- AWS Solutions Library›
- Guidance for Optimizing Deep Learning Workloads for Sustainability on AWS
Guidance for Optimizing Deep Learning Workloads for Sustainability on AWS
Overview
How it works
Data processing
These technical details feature an architecture diagram to illustrate how to effectively use this solution. The architecture diagram shows the key components and their interactions, providing an overview of the architecture's structure and functionality step-by-step.
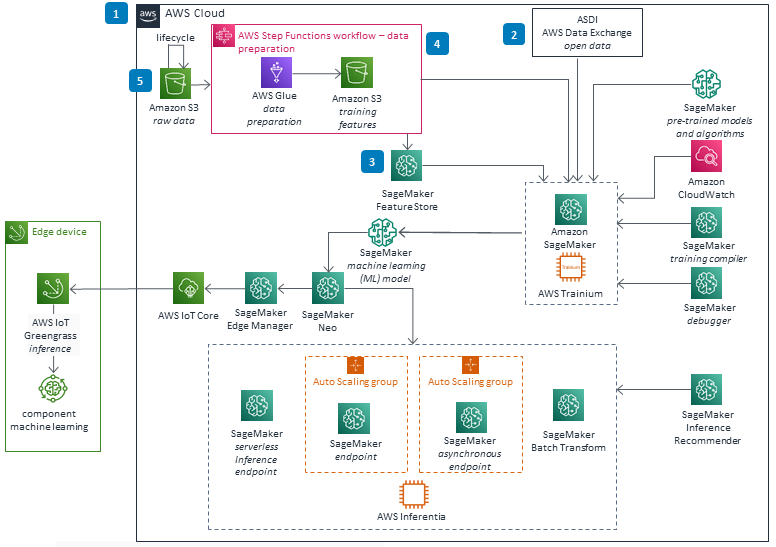
Model building
These technical details feature an architecture diagram to illustrate how to effectively use this solution. The architecture diagram shows the key components and their interactions, providing an overview of the architecture's structure and functionality step-by-step.
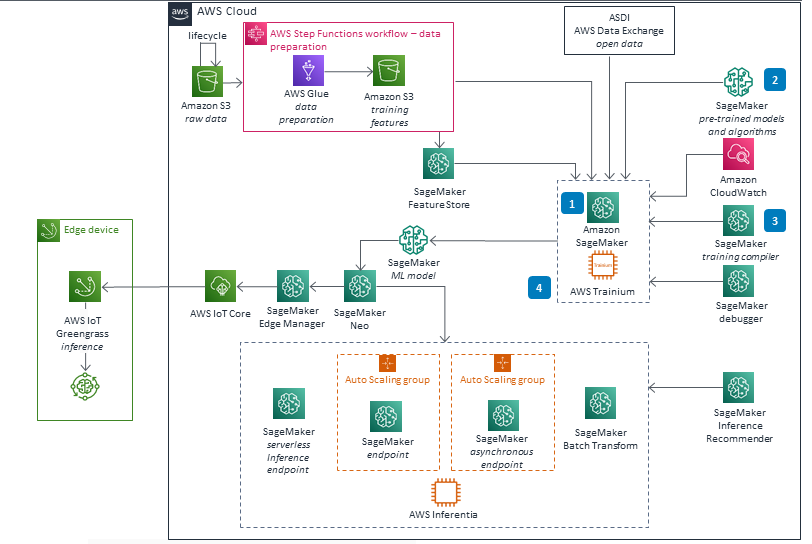
Model training
These technical details feature an architecture diagram to illustrate how to effectively use this solution. The architecture diagram shows the key components and their interactions, providing an overview of the architecture's structure and functionality step-by-step.
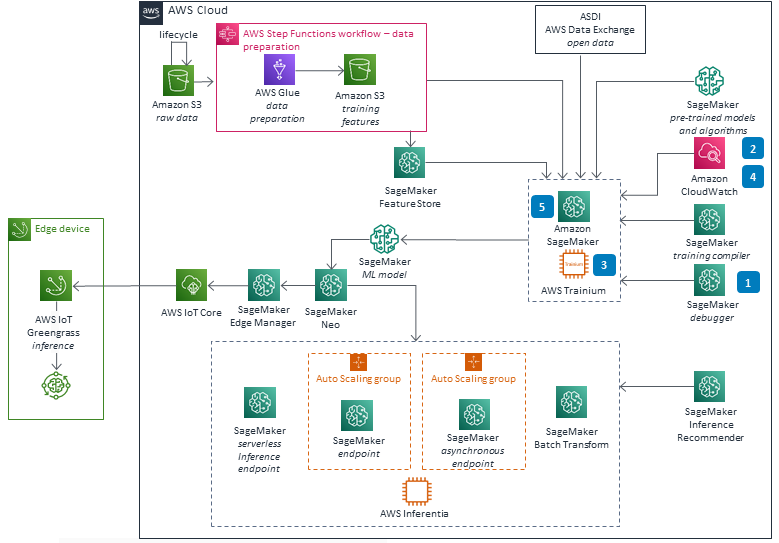
Inference
These technical details feature an architecture diagram to illustrate how to effectively use this solution. The architecture diagram shows the key components and their interactions, providing an overview of the architecture's structure and functionality step-by-step.
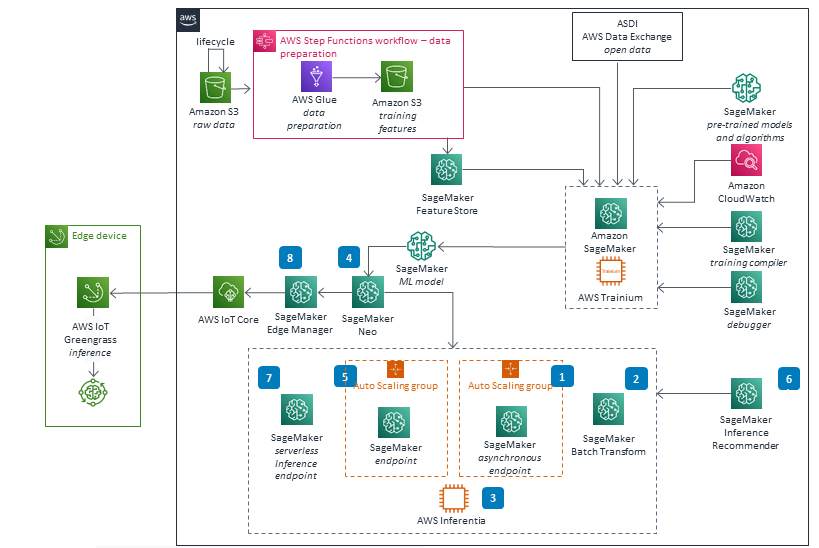
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as amany Well-Architected best practices as possible.
CloudWatch is used to measure machine learning (ML) operations metrics to monitor the performance of the deployed environment. In the data processing phase, AWS Glue and Step Functions workflows are used to track the history of the data within the pipeline execution. In the model development phase, SageMaker Debugger provides near real-time monitoring of training jobs to detect issues and performance bottlenecks. In the deployment phase, the health of model endpoints deployed on SageMaker hosting options is monitored using CloudWatch metrics and alarms.
All the proposed services support integration with AWS Identity and Access Management (IAM) that can be used to control access to resources and data. Data is stored in Amazon S3 and SageMaker Feature Store that support encryption at rest using AWS Key Management Service (AWS KMS). To reduce data exposure risks, data lifecycle plans are established to remove data automatically based on age, and store only the data that has business need.
The customer has the option to deploy SageMaker services in a highly available manner. AWS Glue Data Catalog is used to track the data assets that have been loaded into the ML workloads. Fault tolerant, repeatable, and highly available data processing is ensured thanks to data pipelines.
Training and inference instance types are optimized using CloudWatch metrics and SageMaker Inference Recommender. The use of simplified versions of algorithms, pruning, and quantization is recommended to achieve better performance. SageMaker Training Compiler can speed up training of deep learning models by up to 50%, and SageMaker Neo optimizes ML models to perform up to 25x faster. Instances based on Trainium and Inferentia offer higher performance compared to other Amazon EC2 instances.
We encourage the use of existing publicly available datasets to avoid the cost of storing and processing data. Using the appropriate Amazon S3 storage tier, S3 Lifecycle policies, and S3 Intelligent-Tiering storage class help reduce storage cost.
SageMaker Feature Store helps reduce the cost of storing and processing duplicated datasets. We recommend data and compute proximity to reduce transfer costs. Serverless data pipelines, asynchronous SageMaker endpoints, and SageMaker batch transform help avoid the cost of maintaining compute infrastructure 24/7. We encourage optimization techniques (compilation, pruning, quantization, use of simplified version of algorithms) as well as transfer learning and incremental training to reduce training and inference costs. Scripts are provided to automatically shutdown unused resources.
This reference architecture aligns with the goals of optimization for sustainability:
-
Ensure elimination of idle resources by the use of serverless technologies (AWS Glue, Step Functions, SageMaker Serverless Inference Endpoint) and environment automation
-
Achieve reduction of unnecessary data processing and data storage using Amazon S3 lifecycle policies, SageMaker Feature Store, and the use of existing, publicly available datasets and models
-
Achieve maximization of the utilisation of provisioned resources by right-sizing the environments (using CloudWatch and SageMaker Inference Recommender) and asynchronous processing (SageMaker Asynchronous Endpoints)
-
Achieve maximization of CPU efficiency using simplified versions of algorithms, models compilation (SageMaker Training compiler and SageMaker Neo), and compression techniques (pruning and quantization)
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages