Amazon Web Services ブログ
Amazon Forecast コールドスタート予測で実績データがない商品の予測精度が45%向上
この記事はGenerate cold start forecasts for products with no historical data using Amazon Forecast, now up to 45% more accurateを翻訳したものです。
Amazon Forecastを利用することで、過去の履歴データがない商品に対してもこれまでより最大45%も精度の高い予測を生成できるようになりました。Forecastは、機械学習(ML)を利用して正確な需要予測を生成するマネージドサービスであり、MLの経験は必要ありません。正確な予測は、在庫最適化、物流計画、労働力管理の基礎であり、企業は顧客により良いサービスを提供するための準備をすることができます。コールドスタート予測は、予測を作成する必要があるにもかかわらず、商品の履歴データがない場合によくある課題です。これは、小売業、製造業、消費財メーカーなど、新しく開発した製品を市場に投入したり、ブランドやカタログを初めて導入したり、製品を新しい地域でクロスセリングしたりと、新製品の導入が頻繁に行われる業界でよく見られるものです。今回の発表では、コールドスタート予測に対する従来のアプローチを改良し、最大で45%精度の高い予測を生成できるようになりました。
コールドスタート予測モデルの開発は困難です。なぜなら、自己回帰統合移動平均(ARIMA)や指数平滑化などの従来の統計的予測手法は、製品の履歴データを使って将来の値を予測するという概念で構築されているからです。しかし、過去のデータがなければ、モデルのパラメータを算出することができないため、モデルを構築することができません。Forecastは、DeepAR+やCNN-QRといった独自のニューラルネットワークアルゴリズムを用いて、コールドスタート製品の予測を生成する機能をすでに持っていました。これらのモデルでは商品間の関係を学習し、過去のデータがない商品の予測を生成することができます。しかし、これらの関係を確立するための項目メタデータの使用は暗黙的であり、ネットワークはコールドスタート製品のトレンド特性を完全に推定することができませんでした。
今回、Amazon Forecastにおいて予測精度を最大45%向上させる新しいコールドスタート予測のアプローチが発表されました。このアプローチでは、項目メタデータの扱いを改善し、データセット内のコールドスタート商品と最も類似した特性を持つ商品群を特定します。この類似商品群を通して、コールドスタート商品の予測を生成するためのトレンドをよりよく学習することができます。例えば、新しいTシャツを販売しようとするファッション小売業者は、店舗の在庫を最適化するためにその需要を予測したいと思います。Forecastには、既存のTシャツ、ジャケット、ズボン、靴など、カタログにある他の商品の履歴データに加え、新商品と既存商品の両方のブランド名、色、サイズ、商品カテゴリーなどの項目メタデータを提供することができます。Forecastはこの項目メタデータをもとに、新しいTシャツラインに最も関連性の高い商品を自動的に検出し、それらを使って新しいTシャツの予測を作成します。
この機能は、AWS管理コンソール または AutoPredictor API を通じて Forecast が利用可能なすべてのリージョンで使用できます。リージョンごとの各サービスの利用可否ついては、AWSリージョン別のサービス表を参照してください。コールドスタート予測を開始するには、Generate ForecastsまたはこちらのGitHub notebookを参照してください。
ソリューションの概要
この投稿の手順は、AWS管理コンソールでコールドスタート予測のためにForecastを使用する方法を示しています。データのインポート、予測子のトレーニング、予測の作成という3つのステップに従って、小売業者が新しく発売された商品の在庫需要予測を作成する例について説明します。コールドスタート予測のためにForecast APIを直接使用するには、我々のGitHubリポジトリのノートブックに従ってください。
学習データのインポート
新しいコールドスタート予測手法を使用するには、予測対象を示す目標時系列データと、サイズや色などの商品特性を示す項目メタデータの2つのCSVファイルをインポートする必要があります。Forecastは、コールドスタート商品を、項目メタデータファイルには存在するが、目標時系列ファイルには存在しない商品として特定します。
コールドスタート製品を正しく識別するために、コールドスタート製品のアイテムIDが項目メターデータファイルの1行として入力されており、目標時系列データファイルに含まれていないことを確認してください。複数のコールドスタート製品の場合、各製品のアイテムIDを項目メタデータファイルに別の行として入力します。コールドスタート製品のアイテムIDがまだない場合は、64文字未満の英数字の組み合わせで、データセット内の他の製品を代表していないものを使用することができます。
この例では、目標時系列データファイルには商品アイテムID、タイムスタンプ、需要量(在庫量)が、項目メタデータファイルには商品アイテムID、カラー、商品カテゴリ、ロケーションが格納されています。
データをインポートするには、次の手順を実行します。
- Forecastコンソールで「Views dataset groups」をクリックします。

- 「Create dataset group」をクリックします。

- 「Dataset group name」にはデータセット名(この記事の場合は「my_company_shoe_inventory」)を入力します。
- 「Forecasting domain」で予測ドメインを選択します (この記事では「Retail」)。
- 「Next」をクリックします。

- 「Create target time series dataset」ページで「Dataset name」、「Frequency of your data」、「Data schema」を入力します。
- 「Dataset import details」を設定します。
- 「Start」をクリックします。
各項目の入力は次のスクリーンショットを参考にしてください。
進捗状況を確認するためのダッシュボードが表示されます。
- 項目メタデータファイルをインポートするため、ダッシュボードで、「インポート」を選択します。

- 「Create item metadata dataset」 ページで「Dataset name」と「Data Schema」を入力します。
- 「Dataset import details」を入力します。
- 「Start」をクリックします。
各項目の入力は次のスクリーンショットを参考にしてください。
予測子の学習
次に予測子の学習を行います。
- ダッシュボードで「Train predictor」を選択します。
- 「Train predictor」ページで予測子の名前と、どの程度の期間と頻度で予測したいのか、そして予測したい分位数の数を入力します。
- AutoPredictorを有効にします。これは コールドスタート予測を使用するために必要です。東京リージョンなどではこの項目は表示されませんがデフォルトでAutoPredictorが有効になっています。
- 「Create」をクリックします。
各項目の入力は次のスクリーンショットを参考にしてください。
予測の作成
予測子がトレーニングされた後(約2.5時間かかります)、新しく発売された製品の予測を作成します。ダッシュボードに「予測値の表示」ボタンが表示されれば、予測子がトレーニングされたことがわかります。
- ダッシュボードで「Create a forecast」をクリックします。
- 「Create a forecast」ページで「Forecast name」を入力し、作成した予測子を選択し「Forecast quantiles」(予測分位:オプション)と「Item for generating forecasts」を指定します。
- 「Start」をクリックします。

予測結果のエクスポート
予測が作成されるとデータをCSVにエクスポートすることができます。ステータスがアクティブになると、予測が作成されたことが分かります。
- 「Create forecast export」をクリックします。

- 「Export name」を入力します(この記事の場合は「 my_cold_start_forecast_export」)。
- 「Export location」でAmazon Simple Storage Service(Amazon S3)の場所を指定します。
- 「Start」をクリックします。

- エクスポートをダウンロードするには、まずAWSマネジメントコンソールからエクスポート先に指定したS3のパスに移動し、ファイルを選択してダウンロードボタンを選択します。
エクスポートファイルには、タイムスタンプ、アイテムID、項目メタデータ、選択した各分位の予測値が含まれます。
予測結果の確認
予測が作成された後、コンソールで新製品の予測をグラフィカルに見ることができます。
- ダッシュボードで「Query forecast」をクリックします。
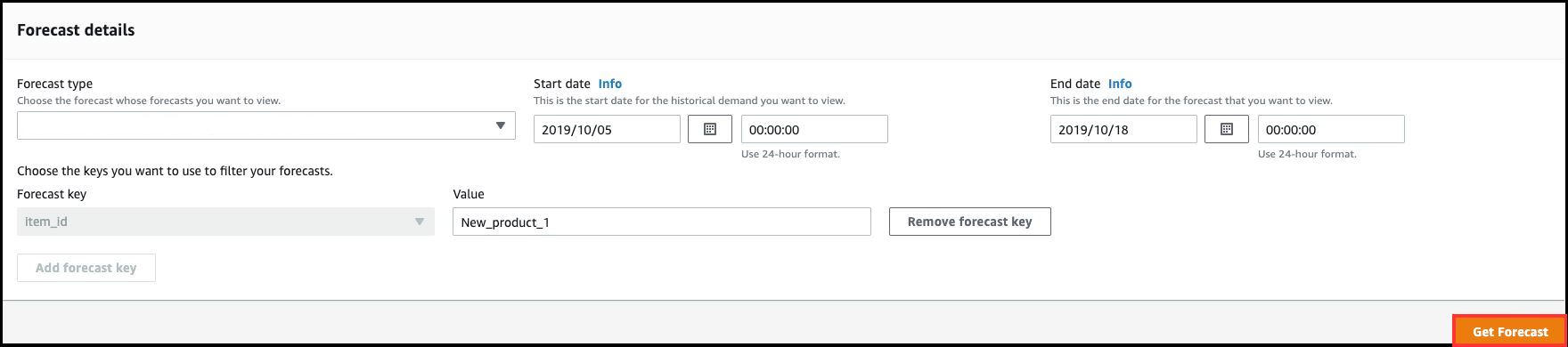
- 前の手順で作成したForecastの名前を選択します(この記事の例では「my_cold_start_forecast」)。
- 確認したい予測期間の開始日と終了日を入力します。
- 「Forecast key」にコールドスタートのアイテムIDを入力します。
- 「Get forecast」をクリックします。
以下の図のように、選択された分位で予測が表示されます。
まとめ
Forecastを使用すると、履歴データのないコールドスタート製品についても同様の予測を生成することができ、その精度は以前より最大で45%向上しています。Forecastでコールドスタート予測を生成するには、Forecastコンソールを開き、この投稿で説明した手順に従うか、API経由で機能にアクセスする方法についてGitHubのノートブックを参照してください。詳細については、Generate Forecastsを参照してください。
著者について
 Brandon Nairは、Amazon Forecastのシニア・プロダクトマネージャーです。専門はスケーラブルな機械学習サービスとアプリケーションの作成です。仕事以外では、国立公園を散策したり、ゴルフのスイングを磨いたり、冒険旅行の計画を立てたりしています。
Brandon Nairは、Amazon Forecastのシニア・プロダクトマネージャーです。専門はスケーラブルな機械学習サービスとアプリケーションの作成です。仕事以外では、国立公園を散策したり、ゴルフのスイングを磨いたり、冒険旅行の計画を立てたりしています。
 Manas Dadarkarは、Amazon Forecast サービスのエンジニアリングを担当するソフトウェア開発マネージャです。機械学習アプリケーションと、機械学習技術を誰もが簡単に導入できるようにすることに情熱を注いでいます。仕事以外では、旅行、読書、友人や家族との時間など、様々なことに興味を持っています。
Manas Dadarkarは、Amazon Forecast サービスのエンジニアリングを担当するソフトウェア開発マネージャです。機械学習アプリケーションと、機械学習技術を誰もが簡単に導入できるようにすることに情熱を注いでいます。仕事以外では、旅行、読書、友人や家族との時間など、様々なことに興味を持っています。
 Bharat Nandamuriは、Amazon Forecastに勤務するシニアソフトウェアエンジニアです。MLシステムのエンジニアリングを中心に、大規模なバックエンドサービスの構築に情熱を注いでいる。仕事以外では、チェス、ハイキング、映画鑑賞を楽しんでいます。
Bharat Nandamuriは、Amazon Forecastに勤務するシニアソフトウェアエンジニアです。MLシステムのエンジニアリングを中心に、大規模なバックエンドサービスの構築に情熱を注いでいる。仕事以外では、チェス、ハイキング、映画鑑賞を楽しんでいます。
 Gaurav Guptaは、AWS AI ラボとAmazon Forecastのサイエンティストです。シーケンシャルデータに対する機械学習、偏微分方程式に対する演算子学習、ウェーブレットに関心を持ち研究しています。南カリフォルニア大学にて博士号を取得後、AWSに入社しました。
Gaurav Guptaは、AWS AI ラボとAmazon Forecastのサイエンティストです。シーケンシャルデータに対する機械学習、偏微分方程式に対する演算子学習、ウェーブレットに関心を持ち研究しています。南カリフォルニア大学にて博士号を取得後、AWSに入社しました。
このブログは、ソリューションアーキテクトの横山誠が翻訳しました。