Möchten Sie über neue Inhalte informiert werden?
Von Becky Weiss und Mike Furr
Bei Amazon müssen die von uns entwickelten Services extrem hohe Verfügbarkeitsziele erfüllen. Das bedeutet, dass wir sorgfältig über die Abhängigkeiten nachdenken müssen, die unsere Systeme aufweisen. Wir gestalten unsere Systeme so, dass sie auch bei Beeinträchtigung dieser Abhängigkeiten widerstandsfähig bleiben. In diesem Artikel werden wir ein Muster definieren, das wir als statische Stabilität bezeichnen, um dieses Niveau der Belastbarkeit zu erreichen. Wir zeigen Ihnen, wie wir dieses Konzept auf Availability Zones anwenden, einen wichtigen Infrastrukturbaustein in AWS und damit eine Grundvoraussetzung, auf der alle unsere Services aufbauen.
In einem statisch stabilen Design funktioniert das Gesamtsystem auch dann noch, wenn eine Abhängigkeit beeinträchtigt wird. Möglicherweise sieht das System keine aktualisierten Informationen (z. B. neue Dinge, gelöschte Dinge oder geänderte Dinge), die seine Abhängigkeit geliefert haben sollte. Doch alles, was es tat, bevor die Abhängigkeit beeinträchtigt wurde, funktioniert trotz der beeinträchtigten Abhängigkeit weiter. Wir beschreiben, wie wir die Amazon Elastic Compute Cloud (EC2) statisch stabil aufgebaut haben. Dann stellen wir zwei statisch stabile Beispielarchitekturen vor, die wir für den Aufbau hochverfügbarer regionaler Systeme auf Basis von Availability Zones für nützlich befunden haben.
Abschließend werden wir einige der Designphilosophie von Amazon EC2 näher erläutern, einschließlich der Frage, wie es entwickelt wurde, um die Unabhängigkeit der Availability Zone auf Softwareebene zu gewährleisten. Darüber hinaus werden wir einige der Kompromisse besprechen, die mit dem Aufbau eines Services mit dieser Wahl der Architektur verbunden sind.
Statische Stabilität
• Sie weist eine Netzwerkschnittstelle aus dem VPC-Subnetz zu.
• Sie bereitet ein Amazon Elastic Block Store (EBS)-Volume vor.
• Sie generiert AWS Identity and Access Management (IAM)-Rollenanmeldeinformationen.
• Sie installiert Sicherheitsgruppenregeln.
• Sie speichert die Ergebnisse in den Datenspeichern der verschiedenen nachgelagerten Services.
• Sie leitet die erforderlichen Konfigurationen an den Server im VPC und an die Netzwerkgrenze weiter.
• Sie liest und schreibt von/auf Amazon EBS-Volumes.
• Und so weiter.
• Es ist typisch für die Datenebene, mit einem höheren Volumen (oft um Größenordnungen) zu laufen als ihre Steuerungsebene. Daher ist es besser, sie getrennt zu halten, damit sie jeweils nach ihren eigenen relevanten Skalierungsdimensionen skaliert werden können.
• Wir haben im Laufe der Jahre festgestellt, dass die Steuerungsebene eines Systems tendenziell mehr bewegliche Teile aufweist als die Datenebene, so dass die statistische Wahrscheinlichkeit einer Beeinträchtigung allein aus diesem Grund höher ist.
Muster statischer Stabilität
In diesem Abschnitt stellen wir zwei High-Level-Muster vor, die wir in AWS verwenden, um Systeme für Hochverfügbarkeit durch Nutzung statischer Stabilität zu entwerfen. Jedes ist auf seine eigenen Situationen anwendbar, aber beide nutzen die Vorteile der Abstraktion der Availability Zone.

Im Falle einer Beeinträchtigung der Availability Zone erfordert die im vorherigen Diagramm dargestellte Architektur keine Maßnahmen. Die EC2-Instances in der beeinträchtigten Availability Zone beginnen mit fehlgeschlagenen Health Checks, und der Application Load Balancer verlagert den Traffic von ihnen weg. Tatsächlich ist Elastic Load Balancing nach diesem Prinzip konzipiert. Der Service hat genügend Lastenausgleichskapazität bereitgestellt, um einer Beeinträchtigung der Availability Zone standzuhalten, ohne dass eine Skalierung erforderlich ist.
Wir verwenden dieses Muster auch dann, wenn es keinen Load Balancer oder HTTPS-Service gibt. So kann beispielsweise auch eine Reihe von EC2-Instances, die Nachrichten aus einer Amazon Simple Queue Service (SQS)-Warteschlange verarbeitet, diesem Muster folgen. Die Instanzen werden in einer Auto Scaling-Gruppe über mehrere Availability Zones verteilt und entsprechend mit Überkapazität bereitgestellt. Im Falle einer beeinträchtigten Availability Zone tut der Service nichts. Die beeinträchtigten Instanzen funktionieren nicht mehr, ihre Arbeit wird von anderen übernommen.

Wie beim zustandslosen, aktiv-aktiven Beispiel, wenn die Availability Zone mit dem primären Knoten beeinträchtigt wird, tut der zustandsbehaftete Service nichts mit der Infrastruktur. Für Services, die Amazon RDS verwenden, verwaltet RDS das Failover und weist den DNS-Namen auf den neuen Primärserver in der funktionierenden Availability Zone zurück. Dieses Muster gilt auch für andere Aktiv-Standby-Setups, auch wenn sie keine relationale Datenbank verwenden. Insbesondere wenden wir dies auf Systeme mit einer Clusterarchitektur an, die einen Leader-Knoten hat. Wir setzen diese Cluster in allen Availability Zones ein und wählen den neuen Leader-Knoten aus einem Standby-Kandidaten, anstatt einen Ersatz „just in time“ zu starten.
Was diese beiden Muster gemeinsam haben, ist, dass beide bereits die Kapazität weit vor jeder tatsächlichen Beeinträchtigung bereitgestellt hatten, die sie im Falle einer Beeinträchtigung der Availability Zone benötigen würden. In keinem dieser beiden Fälle nimmt der Service absichtliche Abhängigkeiten der Kontrollebene an, wie z. B. die Bereitstellung neuer Infrastruktur oder Änderungen als Reaktion auf eine Beeinträchtigung der Availability Zone.
Unter der Haube: Statische Stabilität in Amazon EC2
Dieser letzte Abschnitt des Artikels wird eine Ebene tiefer in die robusten Architekturen von Availability Zones eintauchen und einige der Wege aufzeigen, auf denen wir dem Prinzip der Unabhängigkeit der Availability Zone in Amazon EC2 folgen. Das Verständnis einiger dieser Konzepte ist hilfreich, wenn wir einen Service aufbauen, der nicht nur selbst hochverfügbar sein muss, sondern auch eine Infrastruktur bereitstellen muss, auf der andere hochverfügbar sein können. Amazon EC2, als Anbieter einer Low-Level-AWS-Infrastruktur, ist die Infrastruktur, die Anwendungen nutzen können, um hochverfügbar zu sein. Es gibt Umstände, in denen auch andere Systeme diese Strategie übernehmen möchten.
Wir befolgen bei unseren Bereitstellungspraktiken das Prinzip der Unabhängigkeit der Availability Zone in Amazon EC2. In Amazon EC2 wird Software auf den physischen Servern bereitgestellt, auf denen EC2-Instances, Edge-Geräte, DNS-Resolver, Steuerungsebenenkomponenten im EC2-Instance-Startpfad und viele andere Komponenten gehostet werden, von denen EC2-Instances abhängen. Diese Implementierungen folgen einem zonalen Bereitstellungskalender. Dies bedeutet, dass zwei Availability Zones in derselben Region an verschiedenen Tagen eine bestimmte Bereitstellung erhalten. In AWS verwenden wir einen schrittweisen Rollout von Implementierungen. Beispielsweise folgen wir der bewährten Praxis (unabhängig von der Art des Services, den wir bereitstellen), zuerst eine One-Box und dann 1/N Server usw. bereitzustellen. Im konkreten Fall von Services wie denen in Amazon EC2 gehen unsere Implementierungen jedoch einen Schritt weiter und sind bewusst an der Grenze der Availability Zone ausgerichtet. Auf diese Weise betrifft ein Problem mit einer Bereitstellung eine Availability Zone, wird zurückgesetzt und behoben. Es hat keinen Einfluss auf andere Availability Zones, die weiterhin wie gewohnt funktionieren.
Eine weitere Möglichkeit, wie wir beim Aufbau von Amazon EC2 das Prinzip der unabhängigen Availability Zones anwenden, besteht darin, alle Paketströme so zu gestalten, dass sie innerhalb der Availability Zone bleiben und keine Grenzen überschreiten. Dieser zweite Punkt – der Netzwerkverkehr wird lokal in der Availability Zone gehalten – ist es wert, genauer untersucht zu werden. Es ist ein interessantes Beispiel dafür, wie wir anders denken, wenn wir ein regionales, hochverfügbares System aufbauen, das ein Konsument von unabhängigen Availability Zones ist (d. h. es verwendet Garantien der Unabhängigkeit der Verfügbarkeitszone als Grundlage für den Aufbau eines Hochverfügbarkeitsservices), als wenn wir anderen eine unabhängige Infrastruktur zur Verfügung stellen, die es ihnen ermöglicht, für eine hohe Verfügbarkeit zu sorgen.
Das folgende Diagramm veranschaulicht einen hochverfügbaren externen Service, orange dargestellt, der von einem anderen, internen Service abhängt, grün dargestellt. Ein einfaches Design behandelt beide Services als Konsumenten unabhängiger EC2 Availability Zones. Jeder der orangefarbenen und grünen Services wird von einem Application Load Balancer unterstützt, und jeder Service verfügt über eine gut ausgestattete Reihe von Backend-Hosts, die über drei Availability Zones verteilt sind. Ein hochverfügbarer regionaler Service ruft einen anderen hochverfügbaren regionalen Service auf. Dies ist ein einfaches Design, und für viele der Services, die wir aufgebaut haben, ist es ein gutes Design.

Nehmen wir jedoch an, dass der grüne Service ein grundlegender Service ist. Das heißt, angenommen, er soll nicht nur hochverfügbar sein, sondern auch selbst als Baustein für die Unabhängigkeit der Availability Zone dienen. In diesem Fall könnten wir es stattdessen als drei Instanzen eines zonenlokalen Services gestalten, wobei wir uns an Availability Zone-bewusste Bereitstellungspraktiken halten. Das folgende Diagramm veranschaulicht das Design, bei dem ein hochverfügbarer regionaler Service einen hochverfügbaren zonalen Service aufruft.

Die Gründe, warum wir unsere Bausteinservices so gestalten, dass sie unabhängig von der Availability Zone sind, liegen in der einfachen Arithmetik. Angenommen, eine Availability Zone wird beeinträchtigt. Bei Schwarz-Weiß-Ausfällen fällt der Application Load Balancer automatisch von den betroffenen Knoten weg aus. Doch nicht alle Ausfälle sind so offensichtlich. Es kann graue Fehler geben, wie z. B. Fehler in der Software, die der Load Balancer in seinem Health Check nicht sehen und sauber behandeln kann.
In dem früheren Beispiel, in dem ein hochverfügbarer regionaler Service einen anderen hochverfügbaren regionalen Service aufruft, wenn eine Anfrage über das System gesendet wird, dann ist die Wahrscheinlichkeit, dass die Anfrage die beeinträchtigte Availability Zone vermeidet, 2/3 * 2/3 = 4/9. Das heißt, die Wahrscheinlichkeit, dass die Anforderung das Ereignis vermeidet, ist geringer als 50 %. Im Gegensatz dazu: Wenn wir den grünen Service als zonalen Service wie im aktuellen Beispiel aufgebaut haben, dann können die Hosts im orangefarbenen Service den grünen Endpunkt in der gleichen Availability Zone aufrufen. Bei dieser Architektur liegen die Chancen, die beeinträchtigte Availability Zone zu vermeiden, bei 2/3. Wenn N Services Teil dieses Aufrufpfades sind, dann verallgemeinern sich diese Zahlen auf (2/3)^N für N regionale Services gegenüber einer Konstante von 2/3 für N zonale Services.
Aus diesem Grund haben wir den Amazon EC2 NAT Gateway als zonalen Service aufgebaut. NAT Gateway ist eine Amazon EC2-Funktion, die ausgehenden Internetverkehr aus einem privaten Subnetz ermöglicht und nicht als regionaler, VPC-weiter Gateway, sondern als zonale Ressource erscheint, die Kunden separat pro Availability Zone instanziieren, wie in der folgenden Abbildung dargestellt. Der NAT Gateway befindet sich im Pfad der Internetverbindung für den VPC und ist somit Teil der Datenebene jeder EC2-Instance innerhalb dieses VPCs. Wenn es in einer Availability Zone zu einer Beeinträchtigung der Konnektivität kommt, wollen wir diese Beeinträchtigung innerhalb dieser Availability Zone halten, anstatt sie auf andere Zonen zu übertragen. Am Ende wollen wir, dass ein Kunde, der eine ähnliche Architektur wie die zuvor in diesem Artikel erwähnte aufgebaut hat (d. h. eine Reihe über drei Availability Zones mit genügend Kapazität in zwei Zonen bereitstellt, um die volle Last zu tragen), weiß, dass die anderen Availability Zones von allem, was in der beeinträchtigten Availability Zone vor sich geht, völlig unbeeinflusst bleiben. Die einzige Möglichkeit für uns, dies zu tun, ist sicherzustellen, dass alle grundlegenden Komponenten wie der NAT Gateway wirklich innerhalb der Availability Zone bleiben.
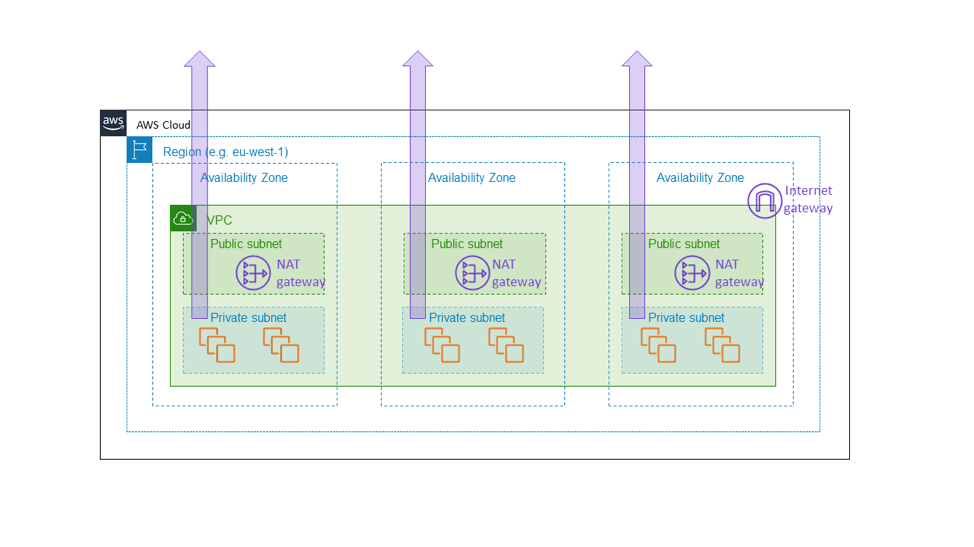
Diese Wahl ist mit den Kosten für zusätzliche Komplexität verbunden. Für uns bei Amazon EC2 liegt die zusätzliche Komplexität in der Verwaltung zonaler und nicht regionaler Serviceumgebungen. Für Kunden von NAT Gateways ergibt sich die zusätzliche Komplexität in Form von mehreren NAT Gateways und Routing-Tabellen für den Einsatz in den verschiedenen Availability Zones des VPC. Die zusätzliche Komplexität ist angemessen, da NAT Gateway selbst ein grundlegender Service ist, Teil der Amazon EC2-Datenebene, die zonale Verfügbarkeitsgarantien bieten soll.
Es gibt noch eine weitere Überlegung, die wir anstellen, wenn wir Services aufbauen, die unabhängig von der Availability Zone sind, und zwar die Datensicherheit. Obwohl jede der zuvor beschriebenen zonalen Architekturen den gesamten Stapel innerhalb einer einzigen Availability Zone zeigt, replizieren wir jeden Hard State über mehrere Availability Zones für Disaster Recovery-Zwecke. Beispielsweise speichern wir typischerweise regelmäßige Datenbank-Backups in Amazon S3 und pflegen Lese-Replikate unserer Datenspeicher über die Grenzen der Availability Zone hinweg. Diese Replikate sind nicht erforderlich, damit die primäre Availability Zone funktioniert. Stattdessen stellen sie sicher, dass wir kunden- oder geschäftskritische Daten an mehreren Standorten speichern.
Beim Design einer serviceorientierten Architektur, die in AWS ausgeführt wird, haben wir gelernt, eines dieser beiden Muster oder eine Kombination aus beiden zu verwenden:
• Das einfachere Muster: Regional ruft regional auf. Dies ist oft die beste Wahl für externe Services und auch für die meisten internen Services geeignet. Wenn wir beispielsweise in AWS übergeordnete Anwendungsservices wie Amazon API Gateway und AWS serverlose Technologien aufbauen, verwenden wir dieses Muster, um eine hohe Verfügbarkeit auch bei Beeinträchtigungen der Availability Zone zu gewährleisten.
• Das komplexere Muster: Regional ruft zonal auf oder zonal ruft zonal auf. Bei der Entwicklung interner und in einigen Fällen externer Datenebenenkomponenten innerhalb von Amazon EC2 (z. B. Netzwerkgeräte oder andere Infrastrukturen, die direkt im kritischen Datenpfad liegen) folgen wir dem Muster der Unabhängigkeit der Availability Zone und verwenden Instanzen, die in Availability Zones isoliert sind, so dass der Netzwerkverkehr in der gleichen Availability Zone bleibt. Dieses Muster trägt nicht nur dazu bei, Beeinträchtigungen gegenüber einer Availability Zone zu isolieren, sondern hat auch günstige Netzwerkverkehrskosten in AWS.
Fazit
In diesem Artikel haben wir einige einfache Strategien besprochen, die wir bei AWS verwendet haben, um erfolgreich Abhängigkeiten von Availability Zones herzustellen. Wir haben gelernt, dass der Schlüssel zur statischen Stabilität darin besteht, Beeinträchtigungen vorwegzunehmen, bevor sie auftreten. Unabhängig davon, ob ein System auf einer aktiv-aktiven, horizontal skalierbaren Reihe läuft oder ob es sich um ein zustandsabhängiges, Aktiv-Standby-Muster handelt, können wir mit Availability Zones eine hohe Verfügbarkeit anstreben. Wir stellen unsere Systeme so bereit, dass alle Kapazitäten, die im Falle einer Beeinträchtigung benötigt werden, bereits vollständig und betriebsbereit bereitgestellt sind. Schließlich haben wir uns genauer angesehen, wie Amazon EC2 selbst statische Stabilitätskonzepte einsetzt, um die Availability Zones unabhängig voneinander zu halten.
Über die Autoren

Becky Weiss ist Senior Principal Engineer bei Amazon Web Services. Sie arbeitet im Moment schwerpunktmäßig am Identity and Access Management in AWS sowie allgemein an flexiblen, umfassenden und verlässlichen Sicherheitskontrollen für Kunden in der Cloud. In der Vergangenheit hat sie an Amazon Virtual Private Cloud (d. h. Networking) und AWS Lambda gearbeitet, und sie hat auch mit AWS Professional Services zusammengearbeitet, um Unternehmenskunden zu helfen, ihre Umgebungen in AWS erfolgreich zu sichern. Sie ist auch zufällig der größte Fan von AWS, und in ihrer Freizeit baut sie alle möglichen nützlichen und nutzlosen Dinge auf AWS. Vor ihrer Tätigkeit bei AWS arbeitete Becky für Microsoft an Windows und dem Windows Phone.

Mike Furr ist Principal Engineer bei Amazon Web Services. Er kam 2009 zu Amazon, nachdem er an der University of Maryland, College Park, in Informatik promoviert hatte. Während seiner Zeit bei Amazon arbeitete er an Virtual Private Cloud, Direct Connect sowie am AWS Metering- und Billing-Stack. Nun konzentriert er sich schwerpunktmäßig auf EC2, wo er Teams bei der Skalierung der Cloud unterstützt.