Amazon Web Services ブログ
Amazon Elasticsearch Serviceでは現在、韓国語分析の改善のためにSeunjeonプラグインをサポート
韓国語テキストの高精度な解析とマッチングを保証するために、Amazon Elasticsearch Service(Amazon ES)がSeunjeonプラグインをサポートするようになりました。このプラグインを使用すると、ユーザーにより良い結果をもたらすカスタムアナライザーを作成できます。
検索のためのアジア言語の処理
検索エンジンを使用するときは、検索ボックスに単語を入力します。その後に検索エンジンはそれらの単語を、索引付けした文書に出てくる単語とマッチングさせます。正しく一致させるには、検索エンジンがソース文字列から単語(言い換えれば、検索語句)を解析する必要があります。
エンジンは一連のステップでこれを行います。ステップに関するいくつかの例としては、空白をトークン化し、語幹を根本的な形にするためのステミングを適用し、ストップワード(頻繁で値の低い用語など)を削除することなどです。
多くの単語は複合語で、空白で区切れないため、アジア言語のテキストの処理は複雑です。同じ文字列は、複合的な文脈で異なることを意味することがあります。
Elasticsearchでのアジア言語の最もベーシックな処理は、cjkアナライザーを介して提供されます。このアナライザーは、空白を分割して、得られたテキストに文字のバイグラム—2文字のペア—を作成します。たとえば、文字列아마존으로は、次の用語をインデックスに追加します。
아마
마존
존으
으로
Elasticsearchは、クエリを実行したときと同じ分析を行います。インデックス内のバイグラムに一致する、クエリ内のバイグラムが多いほど、マッチングが良好になります。
残念ながら、バイグラムをマッチングさせると予期しない結果につながる可能性があります。例えば、아마존이、아마존은、아마존으로、아마존을などは、すべてAmazonを意味する単語です。空白で用語を抽出したりバイグラムを計算すると、結果が悪くなる可能性があります。もし、아마존を照会すると、空白解析の仕組みのために、아마존이、아마존은、아마존으로、そして아마존을を含むドキュメントが結果に含まれない可能性があります。または、そのような文書は、バイグラム分析の仕組みのために、検索結果に表示されるほど十分な高いスコアを示さないことがあります。ユーザーがクエリを書くとき、最も頻繁には、単純に아마존(Amazon)を含むすべての文を検索します。この例のように行うと、多くの結果が抜けてしまいます。
より良い韓国のアナライザー:Seunjeon
高精度のマッチングをサポートするには、空白に基づいた処理条件以上の処理を行う韓国語のアナライザーが必要です。また、バイグラムに分割することもできます。Seunjeonは広く使われているオープンソースの韓国語アナライザーで、現在Amazon ESで利用可能です。このアナライザーは、韓国語の辞書であるmecab-ko-dicに基づいています。この辞書はアナライザーの重要な部分であり、ソーステキストとそのテキストの正しい用語を入力します。Amazon ESは現在、mecab-ko-dic-2.0.1-20150920を提供しています。
プラグインがメモリー不足のインスタンスでうまく動作するように、内部データ構造と関数に対して複数の最適化を行い、コミュニティへの機能拡張に貢献しました。作成されたプラグインのメモリー占有量は59%より少なく、現在はbitbucketリポジトリ内の個別の最適化バージョンとしても利用できます。
Seunjeonプラグインを使ってマッピングを作成する方法
Amazon ESには、Seunjeonアナライザーがあらかじめパッケージ化されており、自動的に導入され管理されます。ソースフィールドにアナライザーを設定した後、韓国語のキーワードで検索を開始することができます。
次のコードは、韓国語アナライザーでインデックスを作成します。
前述のElasticsearchマッピングでは、カスタムトークナイザーを使用する韓国語[2]という名前のカスタムフィールドアナライザー [1]を定義します[3](トークナイザーは文字列を受け取り、用語に変換します)。また、seunjeon_トークナイザーを使用して、トークナイザー[4]をマッピング内に定義します。この時点で、いくつかのオプションを設定し、カスタム用語[5]をユーザ辞書に追加しました。最後に、アナライザーをステータスフィールド[6]に適用します。この場合、Amazon Elasticsearch Serviceにドキュメントを送信すると、ステータスフィールドのテキストのために、常に韓国語アナライザーが使用されます。
アナライザーを直接呼び出すと、トークン化と分析の仕組みを確認できます。
この呼び出しの出力は次のとおりです。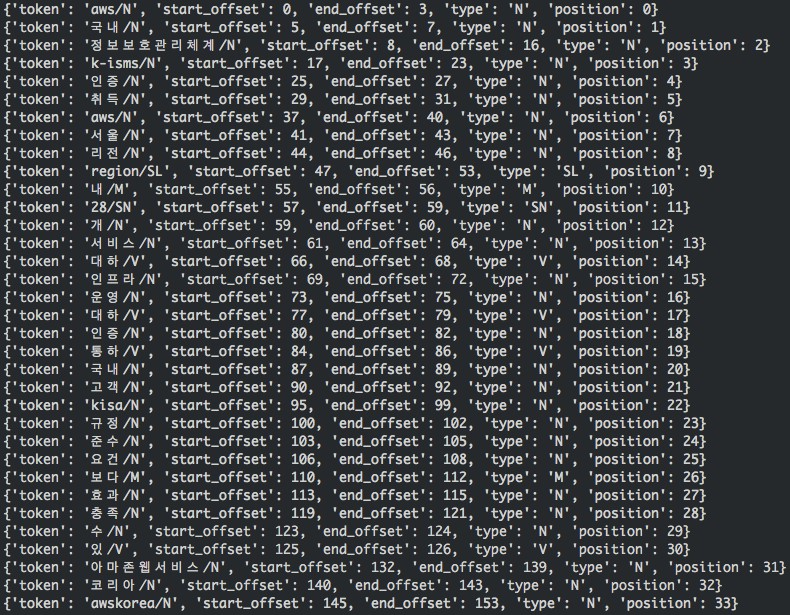
ほとんどの用語は、組み込みのmecab-ko辞書に基づくSeunjeonプラグインによって解析されていることがわかります。カスタム辞書のエントリーに基づいて出力された用語を表示することもできます:aws、awskorea、아마존웹서비스、정보보호관리체계、k-isms,10、そして kisa,10。カスタム辞書がなければ、정보보호관리체계(Information Security Management System)は次のような一連のバイグラムとして扱われます。
カスタム辞書のエントリーは、検索の質を向上させ、より良い結果を提供します。
まとめ
韓国語のテキストの高精度解析と一致を保証するには、Amazon Elasticsearch ServiceのSeunjeonプラグインを使用します。ベーストークン化とカスタムワードを使用してカスタムアナライザーを作成し、そのアナライザーをデータを含む文字列フィールドに適用することができます。Seunjeonプラグインは、そのフィールドに対するクエリを解析してトークン化し、より良い結果を提供します。
著者について
 ピルジュン・ キムは、アマゾン ウェブ サービスのソリューションアーキテクトです。 彼はAWSサービスに関する建築ガイダンスと技術支援を提供するために顧客と協力しています。AWSより先に、彼は開発してマイクロサービスアーキテクチャー上のモバイルゲーム、Webおよびモバイルアプリケーションを開始しました。
ピルジュン・ キムは、アマゾン ウェブ サービスのソリューションアーキテクトです。 彼はAWSサービスに関する建築ガイダンスと技術支援を提供するために顧客と協力しています。AWSより先に、彼は開発してマイクロサービスアーキテクチャー上のモバイルゲーム、Webおよびモバイルアプリケーションを開始しました。
 Dr.Jon Handler(@_searchgeek) は、検索テクノロジーが専門の AWS ソリューションアーキテクトです。 AWS を使用する際にソリューションの価値を向上させる手助けとなるために、当社の顧客と協力してデータベースプロジェクト上の指導や技術支援を行っています。
Dr.Jon Handler(@_searchgeek) は、検索テクノロジーが専門の AWS ソリューションアーキテクトです。 AWS を使用する際にソリューションの価値を向上させる手助けとなるために、当社の顧客と協力してデータベースプロジェクト上の指導や技術支援を行っています。