Amazon Web Services ブログ
Amazon EMR 移行ガイド
世界中の企業が、Apache Hadoop や Apache Spark などの新しいビッグデータ処理および分析のフレームワークの力を発見していますが、同時にオンプレミスのデータレイク環境でこうしたテクノロジを運用する際のいくつかの課題にも気付いています。また、現在の配信ベンダーの将来についても懸念があるかもしれません。
こうした課題に対処するために、Amazon EMR 移行ガイド (2019 年 6 月に最初に公開) を発表しました。 これは、オンプレミスのビッグデータのデプロイから EMR への移行方法を計画する際に役立つ、適切な技術的アドバイスを提供する包括的なガイドです。
IT 組織はリソースのプロビジョニング、不均一なワークロードの大規模な処理、そして急速に変化するコミュニティ主導のオープンソースソフトウェアのイノベーションのスピードに追いつくための努力に取り組んでいるため、オンプレミスのビッグデータ環境における一般的な問題としては、俊敏性の欠如、過剰なコスト、管理に関する課題などがあります。多くのビッグデータに関する取り組みでは、基盤となるハードウェアおよびソフトウェアインフラストラクチャの評価、選択、購入、納入、デプロイ、統合、プロビジョニング、パッチ適用、保守、アップグレード、サポートの遅れや負担が課題となっています。
同様に重要ではあるものの、微妙な問題は、企業のデータセンターでの Apache Hadoop と Apache Spark のデプロイが同じサーバー内のコンピューティングリソースとストレージリソースを直接結びつける方法であり、足並みを揃えて拡張しなければならない柔軟性に欠けるモデルとなることです。つまり、ほとんどのオンプレミス環境では、各ワークロードのコンポーネントに対する要件が異なるため、未使用のディスク容量、処理能力、システムメモリが多くなってしまいます。 一般的なワークロードは、さまざまな種類のクラスターで、さまざまな頻度と時間帯で実行されます。こうしたビッグデータのワークロードは、共有している同じ基盤となるストレージまたはデータレイクにアクセスしながら、いつでも最も効率的に実行できるように解放する必要があります。説明については、下の図 1 を参照してください。
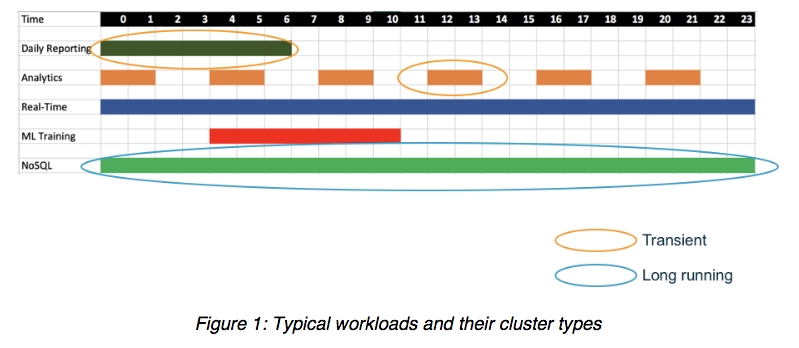
スマートな企業は、どのようにしてビッグデータへの取り組みで成功を収めることができるでしょうか? ビッグデータ (および機械学習) をクラウドに移行することには多くの利点があります。AWS などのクラウドインフラストラクチャサービスプロバイダーは、オンデマンドで伸縮自在なコンピューティングリソース、回復力があり安価な永続的ストレージ、およびビッグデータアプリケーションを開発および運用するための最新の使い慣れた環境を提供するマネージド型サービスの幅広い選択肢を提供します。データエンジニア、開発者、データサイエンティスト、IT 担当者は、データの準備と貴重な洞察の抽出に集中することができます。
Amazon EMR、AWS Glue、Amazon S3 などのサービスを使用すると、コンピューティングとストレージを個別に分離および拡張しながら、統合され、高度に管理された、回復力の高い環境を提供し、オンプレミスアプローチの問題を即座に軽減できます。このアプローチは、より速く、より俊敏で、使いやすく、よりコスト効率の良いビッグデータとデータレイクのイニシアチブにつながります。
ただし、従来のオンプレミスの Apache Hadoop および Apache Spark に関する既存の知恵は、クラウドベースのデプロイでは必ずしも最善の戦略とはなりません。クラウド内でクラスターノードを実行するための単純なリフトアンドシフトアプローチは、概念的には簡単ですが、実際には次善の策です。ビッグデータをクラウドアーキテクチャに移行する際に、さまざまな設計上の決定が利益を最大化するために大きく役立ちます。
このガイドでは、以下のベストプラクティスを紹介します。
- データ、アプリケーション、およびカタログの移行
- 永続的リソースと一時的リソースの使用
- セキュリティポリシー、アクセスコントロール、および監査ログの設定
- 価値を最大化しながら、コストを見積もりそして最小化する
- AWS クラウドを活用して高可用性 (HA) と災害復旧 (DR) を実現する
- 一般的な管理作業の自動化
プロフェッショナルサービスに代わることを意図しているわけではありませんが、このガイドではビッグデータとデータレイクのイニシアチブをクラウドに移行する際の一般的な質問とシナリオを幅広く網羅しています。
ビッグデータプラットフォームをクラウドに移行する道のりを始めるときは、まず移行への取り組み方を決める必要があります。1 つのアプローチは、クラウドの利点を最大限に引き出すためにプラットフォームを再設計することです。もう 1 つのアプローチはリフトアンドシフトとして知られています。既存のアーキテクチャをそのまま、クラウドへ直接的に移行する方法です。最後の選択肢は、リフトアンドシフトを再設計と融合させるハイブリッドアプローチです。どちらのアプローチにも長所と短所があるため、この判断は簡単ではありません。
リフトアンドシフトのアプローチは通常、曖昧さとリスクが少なくて単純です。さらに、このアプローチは、データセンターでリースが期限切れになっている場合など、厳しい納期に対処する場合に適しています。ただし、リフトアンドシフトの短所は、必ずしも最も費用対効果が高いとは限らず、既存のアーキテクチャがクラウド内のソリューションに容易にマッピングできない可能性があることです。
再設計は、コストと効率の最適化を含めて、多くの利点を実現します。再設計では、最新かつ最高のソフトウェアに移行し、クラウドネイティブなツールとの統合を高め、クラウドネイティブな製品とサービスを活用することで運用上の負担を軽減できます。
このガイドでは、Apache Spark および Hadoop のエコシステムの観点から、それぞれの移行アプローチの長所と短所を示します。このガイドを読むには、今すぐ Amazon EMR 移行ガイドをダウンロードしてください。
どのアプローチが自分のワークフローに最適であるかを判断するためのより一般的な情報については、クラウドへの移行をより高いレベルで実行するためのベストプラクティスの概要を説明した An E-Book of Cloud Best Practices for Your Enterprise (企業のためのクラウドベストプラクティスの電子ブック) をご覧ください。
著者について
 Nikki Rouda は AWS でデータレイクおよびビッグデータ向け製品マーケティング主任マネージャーを務めています。Nikki は20 年以上にわたり 40 か国以上で企業の分析および IT インフラストラクチャの課題に対して、ソリューションを開発および実装するのをサポートしてきました。Nikki はケンブリッジ大学で経営管理学修士号を、ブラウン大学で地球物理学と数学の理学士号を取得しています。
Nikki Rouda は AWS でデータレイクおよびビッグデータ向け製品マーケティング主任マネージャーを務めています。Nikki は20 年以上にわたり 40 か国以上で企業の分析および IT インフラストラクチャの課題に対して、ソリューションを開発および実装するのをサポートしてきました。Nikki はケンブリッジ大学で経営管理学修士号を、ブラウン大学で地球物理学と数学の理学士号を取得しています。