Souhaitez-vous recevoir des notifications chaque fois que de nouveaux contenus sont ajoutés à la bibliothèque ?
De Becky Weiss et Mike Furr
Chez Amazon, les services que nous élaborons doivent répondre à des objectifs de très haute disponibilité. Cela signifie que nous devons réfléchir attentivement aux dépendances que nos systèmes prennent. Nous concevons nos systèmes de manière à rester résilients même lorsque ces dépendances sont déficientes. Dans cet article, nous allons définir un modèle que nous utilisons appelé stabilité statique pour atteindre ce niveau de résilience. Nous vous montrerons comment nous appliquons ce concept aux zones de disponibilité, un élément constitutif clé de l'infrastructure dans AWS et, par conséquent, une dépendance fondamentale sur laquelle reposent tous nos services.
Dans une conception statiquement stable, l'ensemble du système continue de fonctionner même lorsqu'une dépendance devient déficiente. Peut-être que le système ne voit pas les informations mises à jour (telles que les nouvelles choses, les choses supprimées ou les choses modifiées) que sa dépendance était supposée avoir fournies. Cependant, tout ce qu'il faisait avant que la dépendance ne soit déficiente continue de fonctionner malgré la dépendance déficiente. Nous allons décrire comment nous avons développé Amazon Elastic Compute Cloud (EC2) pour qu'il soit stable statiquement. Ensuite, nous fournirons deux exemples d'architectures statiquement stables que nous avons trouvées utiles pour construire des systèmes régionaux hautement disponibles en plus des zones de disponibilité.
Enfin, nous approfondirons certains aspects de la philosophie de conception d'Amazon EC2, notamment la manière dont son architecture est conçue pour assurer l'indépendance de la zone de disponibilité au niveau du logiciel. De plus, nous discuterons de certains des compromis qui accompagnent le développement d'un service avec ce choix d'architecture.
Stabilité statique
• Il attribue une interface réseau à partir du sous-réseau VPC.
• Il prépare un volume Amazon Elastic Block Store (EBS).
• Il génère des informations d'identification de rôle AWS Identity and Access Management (IAM).
• Il installe les règles du groupe de sécurité.
• Il stocke les résultats dans les mémoires de données des différents services en aval.
• Il propage les configurations nécessaires au serveur dans le VPC et à la périphérie du réseau, le cas échéant.
• Il lit et écrit à partir des volumes EBS d'Amazon.
• Et ainsi de suite.
• Il est typique que le plan de données fonctionne à un volume plus élevé (souvent par ordre de grandeur) que son plan de contrôle. Il est donc préférable de les séparer pour que chacun puisse être mis à l'échelle en fonction de ses propres dimensions de mise à l'échelle.
• Au fil des ans, nous avons constaté que le plan de contrôle d'un système a tendance à avoir plus de pièces mobiles que son plan de données, donc statistiquement, il est plus susceptible d'être affaibli pour cette seule raison.
Modèles de stabilité statique
Dans cette section, nous présenterons deux modèles de haut niveau que nous utilisons dans AWS pour concevoir des systèmes à haute disponibilité en tirant parti de la stabilité statique. Chacune est applicable à son propre ensemble de situations, mais toutes deux tirent profit de l'abstraction de la zone de disponibilité.

En cas de dégradation d'une zone de disponibilité, l'architecture présentée dans le schéma précédent ne nécessite aucune action. Les instances EC2 dans la zone de disponibilité altérée commenceront à échouer aux bilans de santé, et l'équilibreur de charge d'application déplacera le trafic loin d'eux. En fait, le service Elastic Load Balancing est conçu selon ce principe. Elle dispose d'une capacité d'équilibrage de charge suffisante pour faire face à une dégradation de la zone de disponibilité sans avoir besoin d'une mise à l'échelle.
Nous utilisons également ce modèle même lorsqu'il n'y a pas d'équilibreur de charge ou de service HTTPS. Par exemple, une flotte d'instances EC2 qui traite les messages d'une file d'attente Amazon Simple Queue Service (SQS) peut également suivre ce modèle. Les instances sont déployées dans un groupe Auto Scaling sur plusieurs zones de disponibilité, avec une surprovision appropriée. En cas de zone de disponibilité détériorée, le service ne fait rien. Les instances défaillantes cessent de faire leur travail, et d'autres prennent le relais.

Comme dans le cas de l'exemple de la zone de disponibilité sans état, active-active, lorsque la zone de disponibilité avec le nœud primaire est défaillante, le service dynamique ne fait rien avec l'infrastructure. Pour les services qui utilisent Amazon RDS, RDS gérera le basculement et redirigera le nom DNS vers la nouvelle primaire dans la zone de disponibilité opérationnelle. Ce schéma s'applique également à d'autres configurations de veille active, même si elles n'utilisent pas de base de données relationnelle. En particulier, nous l'appliquons aux systèmes avec une architecture de groupe qui possède un nœud leader. Nous déployons ces groupes sur l'ensemble des zones de disponibilité et sélectionnons le nouveau nœud leader à partir d'un candidat en attente au lieu de lancer un remplacement « juste à temps ».
Ce que ces deux modèles ont en commun, c'est qu'ils avaient déjà provisionné la capacité dont ils auraient besoin dans l'éventualité d'une perte de capacité dans une zone de disponibilité bien avant toute perte de capacité réelle. Dans aucun de ces cas, le service ne dépend délibérément d'un plan de contrôle, comme l'approvisionnement d'une nouvelle infrastructure ou l'apport de modifications, en réponse à une dégradation de la zone de disponibilité.
Sous le capot : Stabilité statique à l'intérieur d'Amazon EC2
Cette dernière section de l'article approfondira les architectures résilientes des zones de disponibilité, couvrant certaines des manières dont nous suivons le principe de l'indépendance de la zone de disponibilité dans Amazon EC2. Comprendre certains de ces concepts est utile lorsque nous développons un service qui doit non seulement être hautement disponible lui-même, mais qui doit aussi fournir une infrastructure sur laquelle d'autres peuvent être hautement disponibles. Amazon EC2, en tant que fournisseur d'infrastructure AWS de bas niveau, est l'infrastructure que les applications peuvent utiliser pour être hautement disponibles. Il y a des moments où d'autres systèmes pourraient souhaiter adopter cette stratégie également.
Nous suivons le principe d'indépendance de la zone de disponibilité dans Amazon EC2 dans nos pratiques de déploiement. Dans Amazon EC2, le logiciel est déployé sur les serveurs physiques hébergeant les instances EC2, les périphériques, les résolveurs DNS, les composants du plan de contrôle dans le chemin de lancement des instances EC2, et de nombreux autres composants dont dépendent les instances EC2. Ces déploiements suivent un calendrier de déploiement zonal. Cela signifie que deux zones de disponibilité dans la même région recevront un déploiement donné à des jours différents. Dans l'ensemble d’AWS, nous procédons à un déploiement progressif des déploiements. Par exemple, nous suivons la meilleure pratique (quel que soit le type de service sur lequel nous déployons) de déployer d'abord une boîte unique, puis 1/N de serveurs, etc. Cependant, dans le cas spécifique de services comme ceux d'Amazon EC2, nos déploiements vont plus loin et sont délibérément alignés sur la limite de la zone de disponibilité. De cette façon, un problème avec un déploiement affecte une zone de disponibilité et est annulé et corrigé. Il n'affecte pas les autres zones de disponibilité, qui continuent à fonctionner normalement.
Une autre façon d'utiliser le principe des zones de disponibilité indépendantes lorsque nous développons Amazon EC2 est de concevoir tous les flux de paquets pour rester dans la zone de disponibilité plutôt que de traverser les frontières. Ce deuxième point, à savoir que le trafic réseau reste local dans la zone de disponibilité, mérite d'être exploré plus en détail. C'est une illustration intéressante de la façon dont nous pensons différemment lorsque nous développons un système régional hautement disponible qui est un consommateur de zones de disponibilité indépendantes (c'est-à-dire qu'il utilise les garanties d'indépendance de la zone de disponibilité comme base pour développer un service haute disponibilité), par opposition à lorsque nous fournissons une infrastructure indépendante de la zone de disponibilité aux autres qui leur permettra de développer pour la haute disponibilité.
Le schéma suivant illustre un service externe hautement disponible, représenté en orange, qui dépend d'un autre service interne, représenté en vert. Une conception simple traite ces deux services comme des consommateurs de zones de disponibilité EC2 indépendantes. Chacun des services orange et vert est précédé d'un Application Load Balancer, et chaque service dispose d'une flotte bien fournie d'hôtes d’arrière plan répartis sur trois zones de disponibilité. Un service régional très disponible appelle un autre service régional très disponible. Il s'agit d'une conception simple, et pour plusieurs des services que nous avons développés, c'est une bonne conception.

Supposons, cependant, que le service vert soit un service de base. En d'autres termes, supposons qu'il soit non seulement destiné à être hautement disponible, mais aussi à servir lui-même de base pour assurer l'indépendance de la zone de disponibilité. Dans ce cas, nous pourrions plutôt le concevoir comme trois instances d'un service zone-local, sur lequel nous suivons les pratiques de déploiement en fonction de la zone de disponibilité. Le diagramme suivant illustre la conception dans laquelle un service régional hautement disponible appelle un service zonal hautement disponible.

Les raisons pour lesquelles nous concevons nos services de base de façon à ce qu'ils soient indépendants de la zone de disponibilité se résument à de simples calculs arithmétiques. Disons qu'une zone de disponibilité est déficiente. Pour les défaillances en noir et blanc, l'Application Load Balancer échouera automatiquement loin des nœuds affectés. Cependant, tous les échecs ne sont pas aussi évidents. Il peut y avoir des défaillances grises, telles que des bogues dans le logiciel, que l'équilibreur de charge ne pourra pas voir dans son bilan de santé et gérer proprement.
Dans l'exemple précédent, lorsqu'un service régional hautement disponible appelle un autre service régional hautement disponible, si une demande est envoyée par l'intermédiaire du système, alors, avec quelques hypothèses simplificatrices, la probabilité que la demande évite la zone de disponibilité déficiente est 2/3 * 2/3 = 4/9. En d'autres termes, la demande a plus de chances d'être rejetée que l'événement. En revanche, si nous avons développé le service vert comme un service zonal comme dans l'exemple actuel, alors les hôtes du service orange peuvent appeler le terminal vert dans la même zone de disponibilité. Avec cette architecture, les chances d'éviter la zone de disponibilité déficiente sont de 2/3. Si N services font partie de ce chemin d'appel, alors ces numéros se généralisent à (2/3)^N pour N services régionaux au lieu de rester constants aux 2/3 pour N services zonaux.
C'est pour cette raison que nous avons construit la passerelle NAT Amazon EC2 comme un service zonal. La passerelle NAT est une fonctionnalité d'Amazon EC2 qui permet le trafic Internet sortant à partir d'un sous-réseau privé et n'apparaît pas comme une passerelle régionale et à l’échelle du VPC, mais comme une ressource zonale, que les clients instancient séparément par zone de disponibilité comme le montre le diagramme suivant. La passerelle NAT se trouve sur le chemin de la connectivité Internet pour le VPC, et fait donc partie du plan de données de toute instance EC2 dans ce VPC. S'il y a un problème de connectivité dans une zone de disponibilité, nous voulons garder ce problème à l'intérieur de cette zone de disponibilité, plutôt que de l'étendre à d'autres zones. En fin de compte, nous voulons qu'un client qui a construit une architecture similaire à celle mentionnée plus haut dans cet article (c'est-à-dire, en fournissant une flotte dans trois zones de disponibilité avec une capacité suffisante dans deux zones pour transporter la pleine charge) sache que les autres zones de disponibilité ne seront complètement pas affectées par ce qui se passe dans la zone de disponibilité dégradée. La seule façon pour nous d'y parvenir est de nous assurer que tous les éléments fondamentaux, comme la passerelle NAT, restent vraiment dans la zone de disponibilité.
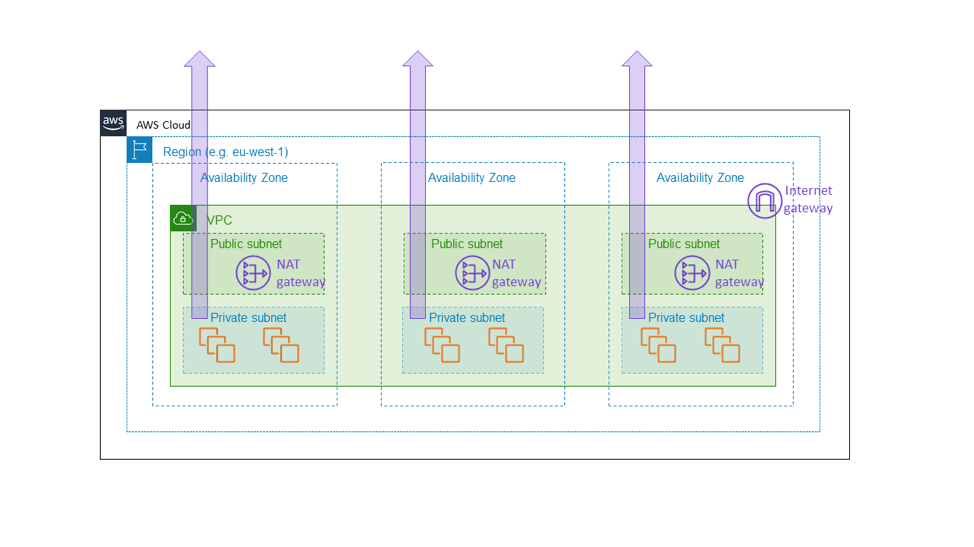
Ce choix s'accompagne d'un surcoût de complexité. Pour nous, dans Amazon EC2, la complexité supplémentaire vient de la gestion des environnements de services zonaux plutôt que régionaux. Pour les clients de la passerelle NAT, la complexité supplémentaire se présente sous la forme de passerelles NAT et de tables de routage multiples, à utiliser dans les différentes zones de disponibilité du VPC. La complexité supplémentaire est appropriée parce que la passerelle NAT est elle-même un service de base, faisant partie du plan de données Amazon EC2 qui est censé fournir des garanties de disponibilité zonale.
Il y a une autre considération que nous prenons en compte lorsque nous développons des services indépendants de la zone de disponibilité, c'est la durabilité des données. Bien que chacune des architectures de zones décrites plus haut montre l'ensemble du bloc contenu dans une seule zone de disponibilité, nous répliquons n'importe quel état dur sur plusieurs zones de disponibilité à des fins de reprise après sinistre. Par exemple, nous stockons généralement des sauvegardes périodiques des bases de données dans Amazon S3 et conservons des répliques lues de nos bases de données au-delà des limites de la zone de disponibilité. Ces répliques ne sont pas nécessaires au fonctionnement de la zone de disponibilité primaire. Au lieu de cela, ils s'assurent que nous stockons les données critiques des clients ou de l'entreprise sur plusieurs sites.
Lors de la conception d'une architecture orientée services qui fonctionnera dans AWS, nous avons appris à utiliser l'un de ces deux modèles, ou une combinaison des deux :
- Le schéma le plus simple : appels régionaux-régionaux. C'est souvent le meilleur choix pour les services externes et cela convient également à la plupart des services internes. Par exemple, lorsque nous créons des services applicatifs de plus haut niveau dans AWS, comme Amazon API Gateway et les technologies sans serveur AWS, nous utilisons ce modèle pour fournir une haute disponibilité, même en cas de dégradation de la zone de disponibilité.
• Le schéma le plus complexe : appels régionaux-zonaux ou appels zonaux-zonaux. Lors de la conception de composants internes et, dans certains cas, externes, de plans de données au sein d'Amazon EC2 (par exemple, des appareils réseau ou d'autres infrastructures qui se trouvent directement dans le chemin de données critiques), nous suivons le modèle de l'indépendance de la zone de disponibilité et utilisons des instances qui sont cloisonnées dans les zones de disponibilité, afin que le trafic réseau reste dans cette même zone. Ce schéma permet non seulement de maintenir les défaillances isolées dans une zone de disponibilité, mais il présente également des caractéristiques de coût de trafic réseau favorables dans AWS.
Conclusion
Dans cet article, nous avons discuté de quelques stratégies simples que nous avons utilisées chez AWS pour réussir à prendre des dépendances sur les zones de disponibilité. Nous avons appris que la clé de la stabilité statique est d'anticiper les défaillances avant qu'elles ne se produisent. Qu'il s'agisse d'un système fonctionnant sur une flotte active-active évolutive horizontalement, ou qu'il s'agisse d'un système dynamique et actif en mode veille, nous pouvons utiliser les zones de disponibilité pour cibler des niveaux élevés de disponibilité. Nous déployons nos systèmes de manière à ce que toute la capacité nécessaire en cas de défaillance soit déjà entièrement provisionnée et prête à démarrer. Enfin, nous avons examiné de plus près comment Amazon EC2 utilise des concepts de stabilité statique pour maintenir les zones de disponibilité indépendantes les unes des autres.
À propos des auteurs

Becky Weiss est ingénieur principal senior chez Amazon Web Services Elle se consacre actuellement sur le service Identity and Access Management d'AWS et plus généralement sur la mise en place de contrôles de sécurité souples, complets et faisant autorité pour les clients dans le cloud. Dans le passé, elle a travaillé sur Amazon Virtual Private Cloud (c’est-à-dire réseautage) et AWS Lambda, et elle a également travaillé avec AWS Professional Services pour aider les entreprises à sécuriser leurs environnements dans AWS. Becky est aussi la plus grande fan d'AWS et, dans ses temps libres, elle développe toutes sortes de choses utiles et inutiles sur AWS. Avant de travailler chez AWS, Becky a travaillé pour Microsoft sur Windows et Windows Phone.

Mike Furr est ingénieur principal chez Amazon Web Services. Il a rejoint Amazon en 2009 après avoir terminé son doctorat en informatique à l'Université du Maryland, College Park. Durant son séjour chez Amazon, il a travaillé sur Virtual Private Cloud, Direct Connect, ainsi que sur le bloc de comptage et de facturation AWS. Il se concentre maintenant sur l'EC2, où il aide les équipes à mettre à l'échelle le cloud.