使用 GitHub Actions 将无服务器 Spark 作业部署到亚马逊云科技

Apache Spark 是本地和云端最常用的数据处理框架之一。尽管 Apache Spark 很常用,但相关的现代化 DevOps 实践缺乏完善的文档,或者无法供数据团队直接采用。GitHub Actions 已成为在代码库中维护持续集成和持续部署的常用工具。通过将开发工作流与源代码相结合,开发人员可以获得有关代码更改的即时反馈,从而可以加快迭代速度。在试验中,我们将通过 GitHub Actions 将一个端到端 Spark ETL 管道部署到 Amazon EMR Serverless,以衡量给定地点的天气趋势。我们的示例应用是一个分析指定地点天气趋势的应用。
学习内容
- 如何使用 Amazon EMR Serverless
- 如何设置 OpenID Connect
- 如何配置适用于 PySpark 的单元测试和集成测试
- 如何自动部署最新代码





前提条件
本文介绍如何使用 Python 构建一个可直接投入生产环境的 Spark 作业,该作业可以自动运行单元测试和集成测试、自动构建和部署新的版本,甚至支持手动运行或定期运行 ETL 作业。
实验过程中,我们将创建一个新的存储库,构建一个 PySpark 作业,将其部署到生产环境中,并运行单元测试和集成测试,自动部署受版本控制的资产以及运行自动化作业。我们将使用美国国家海洋和大气管理局 (NOAA) 全球每日地表概况作为数据源。
在开始本试验前,您需要具备:
- 亚马逊云科技账户(如果您还没有账户,请创建一个账户并设置环境)。
- GitHub 账户(可在 github.com 上免费注册)
- git 命令行工具
- 编辑器(VS Code、vim、emacs 或 Notepad.exe)
此外,还需要创建运行作业的基础设施。此试验中,我们仅创建一组资源。在真实环境中,您可能需要创建测试环境、预发环境和生产环境,并为了在不同的环境中运行而更改您的工作流,甚至在完全不同的亚马逊云科技账户中运行。所需资源:
- EMR Serverless 应用程序:我们将使用 EMR 6.9.0 和 Spark 3.3.0
- S3 存储桶:用于存储集成测试构建、受版本控制的生产版本以及每次作业运行的日志
- IAM 角色
- 一个 GitHub Action 使用的角色。该角色具有部署和运行 Spark 作业以及查看日志的权限。
- 一个 Spark 作业使用的角色。该角色具有访问 S3 存储桶中的数据的权限。
创建运行 Demo 的资源
注意:此 demo 应用只能在 us-east-1 区域运行。若要使用其他区域,则需要创建连接 VPC 的 EMR Serverless 应用程序。
您可以通过以下方式创建资源:下载 CloudFormation 模板,然后使用 Amazon CLI 上传模板,或者前往 CloudFormation 控制台上传模板。
创建该堆栈时,您可以设置两个参数:
- GitHubRepo 指定 OIDC 角色能够访问的 GitHub 存储库。参数取值格式:user/repo。我们将在下一个步骤中创建存储库,其名称为 <your-github-username>/ci-cd-serverless-spark
- CreateOIDCProvider 指定在亚马逊云科技账户下已存在 GitHub OIDC 端点的情况下,是否允许继续创建此类端点。
# Make sure to replace the ParameterValue for GitHubRepo below
aws cloudformation create-stack \
--region us-east-1 \
--stack-name gh-serverless-spark-demo \
--template-body file://./ci-cd-serverless-spark.cfn.yaml \
--capabilities CAPABILITY_NAMED_IAM \
--parameters ParameterKey=GitHubRepo,ParameterValue=USERNAME/REPO ParameterKey=CreateOIDCProvider,ParameterValue=true堆栈创建后,在 CloudFormation 控制台上导航至所创建堆栈的“Outputs”(输出)选项卡,查看输出信息,因为稍后需要使用这些值。
注意:实验过程中需要多次复制/粘贴这些信息。如果您想查看最终状态,请参考 ci-cd-serverless-spark repo。
让我们开始吧!
创建 git push 请求触发的单元测试
首先,在 GitHub 上创建一个存储库,并将该库命名为 ci-cd-serverless-spark。该存储库可以是公共存储库,也可以是私有存储库。
注意:该存储库名称必须与创建 CloudFormation 堆栈时指定的存储库名称完全相同。
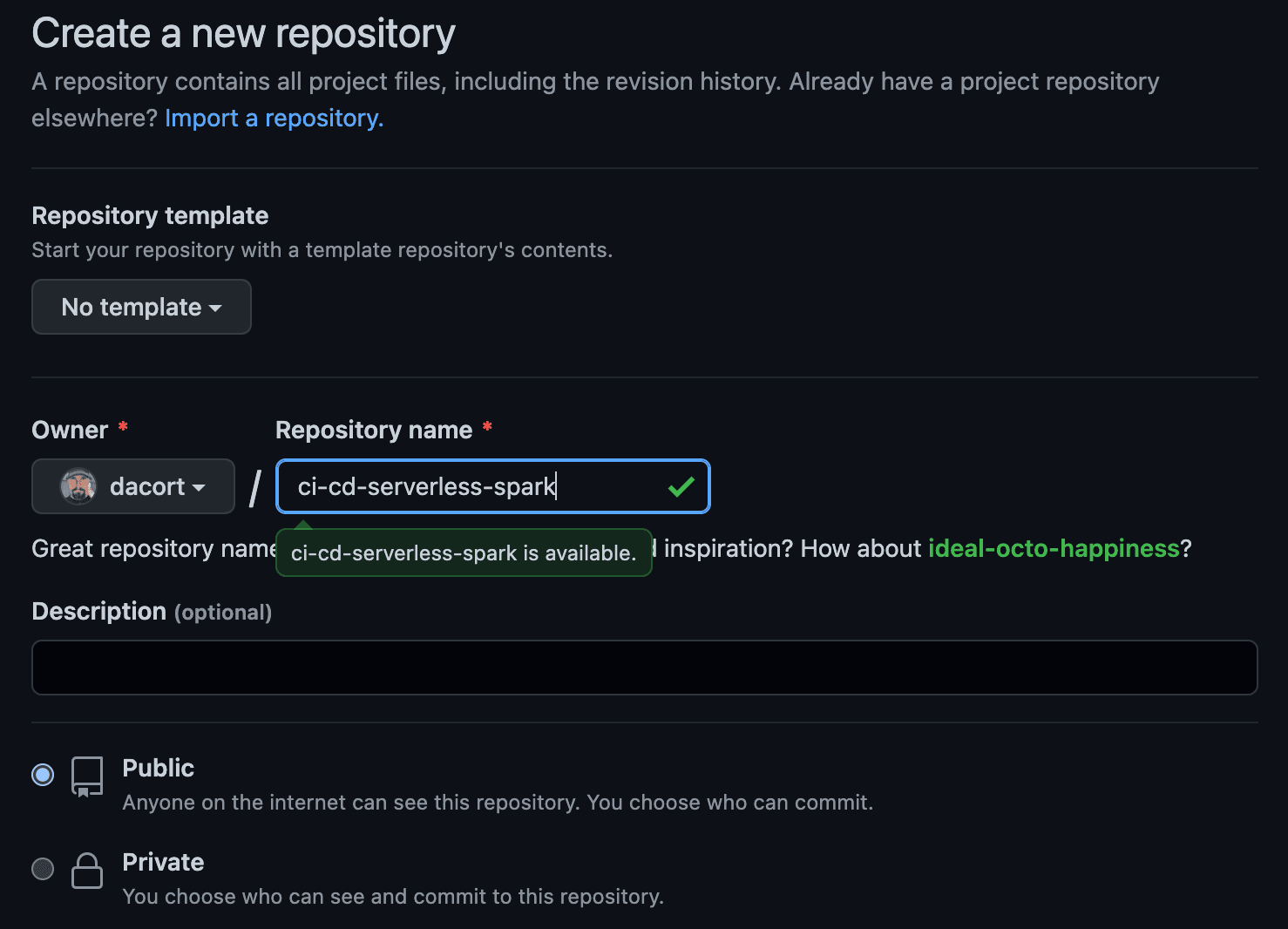
创建初始源代码结构和一个 GitHub 操作,并将其配置为每次收到 git push 请求后运行。如果在标准终端中运行,则需要在 pyspark/tests 目录中创建一个 test_basic.py 文件,并在 pyspark 目录中创建一个 requirements-dev.txt 文件。
# First clone your repository
git clone github.com/<USERNAME>/<REPOSITORY>
# Change into the cloned repository
# Make the directories we'll need for the rest of the tutorial
cd ci-cd-serverless-spark
mkdir -p .github/workflows pyspark/tests pyspark/jobs pyspark/tests pyspark/scripts- 在 pyspark/tests 中创建一个 test_basic.py 文件。文件中,仅包含以下简单断言。
def test_is_this_on():
assert 1 == 1- 在 pyspark 中创建一个 requirements-dev.txt 文件。文件中,定义开发环境所需的 Python 版本。
pytest==7.1.2接下来,创建 GitHub 操作,用于推送代码时运行单元测试。GitHub Actions 会在 GitHub 存储库中创建工作流文件,而 GitHub 上的多种操作可以触发这些文件,从而自动执行软件工作流。这个 GitHub 操作会在我们每次将新的代码推送至存储库时自动运行 pytest。
因此,在 .github/workflows 目录中创建一个 unit-tests.yaml 文件。该文件内容如下所示:
name: Spark Job Unit Tests
on: [push]
jobs:
pytest:
runs-on: ubuntu-20.04
defaults:
run:
working-directory: ./pyspark
steps:
- uses: actions/checkout@v3
- name: Set up Python 3.7.10
uses: actions/setup-python@v4
with:
python-version: 3.7.10
cache: "pip"
cache-dependency-path: "**/requirements-dev.txt"
- name: Install dependencies
run: |
python -m pip install -r requirements-dev.txt
- name: Analysing the code with pytest
run: |
python3 -m pytest这段代码用于实现如下几步操作:
- 检测代码
- 安装 Python 3.7.10(EMR Serverless 使用的版本)
- 安装 pytest 依赖项。该依赖项定义来自 requirements-dev.txt
- 运行 pytest
添加以上三个文件后,我们就可以运行 git add 和 git push 命令添加和推送代码。文件目录结构:

git add .
git commit -am "Initial Revision"
git push返回到 GitHub UI,可以看到代码提交旁边有一个黄色圆点。这表明有一个操作正在运行。GitHub 运行器启动后,点击黄色圆点或“Actions”(操作)选项卡,可以查看代码提交日志。
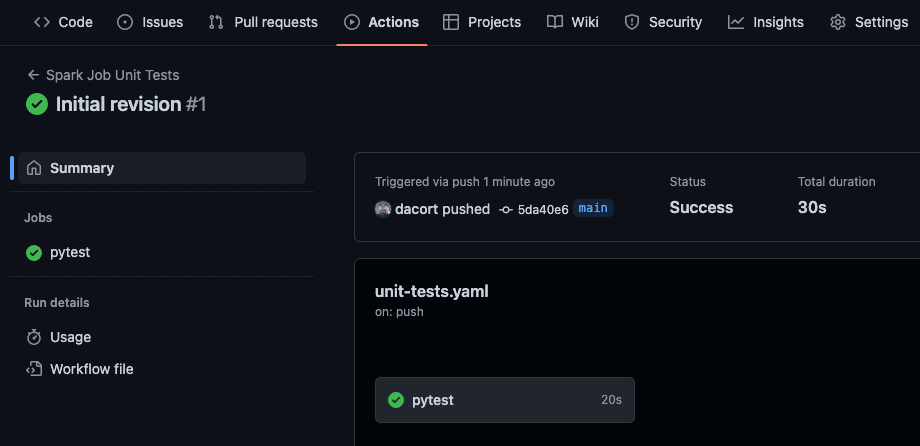
测试成功!以后,您每次执行 git push 操作时,系统都会运行 pyspark/tests 中的单元测试来检验您的代码。我们继续创建一些 Spark 代码。
添加 PySpark 分析和单元测试
我们将使用 NOAA GSOD 数据集作为源数据。接下来,添加主要 PySpark 入口点脚本和一个新的类,该类可以返回 Spark 数据帧中的最大值。
我们看一下源数据集。原数据结构非常典型,也非常简明。我们有一个 S3 存储桶,其中 CSV 文件以年为单位分区存储。每个 CSV 文件都以特定的天气观测站 ID 命名。打开其中一个文件,就会看到其中包含了每日天气数据,包括最低、最高和平均温度,风力和气压,还有降水量和降水类型。如需了解有关该数据集的更多信息,请访问 noaa.gov。
美国华盛顿州西雅图市波音菲尔德机场的天气观测站 ID 是 72793524234。下表是来自该站点的数据。这些数据存储于 s3://noaa-gsod-pds/2022/72793524234.csv。
+-----------+----------+--------+----------+---------+---------------------------+----+---------------+----+---------------+------+--------------+----+--------------+-----+----------------+----+---------------+-----+-----+----+--------------+----+--------------+----+---------------+-----+------+
|STATION |DATE |LATITUDE|LONGITUDE |ELEVATION|NAME |TEMP|TEMP_ATTRIBUTES|DEWP|DEWP_ATTRIBUTES|SLP |SLP_ATTRIBUTES|STP |STP_ATTRIBUTES|VISIB|VISIB_ATTRIBUTES|WDSP|WDSP_ATTRIBUTES|MXSPD|GUST |MAX |MAX_ATTRIBUTES|MIN |MIN_ATTRIBUTES|PRCP|PRCP_ATTRIBUTES|SNDP |FRSHTT|
+-----------+----------+--------+----------+---------+---------------------------+----+---------------+----+---------------+------+--------------+----+--------------+-----+----------------+----+---------------+-----+-----+----+--------------+----+--------------+----+---------------+-----+------+
|72793524234|2023-01-01|47.54554|-122.31475|7.6 |SEATTLE BOEING FIELD, WA US|44.1|24 |42.7|24 |1017.8|16 |17.4|24 |8.1 |24 |1.4 |24 |6.0 |999.9|48.9| |39.9| |0.01|G |999.9|010000|
|72793524234|2023-01-02|47.54554|-122.31475|7.6 |SEATTLE BOEING FIELD, WA US|37.8|24 |34.0|24 |1010.1|16 |10.2|24 |5.2 |24 |2.5 |24 |13.0 |999.9|50.0| |30.0| |0.01|G |999.9|100000|
|72793524234|2023-01-03|47.54554|-122.31475|7.6 |SEATTLE BOEING FIELD, WA US|41.0|24 |30.5|24 |1008.7|22 |7.8 |24 |10.0 |24 |4.5 |24 |11.1 |999.9|50.0| |30.0| |0.0 |G |999.9|010000|
|72793524234|2023-01-04|47.54554|-122.31475|7.6 |SEATTLE BOEING FIELD, WA US|42.6|24 |30.3|24 |1010.6|24 |9.7 |24 |10.0 |24 |2.3 |24 |14.0 |21.0 |51.1| |35.1| |0.0 |G |999.9|000000|
+-----------+----------+--------+----------+---------+---------------------------+----+---------------+----+---------------+------+--------------+----+--------------+-----+----------------+----+---------------+-----+-----+----+--------------+----+--------------+----+---------------+-----+------+我们要运行的作业非常简单:提取某一年中所有天气观测站的极端天气事件。
为了构建 PySpark 作业,我们将在 pyspark 目录中创建以下文件:
- 一个 entrypoint.py 文件,用于初始化作业并运行分析:
import sys
from datetime import date
from jobs.extreme_weather import ExtremeWeather
from pyspark.sql import SparkSession
if __name__ == "__main__":
"""
Usage: extreme-weather [year]
Displays extreme weather stats (highest temperature, wind, precipitation) for the given, or latest, year.
"""
spark = SparkSession.builder.appName("ExtremeWeather").getOrCreate()
if len(sys.argv) >1 and sys.argv[1].isnumeric():
year = sys.argv[1]
else:
year = date.today().year
df = spark.read.csv(f"s3://noaa-gsod-pds/{year}/", header=True, inferSchema=True)
print(f"The amount of weather readings in {year} is: {df.count()}\n")
print(f"Here are some extreme weather stats for {year}:")
stats_to_gather = [
{"description": "Highest temperature", "column_name": "MAX", "units": "°F"},
{"description": "Highest all-day average temperature", "column_name": "TEMP", "units": "°F"},
{"description": "Highest wind gust", "column_name": "GUST", "units": "mph"},
{"description": "Highest average wind speed", "column_name": "WDSP", "units": "mph"},
{"description": "Highest precipitation", "column_name": "PRCP", "units": "inches"},
]
ew = ExtremeWeather()
for stat in stats_to_gather:
max_row = ew.findLargest(df, stat["column_name"])
print(
f" {stat['description']}: {max_row[stat['column_name']]}{stat['units']} on {max_row.DATE} at {max_row.NAME} ({max_row.LATITUDE}, {max_row.LONGITUDE})"
)- 一个 jobs/extreme_weather.py 文件。该文件中将实际分析代码拆解为多个可进行单元测试的方法:
from pyspark.sql import DataFrame, Row
from pyspark.sql import functions as F
class ExtremeWeather:
def findLargest(self, df: DataFrame, col_name: str) -> Row:
"""
Find the largest value in `col_name` column.
Values of 99.99, 999.9 and 9999.9 are excluded because they indicate "no reading" for that attribute.
While 99.99 _could_ be a valid value for temperature, for example, we know there are higher readings.
"""
return (
df.select(
"STATION", "DATE", "LATITUDE", "LONGITUDE", "ELEVATION", "NAME", col_name
)
.filter(~F.col(col_name).isin([99.99, 999.9, 9999.9]))
.orderBy(F.desc(col_name))
.limit(1)
.first()
)我们还将创建一个分析单元测试和一些模拟数据。
在 pyspark/tests 中,创建一个 conftest.py 文件。
- conftest.py - 创建用于测试的示例数据帧
import pytest
from pyspark.sql import SparkSession, SQLContext
@pytest.fixture(scope="session")
def mock_views_df():
spark = (
SparkSession.builder.master("local[*]")
.appName("tests")
.config("spark.ui.enabled", False)
.getOrCreate()
)
return spark.createDataFrame(
[
("72793524234","2023-01-01",47.54554,-122.31475,7.6,"SEATTLE BOEING FIELD, WA US",44.1,24,42.7,24,1017.8,16,017.4,24,8.1,24,1.4,24,6.0,999.9,48.9,"",39.9,"",0.01,"G",999.9,"010000"),
("72793524234","2023-01-02",47.54554,-122.31475,7.6,"SEATTLE BOEING FIELD, WA US",37.8,24,34.0,24,1010.1,16,010.2,24,5.2,24,2.5,24,13.0,999.9,50.0,"",30.0,"",0.01,"G",999.9,"100000"),
("72793524234","2023-01-03",47.54554,-122.31475,7.6,"SEATTLE BOEING FIELD, WA US",41.0,24,30.5,24,1008.7,22,007.8,24,10.0,24,4.5,24,11.1,999.9,50.0,"",30.0,"",0.00,"G",999.9,"010000"),
("72793524234","2023-01-04",47.54554,-122.31475,7.6,"SEATTLE BOEING FIELD, WA US",42.6,24,30.3,24,1010.6,24,009.7,24,10.0,24,2.3,24,14.0, 21.0,51.1,"",35.1,"",0.00,"G",999.9,"000000"),
],
["STATION","DATE","LATITUDE","LONGITUDE","ELEVATION","NAME","TEMP","TEMP_ATTRIBUTES","DEWP","DEWP_ATTRIBUTES","SLP","SLP_ATTRIBUTES","STP","STP_ATTRIBUTES","VISIB","VISIB_ATTRIBUTES","WDSP","WDSP_ATTRIBUTES","MXSPD","GUST","MAX","MAX_ATTRIBUTES","MIN","MIN_ATTRIBUTES","PRCP","PRCP_ATTRIBUTES","SNDP","FRSHTT"]
)然后更新 test_basic.py,使其包含新测试。您可以将旧测试保留在该文件中。
from jobs.extreme_weather import ExtremeWeather
def test_extract_latest_daily_value(mock_views_df):
ew = ExtremeWeather()
assert ew.findLargest(mock_views_df, "TEMP").TEMP == 44.1然后,在 requirements-dev.txt 文件中添加以下依赖项:
pyspark==3.3.0完成后,目录结构应如下所示:
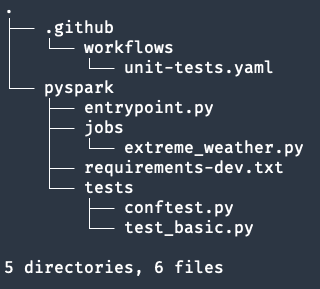
现在,提交代码并推送所做的更改。
git add .
git commit -am "Add pyspark code"
git push我们之前创建的 GitHub 操作会自动运行新的单元测试,并验证分析代码是否能正常运行。
现在,您应该可以在 GitHub UI 中的“Actions”(操作)选项卡上,看到两个单元测试工作流。
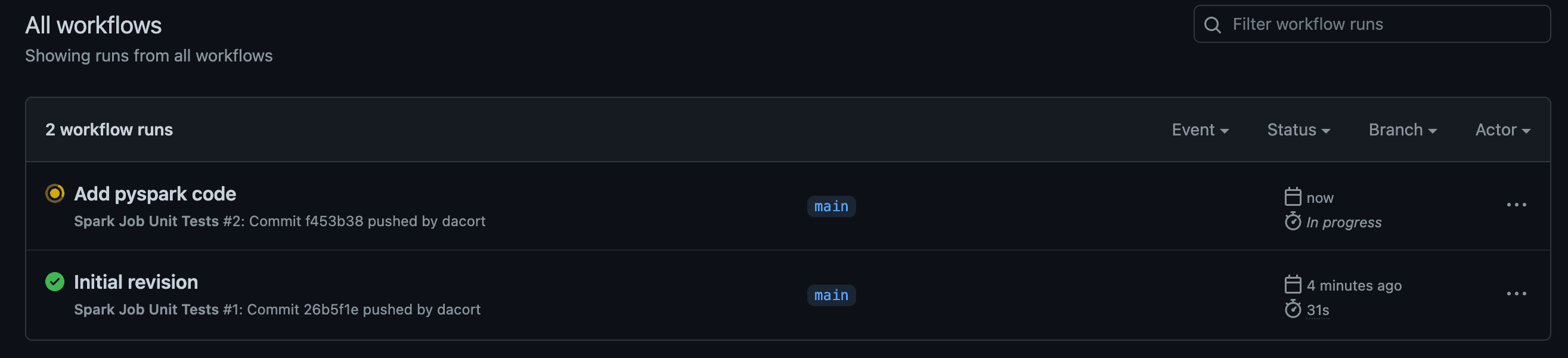
如果您有兴趣,也可以尝试一个额外的操作:故意让测试失败,然后看看代码提交推送失败后会发生什么。
创建拉取请求触发的集成测试
我们已成功创建单元测试。但是,模拟数据仅仅包含实际场景数据中的一小部分,而我们需要捕捉代码库重大更改可能导致的所有错误。
为此,我们将创建一个新的 integration_test.py 文件。将以下代码复制到该文件中。该文件用于对一组已知运行正常的文件进行几次验证。然后,我们将创建一个新的 GitHub 操作。该操作会在代码库收到拉取请求时运行。这有助于验证代码更改是否会实现预期行为。
在 pyspark 目录中,创建一个新的 integration_test.py 文件。
from jobs.extreme_weather import ExtremeWeather
from pyspark.sql import SparkSession
if __name__ == "__main__":
"""
Usage: integration_test
Validation job to ensure everything is working well
"""
spark = (
SparkSession.builder.appName("integration-ExtremeWeather")
.getOrCreate()
)
df = spark.read.csv("s3://noaa-gsod-pds/2022/72793524234.csv", header=True, inferSchema=True)
assert df.count()==365, f"expected 365 records, got: {count}. failing job."
ew = ExtremeWeather()
max_temp = ew.findLargest(df, 'TEMP').TEMP
max_wind_speed = ew.findLargest(df, 'MXSPD').MXSPD
max_wind_gust = ew.findLargest(df, 'GUST').GUST
max_precip = ew.findLargest(df, 'PRCP').PRCP
assert max_temp == 78.7, f"expected max temp of 78.7, got: {max_temp}. failing job."
assert max_wind_speed == 19.0, f"expected max wind speed of 19.0, got: {max_wind_speed}. failing job."
assert max_wind_gust == 36.9, f"expected max wind gust of 36.9, got: {max_wind_gust}. failing job."
assert max_precip == 1.55, f"expected max precip of 1.55, got: {max_precip}. failing job."此外,在 pyspark/scripts 中创建一个 run-job.sh 脚本。该脚本将运行 EMR Serverless 作业并等待其完成。
#!/usr/bin/env bash
set -e
# This script kicks off an EMR Serverless job and waits for it to complete.
# If the job does not run successfully, the script errors out.
APPLICATION_ID=$1
JOB_ROLE_ARN=$2
S3_BUCKET=$3
JOB_VERSION=$4
ENTRY_POINT=$5
SPARK_JOB_PARAMS=(${@:6})
# Convert the passed Spark job params into a JSON array
# WARNING: Assumes there are job params
printf -v SPARK_ARGS '"%s",' "${SPARK_JOB_PARAMS[@]}"
# Start the job
JOB_RUN_ID=$(aws emr-serverless start-job-run \
--name ${ENTRY_POINT} \
--application-id $APPLICATION_ID \
--execution-role-arn $JOB_ROLE_ARN \
--job-driver '{
"sparkSubmit": {
"entryPoint": "s3://'${S3_BUCKET}'/github/pyspark/jobs/'${JOB_VERSION}'/'${ENTRY_POINT}'",
"entryPointArguments": ['${SPARK_ARGS%,}'],
"sparkSubmitParameters": "--py-files s3://'${S3_BUCKET}'/github/pyspark/jobs/'${JOB_VERSION}'/job_files.zip"
}
}' \
--configuration-overrides '{
"monitoringConfiguration": {
"s3MonitoringConfiguration": {
"logUri": "s3://'${S3_BUCKET}'/logs/"
}
}
}' --query 'jobRunId' --output text)
echo "Job submitted: ${APPLICATION_ID}/${JOB_RUN_ID}"
# Wait for it to complete
JOB_STATUS="running"
while [ "$JOB_STATUS" != "SUCCESS" -a "$JOB_STATUS" != "FAILED" ]; do
sleep 30
JOB_STATUS=$(aws emr-serverless get-job-run --application-id $APPLICATION_ID --job-run-id $JOB_RUN_ID --query 'jobRun.state' --output text)
echo "Job ($JOB_RUN_ID) status is: ${JOB_STATUS}"
done
if [ "$JOB_STATUS" = "FAILED" ]; then
ERR_MESSAGE=$(aws emr-serverless get-job-run --application-id $APPLICATION_ID --job-run-id $JOB_RUN_ID --query 'jobRun.stateDetails' --output text)
echo "Job failed: ${ERR_MESSAGE}"
exit 1;
fi
if [ "$JOB_STATUS" = "SUCCESS" ]; then
echo "Job succeeded! Printing application logs:"
echo " s3://${S3_BUCKET}/logs/applications/${APPLICATION_ID}/jobs/${JOB_RUN_ID}/SPARK_DRIVER/stdout.gz"
aws s3 ls s3://${S3_BUCKET}/logs/applications/${APPLICATION_ID}/jobs/${JOB_RUN_ID}/SPARK_DRIVER/stdout.gz \
&& aws s3 cp s3://${S3_BUCKET}/logs/applications/${APPLICATION_ID}/jobs/${JOB_RUN_ID}/SPARK_DRIVER/stdout.gz - | gunzip \
|| echo "No job output"
fi现在,在 .github/workflows 目录中,创建一个新的工作流,用于运行集成测试。创建一个 integration-test.yaml 文件。在这个文件中,将环境变量替换为 CloudFormation 堆栈的对应值。
在 CloudFormation 控制台中,创建堆栈的“Outputs”(输出)选项卡,或者在 Amazon CLI 中运行以下命令查看 CloudFormation 堆栈的相关信息。
# Change "gh-serverless-spark-demo" to the name of the stack you created
aws cloudformation describe-stacks \
--query 'Stacks[?StackName==`gh-serverless-spark-demo`][].Outputs' \
--output text将 APPLICATION_ID、S3_BUCKET_NAME、JOB_ROLE_ARN 和 OIDC_ROLE_ARN 的值替换为您的堆栈信息中的对应值。
name: PySpark Integration Tests
on:
pull_request:
types: [opened, reopened, synchronize]
env:
#### BEGIN: BE SURE TO REPLACE THESE VALUES
APPLICATION_ID: 00f5trm1fv0d3p09
S3_BUCKET_NAME: gh-actions-serverless-spark-123456789012
JOB_ROLE_ARN: arn:aws:iam::123456789012:role/gh-actions-job-execution-role-123456789012
OIDC_ROLE_ARN: arn:aws:iam::123456789012:role/gh-actions-oidc-role-123456789012
#### END: BE SURE TO REPLACE THESE VALUES
AWS_REGION: us-east-1
jobs:
deploy-and-validate:
runs-on: ubuntu-20.04
# id-token permission is needed to interact with GitHub's OIDC Token endpoint.
# contents: read is necessary if your repository is private
permissions:
id-token: write
contents: read
defaults:
run:
working-directory: ./pyspark
steps:
- uses: actions/checkout@v3
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
role-to-assume: ${{ env.OIDC_ROLE_ARN }}
aws-region: ${{ env.AWS_REGION }}
- name: Copy pyspark file to S3
run: |
echo Uploading $GITHUB_SHA to S3
zip -r job_files.zip jobs
aws s3 cp integration_test.py s3://$S3_BUCKET_NAME/github/pyspark/jobs/$GITHUB_SHA/
aws s3 cp job_files.zip s3://$S3_BUCKET_NAME/github/pyspark/jobs/$GITHUB_SHA/
- name: Start pyspark job
run: |
bash scripts/run-job.sh $APPLICATION_ID $JOB_ROLE_ARN $S3_BUCKET_NAME $GITHUB_SHA integration_test.py s3://${S3_BUCKET_NAME}/github/traffic/下面,我们介绍如何根据拉取请求触发集成测试。我们将提交这些更改。方法:创建一个新的分支,将相应的文件推送到该分支中,然后发送一个拉取请求。
当收到提交拉取请求时,integration-test 工作流就会自动运行。
git checkout -b feature/integration-test
git add .
git commit -m "Add integration test"
git push --set-upstream origin feature/integration-test推送代码更改后,前往您的 GitHub 存储库,可以看到一条通知,告诉您新的分支 feature/integration-test 收到了一个最新推送,您可以创建新的拉取请求。

点击 Compare & pull request(比较和拉取请求),激活 integration-test.yaml 集成工作流。点击该按钮后,显示 Open a pull request(打开拉取请求)表单。将它命名为 Add integration test,然后点击 Create pull request(创建拉取请求)。
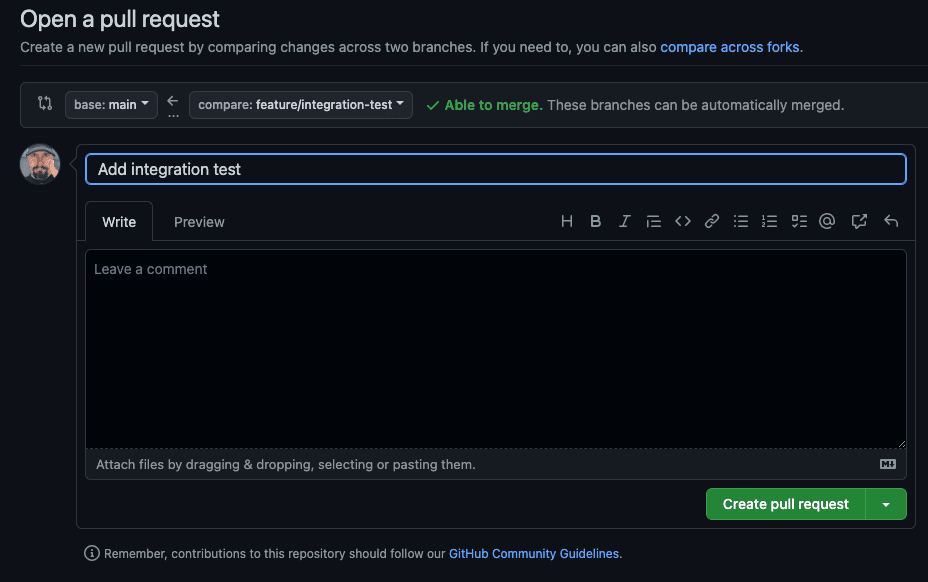
此操作会激活集成工作流。在弹出的页面上,点击 PySpark 集成测试的 Details(详情)链接。
您将看到部署和验证拉取请求工作流的状态。该工作流将运行 scripts/run-job.sh shell 脚本。该脚本会调用您的亚马逊云科技资源,将 Spark 作业推送到您的 EMR Serverless 应用程序中,并运行 integration_test.py 脚本。您可以监控运行进度,能看到作业状态从“PENDING”(待处理)变成“RUNNING”(运行中),然后变成“SUCCESS”(成功)。
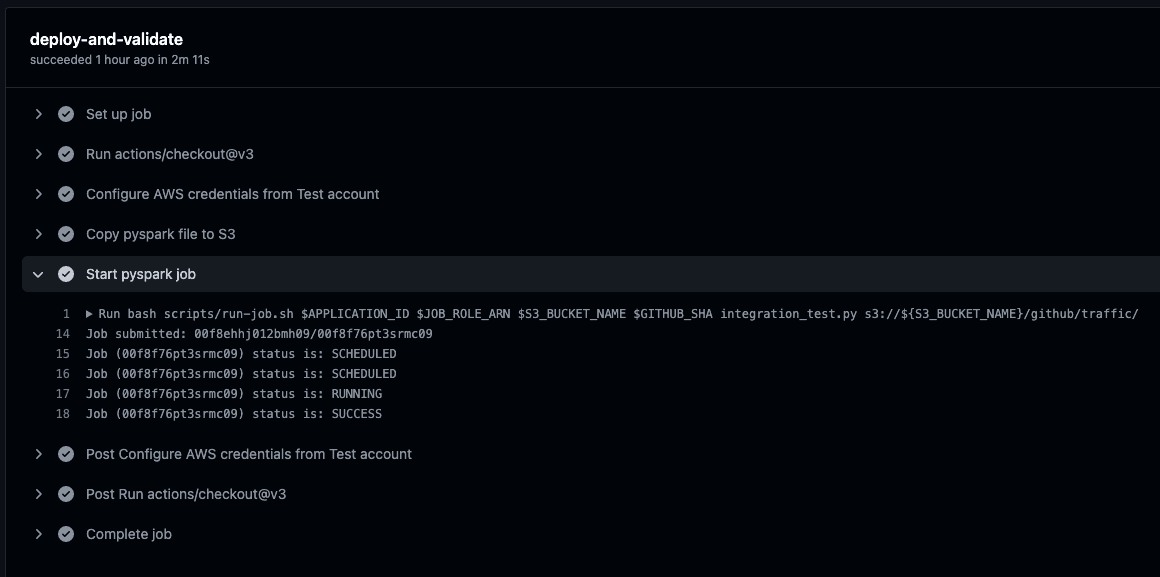
您也可以在 EMR Serverless 控制台上查看作业的状态。
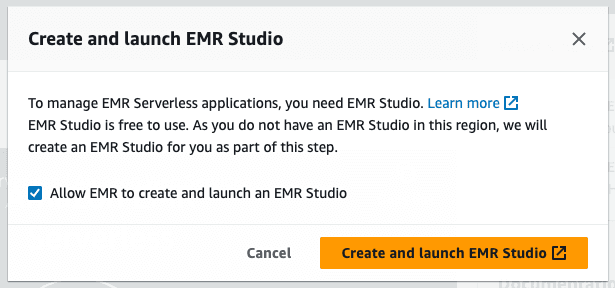
如果您之前没有设置 EMR Studio,请点击 Get started(开始使用)按钮,然后点击 Create and launch EMR Studio(创建并启动 EMR Studio)。
检查完成后,点击拉取请求页面上的 Merge pull request(合并拉取请求)按钮。之后,您的代码库收到任何新的拉取请求时,都会先完成集成测试,然后才合并代码。
在您的台式机/笔记本电脑上的本地存储库中,返回到主分支并执行 git pull。
git checkout main
git pull交付代码
我们已经创建了新存储库并添加了单元测试、集成测试,现在我们将代码交付到生产环境中。为此,我们将创建一个新的 GitHub 操作。该操作会在添加代码库版本标签时运行。如果添加的标签与某个语义化版本(例如 v1.0.2)匹配时,系统自动打包项目并交付到 S3。
注意:实际场景中,我们可以利用不同的环境或账户来隔离生产资源和测试资源。但在本次演示中,我们仅使用一组资源。
理论上讲,只有新代码经过验证并确认可直接交付时,才能添加版本标签。通过此方法,我们可以在准备就绪后轻松运行代码的新版本,或者在必要时回滚至某个较早版本。
我们将创建一个新的 deploy 工作流。该工作流仅在运用版本标签时运行。
在 .github/workflows/deploy.yaml 中创建并提交此工作流文件,并将 S3_BUCKET_NAME 和 OIDC_ROLE_ARN 替换为实际值:
name: Package and Deploy Spark Job
on:
# Only deploy these artifacts when a semantic tag is applied
push:
tags:
- "v*.*.*"
env:
#### BEGIN: BE SURE TO REPLACE THESE VALUES
S3_BUCKET_NAME: gh-actions-serverless-spark-prod-123456789012
OIDC_ROLE_ARN: arn:aws:iam::123456789012:role/gh-actions-oidc-role-123456789012
#### END: BE SURE TO REPLACE THESE VALUES
AWS_REGION: us-east-1
jobs:
deploy:
runs-on: ubuntu-20.04
# These permissions are needed to interact with GitHub's OIDC Token endpoint.
permissions:
id-token: write
contents: read
defaults:
run:
working-directory: ./pyspark
steps:
- uses: actions/checkout@v3
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
role-to-assume: ${{ env.OIDC_ROLE_ARN }}
aws-region: ${{ env.AWS_REGION }}
- name: Copy pyspark file to S3
run: |
echo Uploading ${{github.ref_name}} to S3
zip -r job_files.zip jobs
aws s3 cp entrypoint.py s3://$S3_BUCKET_NAME/github/pyspark/jobs/${{github.ref_name}}/
aws s3 cp job_files.zip s3://$S3_BUCKET_NAME/github/pyspark/jobs/${{github.ref_name}}/git add .
git commit -am "Adding deploy action"
git push接下来,我们将创建一个新发布版本。
- 返回到 GitHub UI,点击右侧的 Releases(发布版本)链接。
- 然后点击 Create a new release(创建发布版本)按钮。
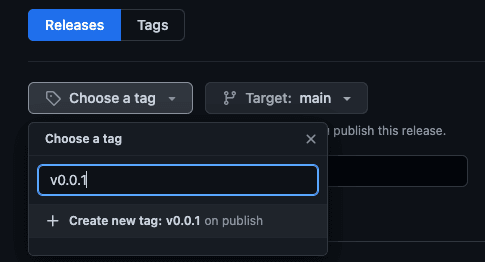
- 点击 Choose a tag(选择标签),然后在 Find or create a new tag(查找标签或创建新标签)字段键入 v0.0.1。
- 然后点击下面的 Create new tag: v0.0.1 on publish(创建新标签:v0.0.1(发布时))。
您也可以填写版本的标题或描述;或者,也可直接点击“Publish release”(发布版本)。
完成此操作后,一个新的版本标签会被添加到存储库,并将触发我们刚刚创建的操作。
返回到存储库的主页面,并点击 Actions(操作)按钮。您应该会看到一个新的 Package and Deploy Spark Job(打包并部署 Spark 作业)操作正在运行。点击该作业,然后点击 deploy(部署)链接,即可看到 GitHub 将您的新代码部署到 S3。

配置作业运行器
最后一步是在生产环境中运行代码。为此,我们将创建一个新的 GitHub 操作。该操作既可以自动运行已部署代码的最新版本,也支持手动指定一组自定义参数来运行同一作业。
创建 .github/workflows/run-job.yaml 文件。请务必替换代码中的环境变量。
name: ETL Job
env:
#### BEGIN: BE SURE TO REPLACE THESE VALUES
APPLICATION_ID: 00f5trm3rnk3hl09
S3_BUCKET_NAME: gh-actions-serverless-spark-123456789012
JOB_ROLE_ARN: arn:aws:iam::123456789012:role/gh-actions-job-execution-role-123456789012
OIDC_ROLE_ARN: arn:aws:iam::123456789012:role/gh-actions-oidc-role-123456789012
#### END: BE SURE TO REPLACE THESE VALUES
AWS_REGION: us-east-1
JOB_VERSION: v0.0.1
on:
schedule:
- cron: "30 2 * * *"
workflow_dispatch:
inputs:
job_version:
description: "What version (git tag) do you want to run?"
required: false
default: latest
jobs:
extreme-weather:
runs-on: ubuntu-20.04
# These permissions are needed to interact with GitHub's OIDC Token endpoint.
permissions:
id-token: write
contents: read
defaults:
run:
working-directory: ./pyspark
steps:
- uses: actions/checkout@v3
- name: Configure AWS credentials from Prod account
uses: aws-actions/configure-aws-credentials@v1
with:
role-to-assume: ${{ env.OIDC_ROLE_ARN }}
aws-region: ${{ env.AWS_REGION }}
- uses: actions-ecosystem/action-get-latest-tag@v1
id: get-latest-tag
if: ${{ github.event.inputs.job_version == 'latest' }}
with:
semver_only: true
- name: Start pyspark job
run: |
echo "running ${{ (steps.get-latest-tag.outputs.tag || github.event.inputs.job_version) || env.JOB_VERSION}} of our job"
bash scripts/run-job.sh $APPLICATION_ID $JOB_ROLE_ARN $S3_BUCKET_NAME ${{ (steps.get-latest-tag.outputs.tag || github.event.inputs.job_version) || env.JOB_VERSION}} entrypoint.py s3://${S3_BUCKET_NAME}/github/traffic/ s3://${S3_BUCKET_NAME}/github/output/views/确认您是否替换了 BEGIN: BE SURE TO REPLACE THESE VALUES 后面的 4 个变量。现有的值只是我当前演示使用的值。但如果您没有替换,我要借此机会提醒您:您可以使用其他账户来运行这个 GitHub 操作,而且该账户的权限可以与您当前使用的账户完全不同。这就是 OIDC 和 CI/CD 工作流的强大之处。
替换变量值后,提交并推送该文件。
git commit -am "Add run job"
git push完成推送后,此操作将在每天凌晨 02:30 UTC运行作业。但是,我们现在要手动触发此操作。
返回到 GitHub UI,点击“Actions”(操作)选项卡,然后点击左侧的 ETL Job(ETL 作业)。点击“Run workflow”(运行工作流)按钮,可以看到我们在上述操作中配置的一些参数。
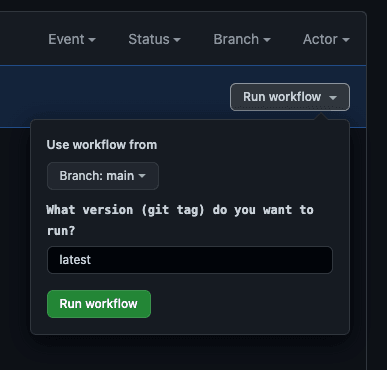
我们可以更改要使用的 git 标签,也可以保留 latest。点击绿色的 Run workflow(运行工作流)按钮,启动 EMR Serverless 作业。
GitHub 操作会启动该作业。等待作业完成,查看输出。
查看输出
该作业会在 stdout 中记录输出日志。如果启用了日志功能,则 EMR Serverless 会将 stdout 驱动写入 S3 上的标准路径。
该作业运行成功,则记录日志时会将作业输出作为 GitHub 操作的一部分。
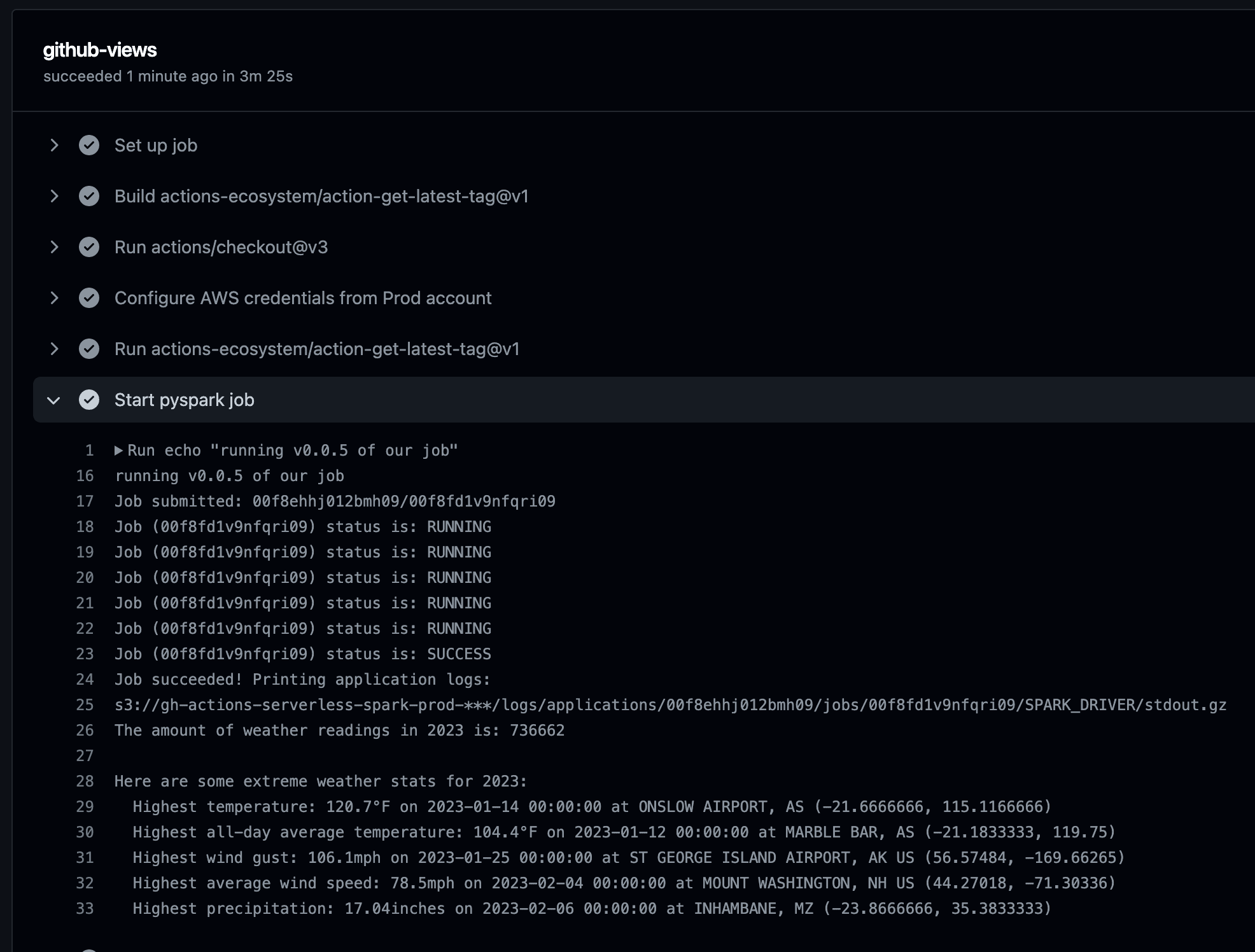
如果您安装了 gunzip,可以使用以下 aws s3 cp 命令查看日志。
将 S3_BUCKET 替换为您的 CloudFormation 堆栈中的存储桶,并将 APPLICATION_ID 和 JOB_RUN_ID 替换为用于获取数据 的 GitHub 操作中的值。
aws s3 cp s3://${S3_BUCKET}/logs/applications/${APPLICATION_ID}/jobs/${JOB_RUN_ID}/SPARK_DRIVER/stdout.gz - | gunzipThe amount of weather readings in 2023 is: 736662
Here are some extreme weather stats for 2023:
Highest temperature: 120.7°F on 2023-01-14 00:00:00 at ONSLOW AIRPORT, AS (-21.6666666, 115.1166666)
Highest all-day average temperature: 104.4°F on 2023-01-12 00:00:00 at MARBLE BAR, AS (-21.1833333, 119.75)
Highest wind gust: 106.1mph on 2023-01-25 00:00:00 at ST GEORGE ISLAND AIRPORT, AK US (56.57484, -169.66265)
Highest average wind speed: 78.5mph on 2023-02-04 00:00:00 at MOUNT WASHINGTON, NH US (44.27018, -71.30336)
Highest precipitation: 17.04inches on 2023-02-06 00:00:00 at INHAMBANE, MZ (-23.8666666, 35.3833333)总结
注意:此 GitHub 操作将会每天运行,由此会产生亚马逊云科技资源使用费用。
实验完成后,请及时在 EMR Serverless 控制台中删除您的 EMR Serverless 应用程序,以免产生额外的费用。如果您不想在定时作业运行失败时收到电子邮件通知,请删除 run-job.yaml GitHub 操作。
rm .github/workflows/run-job.yaml
git commit -am "Removed scheduled job run"
git pushEMR 团队正坚持不懈地努力改进 EMR 的本地 Spark 开发体验。下面列出了另外一些可用资源,可供您参考:

