Amazon Web Services ブログ
Realtor.com が、AWS CloudTrail および Amazon QuickSight によって Amazon Athena の使用状況を監視する方法
これは、Realtor.com のスタッフデータエンジニアである Ajay Rathod 氏の寄稿です。
Realtor.com は、同社の説明によれば「Move、Inc. が運営する Realtor.com® は、住宅の購入者、売り手、いつか購入を夢見ている人にとって信頼できるリソースです。競合する全国のサイトの中で販売用物件に関する最も総合的なデータベース、情報、ツール、専門家の専門知識を提供し、人々が自宅を手に入れるまでのあらゆるステップを自信を持って進めるように支援します。」
Move, Inc. は、日付や時間で区分された数百万テラバイトのデータを処理します。さまざまなチームがこのデータに対して何百ものクエリを実行します。Move, Inc. は、AWS のサービスを利用して、データの収集および分析のためのインフラストラクチャを構築しました。
- データは、様々な情報源から取得します。
- Amazon Kinesis と AWS Data Pipeline を使用して Amazon S3 データレイクにデータをロードします。
- ストレージとその後のクエリの有効性を高めるために、データは Parquet 形式に変換され、再度 S3 に保存されます。
- Amazon Athena は、S3 のデータを照会する SQL (Structured Query Language) エンジンとして使用されます。Athena は使いやすく、多くの場合、さまざまなチームによって速やかに採用されます。
- チームは、Amazon QuickSight でクエリ結果を可視化します。Amazon QuickSight は、データを迅速かつ簡単に可視化したり、アカウント内の他のユーザーと共同作業を行うことがでるビジネス分析サービスです。
- データアクセスは、AWS Identity and Access Management (IAM) ロールによってコントロールされます。
このアーキテクチャはデータプラットフォームとして知られており、組織内のデータサイエンス、データエンジニアリング、データ運用の各チームによって共有されています。また、Move, Inc. では他の機能横断型チームも Athena を使用できます。多くのユーザーが Athena を使用する場合、使用状況を監視することが費用対効果を確保するのに役立ちます。このため、以下の詳細を示すことができる Athena メトリクスに対する必要性が強くなります。
- ユーザー
- スキャンされたデータの量 (AWS のサービス使用のコストを監視するため)
- クエリのために使用したデータベース
- チームが実行した実際のクエリ
現在、Move, Inc. のチームには、単一のツールからすべてのメトリクスを簡単に取得する方法はありません。これを行う方法があれば、監視作業は大幅に簡素化されます。たとえば、データ運用チームは、データ用に Athena で実行するクエリから取得した複数のメトリクスを毎日収集したいと考えています。以下のようなメトリクスが必要です。
- 各ユーザーがスキャンしたデータの量
- 各ユーザーのクエリ数
- 各ユーザーがアクセスしたデータベース
この記事では、Athena の使用状況を監視するためのソリューションを構築する方法について説明します。このソリューションを構築するには、AWS CloudTrail を使用します。CloudTrail は、AWS アカウントの AWS API コールを記録し、ログファイルを S3 バケットに配信するウェブサービスです。
ソリューション
高レベルでの概要は以下のとおりです。
- CloudTrail API を使用してユーザーのクエリを監査し、Athena を使用して CloudTrail ログからテーブルを作成します。
- AWS CLI を使用して Athena API を照会し、ユーザーのクエリによってスキャンされたデータに関するメトリクスを収集し、この情報を Athena の別のテーブルに配置します。
- 2 つのテーブルを結合して、これら 2 つのソースからの情報を結合します。
- 結果として得られたデータを分析し、洞察を構築し、組織内の異なるチームのユーザーによる Athena の使用状況を示すダッシュボードを作成します。
このソリューションのアーキテクチャを次の図に示します。
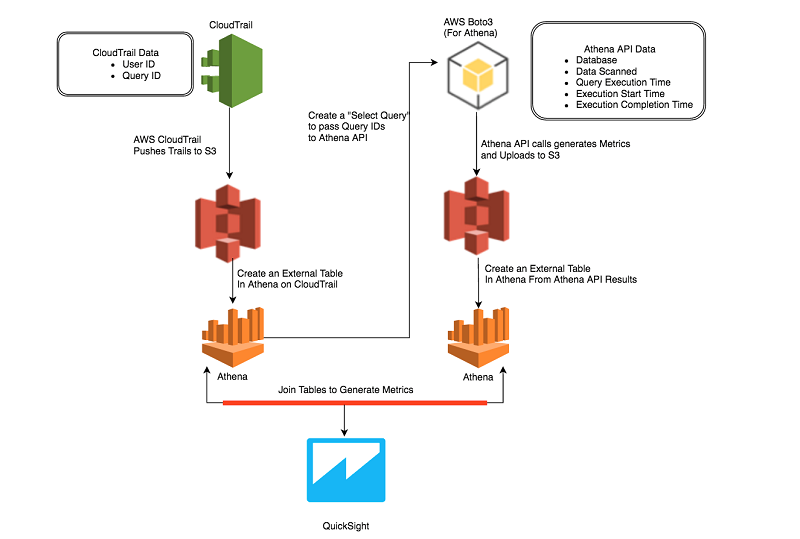
それでは、このソリューションを段階的に見てみましょう。
IAM と権限の設定
このソリューションは、CloudTrail、Athena、S3 を使用します。次のスクリプトと手順を実行するユーザーに、適切な IAM ロールとポリシーが設定されていることを確認します。詳細については、チュートリアル: Delegate Access Across AWS Accounts Using IAM Roles を参照してください。
ステップ 1: CloudTrail のデータ用に Athena でテーブルを作成する
CloudTrail API は、組織内のさまざまなチームが実行したすべての Athena クエリを記録します。これらのログは S3 に保存されます。最も関心があるフィールドは以下のとおりです。
- ユーザー ID
- API コールの開始時刻
- ソース IP アドレス
- リクエストパラメータ
- サービスから返されるレスポンスの要素
エンドユーザーが Athena でクエリを作成すると、これらのクエリは Athena ウェブサービスコールからのレスポンスとして CloudTrail によって記録されます。これらのレスポンスでは、各クエリは JSON (JavaScript Object Notation) 文字列として表されます。
以下の CREATE TABLE ステートメントを使用して、Athena で cloudtrail_logs テーブルを作成することができます。詳細については、Athena ドキュメントの Querying CloudTrail Logs を参照してください。
ステップ 2: API 出力からのデータ用に Amazon Athena にテーブルを作成する
Athena には、特定のクエリ ID の情報を取得するために照会できる API が用意されています。また、バッチサイズが最大 50 までのクエリ ID のバッチ情報を取得するための API も用意されています。
この API コールを使用して、関心がある Athena クエリについての情報を取得し、この情報を S3 の場所に保存することができます。S3 でこのデータを表す Athena テーブルを作成します。この記事の目的から、関心があるレスポンスフィールドは以下のとおりです。
- QueryExecutionId
- Database
- EngineExecutionTimeInMillis
- DataScannedInBytes
- Status
- SubmissionDateTime
- CompletionDateTime
athena_api_output の CREATE TABLE ステートメントは以下のとおりです。
最終日のクエリ ID とユーザー情報を調べることができます。クエリは、以下のとおりです。
ステップ 3: Athena API からクエリ統計を取得する
単純な Python スクリプトを作成して、50 のバッチでクエリをループさせ、クエリ統計のために Athena API を照会することができます。これらの検索では、Boto ライブラリを使用できます。Boto は、AWS の開発とやり取りして自動化する簡単な方法を提供するライブラリです。Boto API からのレスポンスを解析して、ステップ 2 で説明したように必要なフィールドを抽出することができます。
サンプルの Python スクリプトは、AthenaMetrics GitHub リポジトリにあります。
クエリ ID ごとに、これらのフィールドを CSV 文字列として書式設定し、バッチレスポンス全体に対して S3 バケットに保存します。この S3 バケットは、ステップ 2、cloudtrail_logs で作成したテーブルで表されます。
Python コードで、sql_query という名前の変数を作成し、ステップ 2 で定義した SQL クエリを表す文字列を割り当てます。s3_query_folder は、Athena がクエリの結果を保存するために使用する S3 内の場所です。コードは、以下のとおりです。
レスポンスオブジェクト内の結果を繰り返し処理し、50 の結果のバッチでそれらを統合することができます。それぞれのバッチについて、Athena API の batch-get-query-execution を呼び出すことができます。
ステップ 2 のテーブル athena_api_output の CREATE TABLE 定義が指す S3 の場所に出力を保存します。上記の SQL ステートメントは、過去 24 時間に実行されたクエリのみを返します。より長くすると、より長い期間にわたって使用量を得ることができます。この API コールのコードスニペットは以下のとおりです。
batchqueryids の値は、SELECT クエリの結果セットから抽出された 50 のクエリ ID の配列です。このスクリプトは、2 番目のテーブル athena_api_output に必要なデータを作成します。これで、Athena の両方のテーブルを結合する準備が整います。
ステップ 4: CloudTrail と Athena API のデータを結合する
これで 2 つのテーブルに必要なデータが用意されているので、次の Athena クエリを実行してユーザーごとの使用状況を確認することができます。このクエリの出力を最近 5 日間に制限することができます。
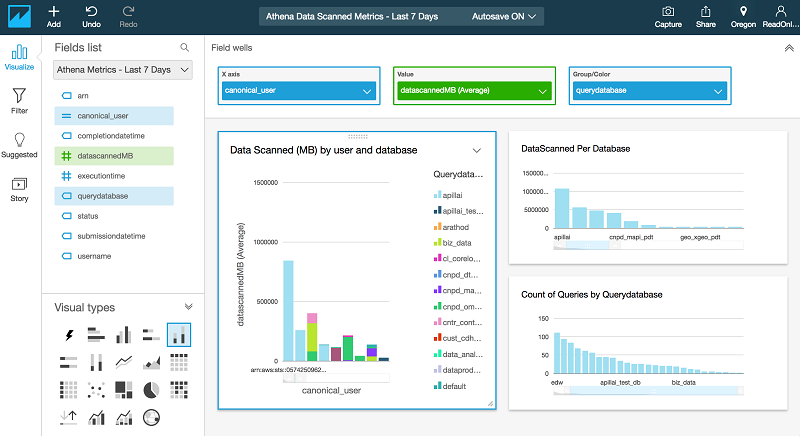
ステップ 5: 結果を分析し可視化する
このステップでは、QuickSight を使用して、以下のメトリクスを表示するダッシュボードを作成できます。
- ユーザーおよびデータベースによってスキャンされた平均データ量 (MB)
- ユーザーあたりのクエリ数
- データベースごとのクエリの数
詳細については、ダッシュボードの操作を参照してください。
結論
この記事で説明したソリューションを使用することで、さまざまなチームによる Athena の使用状況を継続的に監視できます。このステップをさらに進めると、指定した期間内にチームの Athena ユーザーが照会できるデータ量のユーザー制限を自動化および設定できます。また、特定のユーザーによる使用が指定したしきい値を超えたときに通知を追加することもできます。これにより、組織内のさまざまなチームが負担するコストを管理できます。
Realtor.com は、ビッグデータおよびアナリティクス担当のシニアコンサルタントである Hemant Borole が AWS プロフェッショナルサービスと共にこの記事の作成を支援してくれたことに深く感謝しています。
その他の参考資料
この記事が参考になった場合は、「Build a Schema-on-Read Analytics Pipeline Using Amazon Athena」および 「Query and Visualize AWS Cost and Usage Data Using Amazon Athena and Amazon QuickSight」もぜひご覧ください。
著者について

Ajay Rathod 氏は、Realtor.com のスタッフデータエンジニアです。 AWS クラウドプラットフォームとデータインフラストラクチャを深く理解している Ajay 氏は、Realtor.com のデータ運用のデータエンジニアリングと自動化の側面をリードしています。彼は、Data Pipeline、Athena、Batch、Glue、Boto3 などの AWS のサービスを使用して、Realtor Data Analytics Platform 用の多数の ETLパイプラインとワークフローを設計、デプロイしています。また、彼は ETL パイプラインとリソース使用状況を監視するためのさまざまな運用メトリクスも作成しています。