- AWS Solutions Library›
- Guidance for Audience Segments Uploader to Advertising & Marketing Platforms on AWS
Guidance for Audience Segments Uploader to Advertising & Marketing Platforms on AWS
Overview
This Guidance demonstrates various ways to upload audience and segments data to external platforms using AWS services. One way you can deploy this Guidance is through AWS managed services that use existing, pre-built integrations in AWS services to activate the audience and segments data. A second way is through a multi-step API workflow that uses a set of rules, provided by the external platform, to activate the audience and segments data. A third way to deploy this Guidance is through a simple rest API-based integration to activate the audience and segments data. This allows you to maximize the value of the data available in AWS, and helps you tailor your customer's experience to the specific needs of each segment.
How it works
Overview
This architecture diagram shows integration patterns for uploading audience segments built or stored in AWS services to advertising and marketing platforms.
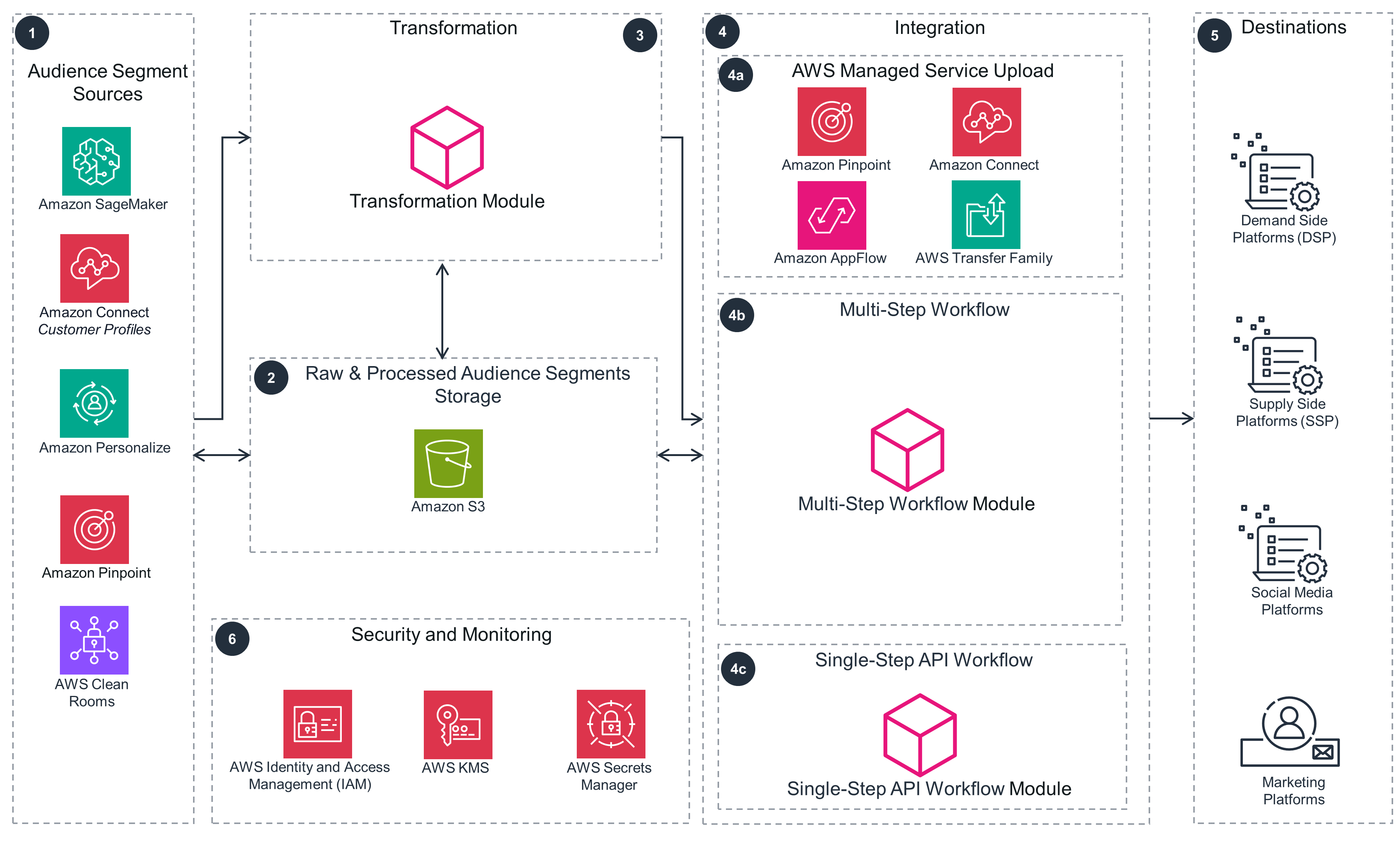
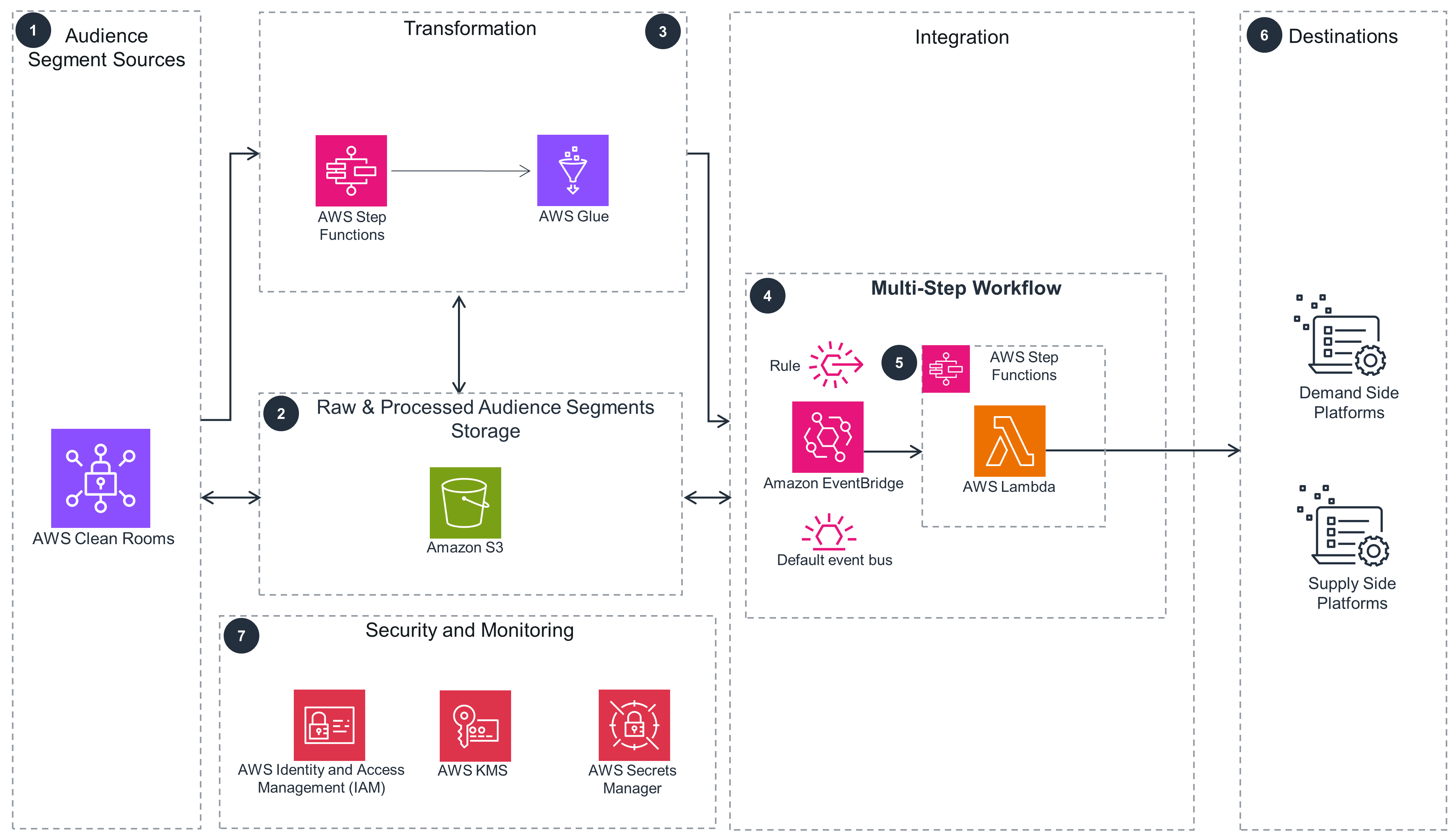
Multi-Step Workflow
The Multi-Step Workflow pattern is shown here in more detail.
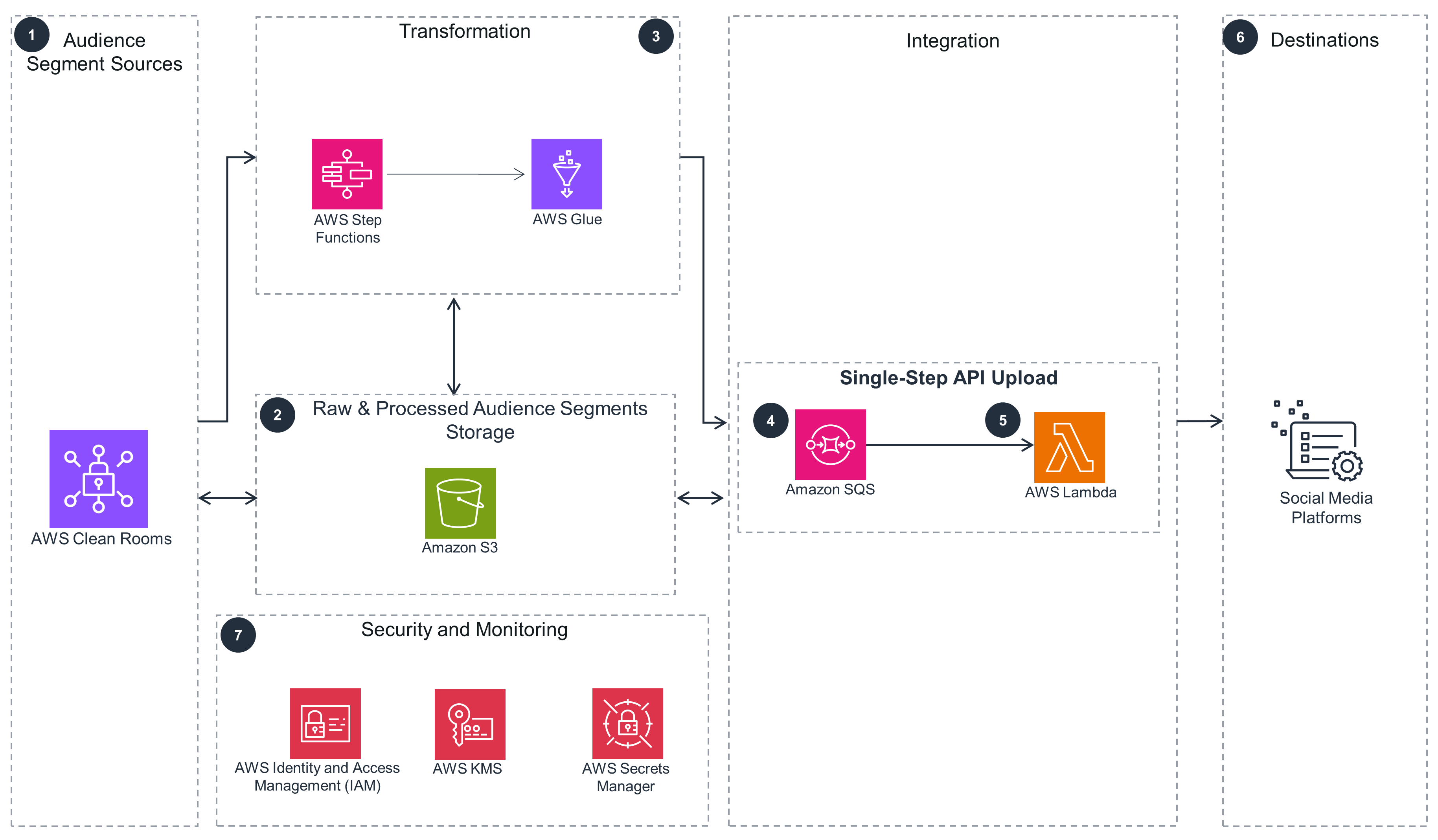
Single-Step API Upload
The Single-Step API Upload pattern is shown here in more detail.
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
This Guidance is designed to provide you with the information you need to understand the internal state of your workloads. Specifically, observability is built into the architecture, with every service publishing metrics to Amazon CloudWatch where dashboards and alarms can be configured. You can then iterate to develop the telemetry necessary for your workloads.
A number of decisions were factored into the design of this Guidance to help you secure your workloads. One, IAM policies are created using the least-privilege access, such that every policy is restricted to the specific resource and operation. Two, secrets and configuration items are centrally managed in Secrets Manager and secured using IAM. Three, the data at rest in the Amazon S3 bucket is encrypted using AWS KMS. And four, the data in transit into the external API is encrypted and transferred over HTTPS, and the sensitive data in the payload is SHA-256 encrypted at the attribution level.
To help you implement a highly available network topology, every service and technology within each architecture layer was used because they are serverless and fully managed by AWS, making the overall architecture elastic, highly available, and fault-tolerant. Also, this Guidance is designed using a multi-tier architecture, where every tier is independently scalable, deployable, and testable.
To further support the reliability of your workloads, implementing a data backup and recovery plan is simple, thanks to the Amazon S3 bucket that is used as persistent storage. Consider using the Amazon S3 Intelligent-Tiering storage class to back up your data and meet your requirements for recovery time objectives (RTO) and recovery point objectives (RPO). Amazon S3 offers industry-leading durability, availability, performance, security, and virtually unlimited scalability at very low costs.
Using serverless technologies, you only provision the exact resources you use. Serverless technology reduces the amount of underlying infrastructure you need to manage, allowing you to focus on solving your business needs. You can use automated deployments to deploy the components of this Guidance into any Region quickly - providing data residence and reduced latency. In addition, all components are colocated in a single Region and use a serverless stack, which avoids the need for you to make infrastructure location decisions apart from the Region choice.
This Guidance helps you use the appropriate services, resources, and configurations, all key to cost savings. For one, by using serverless technologies, you only pay for the resources you consume. Second, as the data ingestion velocity increases and decreases, the costs will align with usage, so you can plan for data transfer charges. Third, when AWS Glue is performing data transformations, you only pay for the infrastructure while the processing is occurring. Fourth, through a tenant isolation model and resource tagging, you can automate cost usage alerts and measure costs specific to each tenant, application module, and service.
This Guidance scales to continually match the load while ensuring that only the minimum resources are required through the extensive use of serverless services, where compute is only used as needed. The efficient use of serverless resources reduces the overall energy required to operate the workload. For example, AWS Glue, Lambda, and Amazon S3 automatically optimize resource utilization in response to demand.
You can extend this Guidance by using Amazon S3 Lifecycle configuration to define policies and move objects to different storage classes based on access patterns.
Finally, all of the services used in this Guidance are managed services that allocate hardware according to workload demand. Using the provisioned capacity option in the service configurations, where it is available and when the workload is predictable, is recommended.
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages