AWS Big Data Blog
Custom packages and hot reload of dictionary files with Amazon OpenSearch Service
Amazon OpenSearch Service is a fully managed service that you can use to deploy and operate OpenSearch clusters cost-effectively at scale in the AWS Cloud. The service makes it easy for you to perform interactive log analytics, real-time application monitoring, website search, and more by offering the latest versions of OpenSearch, support for 19 versions of Elasticsearch (1.5 to 7.10 versions), and visualization capabilities powered by OpenSearch Dashboards and Kibana (1.5 to 7.10 versions).
There are various use cases such as website search, ecommerce search, and enterprise search where the user wants to get relevant content for specific terms. Search engines match the terms (words) sent through the query API. When there are many different ways of specifying the same concept, you use synonyms to give the search engine more match targets than what the user entered.
Similarly, there are certain use cases where input data has a lot of common or frequently occurring words that don’t add much relevance when used in a search query. These include words like “the,” “this,” and “that.” These can be classified as stopwords.
OpenSearch Service allows you to upload custom dictionary files, which can include synonyms and stopwords to be customized to your use case. This is especially useful for use cases where you want to do the following:
- Specify words that can be treated as equivalent. For example, you can specify that words such as “bread,” “danish,” and “croissant” be treated as synonymous. This leads to better search results because instead of returning a null result if an exact match isn’t found, an approximately relevant or equivalent result is returned.
- Ignore certain high frequency terms that are common and lack useful information in terms of contributing to the search’s relevance store. These could include “a,” “the,” “of,” “an,” and so on.
Specifying stems, synonyms, and stopwords can greatly help with query accuracy, and allows you to customize and enhance query relevance. They can also help with stemming (such as in the Japanese (kuromoji) Analysis Plugin). Stemming is reducing a word to its root form. For Example, “cooking” and “cooked” can be stemmed to the same root word “cook.” This way, any variants of a word can be stemmed to one root word to enhance the query results.
In this post, we show how we can add custom packages for synonyms and stopwords to an OpenSearch Service domain. We start by creating custom packages for synonyms and stopwords and creating a custom analyzer for a sample index that uses the standard tokenizer and a synonym token filter, followed by a demonstration of hot reload of dictionary files.
Tokenizers and token filters
Tokenizers break streams of characters into tokens (typically words) based on some set of rules. The simplest example is the whitespace tokenizer, which breaks the preceding characters into a token each time it encounters a whitespace character. A more complex example is the standard tokenizer, which uses a set of grammar-based rules to work across many languages.
Token filters add, modify, or delete tokens. For example, a synonym token filter adds tokens when it finds a word in the synonyms list. The stop token filter removes tokens when finds a word in the stopwords list.
Prerequisites
For this demo, you must have an OpenSearch Service cluster (version 1.2) running. You can use this feature on any version of OpenSearch Service running 7.8+.
Users without administrator access require certain AWS Identity and Access Management (IAM) actions in order to manage packages: es:CreatePackage, es:DeletePackage, es:AssociatePackage, and es:DissociatePackage. The user also needs permissions on the Amazon Simple Storage Service (Amazon S3) bucket path or object where the custom package resides. Grant all permission within IAM, not in the domain access policy. This allows for better management of permissions because any change in permissions can be separate from the domain and allows the user to perform the same action across multiple OpenSearch Service domains (if needed).
Set up the custom packages
To set up the solution, complete the following steps:
- On the Amazon S3 console, create a bucket to hold the custom packages.
- Upload the files with the stopwords and synonyms to this bucket. For this post, the file contents are as follows:
- synonyms.txt:
- stopwords.txt:
The following screenshot shows the uploaded files:

Now we import our packages and associate them with a domain.
- On the OpenSearch Service console, choose Packages in the navigation pane.
- Choose Import package.

- Enter a name for your package (for the synonym package, we use
my-custom-synonym-package) and optional description. - For Package source, enter the S3 location where synonyms.txt is stored.
- Choose Submit.

- Repeat these steps to create a package with stopwords.txt.
- Choose your synonym package when its status shows as
Available.

- Choose Associate to a domain.
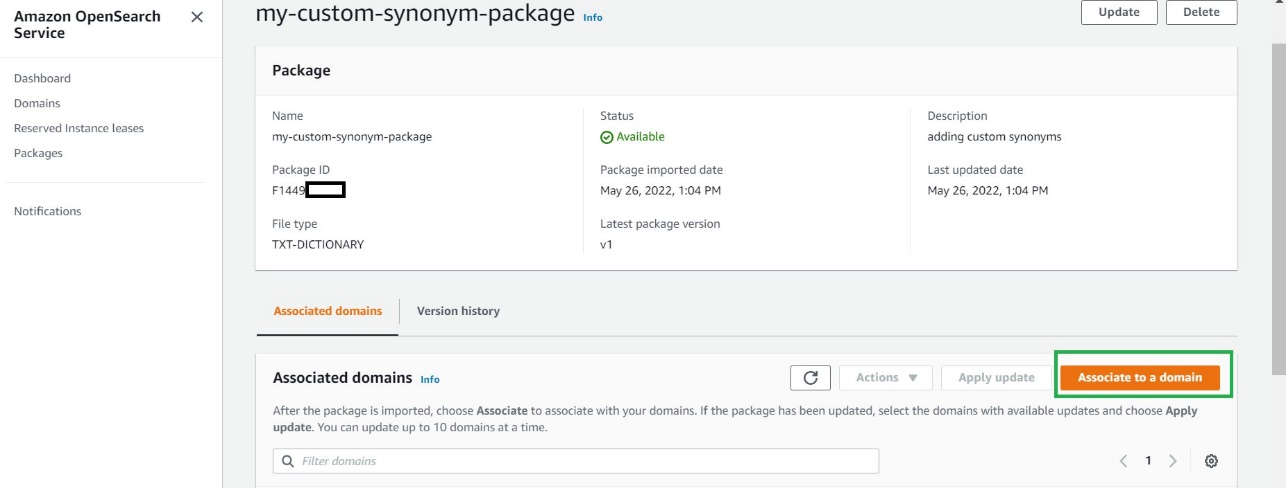
- Select your OpenSearch Service domain, then choose Associate.

- Repeat these steps to associate your OpenSearch Service domain to the stopwords package.
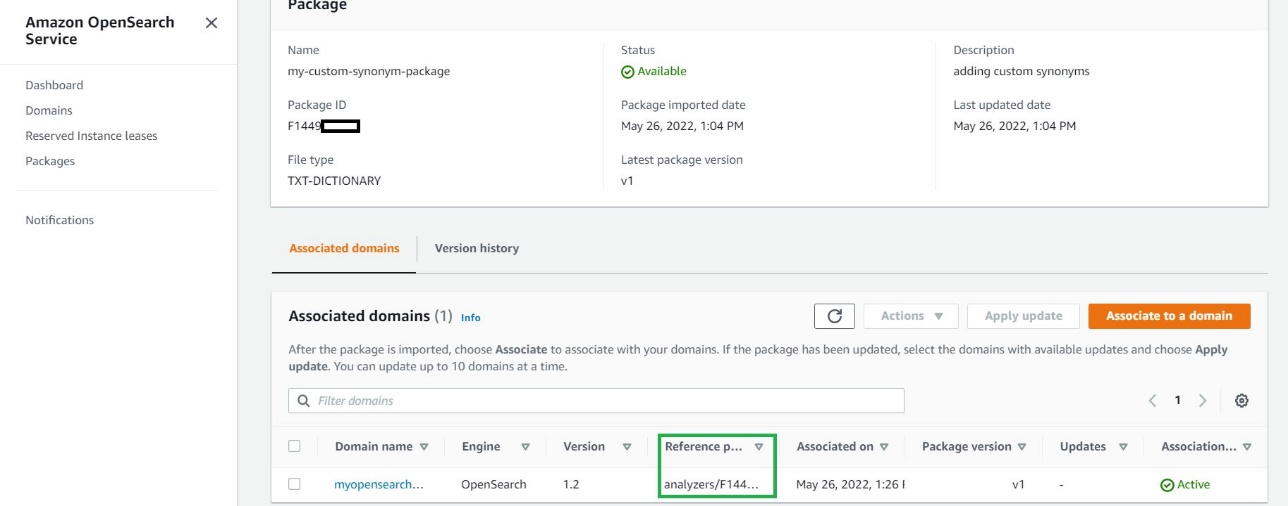
- When the packages are available, note their IDs.
You use analyzers/id as the file path in your requests to OpenSearch.
Use the custom packages with your data
After you associate a file with a domain, you can use it in parameters such as synonyms_path and stopwords_path when you create tokenizers and token filters. For more information, see OpenSearch Service.
You can create a new index (my-index-test) using the following snippet in the OpenSearch Service domain and specify the Analyzers/id values for the synonyms and stopwords packages.
- Open OpenSearch Dashboards.
- On the Home menu, choose Dev Tools.

- Enter the following code in the left pane:
- Choose the play sign to send the request to create the index with our custom synonyms and stopwords.

The following screenshot shows our results.

This request creates a custom analyzer for my index that uses the standard tokenizer and a synonym and stop token filter. This request also adds a text field (description) to the mapping and tells OpenSearch to use the new analyzer as its search analyzer. It still uses the standard analyzer as its index analyzer.
Note the line "updateable": true in the token filter. This field only applies to search analyzers, not index analyzers, and is critical if you later want to update the search analyzer automatically.
Let’s start by adding some sample data to the index my-index-test:
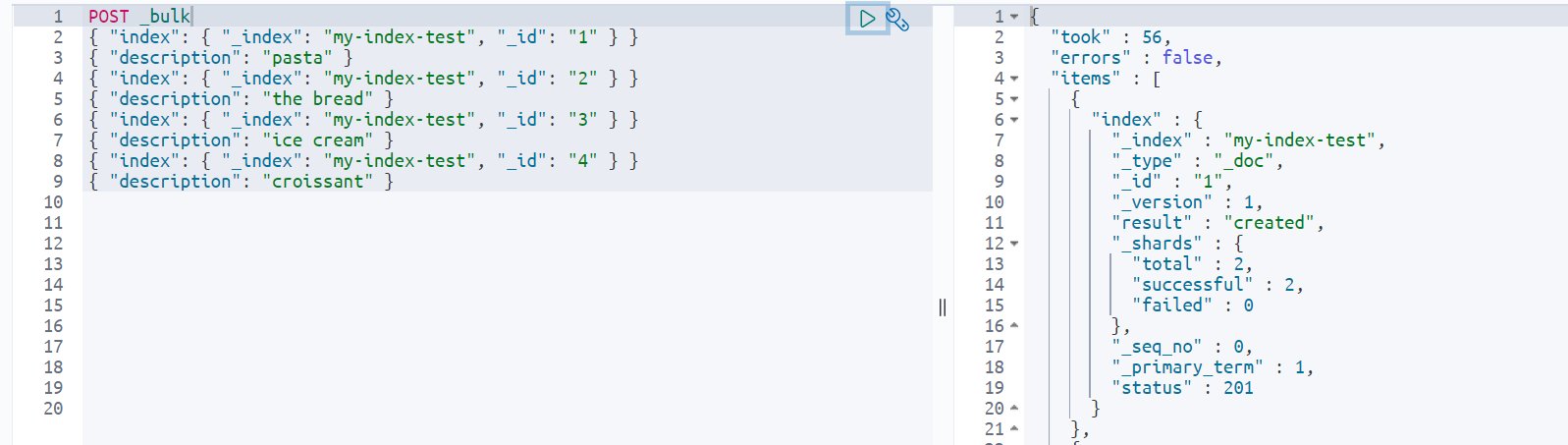
Now If you search for the words you specified in the synonyms.txt file, you get the required results. Note that my test index only has pasta in the indexed data, but because I specified “ravioli” as a synonym for “pasta” in my associated package, I get the results for all documents that have the word “pasta” when I search for “ravioli.”
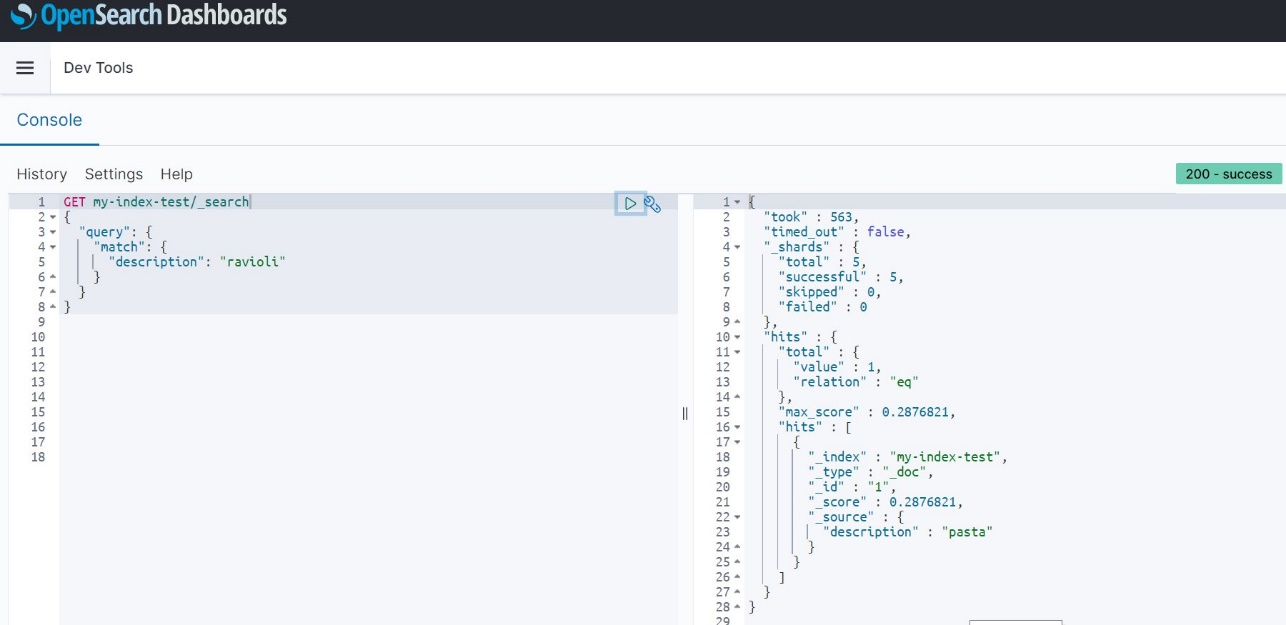
Similarly, you can use the stopwords feature to specify common words that can be filtered out while showing search results and don’t impact the relevance much while returning search query results.
Hot reload
Now let’s say you want to add another synonym (“spaghetti”) for “pasta.”
- The first step is to update the synonyms.txt file as follows and upload this updated file to your S3 bucket:

Uploading a new version of a package to Amazon S3 doesn’t automatically update the package on OpenSearch Service. OpenSearch Service stores its own copy of the file, so if you upload a new version to Amazon S3, you must manually update it in OpenSearch Service.If you try to run the search query against the index for the term “spaghetti” at this point, you don’t get any results:

After the file is modified in Amazon S3, update the package in OpenSearch Service, then apply the update. To do this, perform the following steps:
- On the OpenSearch Service console, choose Packages.
- Choose the package you created for custom synonyms and choose Update.

- Provide the S3 path to the file, then choose Update package.

- Enter a description and choose Update package.

You return to the Packages page. - When the package status shows as
Available, choose it and wait for the associated domain to show as updated. - Select the domain and choose Apply update.

- Choose Apply update again to confirm.

Wait for the association status to change to Active to confirm that the package version is also updated.
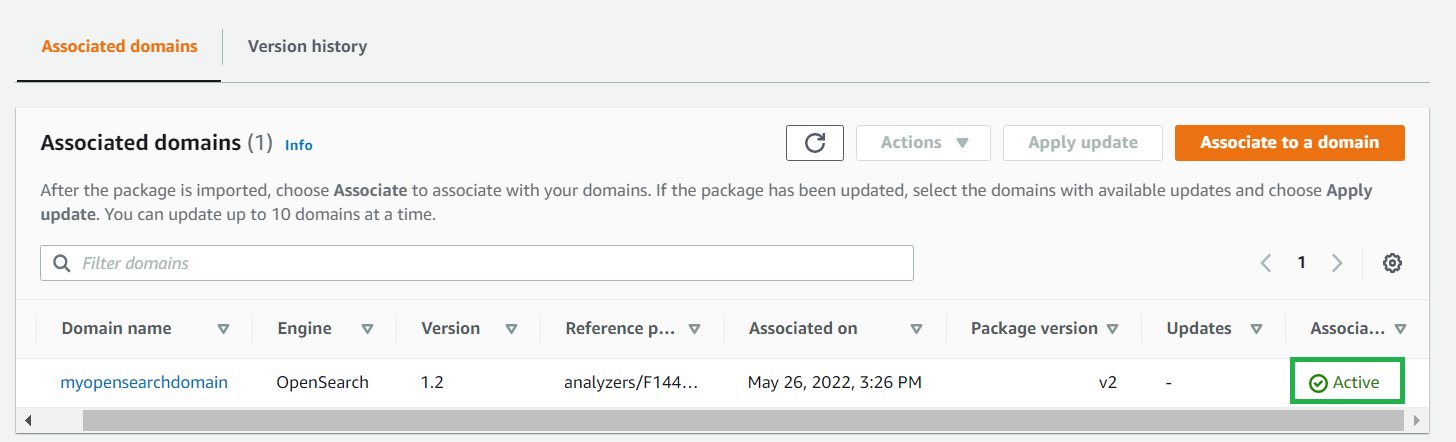
If your domain runs Elasticsearch 7.7 or earlier, uses index analyzers, or doesn’t use the updateable field, and if you want to add some additional synonyms at a later time, you have to reindex your data with the new dictionary file. Previously, on Amazon Elasticsearch Service, these analyzers could only process data as it was indexed.
If your domains runs OpenSearch Service or Amazon Elasticsearch Service 7.8 or later and only uses search analyzers with the updateable field set to true, you don’t need to take any further action. OpenSearch Service automatically updates your indexes using the _plugins/_refresh_search_analyzers API. This allows for refresh of search analyzers in real time without you needing to close and reopen the index.
This feature called hot reload provides the ability to reload dictionary files without reindexing your data. With the new hot reload capability, you can call analyzers at search time, and your dictionary files augment the query. This feature also lets you version your dictionary files in OpenSearch Service and update them on your domains, without having to reindex your data.
Because the domain used in this demonstration runs OpenSearch Service 1.2, you can utilize this hot reload feature and without re-indexing of any data. Simply run a search query for the newly added synonym (“spaghetti”) and get all resultant documents that are synonymous to it:
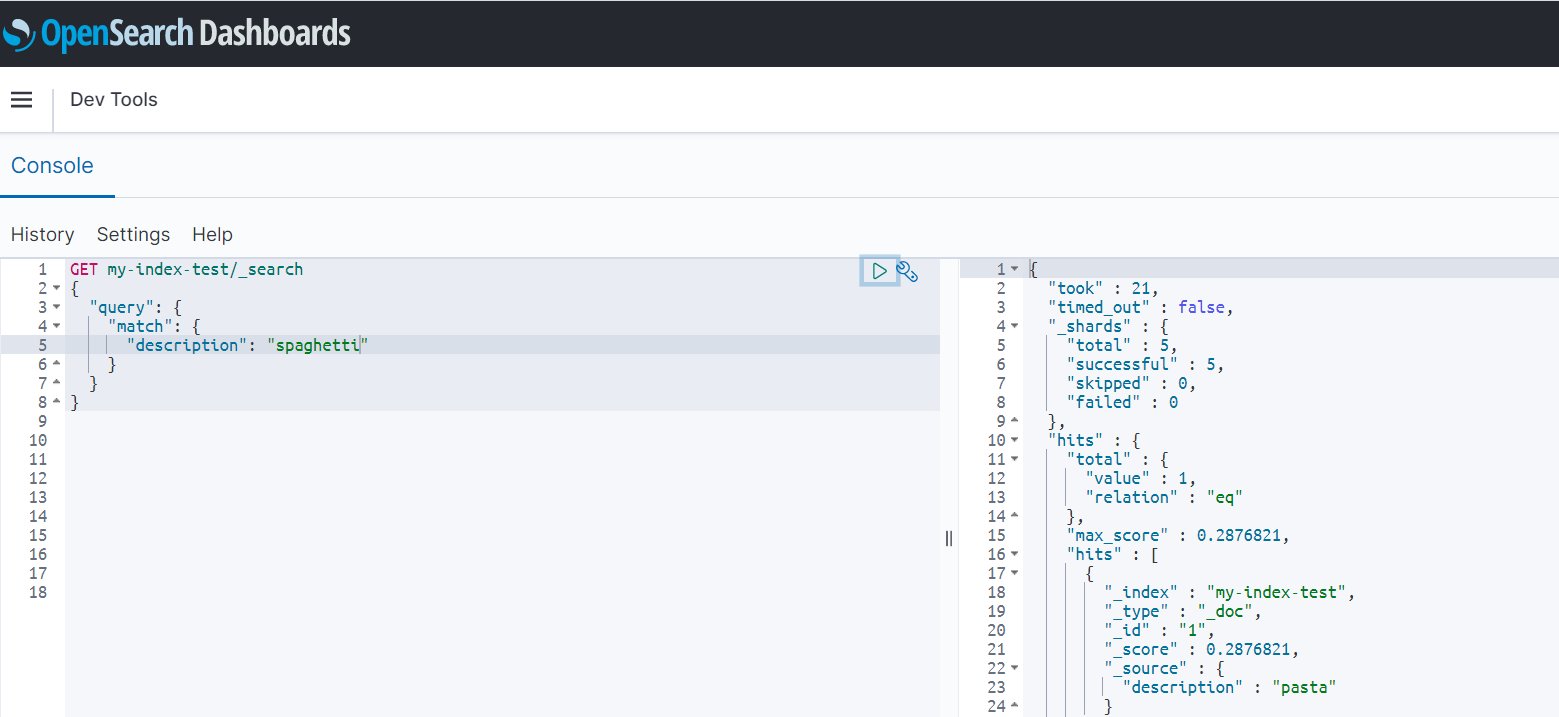
Conclusion
In this post, we showed how easy it is to set up synonyms in OpenSearch Service so you can find the relevant documents that match a synonym for a word, even when the specific word isn’t used as search term. We also demonstrated how to add and update existing synonym dictionaries and load those files to reflect the changes.
If you have feedback about this post, submit your comments in the comments section. You can also start a new thread on the OpenSearch Service forum or contact AWS Support with questions.
About the Authors
 Sonam Chaudhary is a Solutions Architect and Big Data and Analytics Specialist at AWS. She works with customers to build scalable, highly available, cost-effective, and secure solutions in the AWS Cloud. In her free time, she likes traveling with her husband, shopping, and watching movies.
Sonam Chaudhary is a Solutions Architect and Big Data and Analytics Specialist at AWS. She works with customers to build scalable, highly available, cost-effective, and secure solutions in the AWS Cloud. In her free time, she likes traveling with her husband, shopping, and watching movies.
 Prashant Agrawal is a Search Specialist Solutions Architect with OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Search Specialist Solutions Architect with OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.