Amazon Web Services ブログ
Amazon EKS の包括的なオブザーバビリティを実現する AWS Observability Accelerator
この記事は Announcing AWS Observability Accelerator to configure comprehensive observability for Amazon EKS を翻訳したものです。
2022 年 5 月、Amazon EKS Observability Accelerator を発表しました。これは、Terraform モジュールを使用した Amazon Elastic Kubernetes Service (Amazon EKS) クラスタのオブザーバビリティソリューションを設定およびデプロイするためのツールです。 4 つのユースケースについて公開しており、このツールを使用することで可観測性を短期間で実現することができます。このソリューションを使用することで、 Amazon Managed Service for Prometheus 、 AWS Distro for OpenTelemetry (ADOT) 、 Amazon Managed Grafana を利用した アプリケーションの監視を 1 つのコマンド実行で開始することができます。 Amazon EKS Observability Accelerator という名前で公開していましたが、追加のオーケストレーションプラットフォームと機能をサポートするために、この度ツールの名前を AWS Observability Accelerator に変更します。
お客様から寄せられたフィードバックの 1 つに、 AWS Observability Accelerator を利用して既存の環境の可観測性の課題を解決したいというものがありました。このフィードバックには、 Amazon EKS クラスタで稼働するアプリケーションに関する主要なメトリクス ( 使用率、リソース利用限界、エラー ) の収集、 API サーバー 、 etcd などの Kubernetes コンポーネントの正常性の監視、そして最後にアプリケーションがホストされているインフラストラクチャを監視するといったことが含まれます。また、お客様からは、Prometheus Recording rules とAlert rules を Amazon Managed Service for Prometheus と統合することを求められました。さらに、 Amazon Managed Grafana ダッシュボードをすぐに利用できるようにして、さまざまなメトリクスを視覚化し、お客様が環境の全体像を把握できるようにしたいといったご要望もいただきました。
本日、 AWS Observability Accelerator の新しいサンプルを発表します。このサンプルでは、すぐに利用できる Amazon Managed Grafana のダッシュボード、AWS Distro for OpenTelemetry コレクターによって収集したメトリクスを Amazon Managed Service for Prometheus に保存する機能、Alert rules と Recording rules をデプロイするワンクリックソリューションを提供することで、オブザーバビリティの課題を簡素化します。このソリューションを実装することで、お客様は Amazon EKS クラスタのコンポーネント、アプリケーション、インフラストラクチャに関する洞察を得ることができます。このサンプルをご利用いただくことで、お客様は包括的なダッシュボード基盤を利用できるだけでなく、このソリューションを特定のニーズに合わせて柔軟にカスタマイズすることができます。
GitHubリポジトリ
以下の Github リポジトリから AWS Observability Accelerator ソリューションをダウンロードしてください。
https://github.com/aws-observability/terraform-aws-observability-accelerator
ソリューションチュートリアル
このチュートリアルでは既存の Amazon EKS クラスタと Amazon Managed Grafana ワークスペースを活用します。必ず手順 3 で説明した変数ファイルに、それぞれの変数を指定してください。既存の Amazon Managed Service for Prometheus ワークスペースを使用することもできますし、もしくはソリューションのデプロイによって新規で作成されるワークスペースをご利用いただくこともできます。
前提条件
ソリューションのデプロイに進む前に、前提条件を満たしていることを確認してください。
- Terraform インストール
- kubectl インストール
- AWS Command Line Interface (AWS CLI) version 2 インストール
- jq インストール
- AWS アカウントの作成
- AWS CLI での認証情報の設定
- Amazon Managed Grafana Workspace の作成
ソリューションをデプロイするには、terraform-aws-observability-accelerator リポジトリ を使用します。このリポジトリは、お客様が AWS のモニタリングサービスを使用して Amazon EKS クラスタのオブザーバビリティをより簡単かつ迅速に設定できるようにすることを目的とした Terraform モジュール集です。
Step1: リポジトリのクローン
まず、リポジトリをクローンします。
Step2: Grafana API Keyの生成
Terraform のサンプルをデプロイする前に、既存の Amazon Managed Grafana ワークスペースにログインして API キーを作成します。
以下の手順に従ってキーを作成します。
- SAML/SSO 認証情報を使用して Amazon Managed Grafana ワークスペースにログインします。
- 左側のコントロールパネルにカーソルを合わせ、ギアアイコンの下にある API keys タブを選択します。

図1. Amazon Managed Grafanaにプログラムでアクセスするための API キーの設定
次に、Amazon Managed Grafana API キーに管理者の役割を付与します。有効期間は 1 日とします。
- [New API key] を選択し、Key name に任意の値を入力し、Role は [Admin] を選択します。
- Time to LiveフィールドにAPI キーの有効期間を入力します。たとえば、1d を指定すると 1 日後にキーが期限切れになります。サポートされている単位は次のとおりです。s、m、h、d、w、M、y

図2: Amazon Managed Grafana APIキーへの管理者権限付与
- [Add] を選択します。
- API キーは次のステップで使用するので、コピーして安全に保管してください。

図3: Terraformモジュールでの利用に向けたAPIキーのコピー

図4: API キーのリストを示す API キー設定
次のステップでは、作成した API キーを使用するように Terraform 変数ファイルを設定します。
Step3: 環境の設定
次に、Terraform モジュールをデプロイするように環境を設定します。デプロイする前に、作成されるリソースを確認しましょう。
- Amazon Managed Service for Prometheus にメトリクスを取り込むための設定がされた AWS EKS Add-on for ADOT operator と ADOT collector
- Kubernetes ネイティブリソースの現在の状態に基づいて Prometheus 形式のメトリクスを生成する kube-state-metrics
- CPU 、メモリ、ディスクサイズなどのインフラストラクチャメトリクスを収集するNode_exporter
- Amazon Managed Service for Prometheus ワークスペース
- Amazon Managed Service for Prometheus ワークスペースの Recording rules と Alert rules
- Amazon Managed Service for Prometheus の Grafana データソース
- Amazon Managed Service for Prometheus によって収集されたメトリクスを表示する 5 つの Grafana ダッシュボードをデプロイする Amazon Managed Grafana ワークスペース (terraform 変数ファイルで指定) 内の Observability Accelerator ダッシュボードフォルダ
プロビジョニングされるリソースについて十分に理解できたので、既存の Amazon EKS クラスタと Amazon Managed Grafana ワークスペースを指定するように変数ファイルを設定しましょう。
Step4: Terraform モジュールのデプロイ
Terraform モジュールをデプロイするには、次の手順が必要です。
- Plan(Option): Terraform plan は実行計画を作成し、インフラストラクチャの変更をプレビューします
- Apply : Terraform がプランのアクションを実行し、環境を変更します
まず、terraform init コマンドを使用して作業ディレクトリを初期化します。
図5. Terraform モジュールの初期化
加えて、terraform validate コマンドを実行してディレクトリ内の設定ファイルを評価できます。
![]()
図6. terraform設定の評価
次に、terraform plan コマンドを実行して実行プランを作成します。これにより、Terraform インフラストラクチャの変更をプレビューできます。
plan コマンドだけでは提案された変更は実行されません。そのため、このコマンドを使用して変更を適用する前に提案された変更が期待どおりかどうかを確認したり、変更内容をチームと共有してより広範囲にレビューしたりできます。

図7. Terraform plan
最後に、terraform apply コマンドを実行してリソースをプロビジョニングします。完了するまでに約 10 分かかります。デプロイが成功すると、Amazon Managed Service for Prometheus コンソールに Recording rules が表示され、Amazon Managed Grafana コンソールでダッシュボードが作成されていることを確認できるはずです。

図8. Terraform モジュールのデプロイ
Terraform モジュールが正常に実行されたことを確認するには、Amazon Managed Service for Prometheus コンソールにアクセスし、「ルール管理」タブをクリックします。ご覧のとおり、ルールは正常に作成されています。

図9. Amazon Managed Service for Prometheus Workspace でのルール作成
さらに、Amazon Managed Grafana のダッシュボードセクションを調べて、Terraform モジュールで作成されたダッシュボードを見つけることができます。

図10. Amazon Managed Grafana ダッシュボード
次に、 Amazon EKS コンソールで 「アドオン」タブを見ると ADOT アドオンが作成されていることを確認しましょう。さらにAmazon EKS クラスタのデプロイメントについても、ADOT コレクター、Kube-State-Metrics 、node-exporter などのコンポーネントがクラスタに正常にデプロイされていることを確認できるはずです。これにより、Terraform モジュールが正常にデプロイされたことが確認されます。

図11. Amazon EKS クラスタで起動する Pod
Step6: Amazon Managed Grafana でのメトリクス可視化
AWS ADOT operator が収集したさまざまなメトリクスを視覚化するには、Amazon Managed Grafana ワークスペースにログインします。
- [Dashboards] を選択し、[Browse] を選択します

図12. Amazon Managed Grafana ダッシュボード全体像
- [Observability Accelerator Dashboards] フォルダを選択し、いくつかのダッシュボードを見てみましょう。
- 以下のダッシュボードは、Amazon EKS クラスタレベルでの CPU とメモリの使用状況を示しています。
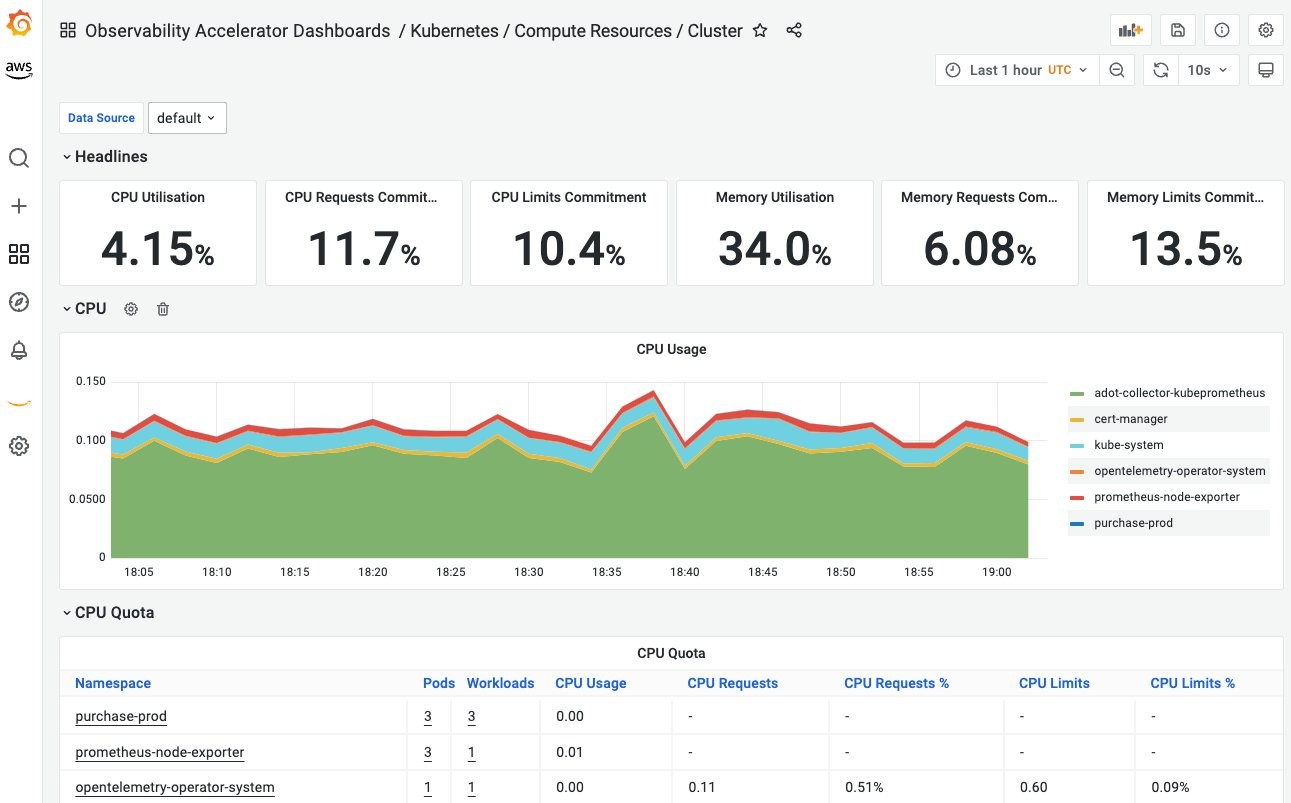
図13. Amazon EKS クラスタでの CPU およびメモリ使用
-
- 以下のダッシュボードは、Amazon EKS クラスタのワーカーノードによる使用率を示しています。

図14. ワーカーノードの CPU およびメモリ使用率
-
- 以下のダッシュボードは、Amazon EKS クラスタで設定された名前空間別のネットワーク使用率を示しています。
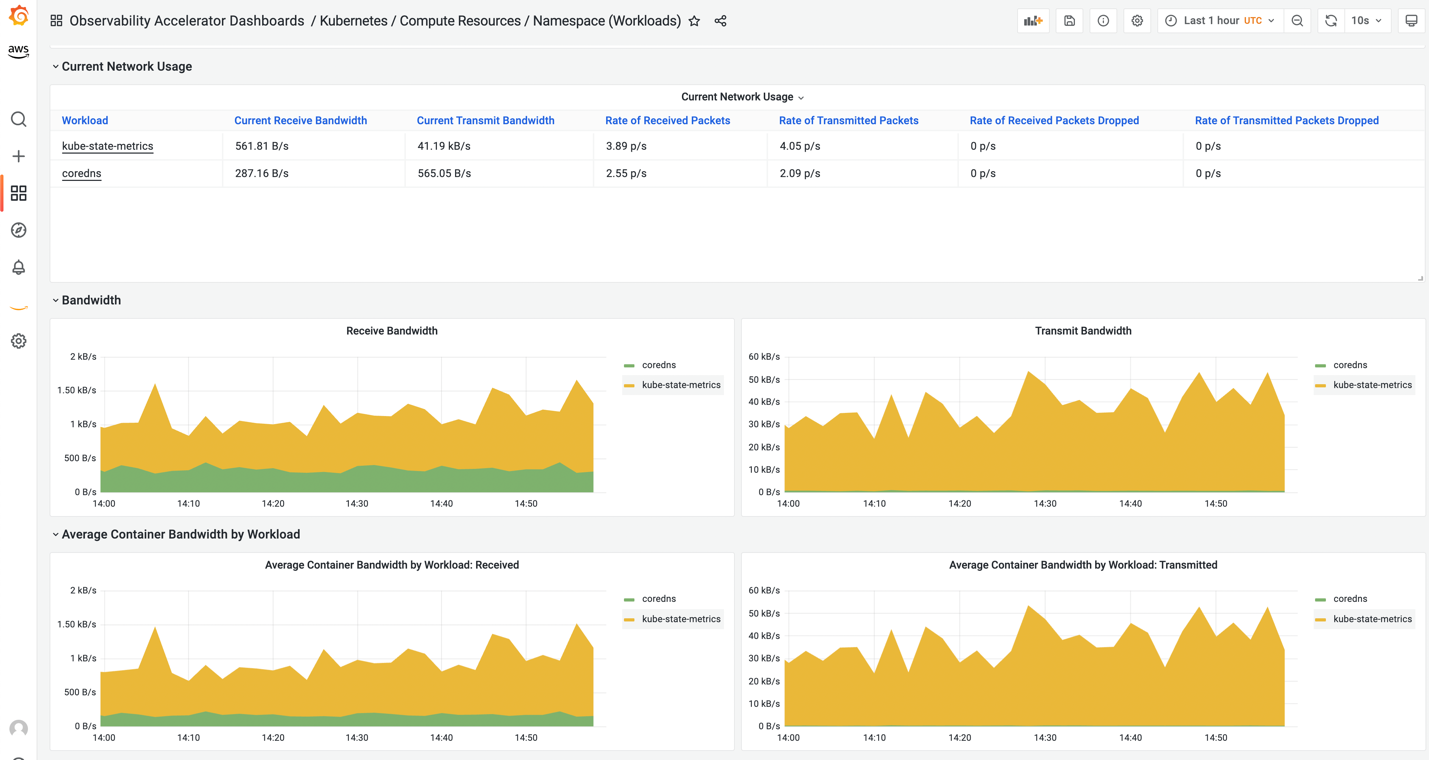
図15. 名前空間別ネットワーク使用率
名前空間フィルタを使用して別の名前空間を選択できます。たとえば、マルチテナント環境では、顧客は特定の名前空間で実行されているワークロードのパフォーマンスを分析できます。
-
- 下のダッシュボードには、Kubelet の情報と Kubelet の稼働率が表示されています
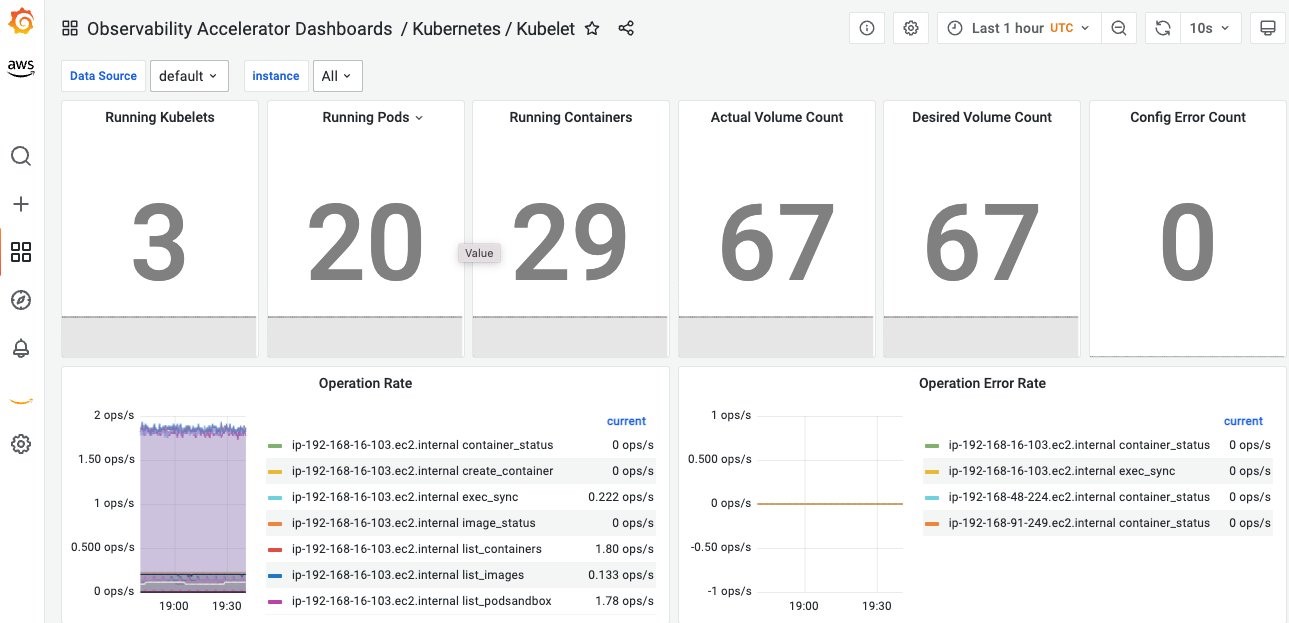
図16. Kubelet に関する情報
環境の削除
ここまでに作成したインフラストラクチャは、削除するまで費用が発生します。次のコマンドを使用して、作成した AWS リソースをクリーンアップします。
まとめ
Terraform 用 AWS Observability Accelerator は、お客様が Terraform 構成に統合してニーズに合わせてカスタマイズできる、柔軟な Terraform モジュールセットを使用しています。今後も他のタイプのワークロードをサポートするために、他のモジュールを追加していきます。お客様は AWS Observability Accelerator モジュールを活用して AWS Distro for OpenTelemetry をデプロイしてメトリクスを収集し、それらを安全かつスケーラブルな方法で Amazon Managed Service for Prometheus に保存し、 Amazon Managed Grafana ダッシュボードを使用してエンドツーエンドの Amazon EKS クラスタモニタリングを実現できます。
Next steps
AWS Observability Accelerator を公開できることを嬉しく思いますし、皆様からのフィードバックをお待ちしています。ロードマップには、 Amazon Managed Grafana の API キー設定の完全自動化など、さらに多くの機能があります。また、Amazon ECS のような他のオーケストレーションプラットフォームもサポートする予定です。今後予定されているすべての機能については、Github リポジトリの issues をご覧ください。また、バグ報告や新機能の提案、プルリクエストによる貢献もお待ちしております!
翻訳はソリューションアーキテクトの津郷が担当しました。原文はこちらです。