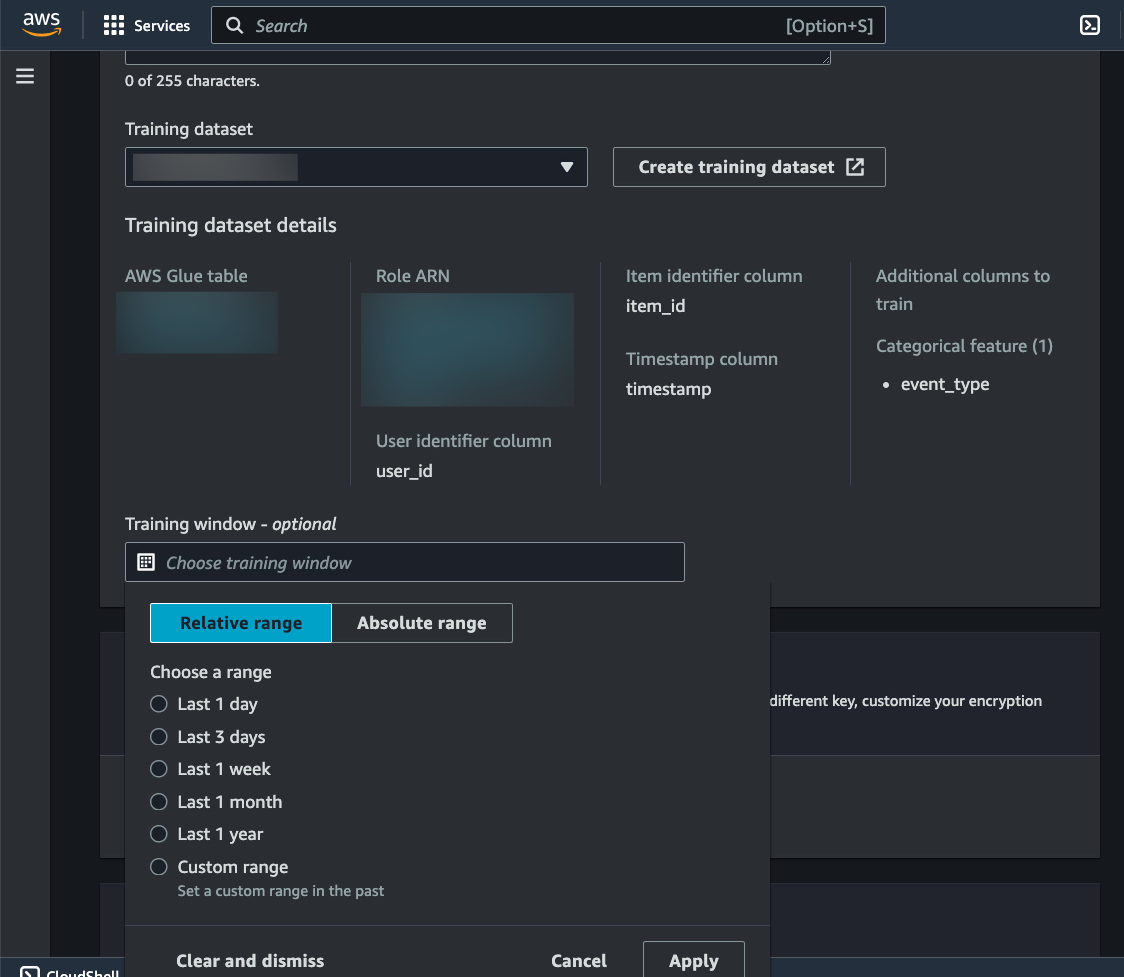
調整が簡単な ML モデル
類似モデルを作成したら、それを AWS Clean Rooms コラボレーションで使用するように設定する必要があります。AWS Clean Rooms ML には柔軟なコントロールが用意されているため、お客様やパートナーは適用された ML モデルの結果を調整して予測的な洞察を得ることができます。
[類似モデルの設定] ページでは、使用する [類似モデル] を選択し、必要な最小マッチングシードサイズを定義できます。このシードサイズは、トレーニングデータ内のプロファイルと重複するシードデータ内のプロファイルの最小数を定義します。
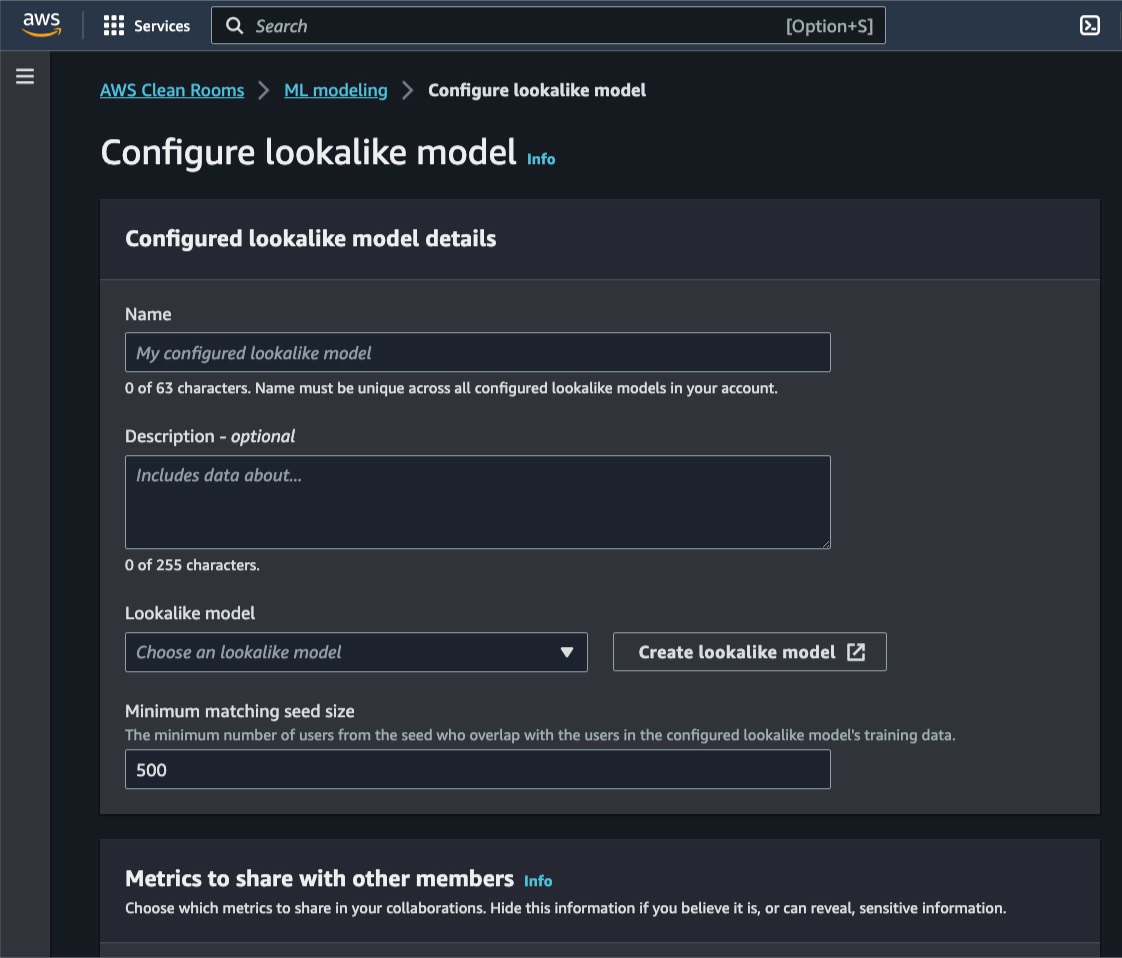
また、コラボレーションのパートナーが他のメンバーと共有するメトリックスを Metricsで受け取るかを柔軟に選択することができます。
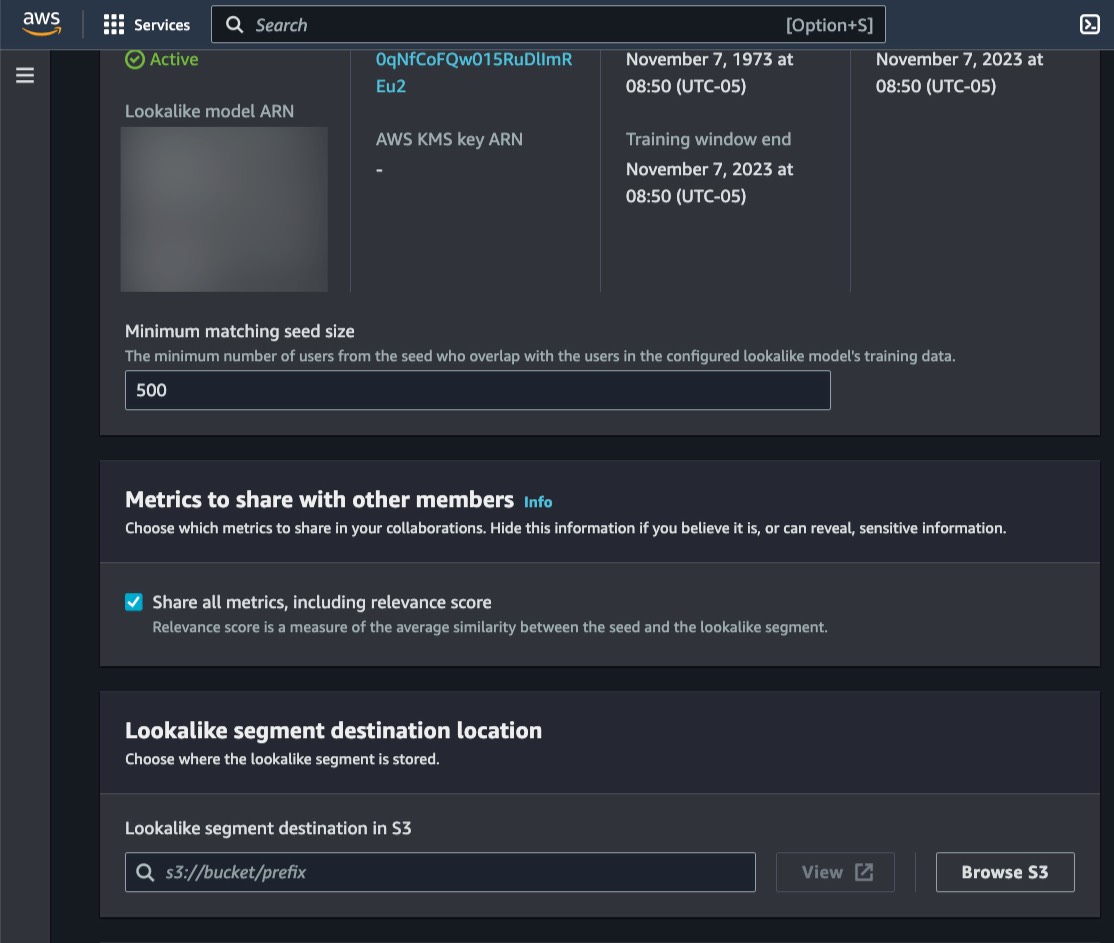
類似モデルを適切に設定したら、設定した類似モデルをコラボレーションに関連付けることで、パートナーが ML モデルを利用できるようになります。

類似セグメントの作成
類似モデルが関連付けられたら、パートナーは [類似セグメントの作成] を選択し、コラボレーションに関連する類似モデルを選択することで、インサイトの生成を開始できるようになります。
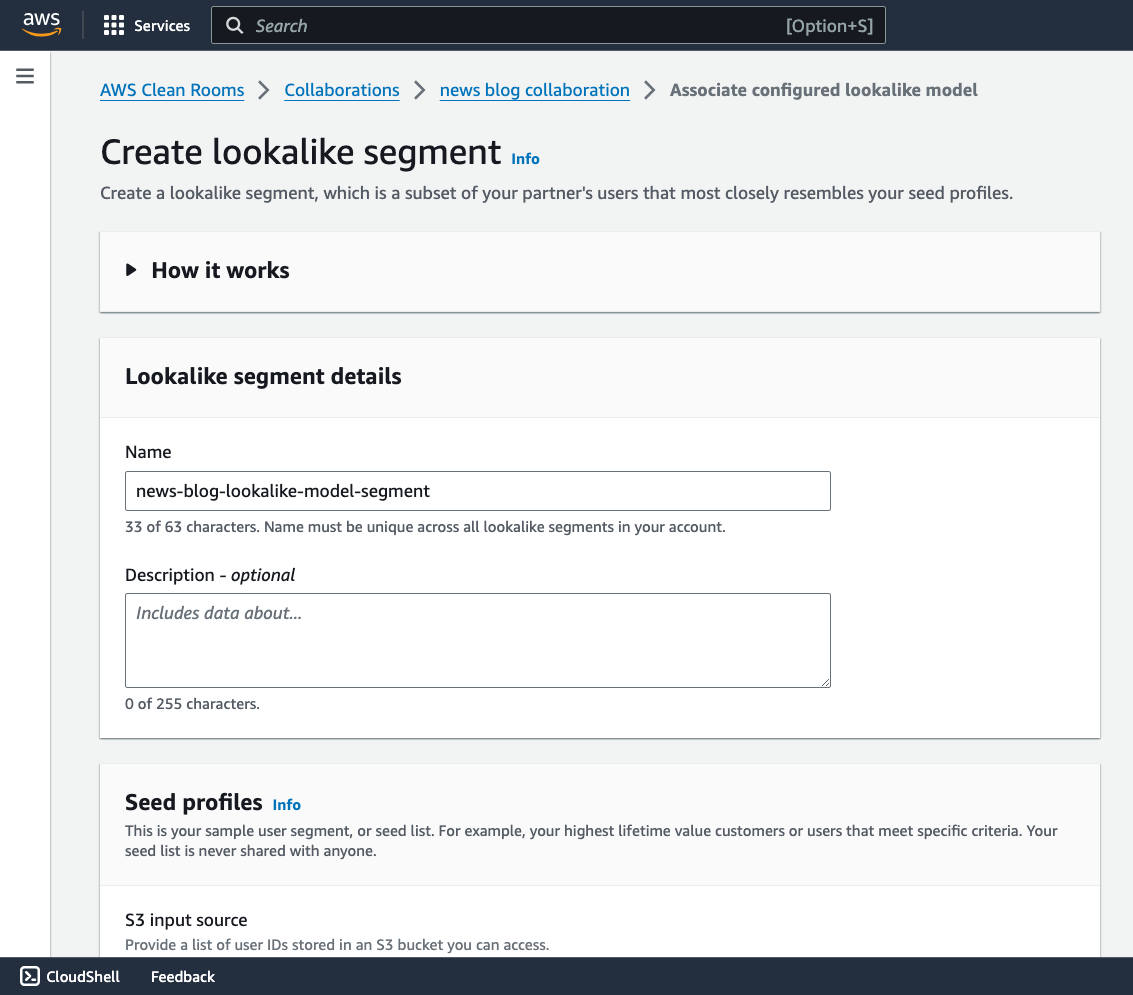
こちらの [類似セグメントの作成] ページで、パートナーがシードプロファイルを提供する必要があります。シードプロファイルの例には、上位の顧客や特定の製品を購入したすべての顧客が含まれます。生成される類似セグメントには、シードからのプロファイルと最も類似したトレーニングデータのプロファイルが含まれます。

最後に、パートナーは ML モデルを使用した類似セグメントの結果として、関連性指標を取得します。この段階では、スコアを使用して決定を下すことができます。
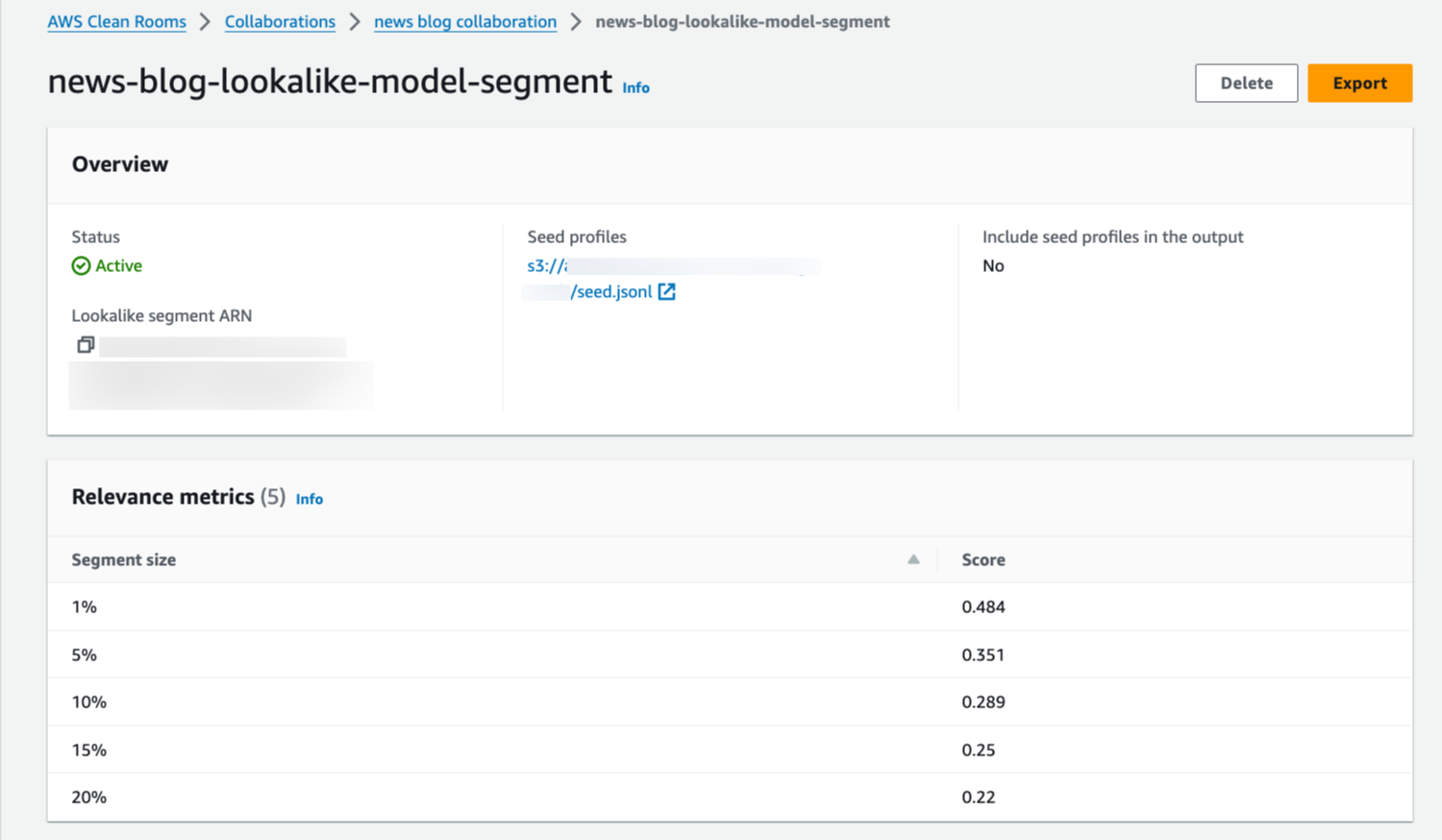
データのエクスポートとプログラマティック API の使用
類似セグメントデータをエクスポートするオプションもあります。エクスポートされると、データは JSON 形式で利用可能になり、AWS Clean Rooms API やアプリケーションと統合してこの出力を処理できます。

プレビューが公開中
AWS Clean Rooms ML は現在プレビュー段階にあり、米国東部 (オハイオ、バージニア北部)、米国西部 (オレゴン)、アジアパシフィック (ソウル、シンガポール、シドニー、東京)、ヨーロッパ (フランクフルト、アイルランド、ロンドン) の AWS Clean Rooms を通じてご利用いただけます。他のモデルのサポートも検討中です。
AWS Clean Rooms ML ページで、基礎となるデータを共有せずにパートナーと機械学習を適用する方法をご覧ください。
よいコラボレーションを!
— Donnie
原文はこちらです。