Amazon Web Services ブログ
Amazon Textractによるテーブル抽出機能の強化
(訳者注)Amazon Textract はブログ公開の時点では日本語に対応しておりませんのでご注意ください。
Amazon Textractは、あらゆる文書や画像からテキスト、手書き文字、データを自動的に抽出する機械学習(ML)サービスです。Amazon Textractには、あらゆるドキュメントから表構造を自動的に抽出する機能を提供するAnalyzeDocument API内のTables機能があります。この投稿では、Tables機能に加えられた改良点と、様々な文書からテーブル構造の情報を簡単に抽出する方法について説明します。
財務報告書、給与明細書、分析証明書ファイルなどの文書に含まれる表構造は、多くの場合、情報を容易に解釈できるようにフォーマットされています。また、読みやすく整理しやすいように、テーブルのタイトル、テーブルのフッター、セクションのタイトル、サマリー行などの情報が表構造内に含まれていることもよくあります。今回の機能強化以前では、同様の文書においてAnalyzeDocumentのTables機能はこれらの要素をセルとして識別し、テーブルの境界の外側に存在するタイトルやフッターを抽出しませんでした。そのためこのようなケースでは、それらの情報を識別したり、APIのJSON出力から個別に抽出したりするための後処理の仕組みをカスタムで用意する必要がありました。今回のテーブル機能の強化の発表により、表形式データの様々な側面の抽出がよりシンプルになります。
2023年4月、Amazon Textractは、Tables機能によってドキュメントに存在するタイトル、フッター、セクションタイトル、サマリー行を自動的に検出する機能を導入しました。この投稿では、これらの機能強化について説明し、ドキュメント処理のワークフローで理解し使用するのに役立つ例を紹介します。また、APIを使用し、Amazon Textract Textractorライブラリでレスポンスを処理するコードの例を通して、これらの改良を利用する方法を説明します。
ソリューション概要
次の画像は、更新されたモデルが、ドキュメント内のテーブルだけでなく、すべてのテーブルのヘッダーとフッターも識別していることを示しています。このサンプルの財務報告書には、テーブルのタイトル、フッター、セクションタイトル、サマリーが含まれています。
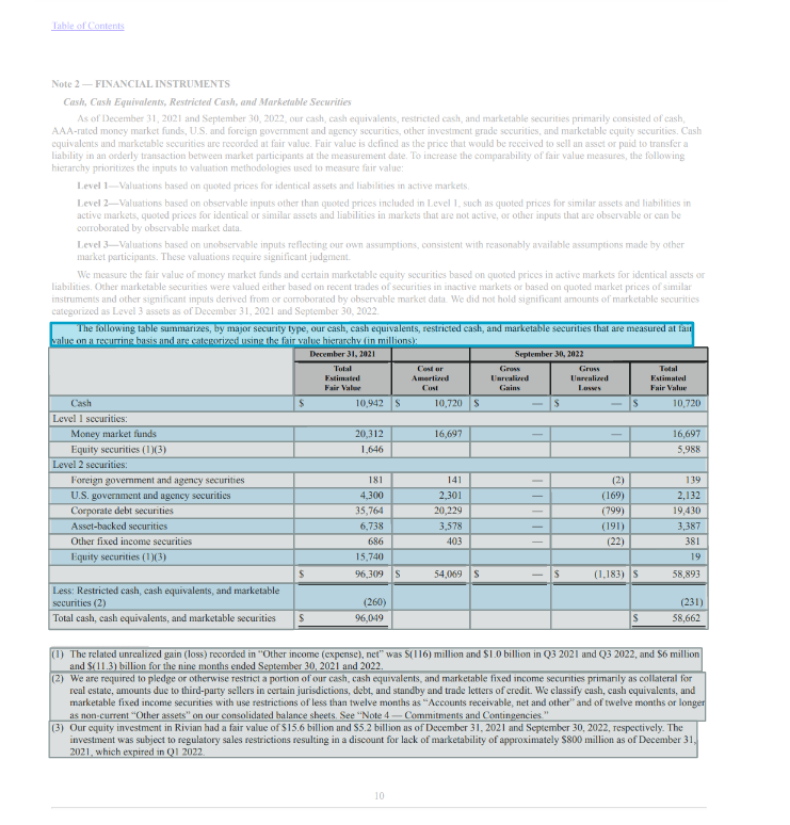
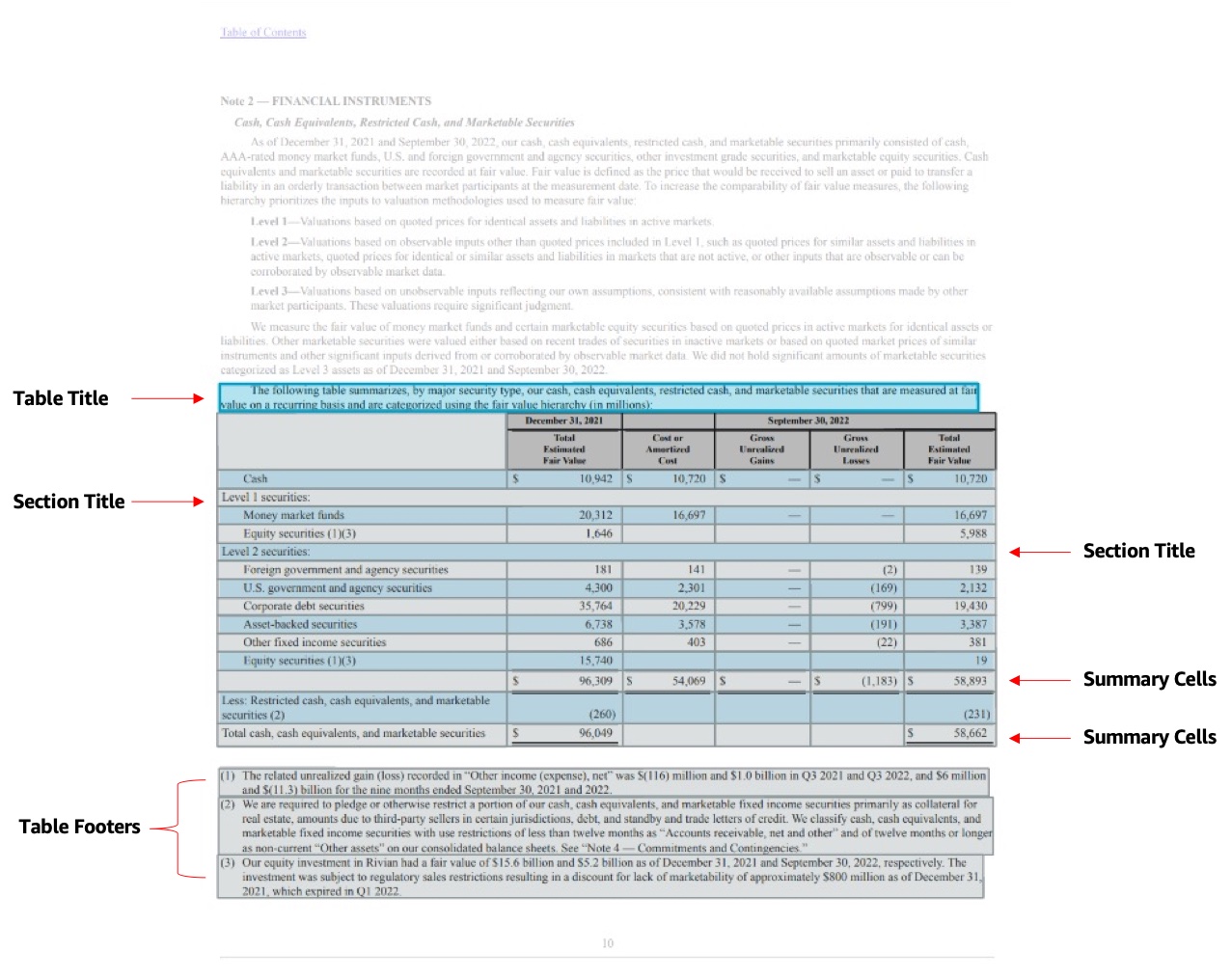
テーブル機能の強化により、APIレスポンスに4つの新しい要素が追加され、それぞれのテーブル要素を簡単に抽出できるようになり、さらにテーブルの種類を区別する機能も追加されました。
テーブル要素
Amazon Textractは、テーブルセルやマージセルなど、テーブルのいくつかのコンポーネントを識別することができます。Blockオブジェクトとして知られるこれらのコンポーネントは、境界ジオメトリ、関係性、信頼スコアなど、コンポーネントに関連する詳細を内包しています。Blockは、 文書内で互いに近接したピクセル群の中で認識される項目を表します。今回の機能強化で導入された新しいテーブルのBlocksを以下に示します:
- テーブルのタイトル –
TABLE_TITLEという新しいBlockタイプが追加され、指定したテーブルのタイトルを識別できるようになりました。タイトルは、1行または複数行にすることができ、通常、テーブルの上にあるか、テーブル内のセルとして埋め込まれています。 - テーブルのフッター –
TABLE_FOOTERという新しいBlockタイプが追加され、指定したテーブルのフッターを識別できるようになりました。フッターは、1行または複数行にすることができ、通常、テーブルの下にあるか、テーブル内のセルとして埋め込まれています。 - セクションタイトル –
TABLE_SECTION_TITLEという新しいBlockタイプが追加され、検出されたセルがセクションタイトルかどうかを識別できるようになりました。 - 要約セル –
TABLE_SUMMARYという新しいBlockタイプが追加され、検出されたセルが給与明細の合計のような要約セルかどうかを識別できるようになりました。
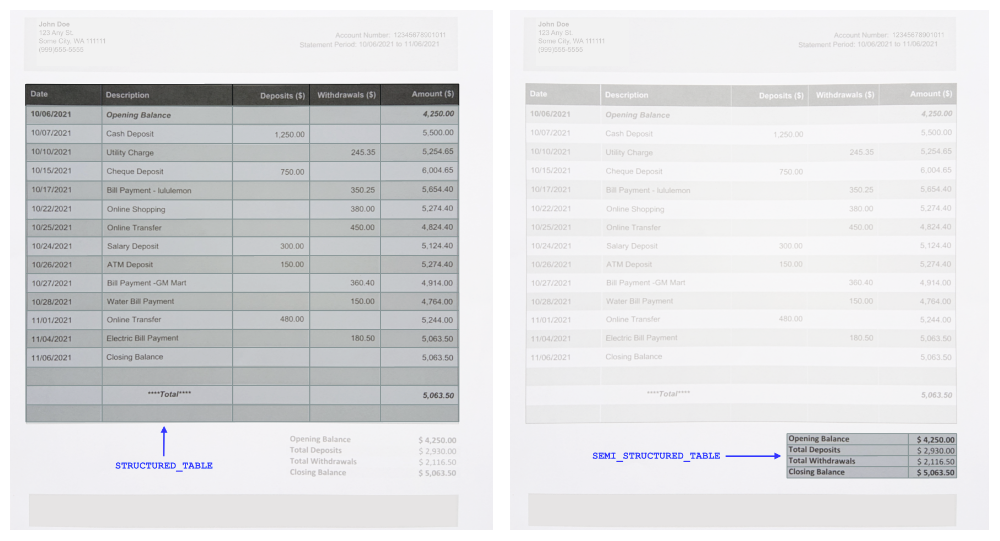
テーブルのタイプ
AmazonTextractは文書内のテーブルを特定すると、そのテーブルの詳細をすべてTABLEというトップレベルのBlockタイプに抽出します。テーブルにはさまざまな形や大きさがあります。たとえば、文書にはテーブルが含まれていることがよくありますが、そのテーブルにはテーブルヘッダーがあることもないこともあります。こうした種類のテーブルを区別しやすくするために、TABLE Blockに2種類の新しいエンティティタイプを追加しました:SEMI_STRUCTURED_TABLEとSTRUCTURED_TABLEです。これらのエンティティタイプは、構造化テーブルと半構造化テーブルを区別するのに役立ちます。
構造化テーブルとは、明確に定義された列ヘッダを持つテーブルです。しかし半構造化テーブルでは、データは厳密な構造に従っていない場合があります。たとえば、ヘッダーが定義されたテーブルではない表構造のデータです。新しいエンティティタイプは、後処理でどのテーブルを残すか削除するかを柔軟に選択できます。次の画像は、STRUCTURED_TABLEとSEMI_STRUCTURED_TABLEの例です。
APIの出力を分析する
このセクションでは、Tables機能強化によるAnalyzeDocumentのAPI出力を後処理するために、Amazon Textract Textractorライブラリを使用する方法を探ります。これにより、テーブルから関連する情報を抽出することができます。
Textractorは、Amazon TextractのAPIやユーティリティとシームレスに動作し、APIから返されたJSONレスポンスをプログラム可能なオブジェクトに変換するために作成されたライブラリです。また、ドキュメント上のエンティティを視覚化し、カンマ区切り値(CSV)ファイルなどの形式でデータをエクスポートするために使用することもできます。これは、Amazon Textractのお客様が後処理パイプラインを設定しやすくすることを目的としています。
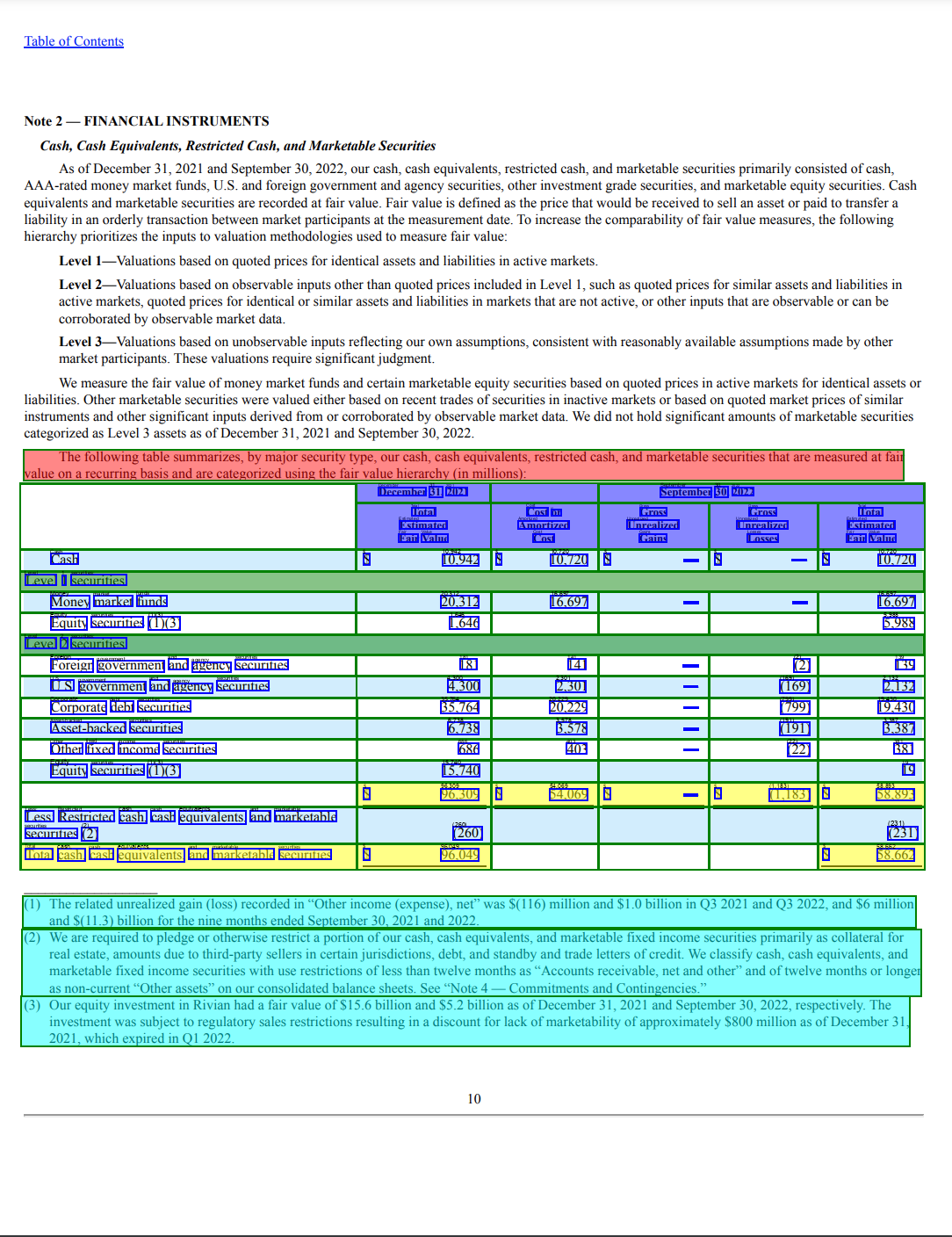
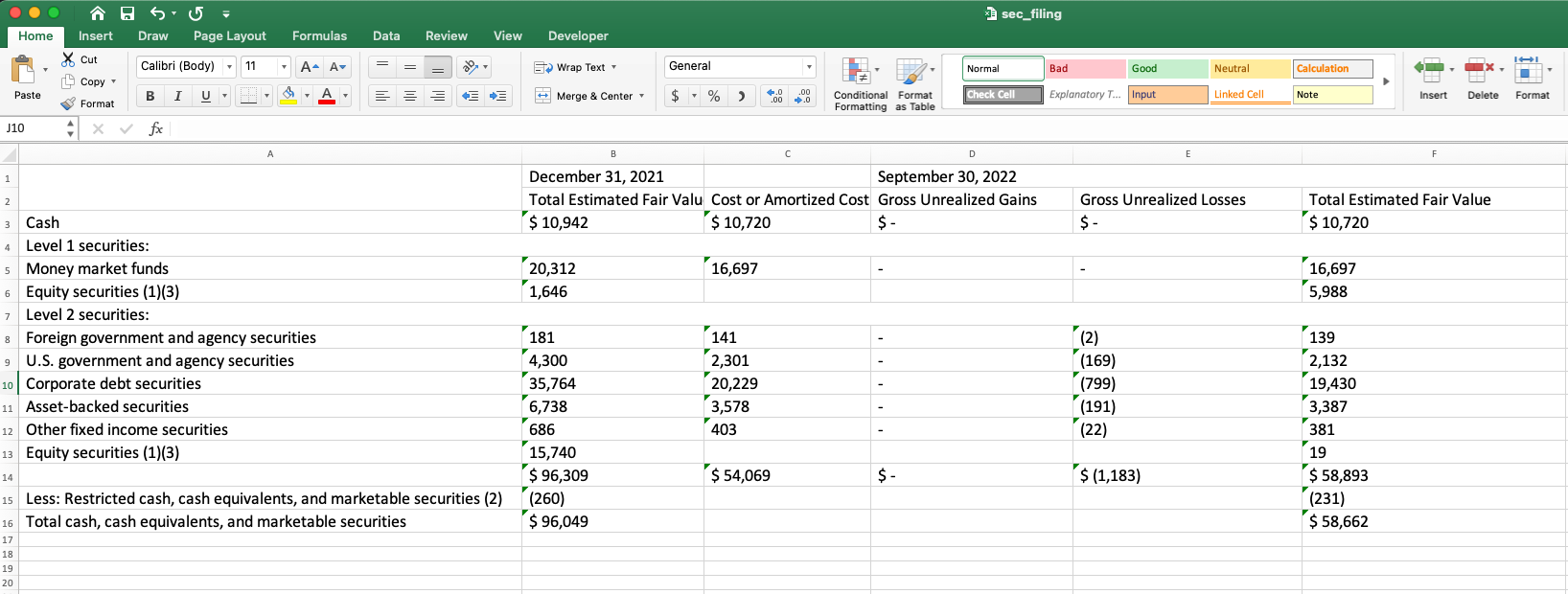
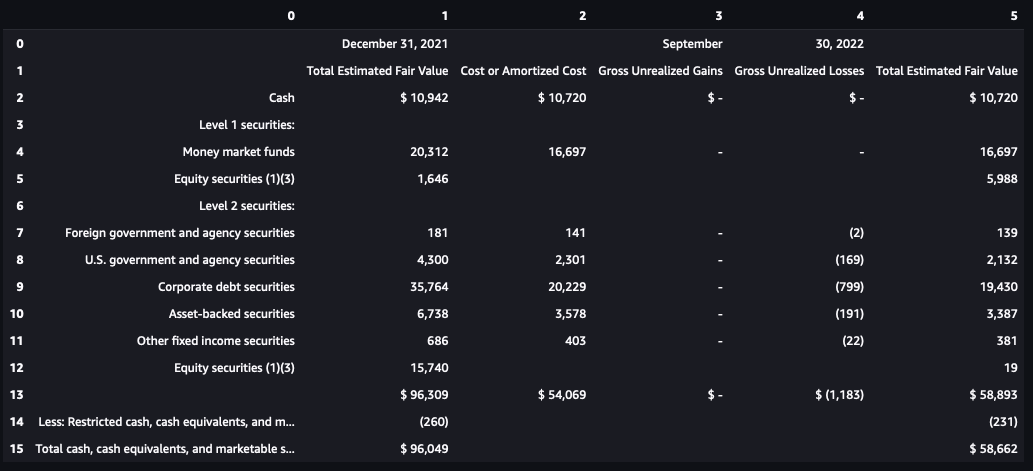
今回の例では、10-K SECファイリングドキュメントの次のサンプルページを使用しています。
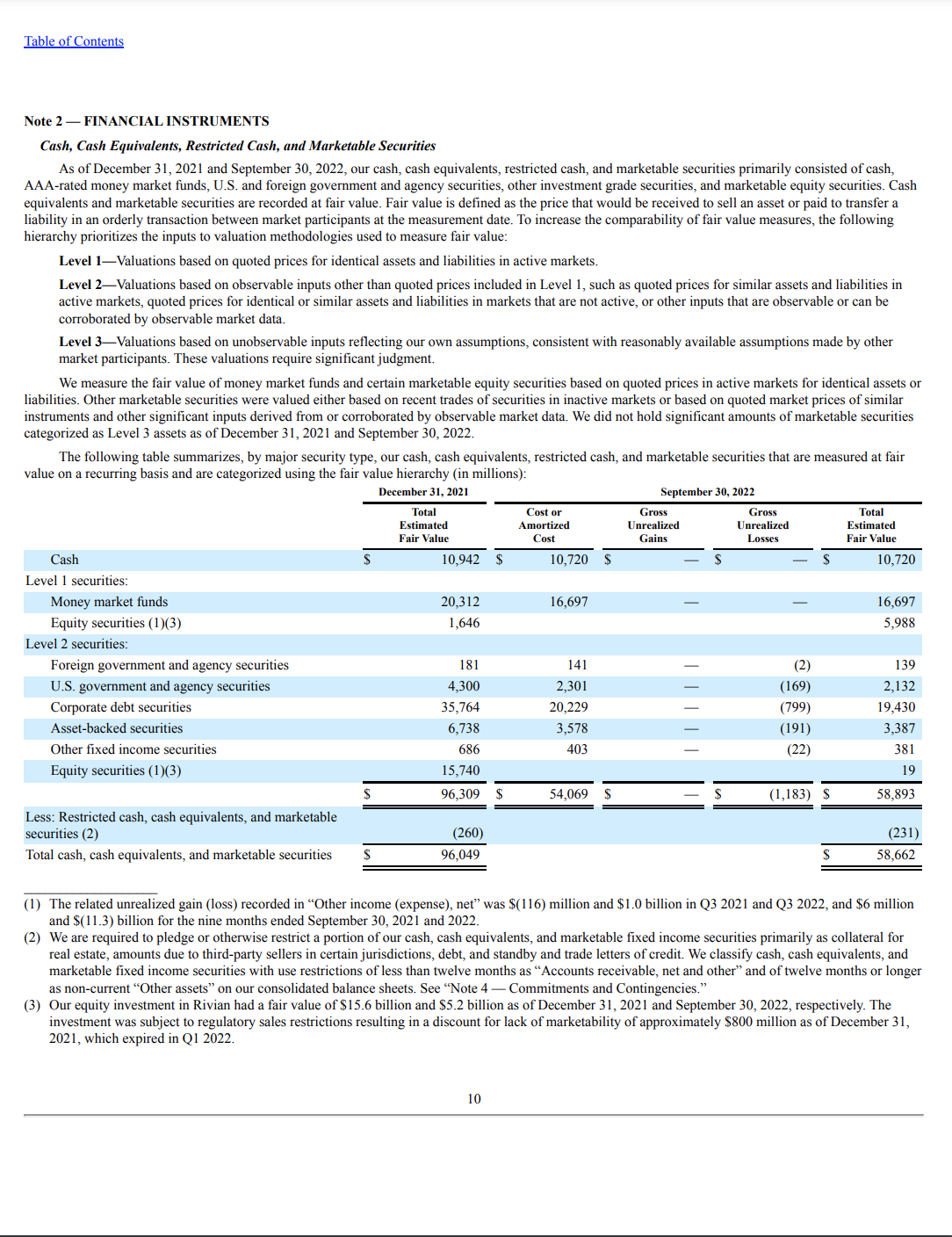
このあと出てくるコードはこちらのGitHubリポジトリで参照できます。このドキュメントを処理するために、Textractorライブラリを利用し、API出力を後処理してデータを可視化するためにインポートしています。
最初のステップは、テーブル情報を抽出するために、features=[TextractFeatures.TABLES]パラメータで示される Amazon TextractのテーブルのAnalyzeDocument 機能を呼び出すことです。このメソッドは、リアルタイム(または同期的)にAnalyzeDocument APIを呼び出し、それは単一ページのドキュメントを処理することに注意してください。しかし、非同期のStartDocumentAnalysis APIを使えば、複数ページ文書(最大3,000ページ)を処理することができます。
このdocumentオブジェクトには、確認可能なドキュメントに関するメタデータが含まれています。ドキュメント内の他のエンティティとともに、ドキュメント内の1つのテーブルを認識していることに注目してください。
結論
これらの新しいブロックとエンティティタイプ(TABLE_TITLE, TABLE_FOOTER, STRUCTURED_TABLE, SEMI_STRUCTURED_TABLE, TABLE_SECTION_TITLE, TABLE_FOOTER, TABLE_SUMMARY)の導入は、Amazon Textractによるドキュメントからの表構造の抽出の大きな進歩を意味します。
これらのツールは、構造化されたテーブルと半構造化されたテーブルの両方に対応し、ドキュメント内の位置に関係なく、重要なデータが見落とされないようにする、より繊細で柔軟なアプローチを提供します。
つまり、多様なデータタイプや表構造を、より高い効率性と正確さで扱えるようになったのです。ドキュメント処理のワークフローに自動化の力を取り入れ続ける中で、これらの機能強化が、より合理的なワークフロー、より高い生産性、より洞察力のあるデータ分析への道を開くことは間違いありません。AnalyzeDocumentとTables機能の詳細については、AnalyzeDocumentを参照してください。
翻訳はSolutions Architect 近藤が担当しました。原文はこちらです。