



¿Qué es el etiquetado de datos?
En machine learning, el etiquetado de datos es el proceso para identificar los datos sin procesar (imágenes, archivos de texto, vídeos, etc.) y agregar una o más etiquetas significativas e informativas para proporcionar contexto, de manera que un modelo de machine learning pueda aprender de ellos. Por ejemplo, las etiquetas pueden indicar si una fotografía contiene un pájaro o un auto, qué palabras se dijeron en una grabación de audio o si una imagen de rayos X contiene un tumor. El etiquetado de datos se requiere para una variedad de casos de uso, incluidos la visión artificial, el procesamiento de lenguaje natural y el reconocimiento de habla.
¿Cómo funciona el etiquetado de datos?
En la actualidad, la mayoría de los modelos prácticos de machine learning utilizan el aprendizaje supervisado, que aplica un algoritmo para asignar una entrada a una salida. Para que el aprendizaje supervisado funcione, necesita un conjunto de datos etiquetados del que el modelo pueda aprender para tomar las decisiones correctas. Por lo general, el etiquetado de datos comienza pidiendo a las personas que emitan juicios sobre un determinado dato no etiquetado. Por ejemplo, se puede pedir a los etiquetadores que etiqueten todas las imágenes de un conjunto de datos en el que se cumpla la condición “la foto contiene un pájaro”. El etiquetado puede ser tan aproximado como una simple clasificación “sí/no” o tan pormenorizado como la identificación de los píxeles específicos de la imagen asociados con el pájaro. El modelo de machine learning utiliza etiquetas proporcionadas por humanos para aprender los patrones subyacentes en un proceso denominado “entrenamiento de modelos”. El resultado es un modelo entrenado que se puede utilizar para hacer predicciones sobre datos nuevos.
En el machine learning, un conjunto de datos debidamente etiquetado que se utiliza como estándar objetivo para entrenar y evaluar un modelo determinado suele denominarse “verdad fundamental”. La precisión de su modelo entrenado dependerá de la precisión de la verdad fundamental, por lo que es esencial dedicar tiempo y recursos a garantizar un etiquetado de datos de alta precisión.
¿Cuáles son algunos tipos comunes de etiquetado de datos?
Visión artificial
Al crear un sistema de visión artificial, primero debe etiquetar imágenes, píxeles o puntos clave, o crear un borde que incluya por completo una imagen digital, lo que se conoce como cuadro delimitador, para generar su conjunto de datos de entrenamiento. Por ejemplo, puede clasificar las imágenes por tipo (por ejemplo, imágenes de productos frente a imágenes de estilo de vida) o contenido (lo que hay realmente en la propia imagen), o puede segmentar una imagen a nivel de píxel. A continuación, puede utilizar estos datos de entrenamiento para crear un modelo de visión artificial que se pueda utilizar para clasificar imágenes automáticamente, detectar la ubicación de objetos, identificar puntos clave de una imagen o segmentarla.
Procesamiento de lenguaje natural
El procesamiento de lenguaje natural requiere que primero identifique de manera manual las secciones importantes del texto o etiquete el texto con etiquetas específicas para generar su conjunto de datos de entrenamiento. Por ejemplo, es posible que desee identificar la opinión o la intención de un texto publicitario, identificar partes del discurso, clasificar los sustantivos propios, como lugares y personas, e identificar el texto en imágenes, archivos PDF u otros archivos. Para ello, puede dibujar recuadros delimitadores alrededor del texto y, a continuación, transcribirlo de forma manual en su conjunto de datos de entrenamiento. Los modelos de procesamiento de lenguaje natural se utilizan para el análisis de opiniones, el reconocimiento de nombres de entidades y el reconocimiento óptico de caracteres.
Procesamiento de audio
El procesamiento de audio convierte todo tipo de sonidos, como habla, ruidos de animales (ladridos, silbidos o trinos) y los sonidos de edificios (cristales rotos, escáneres o alarmas) en un formato estructurado para que pueda usarse en machine learning. Con frecuencia, el procesamiento de audio requiere que primero se transcriba de forma manual en texto escrito. A partir de ahí, puede descubrir información más detallada sobre el audio si agrega etiquetas y clasifica el audio. Este audio clasificado se convierte en el conjunto de datos de entrenamiento.
¿Cuáles son algunas de las prácticas recomendadas para el etiquetado de datos?
Existen muchas técnicas para mejorar la eficiencia y precisión del etiquetado de datos. Algunas de estas técnicas son las siguientes:
- Interfaces de tareas intuitivas y optimizadas para ayudar a minimizar la carga cognitiva y el cambio de contexto para los etiquetadores humanos.
- Consenso de etiquetadores para ayudar a contrarrestar el error/sesgo de los anotadores individuales. El consenso de los etiquetadores implica enviar cada objeto del conjunto de datos a varios anotadores y, a continuación, consolidar sus respuestas (denominadas “anotaciones”) en una sola etiqueta.
- Auditoría de etiquetas para verificar la precisión de las etiquetas y actualizarlas según sea necesario.
- Aprendizaje activo para hacer que el etiquetado de datos sea más eficiente mediante el uso del machine learning a fin de identificar los datos más útiles que pueden etiquetar los seres humanos.
¿Cómo se puede realizar el etiquetado de datos de manera eficiente?
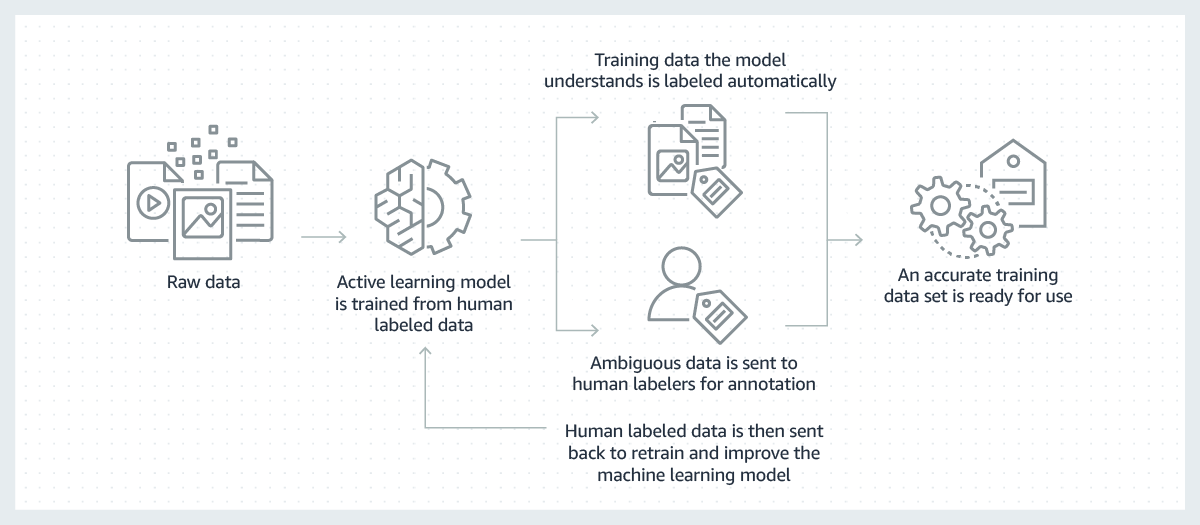
Los modelos de aprendizaje automático con buenos resultados se generan sobre la base de grandes volúmenes de datos de entrenamiento de alta calidad. Sin embargo, el proceso destinado a crear los datos de formación técnica que son necesarios para generar esos modelos suele ser costoso y complicado, y lleva mucho tiempo. La mayoría de los modelos creados hoy en día requieren que un ser humano etiquete los datos manualmente de un modo que permita al modelo aprender a tomar decisiones correctas. Para superar este desafío, el etiquetado puede hacerse más eficiente mediante el uso de un modelo de machine learning que etiquete los datos de modo automático.
En este proceso, un modelo de machine learning para etiquetar datos se entrena primero en un subconjunto de los datos sin procesar que han sido etiquetados por seres humanos. Cuando el modelo de etiquetado tenga plena confianza en sus resultados sobre la base de lo que ha aprendido hasta el momento, aplicará etiquetas de manera automática a los datos sin procesar. Cuando el modelo de etiquetado tenga menor nivel de confianza en sus resultados, pasará los datos a seres humanos a fin de que ellos realicen el etiquetado. A continuación, las etiquetas generadas por seres humanos se devuelven al modelo de etiquetado para que aprenda y mejore su capacidad de etiquetar automáticamente el siguiente conjunto de datos sin procesar. Con el tiempo, el modelo podrá etiquetar más y más datos de forma automática y acelerar de manera considerable la creación de conjuntos de datos de entrenamiento.
¿Cómo puede AWS cumplir con sus requisitos de etiquetado de datos?
Amazon SageMaker Ground Truth reduce significativamente el tiempo y el esfuerzo necesarios para crear conjuntos de datos con fines de entrenamiento. SageMaker Ground Truth ofrece acceso a etiquetadores humanos públicos y privados, y les ofrece interfaces y flujos de trabajo integrados para realizar tareas habituales de etiquetado. Empezar a usar SageMaker Ground Truth es fácil. Puede utilizar el tutorial de introducción para crear su primer trabajo de etiquetado en cuestión de minutos.
Para comenzar a utilizar el etiquetado de datos de AWS, cree una cuenta hoy mismo.
Siguientes pasos en AWS
Obtenga acceso instantáneo al nivel Gratuito de AWS.
Comience a crear en la consola de administración de AWS.