



Qu'est-ce que MLOps ?
Les opérations de machine learning (MLOps) sont un ensemble de pratiques qui automatisent et simplifient les flux de travail et les déploiements de machine learning (ML). Le machine learning et l’intelligence artificielle (IA) sont des fonctionnalités essentielles que vous pouvez mettre en œuvre pour résoudre des problèmes complexes du monde réel et apporter de la valeur à vos clients. MLOps est une culture et une pratique du ML qui unifient le développement d'applications de ML (Dev) avec le déploiement et les opérations (Ops) du système de ML. Votre organisation peut utiliser MLOps pour automatiser et standardiser les processus tout au long du cycle de vie du machine learning. Ces processus incluent le développement de modèles, les tests, l'intégration, la publication et la gestion de l'infrastructure.
Pourquoi le système MLOps est-il nécessaire ?
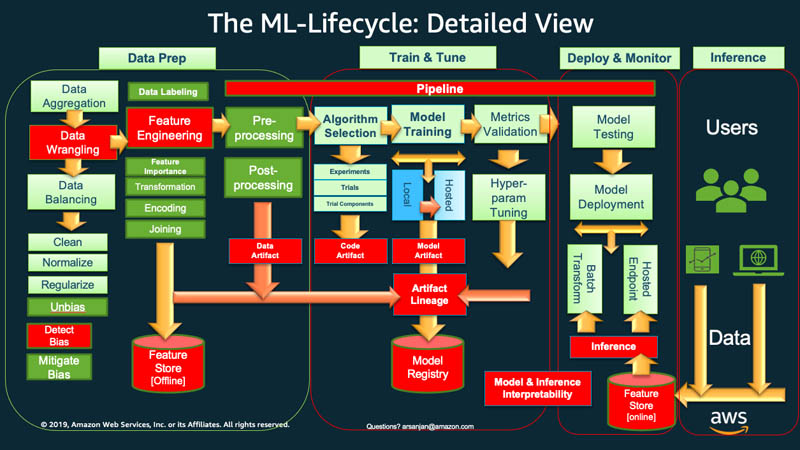
À un niveau élevé, pour démarrer le cycle de vie de machine learning, votre entreprise doit généralement commencer par la préparation des données. Vous récupérez des données de différents types à partir de différentes sources et vous effectuez des activités telles que l'agrégation, le nettoyage des doublons et l'ingénierie des fonctionnalités.
Ensuite, vous utilisez les données pour entraîner et valider le modèle ML. Vous pouvez ensuite déployer le modèle formé et validé en tant que service de prédiction auquel d'autres applications peuvent accéder via des API.
L'analyse exploratoire des données vous oblige souvent à expérimenter différents modèles jusqu'à ce que la meilleure version du modèle soit prête pour le déploiement. Cela entraîne de fréquents déploiements de versions de modèles et une gestion des versions des données. Le suivi des expériences et la gestion du pipeline de formation au machine learning sont essentiels avant que vos applications puissent intégrer ou utiliser le modèle dans leur code.
MLOps est essentiel pour gérer systématiquement et simultanément la publication de nouveaux modèles de machine learning avec le code d'application et les modifications de données. Une implémentation MLOps optimale traite les actifs de ML de la même manière que les autres actifs logiciels de l'environnement d'intégration et de livraison continues (CI/CD). Vous déployez des modèles de machine learning parallèlement aux applications et services qu'ils utilisent et à ceux qui les consomment dans le cadre d'un processus de publication unifié.
Quels sont les principes de MLOps ?
Ensuite, nous expliquons quatre principes clés de MLOps.
Contrôle de version
Ce processus implique le suivi des modifications apportées aux ressources de machine learning afin que vous puissiez reproduire les résultats et revenir aux versions précédentes si nécessaire. Chaque code de formation ou spécification de modèle de ML passe par une phase de révision du code. Chacun est versionné pour rendre la formation de modèles de ML reproductible et auditable.
La reproductibilité d'un flux de travail de ML est importante à chaque phase, du traitement des données au déploiement du modèle de ML. Cela signifie que chaque phase doit produire des résultats identiques avec les mêmes données d'entrée.
Automatisation
Automatisez les différentes étapes du pipeline de machine learning pour garantir la répétabilité, la cohérence et la capacité de mise à l'échelle. Cela inclut les étapes allant de l'ingestion des données, du prétraitement, de la formation des modèles et de la validation jusqu'au déploiement.
Voici quelques facteurs susceptibles de déclencher la formation et le déploiement automatisés des modèles :
- Messagerie
- Événements de surveillance ou du calendrier
- Modifications des données
- Modifications du code d'entraînement du modèle
- Modifications du code de l'application.
Les tests automatisés vous aident à détecter les problèmes à un stade précoce afin de les corriger rapidement et d'en tirer des enseignements. L'automatisation est plus efficace avec l'infrastructure en tant que code (IaC). Vous pouvez utiliser des outils pour définir et gérer l'infrastructure. Cela permet de garantir qu'il est reproductible et qu'il peut être déployé de manière cohérente dans différents environnements.
X continu
Grâce à l'automatisation, vous pouvez exécuter des tests en continu et déployer du code dans votre pipeline ML.
Dans MLOps, le terme continu fait référence à quatre activités qui se produisent en continu si une modification est apportée n'importe où dans le système :
- L'intégration continue étend la validation et le test du code aux données et aux modèles du pipeline
- La livraison continue déploie automatiquement le modèle nouvellement formé ou le service de prédiction de modèles
- La formation continue reforme automatiquement les modèles de machine learning en vue de leur redéploiement
- La surveillance continue concerne la surveillance des données et la surveillance des modèles à l'aide de métriques liées à l'entreprise
Gouvernance du modèle
La gouvernance implique la gestion de tous les aspects des systèmes de machine learning dans un souci d'efficacité. Vous devez effectuer de nombreuses activités de gouvernance :
- Favoriser une collaboration étroite entre les scientifiques des données, les ingénieurs et les parties prenantes de l'entreprise
- Utiliser une documentation claire et des canaux de communication efficaces pour garantir que tout le monde est aligné
- Mettre en place des mécanismes permettant de recueillir des informations sur les prévisions des modèles et de perfectionner les modèles
- Vérifier que les données sensibles sont protégées, que l'accès aux modèles et à l'infrastructure est sécurisé et que les exigences de conformité sont respectées
Il est également essentiel de disposer d'un processus structuré pour examiner, valider et approuver les modèles avant leur mise en ligne. Cela peut impliquer de vérifier l'équité, les préjugés et les considérations éthiques.
Quels sont les avantages de MLOps ?
Le machine learning aide les entreprises à analyser les données et à en retirer des informations utiles à la prise de décision. Cependant, il s'agit d'un domaine innovant et expérimental qui comporte ses propres défis. La protection des données sensibles, les petits budgets, les pénuries de compétences et l'évolution constante de la technologie limitent le succès d'un projet. Sans contrôle ni conseils, les coûts peuvent monter en flèche et les équipes de science des données risquent de ne pas atteindre les résultats souhaités.
MLOps fournit une carte pour guider les projets de ML vers le succès, quelles que soient les contraintes. Voici quelques avantages clés de MLOps.
Délais de commercialisation réduits
MLOps fournit à votre organisation un cadre lui permettant d'atteindre ses objectifs en matière de science des données plus rapidement et plus efficacement. Vos développeurs et responsables peuvent devenir plus stratégiques et plus agiles dans la gestion des modèles. Les ingénieurs en ML peuvent approvisionner l'infrastructure via des fichiers de configuration déclaratifs afin de démarrer les projets plus facilement.
L'automatisation de la création et du déploiement des modèles permet d'accélérer les délais de mise sur le marché et de réduire les coûts d'exploitation. Les scientifiques des données peuvent rapidement explorer les données d'une organisation afin d'apporter une plus grande valeur commerciale à tous.
Amélioration de la productivité
Les pratiques MLOps augmentent la productivité et accélèrent le développement de modèles de machine learning. Par exemple, vous pouvez standardiser l'environnement de développement ou d'expérimentation. Vos ingénieurs en ML peuvent ensuite lancer de nouveaux projets, alterner entre les projets et réutiliser des modèles de ML dans toutes les applications. Ils peuvent créer des processus reproductibles pour une expérimentation rapide et une formation de modèles. Les équipes d'ingénierie logicielle peuvent collaborer et se coordonner tout au long du cycle de développement du logiciel de ML pour une plus grande efficacité.
Déploiement efficace des modèles
MLOps améliore le dépannage et la gestion des modèles en production. Par exemple, les ingénieurs logiciels peuvent surveiller les performances des modèles et reproduire le comportement à des fins de résolution des problèmes. Ils peuvent suivre et gérer de manière centralisée les versions des modèles et choisir celle qui convient le mieux aux différents cas d'utilisation professionnels.
Lorsque vous intégrez des flux de travail de modèles à des pipelines d'intégration continue et de livraison continue (CI/CD), vous limitez la dégradation des performances et maintenez la qualité de votre modèle. Cela est vrai même après les mises à niveau et le réglage du modèle.
Comment mettre en œuvre MLOps dans l'organisation
Il existe trois niveaux de mise en œuvre de MLOps, en fonction de la maturité de l'automatisation au sein de votre organisation.
MLOps niveau 0
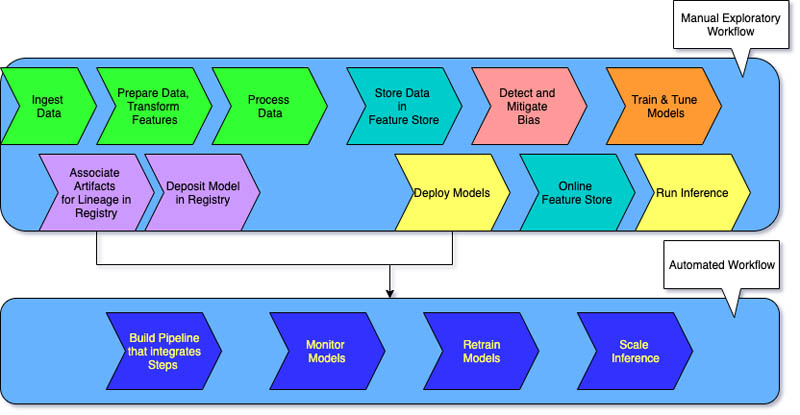
Des flux de travail manuels de machine learning et un processus piloté par des scientifiques des données caractérisent le niveau 0 pour les entreprises qui commencent tout juste à utiliser des systèmes de machine learning.
Chaque étape est manuelle, y compris la préparation des données, la formation au machine learning, ainsi que les performances et la validation des modèles. Cela nécessite une transition manuelle entre les étapes, chaque étape étant exécutée et gérée de manière interactive. Les scientifiques des données transmettent généralement des modèles formés sous forme d'artefacts que l'équipe d'ingénierie déploie sur l'infrastructure d'API.
Le processus fait la distinction entre les scientifiques des données qui créent le modèle et les ingénieurs qui le déploient. Les publications peu fréquentes signifient que les équipes de science des données ne peuvent reformer les modèles que quelques fois par an. Aucune considération CI/CD n'est prise en compte pour les modèles ML avec le reste du code de l'application. De même, la surveillance active des performances est inexistante.
MLOps niveau 1
Les entreprises qui souhaitent former les mêmes modèles avec de nouvelles données ont souvent besoin d'une mise en œuvre de maturité de niveau 1. MLOps niveau 1 vise à former le modèle en continu en automatisant le pipeline ML.
Au niveau 0, vous devez déployer un modèle formé en production. En revanche, pour le niveau 1, vous devez déployer un pipeline de formation qui s'exécute de manière récurrente pour appliquer le modèle entraîné à vos autres applications. Au minimum, vous parvenez à fournir en continu le service de prédiction du modèle.
La maturité de niveau 1 présente les caractéristiques suivantes :
- Étapes d'expérimentation de ML rapide qui impliquent une automatisation significative
- Formation continue du modèle en production avec de nouvelles données comme déclencheurs de pipeline en temps réel
- Mise en œuvre du même pipeline dans les environnements de développement, de préproduction et de production
Vos équipes d'ingénierie travaillent avec des scientifiques des données pour créer des composants de code modularisés réutilisables, composables et éventuellement partageables sur des pipelines de machine learning. Vous créez également un magasin de fonctionnalités centralisé qui normalise le stockage, l'accès et la définition des fonctionnalités pour la formation et le service de machine learning. En outre, vous pouvez gérer les métadonnées, telles que les informations relatives à chaque cycle du pipeline et les données de reproductibilité.
MLOps niveau 2
MLOps niveau 2 est destiné aux organisations qui souhaitent expérimenter davantage et créer fréquemment des modèles nécessitant une formation continue. Ce système convient aux entreprises axées sur la technologie qui mettent à jour leurs modèles en quelques minutes, les reforment toutes les heures ou tous les jours et les redéploient simultanément sur des milliers de serveurs.
Puisque plusieurs pipelines ML sont en jeu, une configuration MLOps de niveau 2 nécessite toute la configuration MLOps de niveau 1. Ce système nécessite également les éléments suivants :
- Orchestrateur de pipeline ML
- Registre de modèles pour le suivi de plusieurs modèles
Les trois étapes suivantes se répètent à l'échelle pour plusieurs pipelines de ML afin de garantir la livraison continue du modèle.
Construire le pipeline
Vous testez de manière itérative de nouvelles modélisations et de nouveaux algorithmes de machine learning tout en vous assurant que les étapes d'expérimentation sont orchestrées. Cette étape génère le code source de vos pipelines ML. Vous stockez le code dans un référentiel source.
Déployer le pipeline
Ensuite, vous créez le code source et exécutez des tests pour obtenir les composants du pipeline destinés au déploiement. Le résultat est un pipeline déployé avec l'implémentation du nouveau modèle.
Servir le pipeline
Enfin, vous servez le pipeline en tant que service de prédiction pour vos applications. Vous collectez des statistiques sur le service de prédiction de modèles déployé à partir de données réelles. La sortie de cette étape est un déclencheur pour exécuter le pipeline ou un nouveau cycle d'expérimentation.
Quelle est la différence entre MLOps et DevOps ?
MLOps et DevOps sont deux pratiques qui visent à améliorer les processus dans lesquels vous développez, déployez et surveillez des applications logicielles.
DevOps vise à combler le fossé entre les équipes de développement et les équipes d'exploitation. DevOps permet de garantir que les modifications du code sont automatiquement testées, intégrées et déployées en production de manière efficace et fiable. Ce système promeut une culture de collaboration afin d'accélérer les cycles de distribution, d'améliorer la qualité des applications et d'utiliser les ressources de manière plus efficace.
MLOps, en revanche, est un ensemble de meilleures pratiques spécialement conçues pour les projets de machine learning. Bien qu'il puisse être relativement simple de déployer et d'intégrer des logiciels traditionnels, les modèles de machine learning présentent des défis uniques. Ils impliquent la collecte de données, la formation des modèles, la validation, le déploiement, ainsi que la surveillance et le recyclage continus.
MLOps se concentre sur l'automatisation du cycle de vie du machine learning. Cela permet de garantir que les modèles ne sont pas seulement développés, mais également déployés, surveillés et reformés de manière systématique et répétée. Il intègre les principes DevOps au ML. Les MLOps se traduisent par un déploiement plus rapide des modèles de machine learning, une meilleure précision au fil du temps et une meilleure assurance qu'ils apportent une réelle valeur commerciale.
Comment les services AWS peuvent-ils prendre en charge vos besoins MLOps ?
Amazon SageMaker est un service entièrement géré que vous pouvez utiliser pour préparer des données et créer, former et déployer des modèles de machine learning. Ce service convient à tous les cas d'utilisation avec une infrastructure, des outils et des flux de travail entièrement gérés.
SageMaker fournit des outils spécialement conçus pour MLOps afin d'automatiser les processus tout au long du cycle de vie du machine learning. En utilisant les outils Sagemaker pour MLOps, vous pouvez rapidement atteindre une maturité MLOps de niveau 2 à l'échelle.
Voici les principales fonctionnalités de SageMaker que vous pouvez utiliser :
- Utilisez SageMaker Experiments pour assurer le suivi des artefacts liés à vos travaux de formation de modèles, comme des paramètres, des métriques et des jeux de données.
- Configurez les SageMaker Pipelines pour qu'ils s'exécutent automatiquement, à intervalles réguliers ou lorsque certains événements sont déclenchés.
- Utilisez le Registre des modèles SageMaker pour suivre les versions des modèles. Vous pouvez également suivre leurs métadonnées, telles que le regroupement de cas d'utilisation et les lignes de base des indicateurs de performance des modèles dans un référentiel central. Vous pouvez utiliser ces informations pour choisir le meilleur modèle en fonction des besoins de votre entreprise.
Commencez à utiliser MLOps sur Amazon Web Services (AWS) en créant un compte dès aujourd'hui.