ドキュメントは、金融、医療、法律、および不動産などの数多くの業界全体における記録管理、コミュニケーション、コラボレーション、そして取引のための主な手段です。毎年処理される何百万もの住宅ローン申請、そして何億もの W2 納税申告書は、そのようなドキュメントの数例にすぎません。多くの情報は、非構造化ドキュメントに閉じ込められています。これらのドキュメントの検索と検出、ビジネスプロセスの自動化、およびコンプライアンス管理を可能にするには、時間がかかる複雑なプロセスが必要になるのが通常です。
この記事では、Amazon Textract を利用して、機械学習 (ML) の経験がなくてもスキャンされたドキュメントからテキストとデータを自動的に抽出することができる方法を説明します。AWS が可用性に優れたスケーラブルな環境での高度な ML モデルの構築、トレーニング、およびデプロイメントを処理するので、皆さんには簡単に使用できる API アクションでこれらのモデルを活用していただきます。この記事で取り上げるユースケースは以下のとおりです。
- ドキュメントからのテキスト検出
- 複数の列の検出と読み順
- 自然言語処理とドキュメント分類
- 医療ドキュメントのための自然言語処理
- ドキュメント翻訳
- 検索と検出
- フォームの抽出と処理
- ドキュメント編集によるコンプライアンス管理
- 表の抽出と処理
- PDF ドキュメントの処理
Amazon Textract
ユースケースについての説明を始める前に、コア機能をいくつか見直して、ご紹介したいと思います。Amazon Textract は、シンプルな光学文字認識 (OCR) という枠を超えて、フォーム内のフィールドのコンテンツや、表に格納された情報も識別します。これにより、Amazon Textract を使用して、手動での工数やカスタムコードを必要とすることなく、実質上どのようなタイプのドキュメントでも瞬時に「読み取り」、テキストとデータを正確に抽出することが可能になります。
以下の画像は、サンプルドキュメントと、AWS マネージメントコンソールにある Amazon Textract を使用して抽出したドキュメントのテキスト、フォーム、および表のデータです。
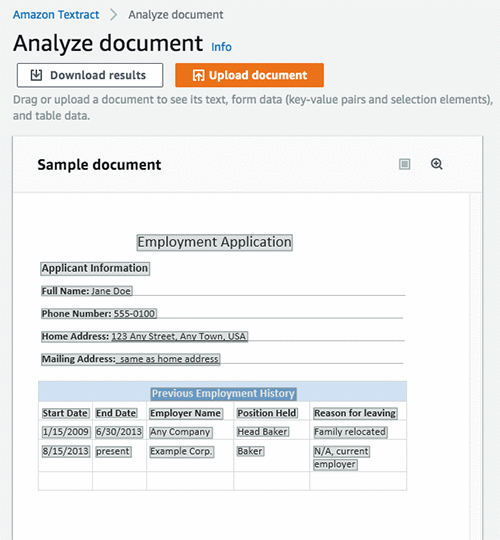
以下の画像は、ドキュメントから未処理のテキストとして抽出された行です。
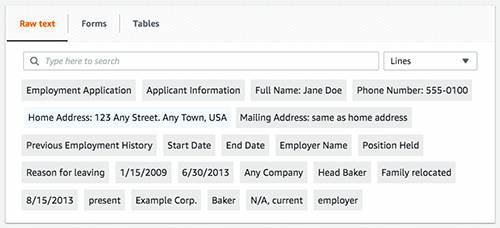
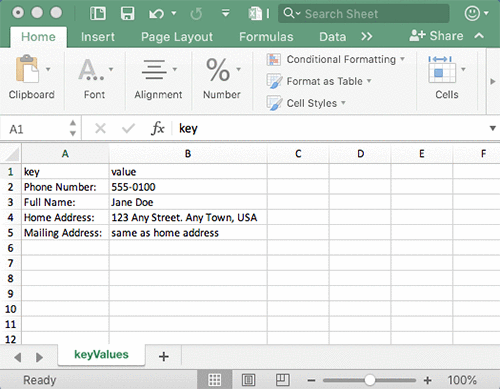
以下の画像は、抽出されたフォームフィールドとそれらに対応する値です。
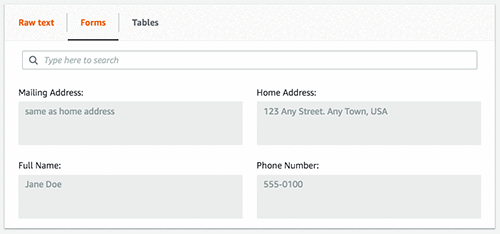
以下の画像は、抽出された表、セル、およびこれらのセル内のテキストです。
出力を含む zip ファイルをすばやくダウンロードするには、[結果をダウンロードする] をクリックします。フォームと表については、未処理の JSON、テキスト、および CSV ファイルなどのさまざまな形式を選択できます。
検出された内容の他にも、Amazon Textract は検出された要素の信頼度スコアとバウンドボックスといった追加情報も提供し、抽出されたコンテンツをどのように利用して、さまざまなビジネスアプリケーションに統合させるかをコントロールできるようにしてくれます。
Amazon Textract は、ドキュメントテキストを抽出し、ドキュメントテキストのデータを分析するために、同期および非同期両方の API アクションを提供します。同期 API は単一ページのドキュメント、およびモバイルキャプチャなどの低遅延ユースケースに使用できます。非同期 API は、何千ものページを含む PDF ドキュメントなど、複数ページのドキュメントに使用できます。詳細については、「Amazon Textract API Reference」を参照してください。
ユースケース
それでは、AWS SDK を使って Amazon Textract の API 操作を活用するコードを作成し、パワースマートなアプリケーションの構築がどれだけ簡単かを確認しましょう。 以下のユースケースの一部には、JSON Parser Library も使用します。
ドキュメントからのテキスト検出
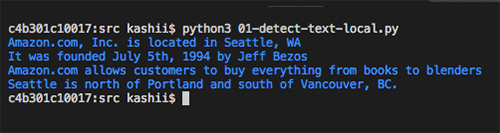
ドキュメントからテキストを検出する方法のシンプルな例から始めます。以下の画像を Amazon Textract への入力ドキュメントとして使用します。ご覧いただけるように、このサンプル画像の品質はよくありませんが、Amazon Textract はそれでも正確にテキストを検出できます。

以下のコードは、数行のコードを使ってこのサンプル画像を Amazon Textract に送信し、JSON 応答を受け取る方法を示しています。その後、以下にあるように JSON のブロックで処理を繰り返し、検出されたテキストを印刷します。
import boto3
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "simple-document-image.jpg"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Print detected text
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
以下の JSON 応答は Amazon Textract から受け取る応答で、ブロックはドキュメント内で検出されたテキストを表しています。
{
"Blocks": [
{
"Geometry": {
"BoundingBox": {
"Width": 1.0,
"Top": 0.0,
"Left": 0.0,
"Height": 1.0
},
"Polygon": [
{
"Y": 0.0,
"X": 0.0
},
{
"Y": 0.0,
"X": 1.0
},
{
"Y": 1.0,
"X": 1.0
},
{
"Y": 1.0,
"X": 0.0
}
]
},
"Relationships": [
{
"Type": "CHILD",
"Ids": [
"2602b0a6-20e3-4e6e-9e46-3be57fd0844b",
"82aedd57-187f-43dd-9eb1-4f312ca30042",
"52be1777-53f7-42f6-a7cf-6d09bdc15a30",
"7ca7caa6-00ef-4cda-b1aa-5571dfed1a7c"
]
}
],
"BlockType": "PAGE",
"Id": "8136b2dc-37c1-4300-a9da-6ed8b276ea97"
}.....
],
"DocumentMetadata": {
"Pages": 1
}
}
以下の画像は、検出されたテキストの出力です。
複数の列の検出と読み順
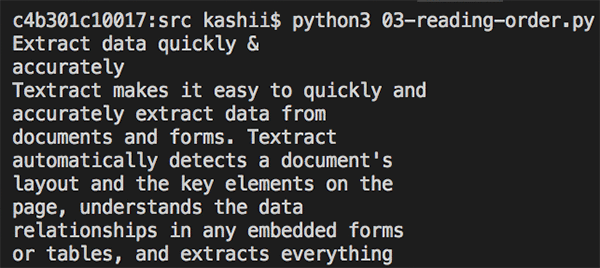
従来の OCR ソリューションは左から右へと読み取りを行い、複数の列は検出しないため、複数の列を持つドキュメントに対して誤った読み順を生成することになります。テキストの検出に加えて、Amazon Textract は、複数の列を検出し、読み順でテキストを印刷するために使用できる追加の幾何情報も提供します。
以下の画像は 2 列のドキュメントです。先ほどの例と同じように、この画像も品質がよくありませんが、Amazon Textract はそれでも良い結果を出します。

以下のコード例は、Amazon Textract でドキュメントを処理し、テキストを読み順で印刷するために幾何情報を活用する例です。
import boto3
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "two-column-image.jpg"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Detect columns and print lines
columns = []
lines = []
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
column_found=False
for index, column in enumerate(columns):
bbox_left = item["Geometry"]["BoundingBox"]["Left"]
bbox_right = item["Geometry"]["BoundingBox"]["Left"] + item["Geometry"]["BoundingBox"]["Width"]
bbox_centre = item["Geometry"]["BoundingBox"]["Left"] + item["Geometry"]["BoundingBox"]["Width"]/2
column_centre = column['left'] + column['right']/2
if (bbox_centre > column['left'] and bbox_centre < column['right']) or (column_centre > bbox_left and column_centre < bbox_right):
#Bbox appears inside the column
lines.append([index, item["Text"]])
column_found=True
break
if not column_found:
columns.append({'left':item["Geometry"]["BoundingBox"]["Left"], 'right':item["Geometry"]["BoundingBox"]["Left"] + item["Geometry"]["BoundingBox"]["Width"]})
lines.append([len(columns)-1, item["Text"]])
lines.sort(key=lambda x: x[0])
for line in lines:
print (line[1])
以下の画像は、検出されたテキストの正しい読み順での出力です。
自然言語処理とドキュメント分類
お客様の E メール、サポートチケット、製品レビュー、ソーシャルメディア、そして広告文でさえも、すべてがビジネスに利用できるカスタマーセンチメントへのインサイトを意味します。このようなコンテンツの多くには、画像またはスキャンされたバージョンのドキュメントが含まれています。これらのドキュメントからテキストを抽出したら、Amazon Comprehend を使用してセンチメント、エンティティ、キーフレーズ、構文、およびトピックを検出することができます。事業ドメインに基づいたカスタムエンティティを検出するように Amazon Comprehend を訓練することも可能です。その後、これらのエンティティは、ドキュメントの分類、ビジネスプロセスワークフローの自動化、およびコンプライアンスの確保のために使用できます。
以下のコード例は、先ほど使用した最初の画像サンプルをテキスト抽出のために Amazon Textract で処理し、その後センチメントとエンティティの検出のために Amazon Comprehend を使用する例です。
import boto3
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "simple-document-image.jpg"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Print text
print("\nText\n========")
text = ""
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
text = text + " " + item["Text"]
# Amazon Comprehend client
comprehend = boto3.client('comprehend')
# Detect sentiment
sentiment = comprehend.detect_sentiment(LanguageCode="en", Text=text)
print ("\nSentiment\n========\n{}".format(sentiment.get('Sentiment')))
# Detect entities
entities = comprehend.detect_entities(LanguageCode="en", Text=text)
print("\nEntities\n========")
for entity in entities["Entities"]:
print ("{}\t=>\t{}".format(entity["Type"], entity["Text"]))
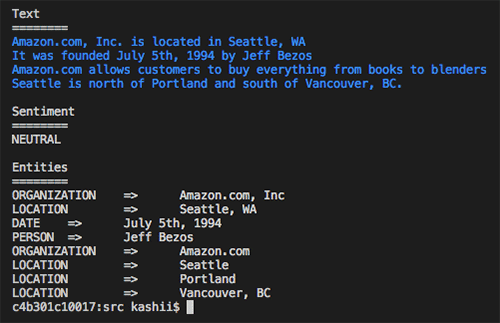
以下の画像は、Amazon Comprehend からのテキスト分析を伴う出力テキストです。 Amazon Comprehend によってセンチメントが「Neutral」であることが検知され、他のエンティティと共に、組織として「Amazon」、ロケーションとして「Seattle, WA」、および日付として「July 5th, 1994」が検出されたことがわかります。
医療ドキュメントのための自然言語処理
患者ケアを向上させ、臨床研究を迅速化するための重要な手段のひとつは、自由形式の医療テキストに「閉じ込め」られたインサイトと関係性を理解することによるものです。これらには、病院の入院メモと患者の病歴を含めることができます。
この例では、以下のドキュメントを使用して Amazon Textract を使ったテキストの抽出を行います。その後、Amazon Comprehend Medical を使用して、病状、薬、投与形態、含量、および保護対象医療情報 (PHI: Protected Health Information) などの医療エンティティを抽出します。

以下のコード例は、異なる医療エンティティが検出される方法を示しています。
import boto3
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "medical-notes.png"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Print text
print("\nText\n========")
text = ""
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
text = text + " " + item["Text"]
# Amazon Comprehend client
comprehend = boto3.client('comprehendmedical')
# Detect medical entities
entities = comprehend.detect_entities(Text=text)
print("\nMidical Entities\n========")
for entity in entities["Entities"]:
print("- {}".format(entity["Text"]))
print (" Type: {}".format(entity["Type"]))
print (" Category: {}".format(entity["Category"]))
if(entity["Traits"]):
print(" Traits:")
for trait in entity["Traits"]:
print (" - {}".format(trait["Name"]))
print("\n")
以下の画像とテキストブロックは、検出されたテキストの出力で、情報はタイプ別に分類されています。「40yo」は、「Protected Health Information」のカテゴリで年齢として検出され、睡眠障害、発疹、下鼻甲介、紅斑性発疹などを含めた異なる病状も検出されました。また、異なる薬と解剖学情報も認識しています。
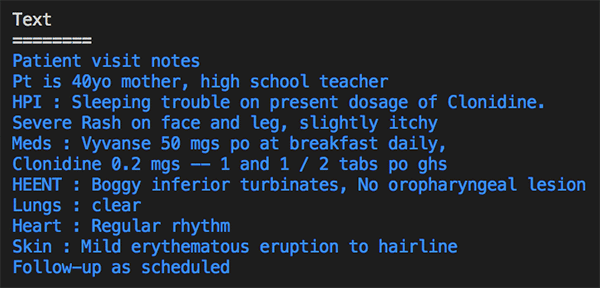
Medical Entities
========
- 40yo
Type: AGE
Category: PROTECTED_HEALTH_INFORMATION
- Sleeping trouble
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SYMPTOM
- Clonidine
Type: GENERIC_NAME
Category: MEDICATION
- Rash
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SYMPTOM
- face
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- leg
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- Vyvanse
Type: BRAND_NAME
Category: MEDICATION
- Clonidine
Type: GENERIC_NAME
Category: MEDICATION
- HEENT
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- Boggy inferior turbinates
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SIGN
- inferior
Type: DIRECTION
Category: ANATOMY
- turbinates
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- oropharyngeal lesion
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SIGN
- NEGATION
- Lungs
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- clear Heart
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SIGN
- Heart
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- Regular rhythm
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SIGN
- Skin
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- erythematous eruption
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SIGN
- hairline
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
ドキュメント翻訳
多くの組織が、ウェブサイトやアプリケーションなどのコンテンツを国際的な使用のためにローカライズします。これらの組織は大量のドキュメントを効率的に翻訳しなければなりません。Amazon Textract と Amazon Translate を併用してテキストとデータを抽出し、それらを他の言語に翻訳することができます。
以下のコード例は、最初の画像のテキストをドイツ語に翻訳します。
import boto3
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "simple-document-image.jpg"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Amazon Translate client
translate = boto3.client('translate')
print ('')
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
result = translate.translate_text(Text=item["Text"], SourceLanguageCode="en", TargetLanguageCode="de")
print ('\033[92m' + result.get('TranslatedText') + '\033[0m')
print ('')
以下の画像は、検出されたテキストの出力で、行ごとにドイツ語に翻訳されています。

検索と検出
ドキュメントから構造化データを抽出し、Amazon Elasticsearch Service (Amazon ES) を使用してスマートインデックスを作成することによって、何百万ものドキュメントをすばやく検索することができます。例えば、住宅ローン会社はスキャンされた何百万ものローン申請を Amazon Textract を使ってほんの数時間で処理し、抽出されたデータを Amazon ES でインデックス化することができます。こうすることによって、申請者の名前が John Doe のローン申請の検索、または金利が 2 パーセントの契約の検索といった検索エクスペリエンスを生み出すことが可能になります。
以下のコード例は、最初の画像からテキストを抽出し、それを Amazon ES に保存してから、Kibana を使って検索する方法を示しています。また、Amazon ES の API を活用することによって、カスタム UI エクスペリエンスを構築することもできます。この記事の後半でフォームと表を抽出する方法を学んだら、その構造化データを同じようにインデックス化して、スマート検索を可能にすることができます。
import boto3
from elasticsearch import Elasticsearch, RequestsHttpConnection
from requests_aws4auth import AWS4Auth
def indexDocument(bucketName, objectName, text):
# Update host with endpoint of your Elasticsearch cluster
#host = "search--xxxxxxxxxxxxxx.us-east-1.es.amazonaws.com
host = "searchxxxxxxxxxxxxxxxx.us-east-1.es.amazonaws.com"
region = 'us-east-1'
if(text):
service = 'es'
ss = boto3.Session()
credentials = ss.get_credentials()
region = ss.region_name
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
es = Elasticsearch(
hosts = [{'host': host, 'port': 443}],
http_auth = awsauth,
use_ssl = True,
verify_certs = True,
connection_class = RequestsHttpConnection
)
document = {
"name": "{}".format(objectName),
"bucket" : "{}".format(bucketName),
"content" : text
}
es.index(index="textract", doc_type="document", id=objectName, body=document)
print("Indexed document: {}".format(objectName))
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "simple-document-image.jpg"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Print detected text
text = ""
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
text += item["Text"]
indexDocument(s3BucketName, documentName, text)
# You can view index documents in Kibana Dashboard
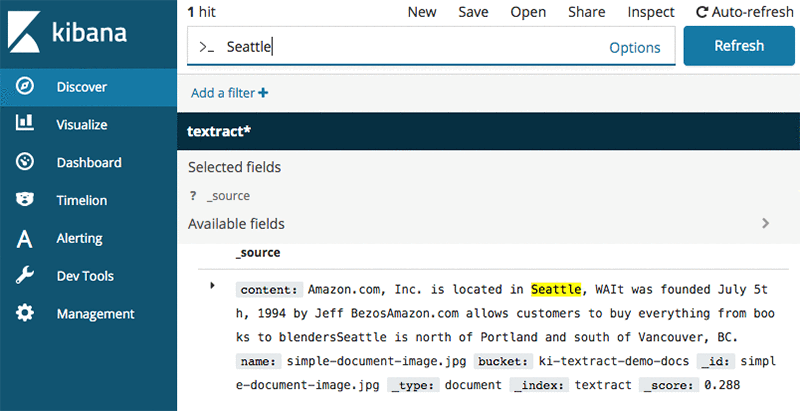
以下の画像は、Kibana 検索結果にある抽出されたテキストの出力です。
フォームの抽出と処理
Amazon Textract は、人が介入することなくフォームを自動的に処理するために必要な入力を提供することができます。例えば、銀行はローン申請の PDF を読み取るコードを作成できます。このドキュメントに含まれる情報は、ローンを承認するために必要なすべての身元チェックとクレジットチェックを開始するために使用できるので、お客様は手動でのレビューと検証のために数日間待たされるかわりに、申請の結果を瞬時に得ることができます。
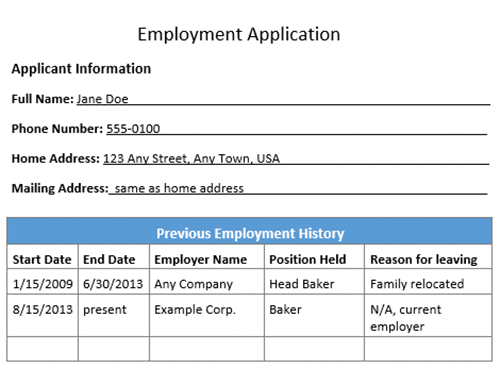
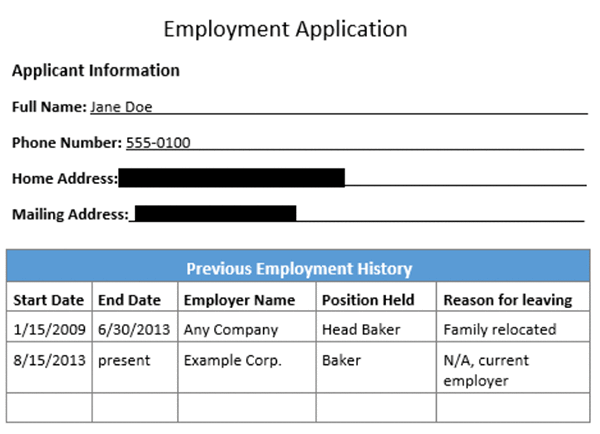
以下の画像は、フォームフィールドと表を伴う求人応募用紙です。
以下のコード例は、求人応募用紙からフォームを抽出し、異なるフィールドを処理する方法を示すものです。
import boto3
from trp import Document
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "employmentapp.png"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.analyze_document(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
},
FeatureTypes=["FORMS"])
#print(response)
doc = Document(response)
for page in doc.pages:
# Print fields
print("Fields:")
for field in page.form.fields:
print("Key: {}, Value: {}".format(field.key, field.value))
# Get field by key
print("\nGet Field by Key:")
key = "Phone Number:"
field = page.form.getFieldByKey(key)
if(field):
print("Key: {}, Value: {}".format(field.key, field.value))
# Search fields by key
print("\nSearch Fields:")
key = "address"
fields = page.form.searchFieldsByKey(key)
for field in fields:
print("Key: {}, Value: {}".format(field.key, field.value))
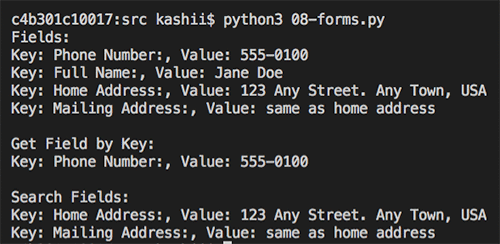
以下の画像は、検出された求人応募用紙のフォームの出力です。
ドキュメント編集によるコンプライアンス管理
Amazon Textract はデータタイプとフォームラベルを自動的に識別するため、AWS は情報管理のコンプライアンスを維持できるようにするためのインフラストラクチャのセキュア化に役立ちます。例えば、保険会社は請求書をアーカイブする前に、Amazon Textract を使用してレビュー用に個人識別情報 (PII) を自動で編集するワークフローを投入できます。Amazon Textract は保護を必要とする重要なフィールドを認識します。
以下のコード例は、先ほど使用した求人応募用紙のフォームフィールドをすべて抽出してから、すべての住所フィールドを編集します。
import boto3
from trp import Document
from PIL import Image, ImageDraw
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "employmentapp.png"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.analyze_document(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
},
FeatureTypes=["FORMS"])
#print(response)
doc = Document(response)
# Redact document
img = Image.open(documentName)
width, height = img.size
if(doc.pages):
page = doc.pages[0]
for field in page.form.fields:
if(field.key and field.value and "address" in field.key.text.lower()):
#if(field.key and field.value):
print("Redacting => Key: {}, Value: {}".format(field.key.text, field.value.text))
x1 = field.value.geometry.boundingBox.left*width
y1 = field.value.geometry.boundingBox.top*height-2
x2 = x1 + (field.value.geometry.boundingBox.width*width)+5
y2 = y1 + (field.value.geometry.boundingBox.height*height)+2
draw = ImageDraw.Draw(img)
draw.rectangle([x1, y1, x2, y2], fill="Black")
img.save("redacted-{}".format(documentName))
以下の画像は、編集されたバージョンの求人応募用紙の出力です。
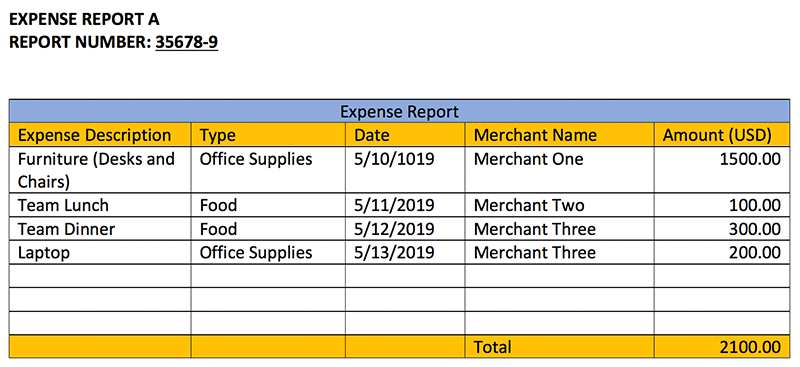
表の抽出と処理
Amazon Textract は、表とそのコンテンツを検出できます。会社は、経費報告書からすべての金額を抽出して、$1000 を超える経費には追加のレビューが必要といったルールを適用することができます。
以下のコード例は、経費報告書のサンプルドキュメントを使用して各セルのコンテンツを印刷し、経費のいずれかが $1000 を超える場合は警告メッセージを追加します。
import boto3
from trp import Document
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "expense.png"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.analyze_document(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
},
FeatureTypes=["TABLES"])
#print(response)
doc = Document(response)
def isFloat(input):
try:
float(input)
except ValueError:
return False
return True
warning = ""
for page in doc.pages:
# Print tables
for table in page.tables:
for r, row in enumerate(table.rows):
itemName = ""
for c, cell in enumerate(row.cells):
print("Table[{}][{}] = {}".format(r, c, cell.text))
if(c == 0):
itemName = cell.text
elif(c == 4 and isFloat(cell.text)):
value = float(cell.text)
if(value > 1000):
warning += "{} is greater than $1000.".format(itemName)
if(warning):
print("\nReview needed:\n====================\n" + warning)
以下のテキストは、テーブルセルとそれらの中にあるテキストの出力です。
Table[0][0] = Expense Description
Table[0][1] = Type
Table[0][2] = Date
Table[0][3] = Merchant Name
Table[0][4] = Amount (USD)
Table[1][0] = Furniture (Desks and Chairs)
Table[1][1] = Office Supplies
Table[1][2] = 5/10/1019
Table[1][3] = Merchant One
Table[1][4] = 1500.00
Table[2][0] = Team Lunch
Table[2][1] = Food
Table[2][2] = 5/11/2019
Table[2][3] = Merchant Two
Table[2][4] = 100.00
Table[3][0] = Team Dinner
Table[3][1] = Food
Table[3][2] = 5/12/2019
Table[3][3] = Merchant Three
Table[3][4] = 300.00
Table[4][0] = Laptop
Table[4][1] = Office Supplies
Table[4][2] = 5/13/2019
Table[4][3] = Merchant Three
Table[4][4] = 200.00
Table[5][0] =
Table[5][1] =
Table[5][2] =
Table[5][3] =
Table[5][4] =
Table[6][0] =
Table[6][1] =
Table[6][2] =
Table[6][3] =
Table[6][4] =
Table[7][0] =
Table[7][1] =
Table[7][2] =
Table[7][3] =
Table[7][4] =
Table[8][0] =
Table[8][1] =
Table[8][2] =
Table[8][3] = Total
Table[8][4] = 2100.00
Review needed:
====================
Furniture (Desks and Chairs) is greater than $1000.
PDF ドキュメントの処理 (非同期 API 操作)
これまでの例では、同期 API 操作で画像を使用しました。今度は、非同期 API 操作を使って PDF ファイルをどのように処理できるかを見てみましょう。
まず、StartDocumentTextDetection または StartDocumentAnalysis を使用して Amazon Textract ジョブを開始します。ジョブが完了したら、Amazon Textract が完了ステータスを含む Amazon Textract リクエストの結果を Amazon SNS にパブリッシュします。その後、GetDocumentTextDetection または GetDocumentAnalysis を使用して Amazon Textract から結果を取得できます。
以下のコード例は、ジョブを開始し、ジョブステータスを取得して、結果を処理する方法を示しています。サンプル PDF ドキュメントについては、こちらをクリックしてください。詳細については、「Calling Amazon Textract Asynchronous Operations」を参照してください。
import boto3
import time
def startJob(s3BucketName, objectName):
response = None
client = boto3.client('textract')
response = client.start_document_text_detection(
DocumentLocation={
'S3Object': {
'Bucket': s3BucketName,
'Name': objectName
}
})
return response["JobId"]
def isJobComplete(jobId):
# For production use cases, use SNS based notification
# Details at: https://docs.thinkwithwp.com/textract/latest/dg/api-async.html
time.sleep(5)
client = boto3.client('textract')
response = client.get_document_text_detection(JobId=jobId)
status = response["JobStatus"]
print("Job status: {}".format(status))
while(status == "IN_PROGRESS"):
time.sleep(5)
response = client.get_document_text_detection(JobId=jobId)
status = response["JobStatus"]
print("Job status: {}".format(status))
return status
def getJobResults(jobId):
pages = []
client = boto3.client('textract')
response = client.get_document_text_detection(JobId=jobId)
pages.append(response)
print("Resultset page recieved: {}".format(len(pages)))
nextToken = None
if('NextToken' in response):
nextToken = response['NextToken']
while(nextToken):
response = client.get_document_text_detection(JobId=jobId, NextToken=nextToken)
pages.append(response)
print("Resultset page recieved: {}".format(len(pages)))
nextToken = None
if('NextToken' in response):
nextToken = response['NextToken']
return pages
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "Amazon-Textract-Pdf.pdf"
jobId = startJob(s3BucketName, documentName)
print("Started job with id: {}".format(jobId))
if(isJobComplete(jobId)):
response = getJobResults(jobId)
#print(response)
# Print detected text
for resultPage in response:
for item in resultPage["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
以下の画像は、API コールが行われたときのジョブステータスを示しています。
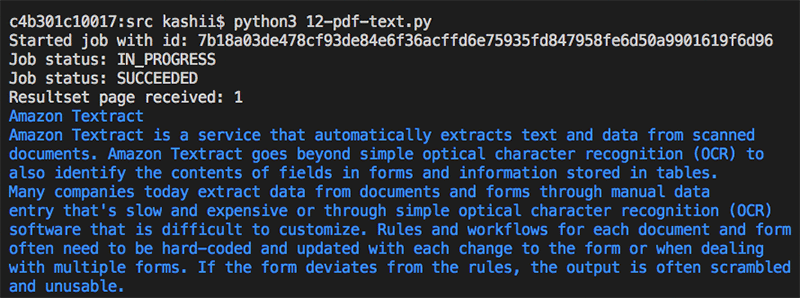
結論
この記事では、Amazon Textract を利用して、機械学習 (ML) の経験がなくてもスキャンされたドキュメントからテキストとデータを自動的に抽出する方法を説明しました。今回は金融、ヘルスケア、および HR などの分野におけるユースケースを取り上げましたが、非構造化ドキュメントからテキストとデータを解放する機能が非常に役立つ機会が他にもたくさんあります。Amazon Textract の詳細に関しては、単一ページと複数ページの処理に関するドキュメント、ブロックオブジェクトでの作業、およびコードサンプルについてお読みください。
Amazon Textract は、米国東部 (バージニア北部)、米国東部 (オハイオ)、米国西部 (オレゴン)、および欧州 (アイルランド) で今すぐご利用を開始していただけます。
著者について
 Kashif Imran はアマゾン ウェブ サービスのソリューションアーキテクトです。 Kashif は AWS における最大規模の戦略的なお客様数社と連携し、技術的なガイダンスと設計アドバイスを提供しています。また、同氏の専門知識は、アプリケーションアーキテクチャー、サーバーレス、コンテナ、NoSQL 、機械学習にまで多岐にわたります。
Kashif Imran はアマゾン ウェブ サービスのソリューションアーキテクトです。 Kashif は AWS における最大規模の戦略的なお客様数社と連携し、技術的なガイダンスと設計アドバイスを提供しています。また、同氏の専門知識は、アプリケーションアーキテクチャー、サーバーレス、コンテナ、NoSQL 、機械学習にまで多岐にわたります。