Desideri essere informato quando sono disponibili nuovi contenuti?
Di Becky Weiss e Mike Furr
Da Amazon, i servizi che offriamo devono raggiungere destinazioni a disponibilità estremamente alta. Ciò significa che dobbiamo riflettere attentamente sulle dipendenze che i nostri sistemi acquisiscono. Progettiamo i nostri sistemi in modo che siano resilienti anche quando queste dipendenze sono danneggiate. In questo articolo, definiremo un modello che chiamiamo stabilità statica per raggiungere questo livello di resilienza. Ti mostreremo il modo in cui applichiamo questo concetto alle zone di disponibilità, un elemento chiave dell'infrastruttura a blocco predefinito in AWS e quindi una dipendenza fondamentale su cui sono realizzati tutti i nostri servizi.
In una progettazione staticamente stabile, l'intero sistema continua a funzionare anche quando una dipendenza è danneggiata. Forse il sistema non vede nessuna informazione aggiornata (ad esempio cose nuove, cose cancellate o modificate) che la sua dipendenza avrebbe dovuto fornire. Tuttavia, tutto quello che stava facendo prima che la dipendenza si danneggiasse continua a funzionare nonostante il danneggiamento della dipendenza. Descriveremo come abbiamo costruito Amazon Elastic Compute Cloud (EC2) e lo abbiamo reso staticamente stabile. In seguito forniremo due esempi di architetture staticamente stabili che abbiamo ritenuto utili per costruire sistemi regionali altamente disponibili in aggiunta alle zone di disponibilità.
Infine, approfondiremo la filosofia di progettazione di Amazon EC2, incluso il modo in cui è stato progettato per fornire l'indipendenza della zona di disponibilità a livello di software. Inoltre, parleremo di alcuni dei compromessi conseguenti alla realizzazione di un servizio con questo tipo di architettura.
Stabilità statica
• Assegna un'interfaccia di rete a partire dalla sottorete VPC.
• Prepara un volume Amazon Elastic Block Store (EBS).
• Genera le credenziali di ruolo AWS Identity and Access Management (IAM).
• Installa le regole del gruppo di sicurezza.
• Archivia i risultati negli archivi dati dei vari servizi a valle.
• Propaga le configurazioni necessarie al server nel VPC e nel network edge, a seconda dei casi.
• Legge e scrive dai volumi Amazon EBS.
• E così via.
• È tipico per il piano dati un funzionamento a un volume superiore (spesso per ordini di grandezza) rispetto al suo piano di controllo. Quindi, è meglio tenerli separati in modo che ognuno possa essere ridimensionato in base alle proprie dimensioni di ridimensionamento.
• Nel corso degli anni abbiamo scoperto che il piano di controllo di un sistema tende ad avere più parti in movimento rispetto al piano dati, quindi è statisticamente più probabile che, solo per questo motivo, venga danneggiato.
Modelli di stabilità statica
In questa sezione introduciamo due modelli di alto livello che utilizziamo in AWS per progettare sistemi ad alta disponibilità sfruttando la stabilità statica. Ognuno è applicabile al proprio insieme di situazioni, ma entrambi sfruttano l'astrazione della zona di disponibilità.

Nel caso di un danneggiamento della zona di disponibilità, l'architettura mostrata nel diagramma precedente non richiede nessuna azione. Le istanze EC2 nella zona di disponibilità danneggiata inizieranno a non superare i controlli di integrità e l'Application Load Balancer allontanerà il traffico da tali istanze. Infatti, il servizio Elastic Load Balancing è progettato secondo questo principio. Ha eseguito il provisioning per una capacità di bilanciamento del carico sufficiente per far fronte a un danneggiamento della zona di disponibilità senza dover aumentare le dimensioni.
Utilizziamo questo modello anche in assenza del sistema di bilanciamento del carico o del servizio HTTPS. Ad esempio, anche un parco istanze EC2 che elabora i messaggi da una coda di Amazon Simple Queue Service (SQS) può seguire questo schema. Le istanze vengono distribuite in un gruppo Auto Scaling su più zone di disponibilità a cui è stato opportunamente eseguito l'overprovisioning. Nel caso di un danneggiamento della zona di disponibilità, il servizio non interviene. Le istanze danneggiate smettono di fare il loro lavoro che verrà terminato dalle restanti.

Come nel caso dell'esempio senza stato attivo-attivo, quando la zona di disponibilità con il nodo primario viene danneggiata, il servizio con stato non interagisce con l'infrastruttura. Per i servizi che utilizzano Amazon RDS, RDS gestirà il failover e reindirizzerà il nome DNS al nuovo primario nella zona di disponibilità operativa. Questo modello si applica ad altre configurazioni attive in standby, anche se non utilizzano un database relazionale. In particolare, lo applichiamo a sistemi con un'architettura cluster che ha un nodo leader. Distribuiamo questi cluster nelle zone di disponibilità ed eleggiamo il nuovo nodo leader da un candidato in standby invece di lanciare un sostituto "all'ultimo momento".
Ciò che questi due modelli hanno in comune è che entrambi avevano già eseguito il provisioning della capacità di cui avrebbero avuto bisogno in caso di un danneggiamento della zona di disponibilità con largo anticipo rispetto all'effettivo danneggiamento. In nessuno di questi casi il servizio sta utilizzando dipendenze deliberate del piano di controllo, come il provisioning di nuove infrastrutture o l'introduzione di modifiche, in risposta a un danneggiamento della zona di disponibilità.
Dulcis in fundo: stabilità statica all'interno di Amazon EC2
Questa sezione finale dell'articolo approfondirà ulteriormente le architetture resilienti della zona di disponibilità, coprendo alcuni dei modi in cui seguiamo il principio di indipendenza della zona di disponibilità in Amazon EC2. Comprendere alcuni di questi concetti è utile quando costruiamo un servizio che non solo deve essere altamente disponibile, ma che deve anche fornire infrastrutture su cui altri possano essere altamente disponibili. Amazon EC2, come fornitore di infrastrutture AWS di basso livello, è l'infrastruttura che le applicazioni possono utilizzare per essere altamente disponibili. Ci sono volte in cui anche altri sistemi potrebbero voler adottare tale strategia.
Nelle nostre pratiche di implementazione, seguiamo il principio di indipendenza della zona di disponibilità in Amazon EC2. In Amazon EC2, il software viene distribuito sui server fisici che ospitano istanze EC2, dispositivi edge, resolver DNS, componenti del piano di controllo nel percorso di avvio dell'istanza EC2 e molti altri componenti da cui dipendono le istanze EC2. Queste distribuzioni seguono un calendario di distribuzione zonale. Ciò significa che due zone di disponibilità nella stessa regione riceveranno una determinata distribuzione in giorni diversi. In AWS usiamo un'implementazione graduale delle distribuzioni. Ad esempio, seguiamo la procedura consigliata (indipendentemente dal tipo di servizio che forniamo) per distribuire prima una casella unica, e poi 1/N di server, ecc. Tuttavia, nel caso specifico di servizi come quelli di Amazon EC2, le nostre distribuzioni fanno un ulteriore passo avanti e sono deliberatamente allineate ai confini della zona di disponibilità. In questo modo, un problema con una distribuzione che influenza una zona di disponibilità, viene ripristinato e risolto. Non influisce sulle altre zone di disponibilità, che continuano a funzionare normalmente.
Un altro modo in cui utilizziamo il principio delle zone di disponibilità indipendenti quando operiamo in Amazon EC2 è progettare tutti i flussi di pacchetti per rimanere all'interno della zona di disponibilità piuttosto che oltrepassare i confini. Questo secondo punto, in cui il traffico di rete è mantenuto circoscritto alla zona di disponibilità, merita un approfondimento. È un'interessante illustrazione di come pensiamo diversamente quando creiamo un sistema regionale ad alta disponibilità, ovvero un consumer di zone di disponibilità indipendenti (utilizza cioè garanzie di indipendenza della zona di disponibilità come base per la costruzione di un servizio ad alta disponibilità), rispetto a quando forniamo ad altri un'infrastruttura indipendente della zona di disponibilità che permetterà loro di renderla ad alta disponibilità.
Lo schema seguente illustra un servizio esterno altamente disponibile, indicato in arancione, che dipende da un altro servizio interno, indicato in verde. Un design semplice configura entrambi i servizi come consumer di zone di disponibilità EC2 indipendenti. Ognuno dei servizi arancione e verde è preceduto da una Application Load Balancer, e ogni servizio ha un parco istanze con host di back-end distribuiti su tre zone di disponibilità. Un servizio regionale altamente disponibile chiama un altro servizio regionale altamente disponibile. È un design semplice, e per molti dei servizi che abbiamo creato, è un buon design.

Supponiamo, tuttavia, che il servizio verde sia un servizio fondamentale. In altre parole, supponiamo che sia destinato non solo a essere altamente disponibile, ma anche, di per sé, a fungere da elemento costitutivo per garantire l'indipendenza della zona di disponibilità. In questo caso, potremmo invece progettarlo come se fossero tre istanze di un servizio locale di zona su cui seguiamo le pratiche consigliate di distribuzione della zona di disponibilità. Lo schema seguente illustra il progetto in cui un servizio regionale altamente disponibile chiama un servizio zonale altamente disponibile.

Le ragioni per cui progettiamo i nostri servizi di blocco predefinito per essere indipendenti dalla zona di disponibilità si riducono a un semplice calcolo aritmetico. Immaginiamo che una zona di disponibilità sia danneggiata. In caso di guasti in bianco e nero, l'Application Load Balancer si allontanerà automaticamente dai nodi interessati. Comunque, non tutti gli errori sono così lampanti. Ci possono essere errori grigi, come i bug nel software, che il sistema di bilanciamento del carico non sarà in grado di vedere nel controllo di integrità e che non potrà gestire correttamente.
Nell'esempio precedente, in cui un servizio regionale altamente disponibile chiama un altro servizio regionale altamente disponibile, se una richiesta viene inviata attraverso il sistema, con alcune ipotesi semplificatrici, la possibilità che la richiesta eviti la zona di disponibilità danneggiata è di 2/3 * 2/3 * 2/3 = 4/9. Cioè, la richiesta è peggiore delle probabilità di evitare l'evento. Al contrario, se abbiamo creato il servizio verde per essere un servizio zonale come nell'esempio attuale, allora gli host del servizio arancione possono chiamare l'endpoint verde nella stessa zona di disponibilità. Con questa architettura, le possibilità di evitare la zona di disponibilità danneggiata sono 2/3. Se N servizi fanno parte di questo percorso di chiamate, allora questi numeri tendono a (2/3)^N per N servizi regionali, mentre rimangono costanti a 2/3 per N servizi di zona.
Ecco perché abbiamo costruito il gateway NAT di Amazon EC2 NAT come servizio zonale. Il gateway NAT è una funzionalità di Amazon EC2 che consente il traffico Internet in uscita da una sottorete privata e non appare come un gateway regionale a livello di VPC, ma come una risorsa zonale per cui i clienti avviano un'istanza in modo separato a seconda della zona di disponibilità, come mostrato nel diagramma seguente. Il gateway NAT si trova nel percorso di connettività internet per il VPC, ed è quindi parte del piano dati di qualsiasi istanza EC2 all'interno di quel VPC. Se c'è un danneggiamento di connettività in una zona di disponibilità, è bene circoscrivere il problema all'interno di quella medesima zona piuttosto che estenderlo ad altre zone. Alla fine, l'obiettivo è che il cliente che ha costruito un'architettura simile a quella menzionata in questo articolo (cioè, eseguendo il provisioning di un parco istanze su tre zone di disponibilità con una capacità sufficiente in due qualsiasi zone per trasportare il carico completo) sappia che le altre zone di disponibilità non saranno affatto influenzate da ciò che accade nella zona di disponibilità danneggiata. L'unico modo in cui possiamo farlo è garantendo che tutti i componenti fondamentali, come il gateway NAT, rimangano realmente all'interno della zona di disponibilità.
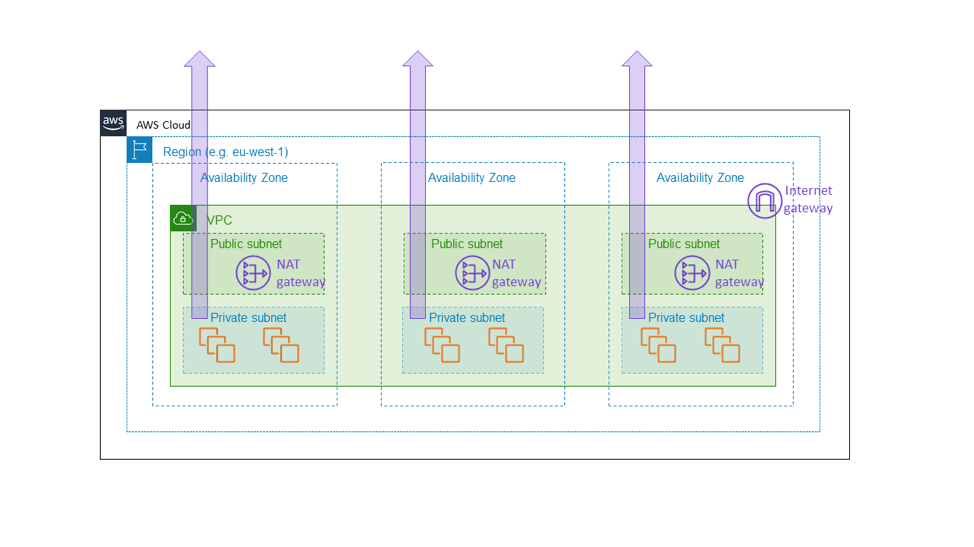
Questa scelta comporta il costo di una maggiore complessità. Per noi, in Amazon EC2, l'ulteriore complessità è rappresentata dalla gestione di ambienti di servizio zonale piuttosto che regionale. Per i clienti del gateway NAT, l'ulteriore complessità consiste nell'avere più gateway NAT e tabelle di routing da utilizzare nelle diverse zone di disponibilità del VPC. La complessità aggiuntiva è appropriata perché il gateway NAT è esso stesso un servizio fondamentale, parte del piano dati Amazon EC2 che dovrebbe fornire garanzie di disponibilità zonale.
C'è un'altra considerazione che facciamo quando creiamo servizi che sono indipendenti dalla zona di disponibilità, e cioè la durata dei dati. Sebbene ciascuna delle architetture zonali descritte in precedenza mostra l'intero stack contenuto in una singola zona di disponibilità, replichiamo qualsiasi stato difficile in più zone di disponibilità per scopi di ripristino di emergenza. Ad esempio, di solito facciamo backup periodici dei database in Amazon S3 e conserviamo repliche in lettura dei nostri archivi di dati in tutta la zona di disponibilità. Queste repliche non sono necessarie per il funzionamento della zona di disponibilità primaria. Al contrario, ci assicurano che stiamo immagazzinando dati critici per i clienti o per l'azienda in più ubicazioni.
Quando si progetta un'architettura orientata ai servizi che verrà eseguita in AWS, abbiamo imparato a utilizzare uno di questi due modelli o una combinazione di entrambi:
• Il modello più semplice: regionale-chiamate-regionale. Questa è spesso la scelta migliore per i servizi rivolti all'esterno ed è appropriata anche per la maggior parte dei servizi interni. Ad esempio, quando creiamo servizi applicativi di livello superiore in AWS, come Amazon API Gateway e tecnologie serverless AWS, utilizziamo questo modello per fornire un'elevata disponibilità anche a fronte di danneggiamento delle zone di disponibilità.
• Il modello più complesso: regionale-chiamate-zonale o zonale-chiamate-zonale. Quando si progettano componenti interni, e in alcuni casi esterni, del piano dati all'interno di Amazon EC2 (ad esempio, dispositivi di rete o altre infrastrutture che si trovano direttamente nel percorso dati critici), seguiamo lo schema di indipendenza della zona di disponibilità e utilizziamo istanze che sono conservate nelle zone di disponibilità, in modo che il traffico di rete rimanga nella sua stessa zona di disponibilità. Questo modello non solo aiuta a mantenere i danneggiamenti isolati a una zona di disponibilità, ma ha anche caratteristiche favorevoli per quanto riguarda il costo del traffico di rete in AWS.
Conclusione
In questo articolo, abbiamo parlato di alcune semplici strategie usate in AWS per utilizzare con successo le dipendenze sulle zone di disponibilità. Abbiamo imparato che la chiave della stabilità statica è quella di anticipare i danneggiamenti prima che si verifichino. Sia che un sistema funzioni su un parco istanze attivo-attivo scalabile orizzontalmente, sia che si tratti di un modello con stato, attivo-standby, possiamo utilizzare le zone di disponibilità per raggiungere alti livelli di disponibilità. Utilizziamo i nostri sistemi in modo che sia già stato eseguito il provisioning di tutta la capacità necessaria in caso di danneggiamento e che essa sia pronta per l'utilizzo. Infine, abbiamo approfondito il modo in cui Amazon EC2 utilizza i concetti di stabilità statica per mantenere le zone di disponibilità indipendenti l'una dall'altra.
Informazioni sull'autore

Becky Weiss è Senior Principal Engineer presso Amazon Web Services. Si occupa attualmente di Identity and Access Management in AWS e, in generale, di fornire controlli di sicurezza flessibili, completi e accreditati per i clienti nel cloud. Precedentemente, ha lavorato presso Amazon Virtual Private Cloud (cioè il networking) e AWS Lambda, e ha anche lavorato con AWS Professional Services per aiutare i clienti aziendali a proteggere con successo i loro ambienti in AWS. Becky è anche la più grande fan di AWS e, nel suo tempo libero, costruisce ogni sorta di cosa, utile e inutile, sull'AWS. Prima di lavorare in AWS, Becky ha lavorato per Microsoft su Windows e Windows Phone.

Mike Furr è Principal Engineer presso Amazon Web Services. È entrato in Amazon nel 2009 dopo aver completato il suo dottorato di ricerca in Informatica presso l'Università del Maryland, College Park. Durante la sua permanenza in Amazon, ha lavorato su Virtual Private Cloud, Direct Connect, oltre che sullo stack di conteggio e fatturazione AWS. Ora si occupa di EC2, aiutando le squadre a scalare il cloud.