Amazon Web Services ブログ
SAP と Amazon Connect のデータを使用した Amazon Redshift レイクハウスアーキテクチャによる大規模な分析
ビジネス変革の第一歩として、SAP on AWSのお客様は、Amazon Web Services (AWS) プラットフォームの柔軟性、俊敏性、拡張性およびビジネスクリティカルなSAPワークロードを稼働するためのSAP認定済みオファリングの一式を好んでいます。Madrileña Red de Gas (MRG)のような私たちのお客様の多くにとって、最も直接的な利点はAWSクラウドで得られる柔軟性であり、SAPインフラストラクチャのコスト削減です。 しかし、お客様を最も鼓舞するものは、ビッグデータ、機械学習、サーバレスアーキテクチャ、オムニチャネルクラウドベースのAmazon Connect コンタクトセンターの分野でAWSが提供する幅広い技術です。Amazon Connect コンタクトセンターにより、イノベーションの障壁を下げ、日々の運用を継続的に改善する費用対効果の高いコールセンターツールを実行できます。詳細は、MRGの事例を参照してください。
進化するクラウド機能が多くの企業のシステムとITランドスケープを変革しており、ビジネス変革においては、データサイロを解消するための堅実なデータと分析プラットフォームの実装が一般的に優先されます。変革の旅路の一環として、お客様は組織内の様々なソースからデータを収集し、情報に基づいた意思決定と革新を実現するために、様々なビジネスイベントに関する「単一バージョンの真実」を提供できる複雑なレポーティング機能を作成する必要があります。
このブログでは、SAPデータと非SAPアプリケーションデータを統合してカスタマーサービスへの問い合わせの頻度をより正確に把握するためのデータと分析プラットフォームの実装方法を紹介します。アプリケーションレベルの抽出でSAP Data Servicesを使い、SAPの受注伝票データをデータウェアであるAmazon Redshiftに取り込み、 Amazon Simple Storage Service (Amazon S3)に保存されたAmazon Connectのデータセットを用いてカスタマーサービスへの問い合わせ頻度を分析し、そしてサービスへの問い合わせデータの変換とAmazon Redshiftへの格納にAWS Glueを使用する方法をみていきましょう。レポーティング層には、受注伝票タイプごとにカスタマーサービスの頻度をフィルターする用途でAmazon QuickSightとSAP Analytics Cloudを使用します。
Amazon Redshiftを使用した一元的なレイクハウスアーキテクチャ

図 1: SAP Data Servicesを使用したAmazon Redshiftへのデータ抽出
このブログでは、プロバイダーとサブスクライバーのモデルによってSAPアプリケーション間およびSAPと非SAPをデータターゲットとしたデータ複製機能を有効にするフレームワークであるSAP Operational Data Provisioning (ODP)を使用します。SAPをソースとして開始し、関連する手順を確認していきましょう。
注: デモンストレーションとテストを目的としたSAPデータの作成。SAP NetWeaver Enterprise Procurement Model (EPM)のドキュメントを参照してください。
前提条件
このチュートリアルでは、次の前提条件が必要です。
- Amazon Redshift、Amazon S3、AWS Glue、Amazon QuickSightを構成するために必要な権限を持ったAWSアカウント
- SAP ECCまたはSAP S/4HANAシステムのいずれかでソースデータを作成する機能
- データの統合と変換を構成するためにSAP Data Servicesで必要とする権限
- 後処理分析の演習のために、Amazon S3からサンプルの問い合わせ追跡レコード (CTR) JSONデータのモデルをダウンロード
SAPエクストラクタの作成
- SAPにログインして、SAPトランザクションRSO2から、SAP受注伝票テーブルの汎用データソースを作成します。
- エクストラクタの名前 (例: ZSEPM_SALES)を入力し、”作成”をクリックします。
- 次の画面で、アプリケーションコンポーネントとして”New_Hire_Root”を選択し、説明欄を任意の文章で更新します。
- ビュー/テーブル項目にデータソースとしてテーブル”SEPM_SDDL_SO_JOI”を入力し、受注伝票ヘッダと品目詳細を抽出します。
- メニューの”Generic Delta”をクリックし、変更済みレコードをフィルターするための箇所で”CHANGED_AT”を選択します。初期ロード以降の差分または変更済みレコードの抽出を行い、”保存”をクリックします。
- メニューの”Data-Source Test Extraction”オプションを使用してデータソースを確認してください。
SAP Data Servicesでソースデータストアの作成
- SAP Data Services Designerのアプリケーションメニューから”新規”を選択して新しいプロジェクトを作成し、プロジェクトに任意の名前を付けます。
- Data Servicesのオブジェクトライブラリーから、ドロップダウンメニューでSAPアプリケーションとしてソースデータストアとデータストアタイプに任意の名前を付けて新しいデータストアを作成します。
- 詳細設定タブでSAPアプリケーションサーバ名とログイン認証情報を入力し、SAPクライアントを更新して、”OK”をクリックします。
- 新しいデータストアのODPオブジェクトから”名前でインポート”を右クリックして、SAPで作成したデータソース”ZSEPM_SALES”をインポートします。
- “次へ”をクリックして、手順1で作成したプロジェクトにプロジェクト名を割り当てます。
- “Changed-data capture (CDC)”オプションを選択し、フィールド名は空白のままにして、”インポート”をクリックしてSAP ODPオブジェクトをデータストアにインポートします。
ソースデータストアとしてSAP Landscape Transformation (SLT) Replication Serverベースのエクストラクタも使用できます。SLTベースのデータソースの構成については、ほぼリアルタイムなレプリケーションのためのSAP Data ServicesとSAP LT Serverのブログを参照してください。
Redshift テーブルの作成
- 以下のDDLスクリプトを使用して、RedshiftのクエリエディタやSQLクライアントからRedshiftのターゲットテーブルを作成します。Amazon Redshift クラスタを構成するには、Amazon Redshiftのドキュメントを参照してください。
SAP Data Servicesでターゲットデータストアの作成
- Data Servicesのオブジェクトライブラリーから、ターゲットデータストアに任意の名前をつけた新しいデータストアを作成し、データストアタイプに”Amazon Redshift”を選択します。
- Redshift クラスタに接続するためのODBC接続設定をクリックします。
- データソース名から、ODBC管理機能をクリックし、システムDSNの下にある構成オプションをクリックします。
- 認証タイプ標準として、Amazon Redshift Server、ポート、データベース名、ユーザー認証情報を入力します。”テスト”をクリックして接続を検証します。それから”OK”をクリックします。
- ターゲットデータストア用に作成した新しいデータソース名を選択し、”OK”をクリックします。
- 新しいデータストアから、右クリックして”名前でインポート”オプションを選択し、Amazon Redshift データベーステーブルの定義をインポートします。
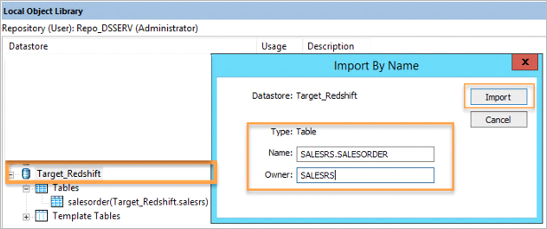
図 2: ターゲットデータベーステーブルをインポート
SAP Data Servicesでデータフローの作成
- SAP Data Servicesのプロジェクト領域で右クリックして、任意のジョブ名で”新しいバッチジョブ”を作成します。
- 作成した新しいジョブをクリックし、SAP Data Servicesのパレットからデータフローオプションをドラッグして、任意のデータフロー名を付けて新しいデータフローを作成します。

図 3: データフローを作成
SAP Data Servicesdeでワークフローの構成
- 前の手順で作成したデータフローをクリックして、データフローワークスペースにアクセスします。
- データストアからソースのODPデータソース (例: ZSEPM_SALES)をドラッグアンドドロップしてワークフローを作成します。
- 変換タブからデータフローワークスペースにクエリオブジェクトをドラッグし、ODPオブジェクトに接続します。
- データフローワークスペースにクエリオブジェクトのターゲットのRedshift SalesOrder データストアテーブルをドラッグし、オブジェクトに接続します。
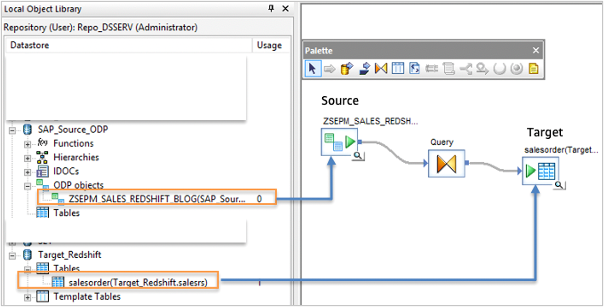
図 4: ソースとターゲットのデータストアを設定
Amazon Redshiftにデータの取り込み
- ワークフローでソースデータストアをダブルクリックし、初期ロードのために”Initial load”を”Yes”に設定します。
- クエリ変換をクリックし、”Map to Output”オプションを使用してソース欄とターゲット欄をマッピングします。
- これで受注伝票ジョブを実行してAmazon Redshiftにデータを取り込むことができ、ターゲットのRedshift データベースに格納したデータを確認できます。
オプションの変換
クエリ変換を使用して、ターゲットへの道筋の途中でデータを変換できます。ここでは、正規表現を追加して、Amazon Redshift ターゲットに取り込む前にデータセット内の特殊文字を削除します。例: HEADER_NOTE_TEXTの特殊文字を削除するために、正規表現関数 regex_replace(<input_string/column_name>, ‘\[^a-z0-9\]’, ”, ‘CASE_INSENSITIVE’)を使用できます。
変換に追加するには、クエリ変換を選択して、スキーマ出力のセクションで‘item_note_text’を選択します。 マッピングタブで、以下の正規表現関数を追加します。
regex_replace(ZSEPM_SALESORDER_S4HANATOREDSHIFT.HEADER_NOTE_TEXT, '\[^a-z0-9\]', '', 'CASE_INSENSITIVE')

図 5: Header_Textから特殊文字を削除
SAP Data Servicesを使用したChange Data Capture (CDC)
ソースとターゲット両方を基にしたCDCは、データベース用途においてSAP Data Servicesでサポートされています。CDCのオプションについては、SAPのドキュメントを参照してください。
注: SAP Data Servicesは、基盤となるSAPテーブルにアクセスするためのソースとして、SAPからのSAPデータベースレベルの抽出もまたサポートしています。ネイティブのODBCデータソースを構成するには、SAPのドキュメントを参照してください。
Amazon RedshiftにデータをストリーミングするためのAmazon Connectの設定
Amazon ConnectをAmazon Kinesisと統合して、問い合わせ追跡レコード (CTR)をAmazon Redshiftにストリーミングできます。Amazon Connectのデータ統合と設定については、Amazon Connect クイックスタートのドキュメントを参照してください。また、Amazon Connect 管理者ガイドを参照して、問い合わせ追跡レコード (CTR) データモデルを確認してください。問い合わせ追跡レコードをAmazon Redshiftに取り込んで、このデータをSAPソースシステムから複製した受注伝票詳細と結合できます。
問い合わせフローの問い合わせ属性を使用して、任意のキーと値のペアをCTRに追加できます。問い合わせ属性”SAPOrder”を使用して、SalesOrderIdをキーと値のペアとしてCTRに追加します。問い合わせ属性を使用してカスタマーエクスペリエンスをパーソナライズする方法は、Amazon Connect 管理者ガイドを参照してください。この例では、Amazon ConnectのデータとSAPの受注伝票をリンクするために、”SalesOrderId”を使用します。
CTR JSONデータ
この記事では、カスタム属性を持った既に作成済みの、S3ロケーションから利用可能なこのJSONデータを使用します。これは、エージェントがOrderIdに関連した照会を行うために追加したカスタム属性”SAPOrder”を持つAmazon Connect ワークフローからのJSONデータセットです。
このデータを使用して、SAPソースシステムから抽出したSAP注文をリンクし、注文の問い合わせを分析できます。
CTRデータのクロールによるGlue カタログの作成
- サンプルのCTR JSONファイルをお客様AWSアカウントのAmazon S3 バケットにアップロードします。
- AWSコンソールでAWS Glueを開き、”クローラ”と”クローラの追加”を選択して新しいクローラを作成します。

図 6: AWS Glue クローラを追加
AWS Glueでデータストアの追加
- クローラには任意の名前を使用できます。この例では、クローラ名としてamznconnectsaplinkを使用し、次の2つの画面で”次へ”を選択します。
- “データストアの追加”画面で、Amazon Connect CTRファイルをアップロードしたAmazon S3 バケット名を入力または選択し、”次へ”を選択します。

図 7: ソースS3バケットパスを指定
AWS Glue クローラの実行
- “他のデータストアの追加”で”いいえ”を選択し、”次へ”を選択します。
- “IAMロールの作成”、”AWSGlueServiceRole-ConnectSAP”を選択し、IAMロールの名前を入力して、”次へ”を選択します。
- 頻度に”オンデマンドで実行”を選択して、”次へ”を選択します。
- “データベースの追加”オプションを選択し、Glue カタログテーブルを作成したい任意のデータベース名を入力します。この例では、amazonconnectと入力します。
- “完了”をクリックします。
- 作成したばかりの新しいクローラが表示されます。”クローラ”を選択して、”クローラの実行”オプションをクリックしてください。
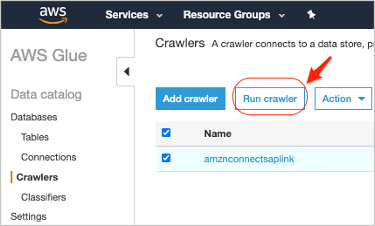
図 8: Glue クローラを実行
クローラの実行が完了すると、Glue データベースにテーブルamznconnectsapordlinkが表示されます。
Amazon Redshiftでのデータモデリング
Amazon Redshiftは、列指向ストア、超並列処理 (MPP)のデータウェアハウスサービスで、高度にスケーラブルな分析ソリューションを実装できるよう、データレイクとの統合を提供しています。
SAP HANAの計算ビューのように、Amazon Redshift データベースビューを作成して、テーブルを組み合わせたビジネスロジックを構築できます。Redshiftは、この機能をマテリアライズドビューに拡張します。クエリの事前計算結果を保存し、ソーステーブルに加えられた最新の変更を増分的に処理することで効率的に維持できます。マテリアライズドビューで実行されるクエリは、非常に高速に処理するために事前計算結果を用います。
- 新しいAmazon Redshift クラスタを作成します。クラスタを作成する手順は、Amazon Redshiftのドキュメントを参照してください。
- Redshift クラスタにアタッチするAWS IAMロールにAamzon S3とAWS Glueにアクセスするための読み取りと書き込みのIAMポリシーが付与されていることを確認します。注: Amazon S3は、Amazon RedshiftからAmazon S3へのデータのエクスポートを許可する必要があります。AWSGlueConsoleFullAccessは、Glueカタログを作成し、Amazon Redshift Spectrumを使用したCTRデータのクエリを有効にするために必要です。
- クエリエディタを使用するために、Amazon Redshiftにログインします。今回の場合、DBeaverのようなSQLクライアントツールを使用することもできます。SQLクライアントツールとAmazon Redshift間の接続を設定するには、Amazon Redshiftのドキュメントを参照してください。
- 以下のコードスニペットから外部スキーマを作成するステートメントを実行します。前の手順で作成した適切なAWS Glue データカタログデータベースとIAMロールARNを使用します。
- S3にあるAmazon Connect CTRデータを指すAmazon Redshift データベースの新しい外部スキーマと外部テーブルを確認してください。
統合ビューのためのデータ統合
- 以下のコードスニペットからクエリを実行して、Data Servicesで取り込んだSAP受注伝票データとS3にあるAmazon Connect CTRデータを組み合わせ、問い合わせ開始のタイムスタンプの変換を追加し、ディメンションに週、月、年、曜日を追加し、アドホックな分析を有効にします。
注: 以下のコードスニペットからクエリを実行して、視覚化に必要なデータを含むビューを作成できます。このクエリは、このビューの性能を向上するためにマテリアライズドビューとして作成することもできます。Amazon Redshiftでマテリアライズドビューを作成するには、Amazon Redshiftのドキュメントを参照してください。
データ出力の検証
以下のコードスニペットからクエリを実行をして、分析用のデータ出力を確認してください。
a. 通話の頻度と時間が最も多いトップ10の購入者
a. より多くの問い合わせを引き起こした製品
Amazon QuickSightを使用した視覚化
- AWSマネジメントコンソールからAmazon QuickSightにログインします。
- データセットを選択し、新しいデータセットを作成します。
- データソースに任意の名前を入力します。
- Amazon RedshiftのインスタンスIDを選択し、データベース名、ユーザー名、パスワードを入力します。
- データソースの作成を選択します。
- 前に作成したAmazon Redshiftのスキーマ (例: sapsales)を選択します。
- 前の手順で作成したRedshift テーブル (例: orderenuiryanalytics)を選択します。
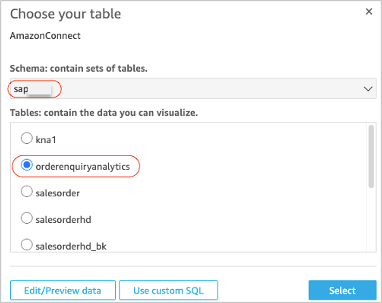
図 9: QuickSightでAmazon Redshift スキーマを選択
視覚化の設定
- “データを直接クエリする”を選択し、”視覚化”をクリックします。
- 視覚化の画面で、”+追加”を選択し、画面の左上にある”ビジュアルの追加”を複数回クリックして、4つのビジュアル要素を作成します。
- 1つ目のビジュアルタイプとして、”垂直棒グラフ“を選択します。フィールドリストから、y軸にaidurを、x軸にbuyer_nameを選択します。
- 2つ目のビジュアルは、ビジュアルタイプに”円グラフ“を選択し、aidurとmonthを選択します。
- 3つ目のビジュアルは、ビジュアルタイプに”水平棒グラフ“を選択し、x軸にaidurを、y軸にitem_product_idを選択します。
- 4つ目のビジュアルは、”散布図“を選択し、x軸にdowを、y軸にaidurを選択します。
- 最後に、以下に示すような視覚化が表示されます。

図 10: Amazon QuickSight ダッシュボード
SAP HANA Studioを使用したモデリング
モデリングおよびフロントエンドツールの選択肢にSAP HANA StudioまたはSAP Analytics Cloudを使用したい場合、Smart Data Access (SDA)によりAmazon Redshiftに接続できます。Amazon Redshiftのビューまたはマテリアライズドビューには、Simba Connectorを使用してSAP HANA Studioからアクセスできます。SDAの詳細は、SAP HANA Smart Data Accessに関するSAPのドキュメントを参照してください。

図 11: SAP HANAにリモートデータソースを追加
SAP Analytics Cloudを使用した統合データの視覚化
アンロードコマンドを使用して、SAP Analytics Cloud (SAC)での可視化用のCSVファイルとしてRedshiftのクエリ結果をAmazon S3 バケットに保存することができます。アンロードの例は、Amazon Redshiftのドキュメントを参照してください。

図 12: Amazon S3データを使用したSAP Analytics Cloudの視覚化
注: SACのレポーティング層を使用して、APOS Live Data GatewayによるAmazon Redshiftとの接続も可能です。
サマリー
企業は、ビジネスパフォーマンスを追跡および最適化するために、ますますデータレイクに向かっています。このブログでは、データ抽出にSAP Data Servicesを、Amazon ConnectとSAPの両方のデータを統合ビューとして提供するデータウェアハウスとしてAmazon Redshiftを使い、顧客のインサイトを深めるためにSAPと非SAPのデータを統合するデータレイクの確立方法を紹介しました。
開始するには、thinkwithwp.com/redshiftを訪問してください。SAP on AWSでの稼働の詳細を知りたいなら、thinkwithwp.com/ sapを訪問してください。
翻訳は、Partner SA 河原が担当しました。原文はこちらです。