Blog de Amazon Web Services (AWS)
Procesamiento de Video Bajo Demanda con AWS Lambda y FFmpeg
- cambiar el formato o el contenedor del archivo multimedia (reempaquetar/volver a empaquetar)
- recortar archivos multimedia
- convertir archivos de solo audio en audio/vídeo (A/V) mediante la inserción de una secuencia de vídeo de una pizarra, marcos negros o incluso una forma de onda
- convertir audio con velocidad de fotogramas variable (VFR) en audio con velocidad de fotogramas constante (CFR), que es el caso de uso que hemos elegido para esta publicación.
Dependiendo del dispositivo de grabación, el UGC a veces se captura con audio VFR (con teléfonos inteligentes, por ejemplo). El audio VFR a menudo puede provocar problemas de sincronización de audio en las cargas de trabajo multimedia. En esta publicación, creamos una demostración que procesa UGC y convierte el audio de VFR a CFR. La función Lambda que utilizamos se puede utilizar como etapa de preprocesamiento para cargas de trabajo más grandes. Usamos FFmpeg para procesar la transmisión de audio, pero el mismo concepto también puede funcionar con otras herramientas de procesamiento multimedia.
Para crear este flujo de trabajo, se recomienda un conocimiento básico de lenguajes de programación, Lambda, Amazon S3, AWS Identity and Access Management (IAM), FFmpeg, Boto3 y Python.
Descripción general del código
El primero es el comando FFmpeg que ejecutaremos en la función Lambda, donde la salida no se copia a un archivo local, sino que se envía a la salida estándar (stdout). El comando FFmpeg que se utiliza para convertir VFR de audio a CFR es similar al siguiente:
ffmpeg -i <source-file> -f mpegts -c:v copy -af aresample=async=1:first_pts=0 -Explicación de los parámetros:
- “<source-file>” es una URL prefirmada para el objeto Amazon S3. Para esta demostración, solo consideramos los archivos mp4 como fuentes.
- “-f mpegts” representa el formato de la salida.
- “-c:v copy” le dice a FFmpeg que copie el vídeo «tal cual» de la entrada a la salida. Básicamente, solo estamos procesando el audio de esta demostración.
- “-af aresample=async=1:first_pts=0” es el filtro de audio Resampler con la opción “async=1” que convierte el audio a CFR. La opción “first_pts=0” se usa para rellenar la transmisión de audio para que comience desde el principio en sincronía con el vídeo. Algunos dispositivos pueden capturar el UGC y el audio comienza detrás del vídeo.
- El “-“ al final del comando envía la salida de FFmpeg a stdout.
Usamos el formato de salida “mpegts” porque FFmpeg requiere un formato de salida que se pueda buscar cuando se escribe en stdout o, en general, en un pipe. Tenga en cuenta que una canalización (en sistemas tipo Unix) es un búfer creado en la memoria que actúa como canal de comunicación para conectar varios procesos o programas. Puede encontrar una discusión relevante sobre este tema en Stack Overflow aquí.
Al ejecutar el comando anterior mediante el “subproceso” de Python, la salida de FFmpeg es capturada por el subproceso stdout, que se define como una canalización (subprocess.PIPE).
p1 = subprocess.run(<ffmpeg command args>, stdout=subprocess.PIPE, stderr=subprocess.PIPE)La salida de FFmpeg contenida en el subproceso stdout (p1.stdout) se pasará entonces al cliente Boto3 de Amazon S3 como el -parámetro “Body” del método put_object ():
s3client = boto3.client('s3')
response = s3client.put_object(Body=p1.stdout, Bucket=<destination-bucket>, Key=<destination-file-name.ts>)Configurar el flujo de trabajo
Nota: Elija una región de AWS en la que estén disponibles todos los servicios para crear el flujo de trabajo.
1. Configuración de Amazon S3 e IAM
Con la consola Amazon S3, cree dos buckets: uno para los archivos de origen multimedia (ugc-source-bucket ) y otro para los archivos de destino (ugc-destination-bucket ).
En la consola de IAM, cree un rol para Lambda (lambda-ugc-role) que permita leer desde el bucket de origen de Amazon S3 y escribir en el bucket de destino de Amazon S3. Lambda también necesita acceso a los registros de Amazon CloudWatch para solucionar problemas. El siguiente es un ejemplo de una política de Lambda con los permisos mínimos necesarios para esta demostración:
Nota: Actualice los nombres de los depósitos de Amazon S3 en función de los nombres de los depósitos que haya elegido. De igual forma, asegúrese de que el rol creado también contenga los permisos AWSLambdaBasicExecutionRole y AWSLambdaRole.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::ugc-source-bucket/*"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::ugc-destination-bucket/*"
},
{
"Sid": "VisualEditor2",
"Effect": "Allow",
"Action": [
"logs:PutLogEvents",
"logs:CreateLogStream",
"logs:CreateLogGroup"
],
"Resource": "*"
}
]
}
2. Cree la capa Lambda FFmpeg
Antes de empezar, asegúrese de estar familiarizado con los términos de la licencia de FFmpeg y las consideraciones legales que se enumeran aquí. Además, la compilación estática de FFmpeg utilizada en esta demostración está licenciada bajo la licencia GPLv3, como se menciona aquí.
Primero, debemos crear un paquete zip para la capa Lambda que contenga el binario FFmpeg. Este es un resumen de los pasos necesarios para crear el paquete FFmpeg y la capa Lambda. Para crear el paquete, puede utilizar una instancia de EC2 que ejecute la misma imagen de máquina de Amazon (AMI) que utiliza Lambda (tal y como se indica aquí):
The FFmpeg output held in subprocess stdout (p1.stdout) will then be passed to Boto3 Amazon S3 client as the “Body” parameter of put_object() method:
En su directorio de trabajo, descargue y desempaquete la última versión estática de FFmpeg para Linux amd64 desde https://johnvansickle.com/ffmpeg/. Las instrucciones se proporcionan en las preguntas frecuentes de la página y se encuentran en la siguiente sección para mayor comodidad.
wget https://johnvansickle.com/ffmpeg/releases/ffmpeg-release-amd64-static.tar.xz
wget https://johnvansickle.com/ffmpeg/releases/ffmpeg-release-amd64-static.tar.xz.md5
md5sum -c ffmpeg-release-amd64-static.tar.xz.md5
tar xvf ffmpeg-release-amd64-static.tar.xz- El binario de FFmpeg se encuentra en la carpeta “ffmpeg-6.0-amd64-static”
- Cree un paquete ZIP para la capa Lambda de la siguiente manera:
mkdir -p ffmpeg/bin
cp ffmpeg-4.3.1-amd64-static/ffmpeg ffmpeg/bin/
cd ffmpeg
zip -r ../ffmpeg.zip .- Cargue el paquete ffmpeg.zip resultante en Amazon S3 y, a continuación, cree una nueva capa en la consola de Lambda que apunte al paquete, como hicimos en la siguiente imagen. Para esta demostración, solo necesitamos el tiempo de ejecución «Python 3.8»; sin embargo, si lo desea, puede añadir otros tiempos de ejecución compatibles de la lista desplegable a la configuración de capas.
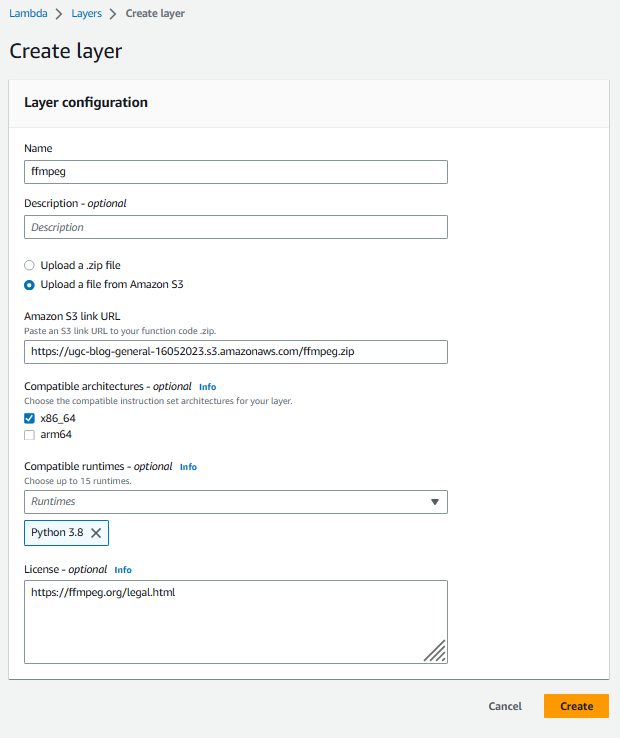
Creación de una capa para FFmpeg en la consola Lambda: introduzca un nombre para la capa y una descripción opcional. Seleccione Cargar un archivo desde Amazon S3 y, a continuación, introduzca la URL del enlace de Amazon S3 al paquete ffmpeg.zip. En el menú desplegable de tiempos de ejecución compatibles, seleccione “Python 3.8”. NOTA: Si descargó FFmpeg para arquitectura amd64, asegúrese que, en el tiempo de ejecución para Lambda la arquitectura sea x86_64. Si lo desea, puede introducir información sobre la licencia y, a continuación, elija “Crear”.
3. Crear la función Lambda
Ahora puede crear una nueva función Lambda en la consola: elija la opción Autor desde cero, rellene la información básica y elija Crear función.
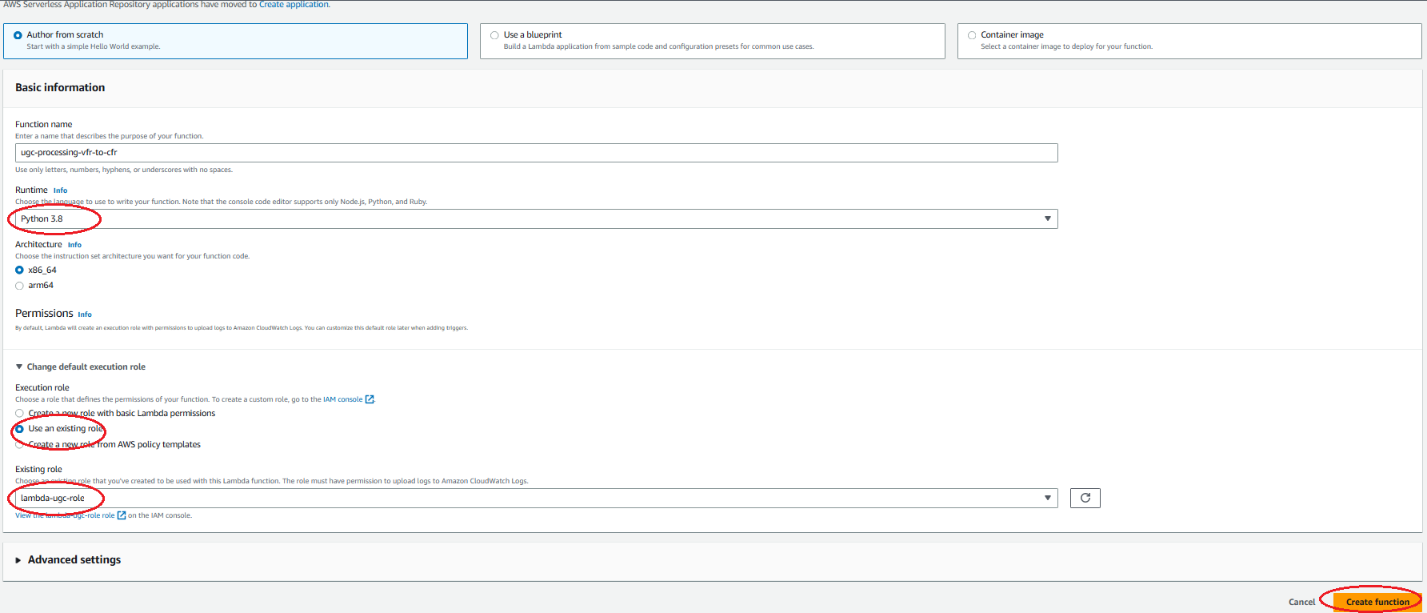
Creación de una función Lambda desde cero en la consola de Lambda: seleccione Autor desde cero. Introduzca el nombre de la función y seleccione “Python 3.8” en Runtime. En Permisos, elija Usar un rol existente y elija el rol que creamos en el primer paso y, a continuación, elija crear función
Una vez creada la función Lambda, seleccione Capas y, a continuación, Añadir una capa. Elija Capas personalizadas. Selecciona “ffmpeg” en la lista desplegable de Capas personalizadas y versión y, a continuación, selecciona Agregar.
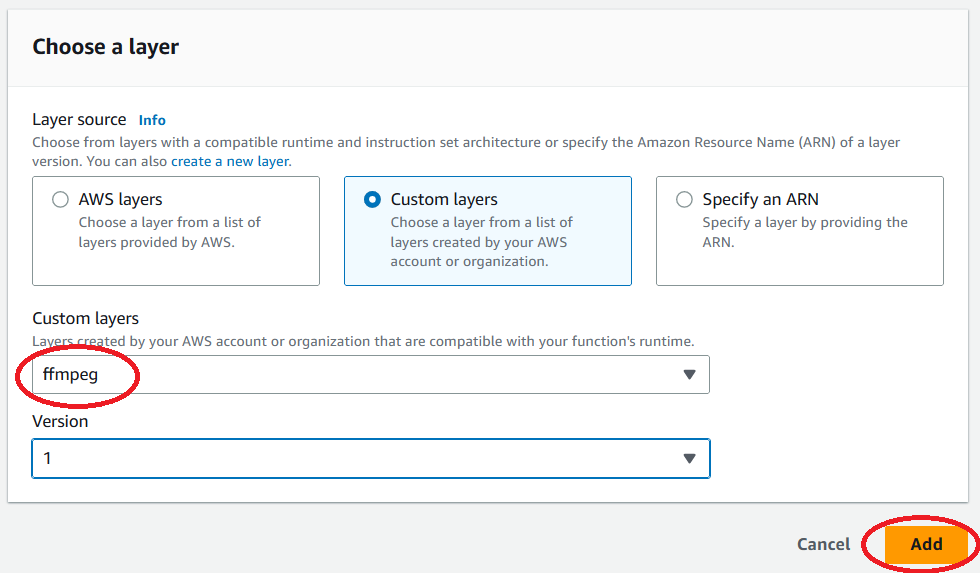
Añadir la capa FFmpeg a la función Lambda de la consola: seleccione Capas personalizadas. Seleccione “ffmpeg” en la lista desplegable de Capas personalizadas y versión y, a continuación, seleccione Agregar.
A continuación, añada su bucket de origen de Amazon S3 como disparador seleccionando + Agregar disparador y seleccionando S3 aws storage. Introduzca el sufijo “.mp4” para limitar las invocaciones de Lambda únicamente a archivos mp4. Lea la sección de invocación recursiva y confirme marcando la casilla y, a continuación, seleccione Agregar.
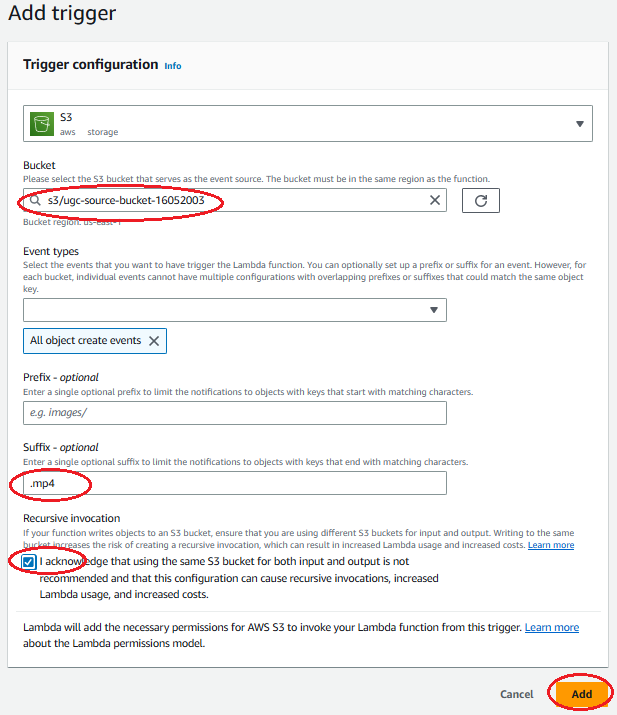
Añadir un disparador de Amazon S3 desde el bucket de origen a la función Lambda de la consola: en Bucket, seleccione el bucket de origen. Seleccione “Todos los eventos de creación de objetos” como Tipo de evento. Introduzca “.mp4” como sufijo. Lea la sección de invocación recursiva y confirme marcando la casilla y, a continuación, seleccione Agregar.
A continuación, edite la configuración básica de la función Lambda para aumentar los valores de memoria y tiempo de espera. Seleccione 2240 MB de memoria y un tiempo de espera de 1 minuto para esta demostración. Estos valores pueden diferir para otros tipos de procesamiento. Analizamos las necesidades de memoria para esta demostración en la sección “Pruebas y resultados” que sigue.
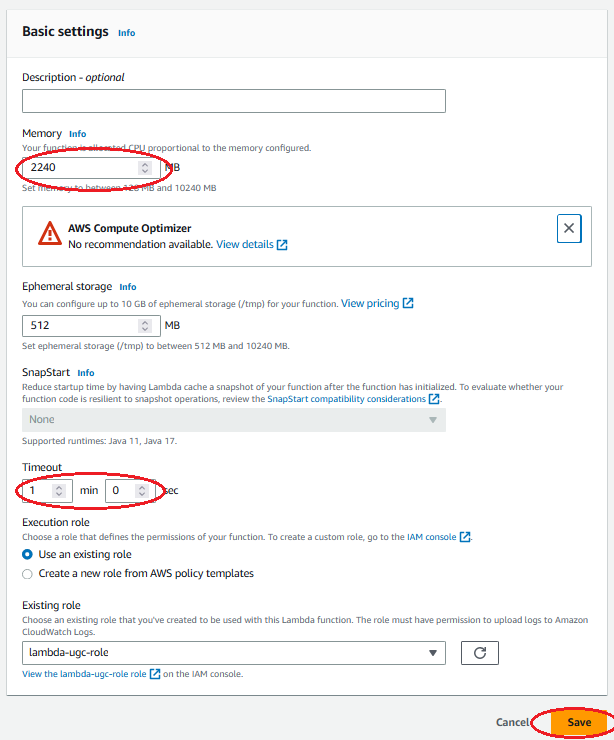
Edite los ajustes básicos de la función Lambda para aumentar los valores de memoria y tiempo de espera: establecer el tamaño de la memoria en 2240 MB e introduzca “1 minuto y 0 segundos” para indicar el tiempo de espera y, a continuación, seleccione “Guardar”. NOTA: Puede dejar el tamaño de almacenamiento Ephemeral por defecto para esta demostración, en otros casos puede elegir hasta 10GB de storage o bien, elegir otro tipo de almacenamiento permanente, por ejemplo EFS o S3.
Por último, copie el siguiente script de Python al código de la función, asegúrese de actualizar el nombre de su bucket de destino
# Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
# SPDX-License-Identifier: MIT-0 (https://spdx.org/licenses/MIT-0.html)
import json
import os
import subprocess
import shlex
import boto3
S3_DESTINATION_BUCKET = "ugc-destination-bucket"
SIGNED_URL_TIMEOUT = 60
def lambda_handler(event, context):
s3_source_bucket = event['Records'][0]['s3']['bucket']['name']
s3_source_key = event['Records'][0]['s3']['object']['key']
s3_source_basename = os.path.splitext(os.path.basename(s3_source_key))[0]
s3_destination_filename = s3_source_basename + "_cfr.ts"
s3_client = boto3.client('s3')
s3_source_signed_url = s3_client.generate_presigned_url('get_object',
Params={'Bucket': s3_source_bucket, 'Key': s3_source_key},
ExpiresIn=SIGNED_URL_TIMEOUT)
ffmpeg_cmd = "/opt/bin/ffmpeg -i \"" + s3_source_signed_url + "\" -f mpegts -c:v copy -af aresample=async=1:first_pts=0 -"
command1 = shlex.split(ffmpeg_cmd)
p1 = subprocess.run(command1, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
resp = s3_client.put_object(Body=p1.stdout, Bucket=S3_DESTINATION_BUCKET, Key=s3_destination_filename)
return {
'statusCode': 200,
'body': json.dumps('Processing complete successfully')
}Pruebas y resultados
El flujo de trabajo ya está listo para su procesamiento. Puede probarlo cargando un archivo fuente mp4 en Amazon S3 'ugc-source-bucket'. La salida de FFmpeg se almacena entonces en 'ugc-destination-bucket'. Los registros de invocación de Lambda se encuentran en la consola de servicio Amazon CloudWatch; seleccione Grupos de registros en el panel de la izquierda y, a continuación, elija el grupo de registros de la función, que tiene el siguiente patrón de nombres: “/aws/lambda/<function-name>”.

Identifique el grupo de registro de la función Lambda en la consola de CloudWatch mediante el patrón “/aws/lambda/”
Cada invocación de la función Lambda agrega registros a un flujo de registro dentro del grupo Log de la función. Puede revisar los registros de invocación y las estadísticas de la invocación en el flujo de registros para solucionar cualquier error o si ha añadido mensajes de depuración adicionales al código. Por ejemplo:

Ejemplo de registros de invocación de funciones Lambda en la consola de CloudWatch: puede encontrar en el registro los errores de código y los mensajes de depuración. Para cada invocación, puede leer los valores de duración facturada y memoria máxima utilizada.
Probamos tres archivos fuente de diferentes tamaños mediante el flujo de trabajo y obtuvimos los siguientes resultados
| Tamaño de archivo fuente (MB) | Memoria Max Utilizada (MB) | Duración facturada (ms) |
| 33.8 | 187 | 2600 |
| 194.1 | 521 | 6200 |
| 529.6 | 1180 | 13200 |
Como era de esperar, la memoria máxima utilizada por Lambda aumenta linealmente con el tamaño del archivo fuente. La relación entre ambos puede aproximarse al doble del tamaño del archivo fuente, además de una sobrecarga de procesamiento de 120 a 140 MB. Esto se debe a que tanto los archivos de origen como los de salida tienen aproximadamente el mismo tamaño, ya que solo hemos procesado el audio en esta demostración.
Estimamos que la configuración de memoria actual es de 2240 MB para funcionar con fuentes de un tamaño igual o ligeramente superior a 1 GB. Se espera que el tamaño máximo de asignación de memoria de Lambda, de 10240 MB, permita procesar archivos fuente de hasta 4 GB de tamaño, considerablemente más que los 512 MB disponibles por defecto en el directorio /tmp de Lambda. Tenga en cuenta que estas observaciones solo son relevantes para procesar audio en archivos mp4. Para otros tipos de contenido o procesamiento, asegúrese de realizar las pruebas suficientes para estimar sus propios requisitos de memoria Lambda.
Limpieza
Para evitar incurrir en cargos futuros, elimine los recursos y, más específicamente, los objetos de Amazon S3 y el grupo de registro de invocación de CloudWatch utilizados para estas pruebas.
Conclusión
En esta publicación, presentamos un flujo de trabajo para procesar UGC en AWS Lambda mediante FFmpeg. Presentamos una demostración para procesar audio VFR y convertirlo en audio CFR. También analizamos los requisitos de memoria Lambda para el flujo de trabajo.
Para obtener más información sobre la gestión y el procesamiento de UGC, además de habilitar los flujos de trabajo de vídeo bajo demanda (VOD) en AWS, recomendamos los siguientes recursos:
- Resolución de 2020: añada contenido generado por los usuarios a sus aplicaciones (https://thinkwithwp.com/blogs/media/2020-resolution-add-user-generated-content-to-your-applications/)
- Uso de Amazon EFS para AWS Lambda en sus aplicaciones sin servidor (https://thinkwithwp.com/blogs/compute/using-amazon-efs-for-aws-lambda-in-your-serverless-applications/)
- Vídeo bajo demanda en AWS (https://thinkwithwp.com/solutions/implementations/video-on-demand-on-aws/?did=sl_card&trk=sl_card)
- Cuotas de AWS Lambda (https://docs.thinkwithwp.com/lambda/latest/dg/gettingstarted-limits.html)
- Cree un archivo mp4 a partir de h264 sin procesar utilizando una canalización en lugar de archivos (https://stackoverflow.com/questions/55698581/create-mp4-file-from-raw-h264-using-a-pipe-instead-of-files)
- https://stackoverflow.com/questions/55698581/create-mp4-file-from-raw-h264-using-a-pipe-instead-of-files)
Este artículo fue traducido del Blog de AWS en Inglés.