开始使用 Amazon SageMaker Data Wrangler 图像数据准备




亚马逊云科技免费套餐配额或 1.84 美元



想象一下,您正在与地方政府合作,以尽可能快的速度响应交通事故。您正在尝试构建一个机器学习 (ML) 模型,能够从交通监控画面中识别事故,以便调度急救人员及时赶到现场。您的成果非常重要,因为它们将挽救生命!
为此,您需要准备大量图像来训练和构建 ML 模型。但是,构建模型需要编写数百行代码,您可能心有余而力不足。也许您更熟悉使用表格数据,或者不习惯使用处理图像的库。幸运的是,Amazon SageMaker Data Wrangler 可以为您提供帮助。Data Wrangler 将聚合和准备用于 ML 的图像数据所需的时间从数周缩短到几分钟。您可以使用其单一的可视化界面来准备这些图像,无需编写任何代码。而如果您内心的数据科学家人格仍然想写一些代码,Data Wrangler 也能为您提供帮助。
在本教程中,我们将使用 Amazon SageMaker Data Wrangler 来准备图像数据以用于图像分类模型。数据准备任务对于构建能够识别并响应道路交通事故的模型而言至关重要。
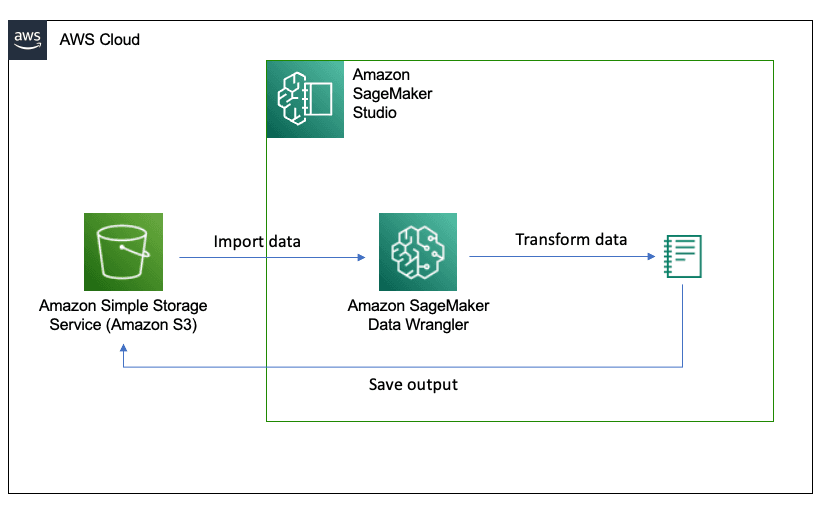
上图展示了本教程的工作流。设置 Amazon SageMaker Studio 域后,您将下载监控探头捕获的车祸图像,并将其上传至 Amazon S3 存储桶中。然后,您将这些图像导入 Amazon SageMaker Studio 进行处理。
为什么我们需要对图像进行预处理?为构建准确的机器学习模型,我们希望提高图像质量,提取相关特征(如汽车轮廓)并标准化数据。这些都是准备图像数据、将它们转换为合适的格式以及使机器学习模型能够从数据中学习的基本步骤。
对于 Data Wrangler 中的图像准备步骤,我们将首先处理数据集中损坏或有缺陷的图像。这会删除不适于训练机器学习模型的图像。然后,我们将增强对比度以提取相关特征,再调整图像大小以使之标准化。最后,我们将应用自定义转换来提高模型检测图像中边缘的能力。
转换步骤完成后,我们会将准备好的图像导出到另一个 Amazon S3 存储桶。我们将执行作业来处理图像。最后,我们将清除环境,以免在完成后产生费用。
前提条件
在开始本指南之前,您需要一个亚马逊云科技账户。如果您还没有账户,请遵循设置亚马逊云科技环境指南中的说明获取快速概览。
执行步骤
设置 Amazon SageMaker Studio 域和数据集
在本教程中,我们将使用 Amazon SageMaker Studio 访问 Amazon SageMaker Data Wrangler 图像准备和处理。
Amazon SageMaker Studio 是一个集成开发环境 (IDE),它提供了一个基于 Web 的单一可视化界面,您可以在此使用专门构建的工具,可执行从准备数据到构建、训练和部署机器学习模型的所有机器学习开发步骤。
如果您已经拥有一个 US West (Oregon)「美国西部(俄勒冈)」区域的 SageMaker Studio 域,请按照 SageMaker Studio 设置指南将所需的 Amazon IAM 策略附加到您的 SageMaker Studio 账户,然后跳过步骤 1,直接执行步骤 2。
如果没有现有的 SageMaker Studio 域,请继续执行步骤 1,运行 Amazon CloudFormation 模板,创建 SageMaker Studio 域并添加本教程后续步骤所需的权限。
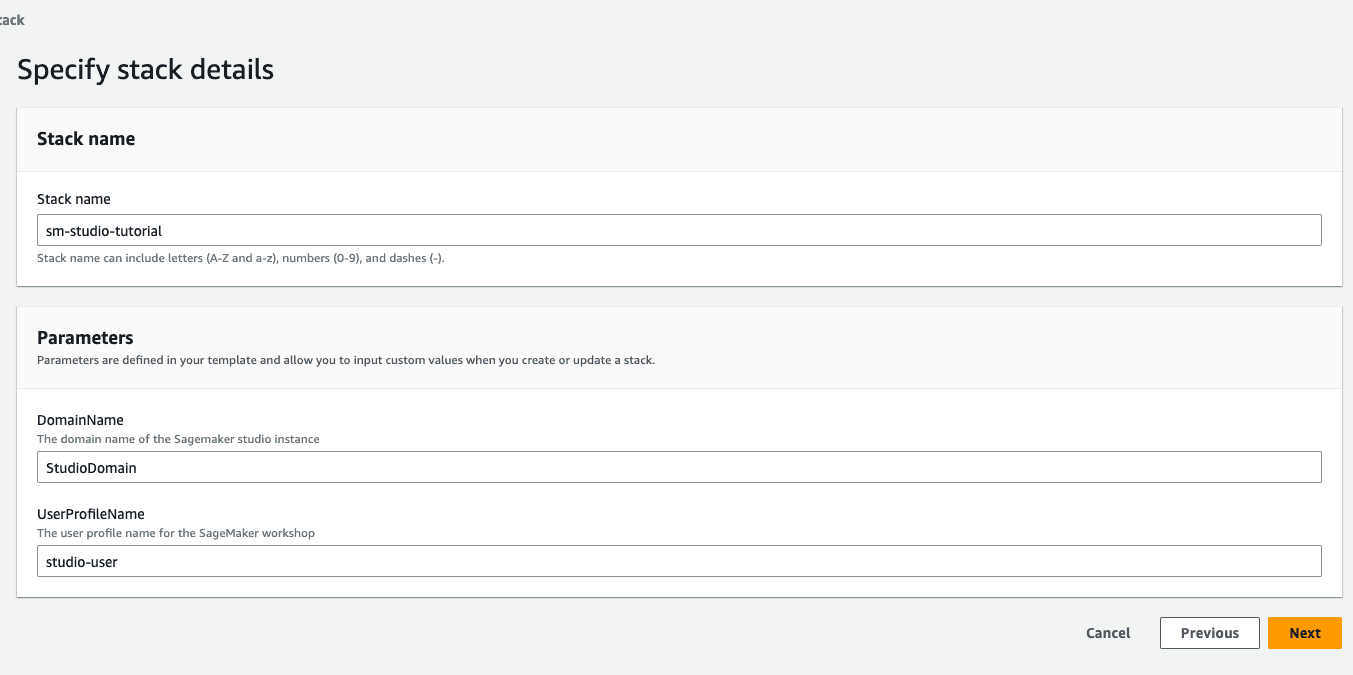
步骤 1:选择 Amazon CloudFormation 堆栈链接。您将通过此链接打开 Amazon CloudFormation 控制台,并创建 SageMaker Studio 域和名为 studio-user 的用户。您还将为您的 SageMaker Studio 账户添加所需的权限。在 CloudFormation 控制台上,确认右上角显示的区域是 US West (Oregon)「美国西部(俄勒冈)」。堆栈名称应为 sm-studio-tutorial,不应更改。系统需要 10 分钟左右来创建此堆栈的所有资源。
此堆栈假定您已在账户中设置了公共 VPC。如果没有公共 VPC,请参阅使用单个公有子网的 VPC 了解如何创建公共 VPC。
步骤 2:堆栈创建完成后,您可以继续将一些图像上传至 Amazon S3 存储桶。别担心,我们很快就会从 Kaggle 获得一些图像文件。
SageMaker Studio 会在 Studio 域所在的区域自动创建一个 Amazon S3 存储桶。我们这就去看看它。
我们会将图像文件放在 Amazon S3 中,以便从 SageMaker Studio 访问这些图像。Amazon S3 非常适合存储图像文件,因为其持久性强、可用性高且价格低廉!在管理控制台搜索栏中搜索 “S3”,导航至 Amazon S3。
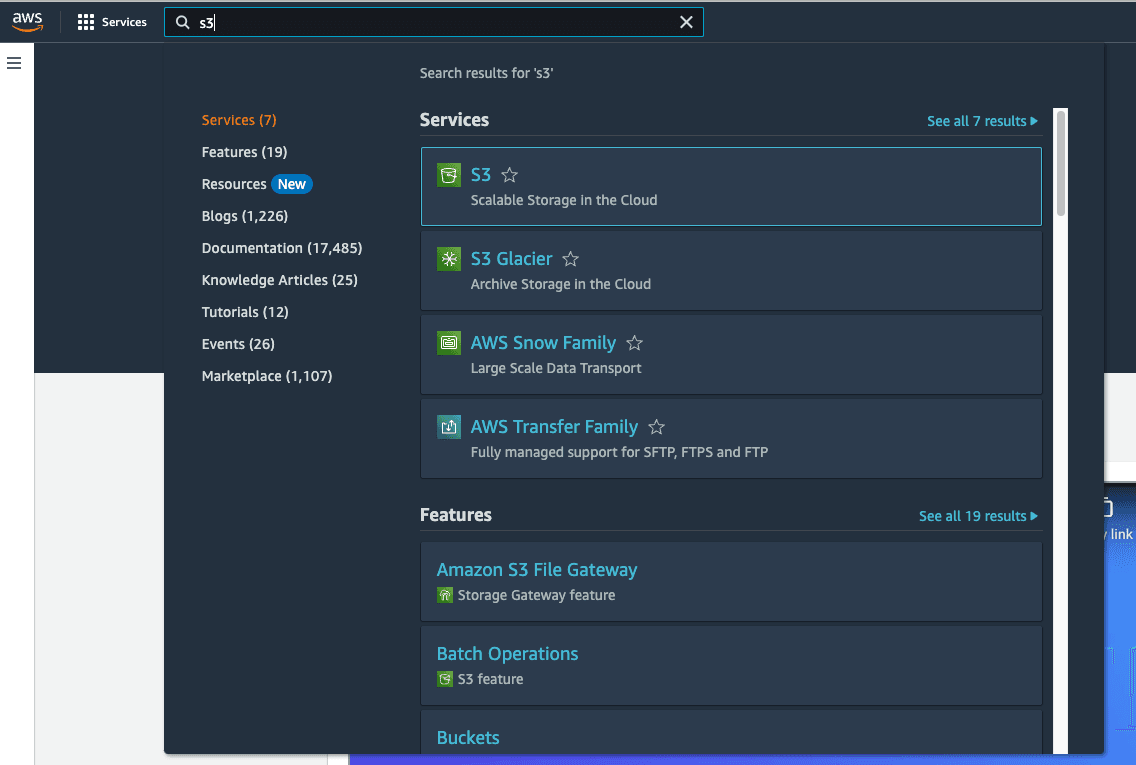
您将找到一个名为 sagemaker-studio-xxxxxxxx 的存储桶。点击该存储桶以上传文件。
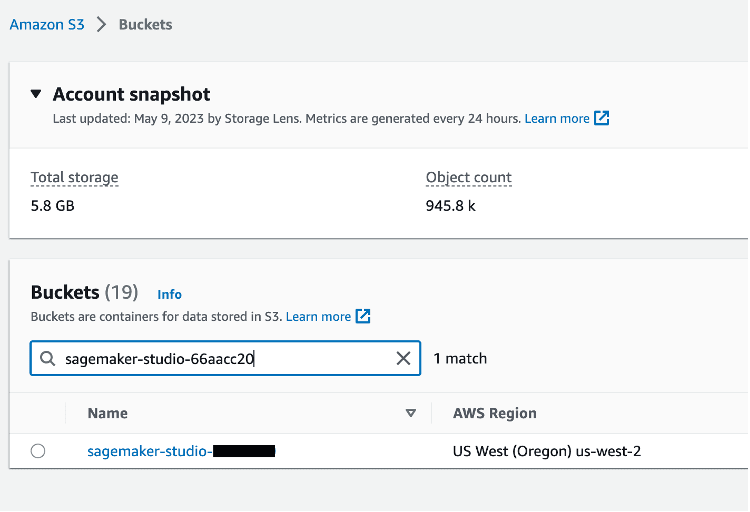
步骤 3:下载此示例数据集中的文件,然后解压缩内容。示例数据集包含 Kaggle 提供的事故和非事故的监控录像数据。该数据集包含从 YouTube 事故和非事故视频中捕获的帧。图像分为 train(训练)、test(测试)和 validation(验证)文件夹。
点击 Add folder(添加文件夹)上传文件夹解压缩之后的内容。
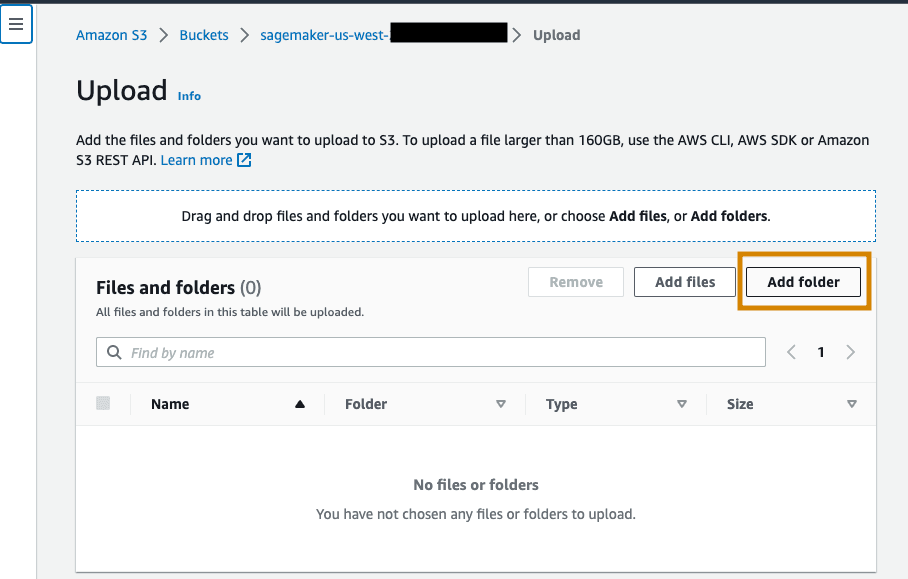
这样您就设置好了!我们已经设置了 Amazon SageMaker Studio,并将我们的图像保存在 Amazon S3 中。接下来,让我们开始使用 Amazon SageMaker Data Wrangler 处理图像。
将数据导入 SageMaker Data Wrangler 数据流
在本节中,您将在 SageMaker Studio 域中启动新的 Data Wrangler 流。您可以使用此数据流准备图像数据,而无需使用 Data Wrangler 用户界面 (UI) 编写代码。
步骤 4:让我们首先转到 SageMaker 并启动它。在控制台搜索栏中输入 SageMaker Studio,然后点击 SageMaker Studio。
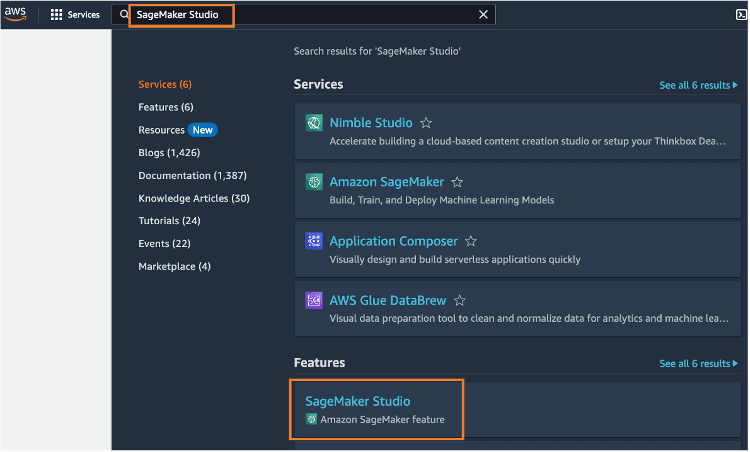
从 SageMaker 控制台右上角的区域下拉菜单中选择 US West (Oregon)「美国西部(俄勒冈)」。我们之所以选择此区域,是因为这是我们在上一节中部署 CloudFormation 模板的区域。
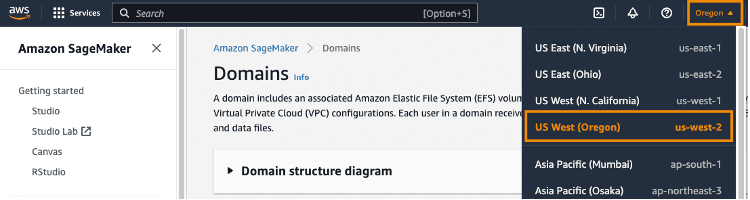
步骤 5:为了启动应用程序,请点击控制台左侧的 Studio,然后选择 studio-user 配置文件并点击 Open Studio(打开 Studio)。

您将看到 SageMaker Studio 正在创建应用程序,可能需要一些时间才能加载完成。这段时间您可以休息一下!
完成后,打开 SageMaker Studio 界面。在导航栏上,依次点击 File、New 和 Data Wrangler Flow(文件、新建、Data Wrangler 数据流)。
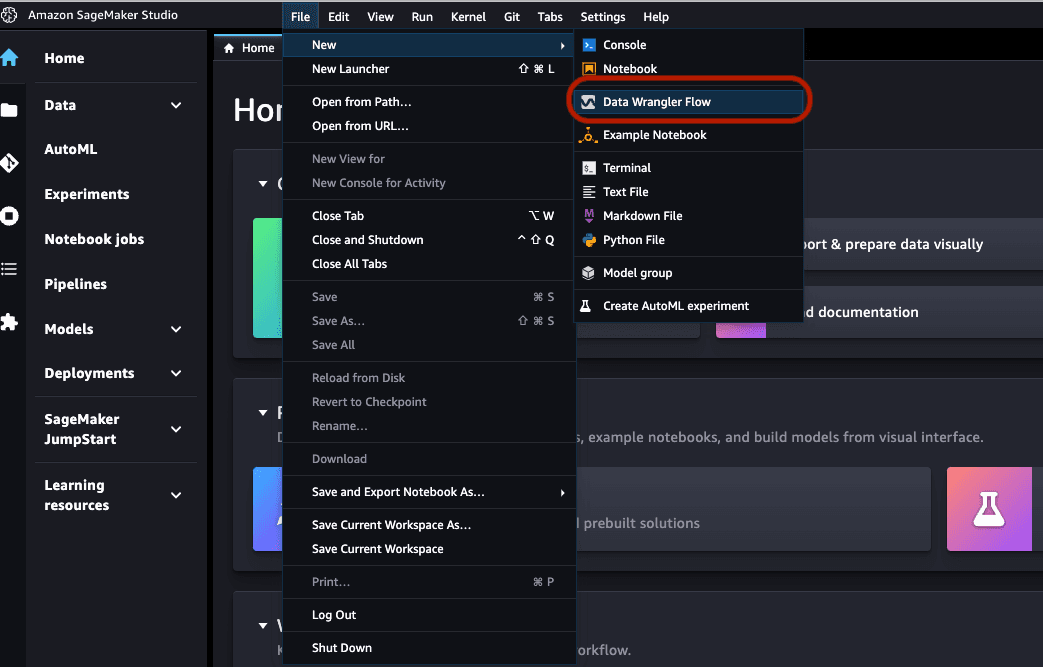
Data Wrangler 加载需要一些时间,在此过程中,请注意您可以将 Data Wrangler 连接至多个数据源。由于我们将图像保存在 Amazon S3 中,因此我们会将其用作数据源。
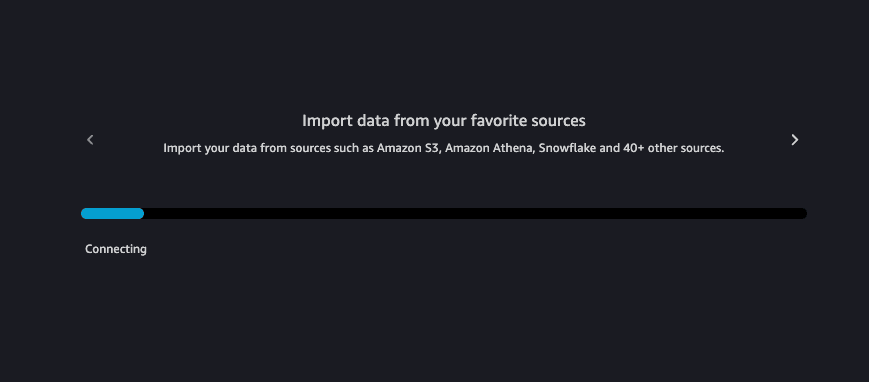
Data Wrangler 完全加载后,您可以右键点击 Flow(数据流)选项卡并重命名数据流。您可以将其重命名为任何名称,或类似 car_creash_detection_data.flow 这样的名称。
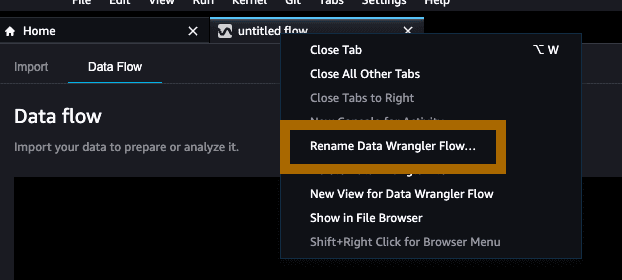
步骤 6:我们现在有数据流,也有 S3 中的数据。接下来我们将数据引入数据流中。点击 Import data(导入数据)以开始在数据流中加载数据。
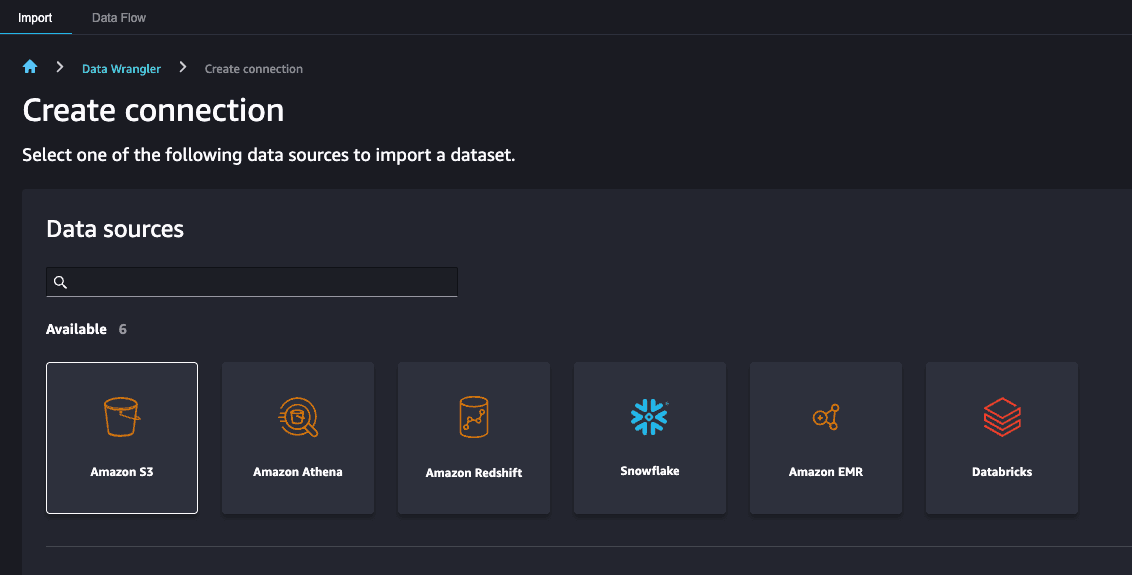
选择 Amazon S3 作为数据源,然后导航至包含上一节中的图像数据集的 Amazon S3 存储桶。
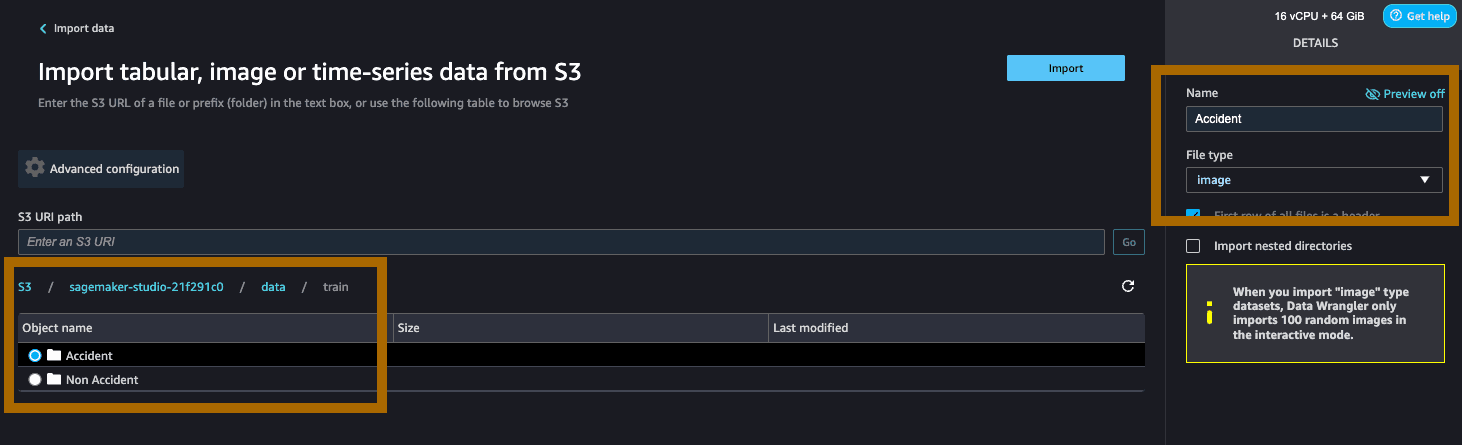
浏览文件夹前缀,找到 data/train 前缀,然后选择其中的 accident(事故)前缀。在右侧的 Details(详细信息)下,选择 image(图像)作为 File type(文件类型)。点击 Import(导入)。
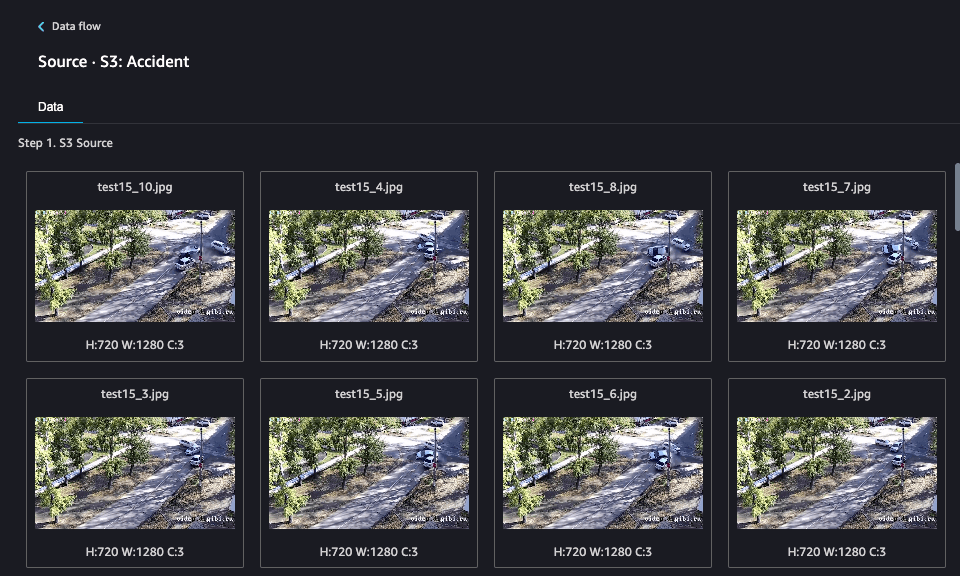
您可能注意到了,Data Wrangler 仅导入 100 张随机图像。这是合理的,因为如果它导入了所有内容,您就得在这里等它加载一整天,如果图像数量更多,花的时间甚至会更久!片刻之后,Data Wrangler 将在 UI 中显示图像。
图像准备步骤:损坏的图像
步骤 7:我们的数据流中有数据了。现在,我们可以转换数据以构建准确的模型。在本节中,您将使用 Amazon SageMaker Data Wrangler 内置转换来运行一系列图像转换步骤。希望这能帮助您熟悉 Data Wrangler 的图像转换功能。图像数据转换是构建更强大的模型的一种方法 - 增强数据图像不仅可以增加训练集的大小,还可以帮助模型更好地泛化。
如果您看不到 Add step(添加步骤)选项,请点击 “>” 图标以显示转换
点击 Add step(添加步骤),再点击 Corrupt image(损坏的图像)。
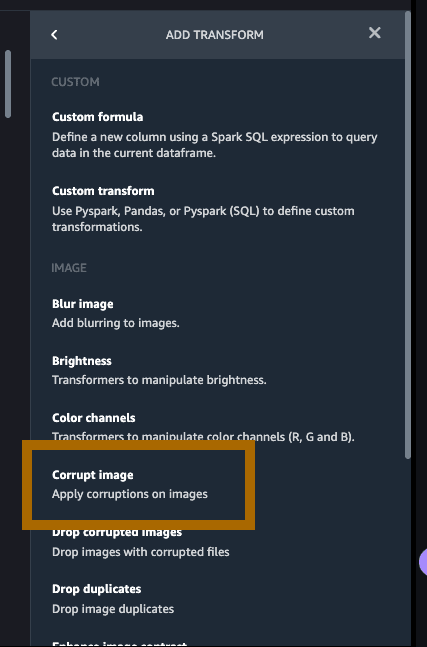
我们故意对这里的图像进行损坏处理,以此训练我们的模型在现实世界中遇到受损的图像时也能检测到事故。脉冲噪声通常也称为椒盐噪声,该术语指的是图像有暗斑、破损像素以及图像质量出现其他突发性干扰的情况。让我们将 Corruption(损坏类型)设为 Impulse noise(脉冲噪声),将 Severity(严重性)设为 3。点击 Preview(预览),再点击 Add(添加)。
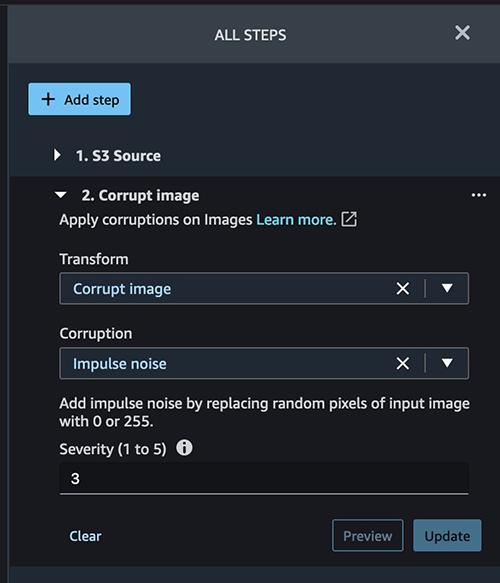
该步骤很快就会完成。这有助于训练我们的模型,因为并非所有图像数据都以完美的 4K 分辨率存在。
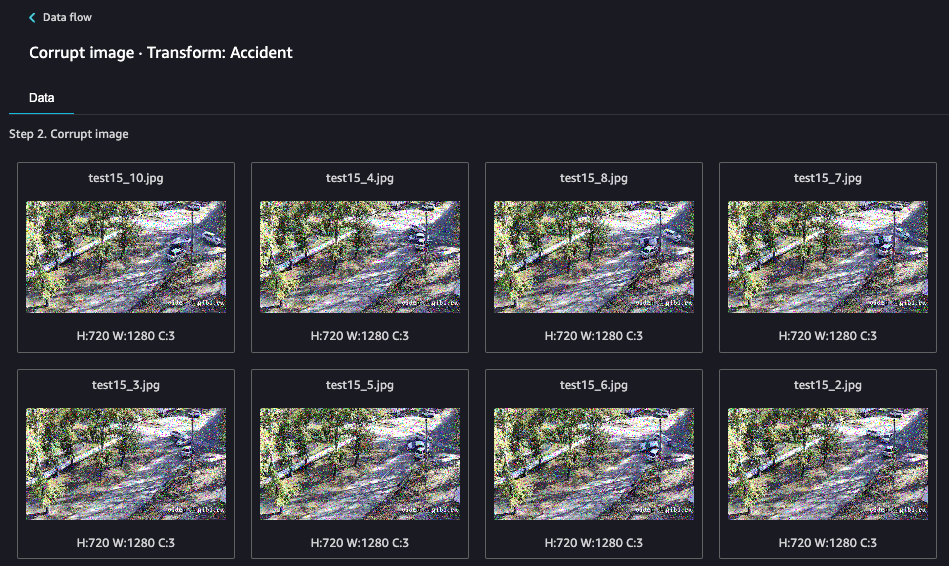
图像准备步骤:增强对比度和调整图像大小
步骤 8:在图像转换的下一阶段,您将增强对比度并调整图像大小,使其保持一致。您可能不会在每个使用场景中都执行这些步骤,但这些是 Data Wrangler 提供的用于改进图像数据集的内置转换示例。增强伽玛对比度可控制图像的整体亮度。而调整图像大小也是我们在拍照时经常做的事情。减小图像的大小可以使其更容易共享。它还可以通过丢弃不必要的像素来提高图像质量。
点击 Add step(添加步骤),再点击其中的 Enhance image contrast(增强图像对比度)。
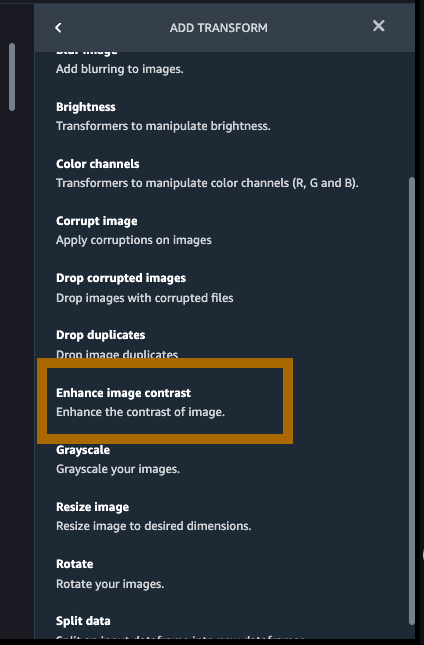
选择 Enhance Contrast(增强对比度)> Gamma contrast(伽玛对比度),将 Gamma 值设为 0.75,再点击 Preview(预览)和 Add(添加)。
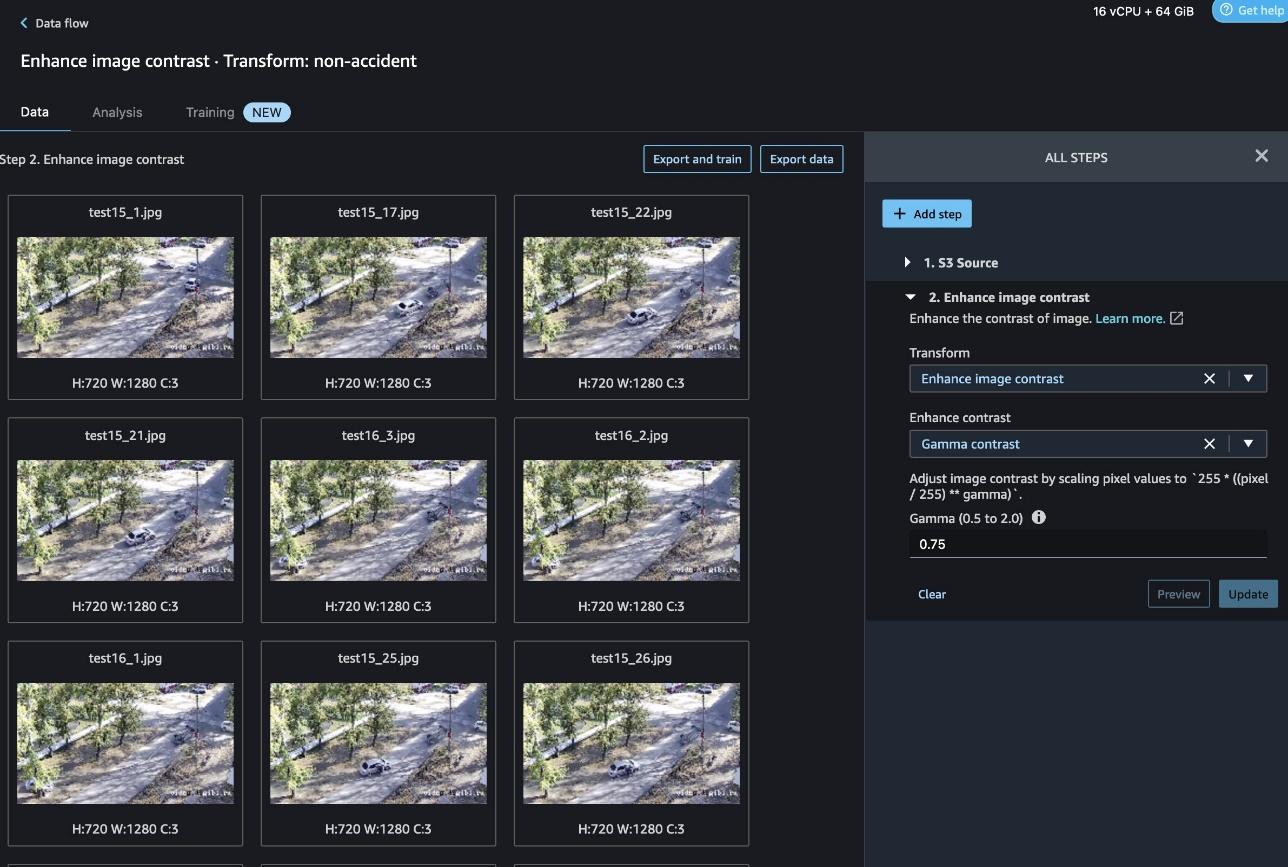
再添加一个调整图像大小的步骤。
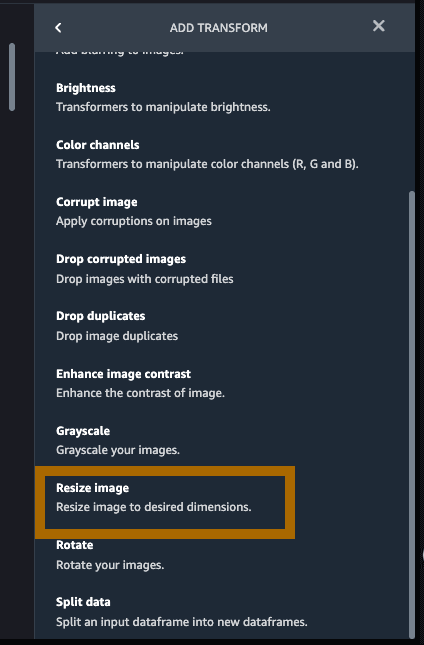
选择 Resize > Crop(调整图像大小 > 裁剪)将图像各边分别裁剪 50 像素。点击 Preview(预览),查看将对图像造成的更改,然后点击 Add(添加)。该操作最终会将图像大小从 720 x 1280 调整为 620 x 1180。
点击 Add(添加)。
图像准备步骤:自定义转换
步骤 9:在这一步中,我们将使用自定义转换来完成图像准备。到目前为止,您一直在使用 Data Wrangler 的内置转换来改进图像数据集,没有编写任何代码。但是,目前可用的内置功能或许不足以满足您的使用场景。如果找不到满足需求的内置转换,则可以将自定义转换用于图像准备工作流。在这种情况下,我们找不到能实现更好的边缘检测的内置转换,因此我们将编写自己的转换。
点击 Add step(添加步骤),再点击 Custom transform(自定义转换)。
给自定义转换指定一个名称,比如 “Edge detection”(边缘检测),再选择 Python (PySpark)。
将以下 Python 代码粘贴到自定义转换代码段中。
# A table with your image data is stored in the 'df' variable
import cv2
import numpy as np
from pyspark.sql.functions import column
def my_transform(image: np.ndarray) -> np.ndarray:
# To use the code snippet on your image data, modify the following lines within the function
HYST_THRLD_1, HYST_THRLD_2 = 100, 200
edges = cv2.Canny(image,HYST_THRLD_1,HYST_THRLD_2)
return edges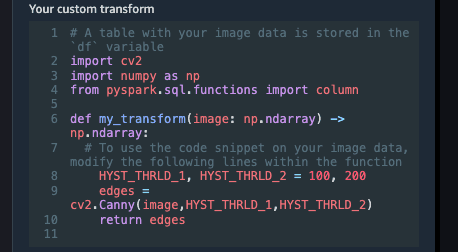
我们使用 Canny 边缘检测器来更好地揭示图像中物体的结构。为达成这一目的,我们要检测图像中物体的轮廓。点击 Preview(预览),查看将对图像造成的更改,然后点击 Add(添加)。
现在,您应该可以看到图像准备数据流中的所有步骤。
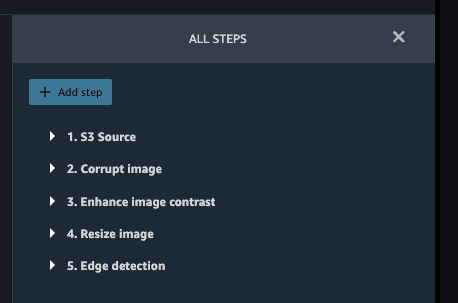
将准备好的图像数据导出到另一个 S3 存储桶
步骤 10:在这一步中,您将最终确定所用的转换,以便将数据流的结果输出到 Amazon S3 存储桶。
点击 Data flow(数据流),回到数据流。

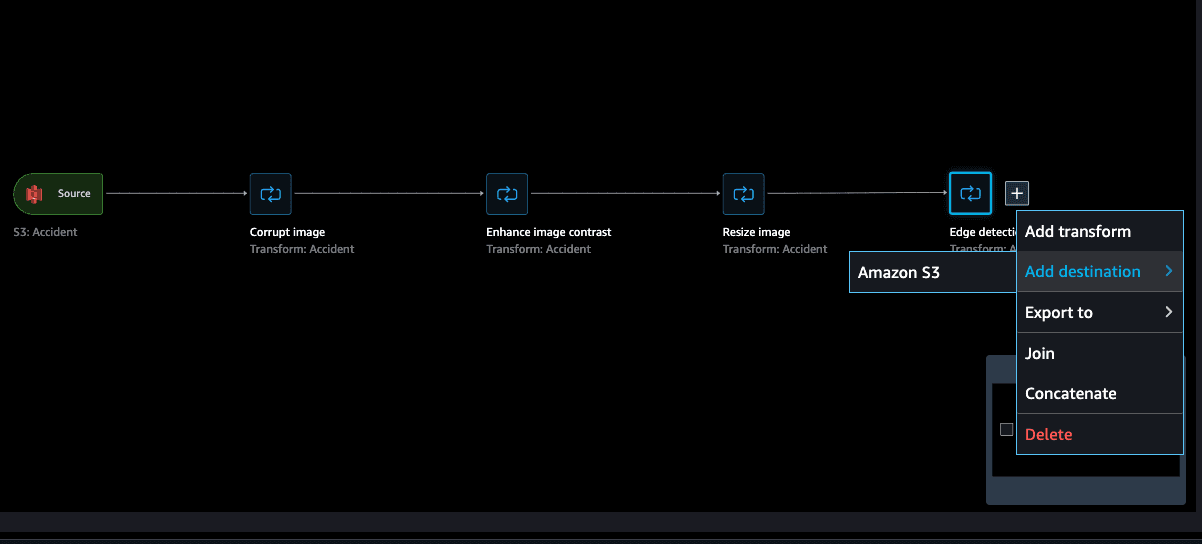
您可以可视化您的数据流,用流程图展示您定义的每个步骤。点击 + 图标,将结果添加到 S3 中的目标。
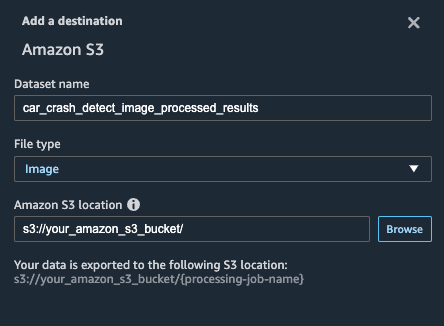
为数据集命名。将 File type(文件类型)设为 Image(图像),并提供用于保存文件的 Amazon S3 位置。点击 Add destination(添加目标)。
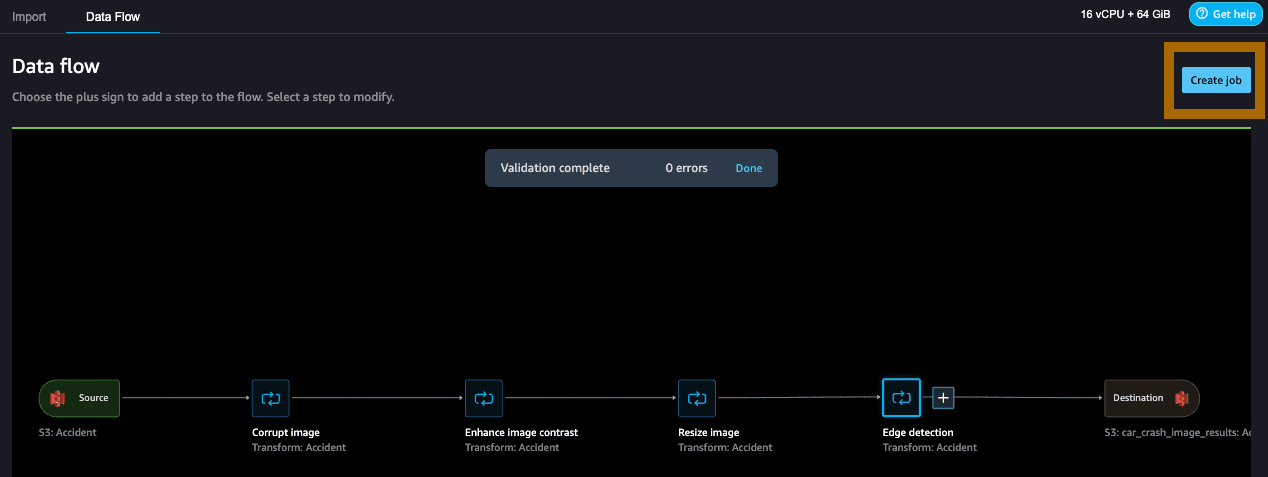
您已经完成了从转换到将输出保存至 Amazon S3 的整个数据流。现在,点击 Create job(创建作业)即可从头到尾运行整个数据流。
创建 Data Wrangler 作业以处理图像
步骤 11:最后,我们将使用 Data Wrangler 运行图像处理流程,并将结果保存至指定的 Amazon S3 存储桶中。这项作业可以由事件、计划触发,也可以手动触发。这样一来,我们迄今为止构建的所有内容就都具有可重复性和可扩展性。
命名 Job name(作业名称),创建作业。我们可以将其他选项留空。点击 Next(下一步)。
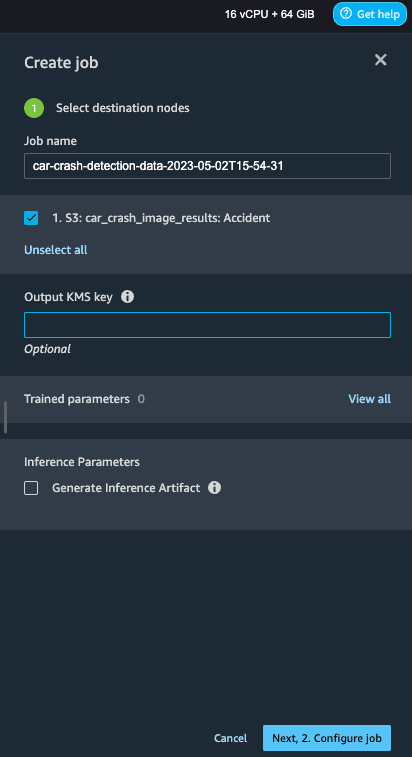
在下一页上,选择 Instance type(实例类型)和 Count(数量),允许 SageMaker 启动以运行作业。您可以更改其他配置,但我们将使用默认配置。
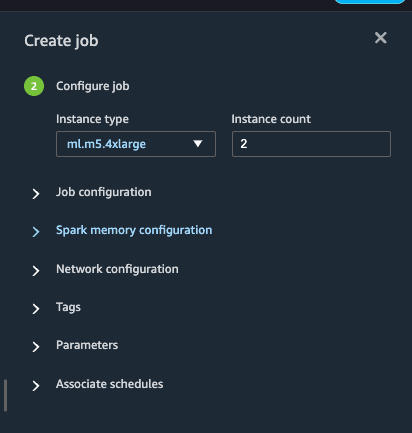
最后,点击 Create(创建)。
我们可以在亚马逊云科技控制台中依次点击 Amazon SageMaker、Processing jobs(处理中的作业),依据所处理作业的名称和/或它的 ARN 来监控作业进展情况。处理作业大约需要 7 分钟才能完成,因为我们要处理整个数据集。
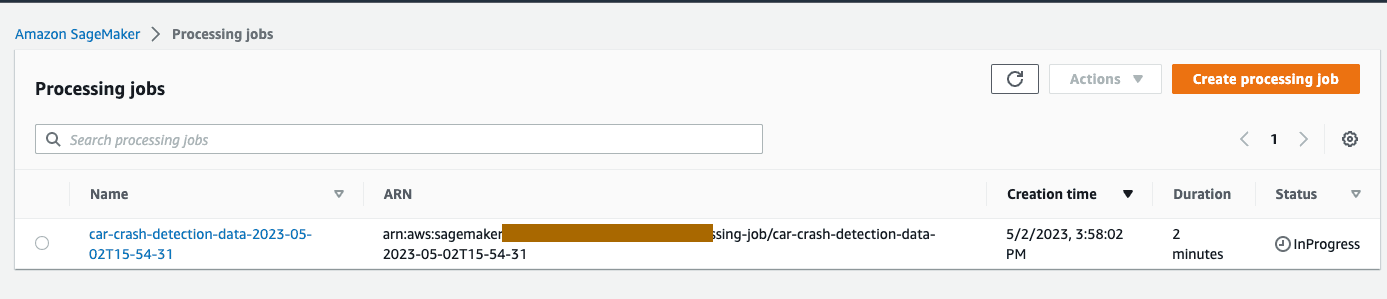
任务完成后,即可在您指定的 Amazon S3 存储桶中查看结果。
恭喜您!您已经完成了使用 Amazon SageMaker Data Wrangler 准备图像数据的教程,整个过程几乎不需要编写代码!
清理资源
对于您不再需要的资源,最佳做法是及时删除,以避免产生意外费用。
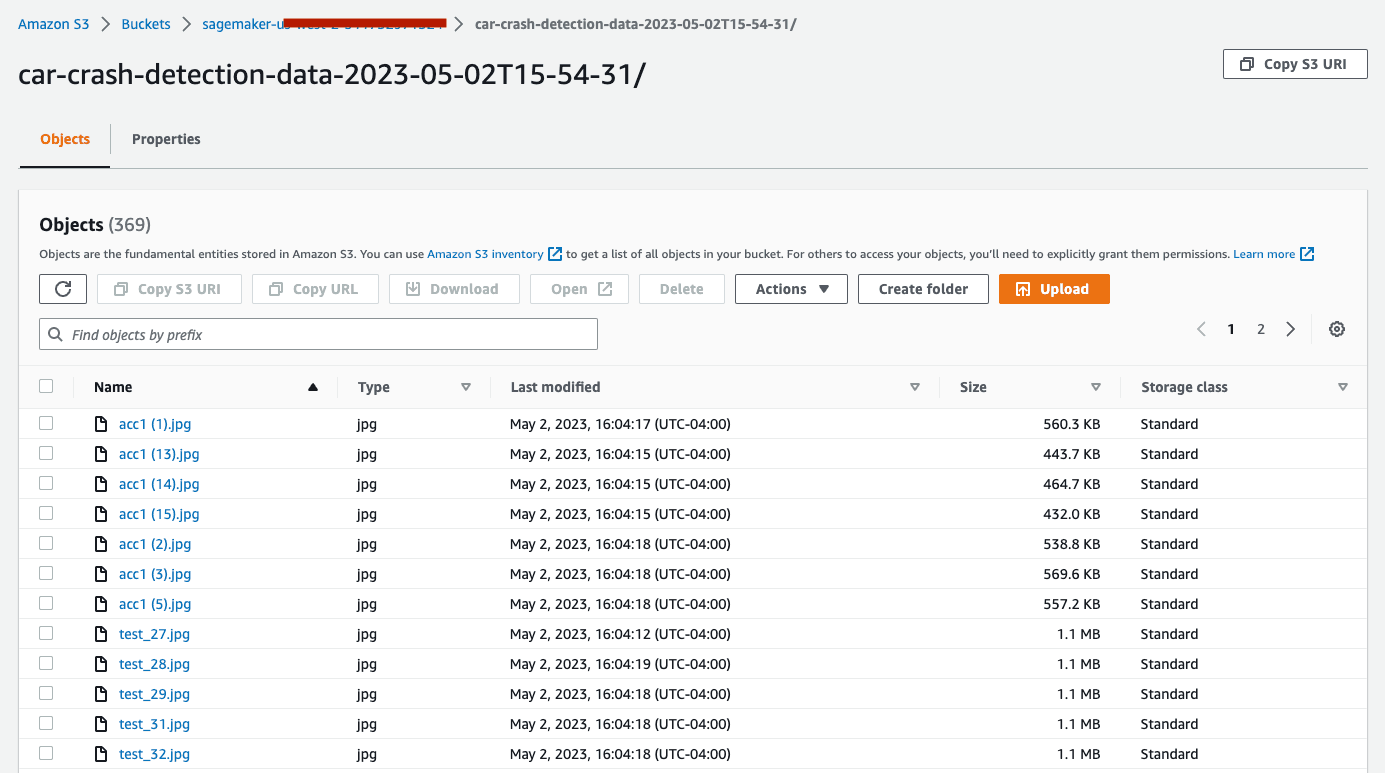
要删除 S3 存储桶,请打开 Amazon S3 控制台。在导航栏上,依次点击 Buckets、sagemaker-studio-xxxxxxxxx,然后选中数据集和输出结果旁边的复选框。
在 Delete objects(删除对象)对话框中,确认您选择的删除对象正确无误,并在 Permanently delete objects(永久删除对象)确认框中输入 permanently delete(永久删除)。
完成此操作且存储桶为空后,您可以再次执行相同的过程删除 sagemaker-studio-xxxxxxxxx 存储桶。
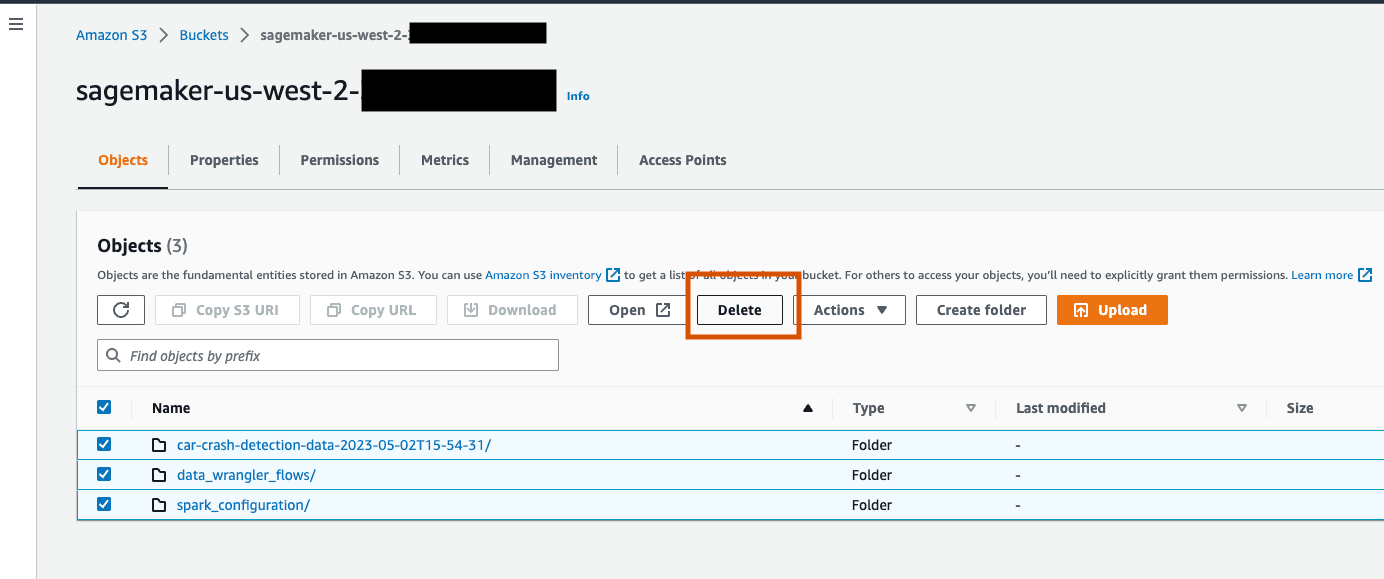
若您不停止内核或执行以下步骤来删除应用程序,本教程中用于运行数据流的 Wrangler 内核将继续累积费用。有关更多信息,请参阅 Amazon SageMaker 开发者指南中的关闭资源。
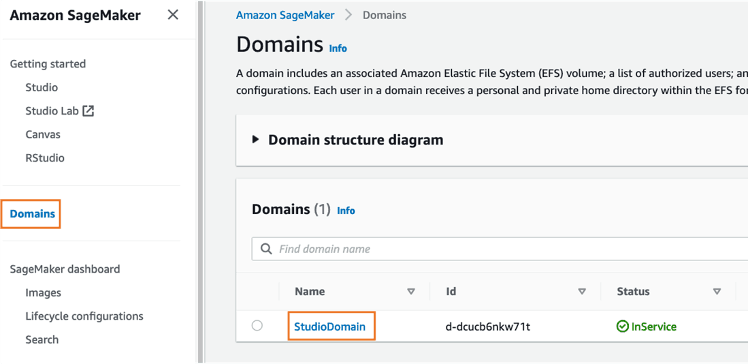
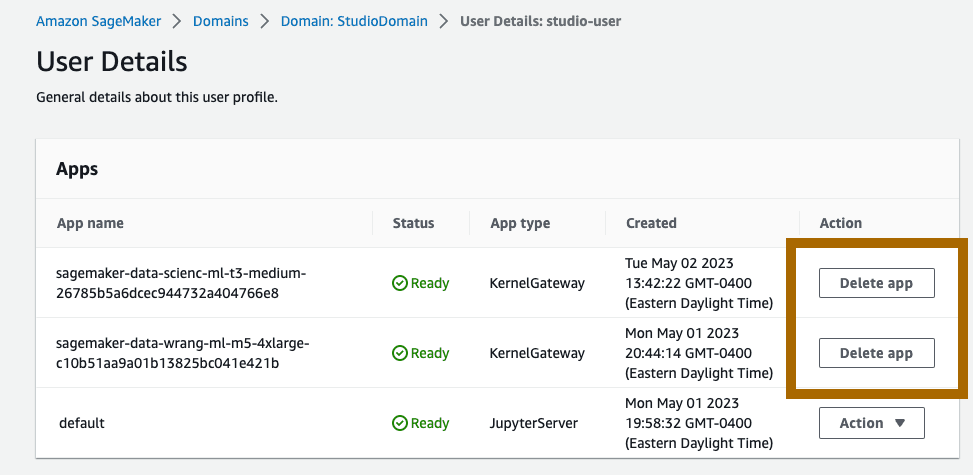
要删除 SageMaker Studio 应用程序,请执行以下操作:在 SageMaker 控制台上,选择 Domains(域),然后选择 StudioDomain。从用户配置文件列表中选择 studio-user,然后点击 Delete app(删除应用程序),删除 Apps(应用程序)下列出的所有应用程序。若要删除 JupyterServer,请选择 Action(操作)下拉菜单中的 Delete(删除)。请耐心等待,直到 Status(状态)变为 Deleted(已删除)为止。
如果您在步骤 1 中使用现有的 SageMaker Studio 域,请跳过步骤 5 的其余部分,直接进入结论部分。
如果您在步骤 1 中创建新的 SageMaker Studio 域时运行了 CloudFormation 模板,请继续执行以下步骤来删除域、用户和由 CloudFormation 模板创建的资源。
为打开 CloudFormation 控制台,请在亚马逊云科技控制台搜索栏中输入 CloudFormation,然后从搜索结果中选择 CloudFormation。
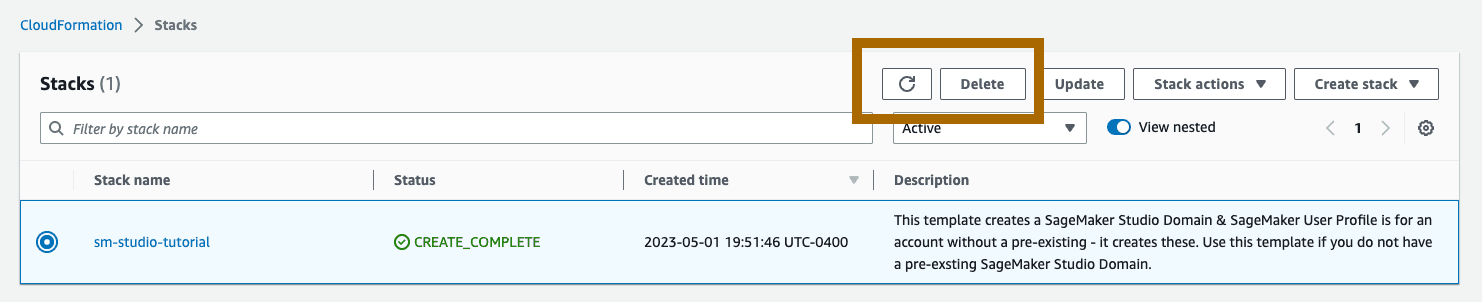
打开 CloudFormation 控制台。在 CloudFormation 面板上,选择 Stacks(堆栈)。从状态下拉菜单中,选择 Active(运行中)。在 Stack name(堆栈名)下,选择 sm-studio-tutorial 以打开堆栈详情页面。
在 sm-studio-tutorial 堆栈详情页面上,点击 Delete 删除此堆栈和它在步骤 1 中创建的资源。
总结
恭喜您!您已完成利用 Amazon SageMaker Data Wrangler 准备图像数据的教程。
在本教程中,您使用了 Amazon SageMaker Data Wrangler,通过内置和自定义转换来准备图像数据。您将步骤保存为 Data Wrangler 数据流,并执行了将输出保存至 Amazon S3 存储桶的作业。
SageMaker Data Wrangler 是 Amazon SageMaker 提供的一系列广泛功能中的一项。您可以集成 SageMaker Data Wrangler 与 Amazon SageMaker Autopilot,探索如何创建端到端图像预处理、模型构建、微调和部署的管道。查看此博客,了解如何操作。您还可以详细了解 Amazon SageMaker 提供的各种各样的功能,它们可以满足数据科学家和业务分析师的各种使用场景。祝您快乐!


{kind=link}