AWS Storage Blog
Teespring controls its legacy data using Amazon S3
Do you know exactly what’s in all of your Amazon Simple Storage Service (Amazon S3) buckets? Do all of your objects have the correct set of object tags applied? Have you set up lifecycle rules to ensure your current and future objects are managed automatically for you?
If you answered “yes” to all of the previous questions, then this post might not be for you. However, if you have legacy data files in your Amazon S3 buckets, possibly with little structure, inconsistent naming, or a lack of metadata, then definitely keep reading! In this post, I explain how S3 Intelligent-Tiering and S3 Batch Operations can help you regain control of your legacy data. Ultimately, these features can help you reduce your storage costs and give you a clear path towards adopting the latest S3 features for unlocking the value of your oldest data.
The following video is my 15 minute re:Invent 2019 session, where I cover how Teespring uses S3 Intelligent-Tiering and S3 Batch Operations:
Where Teespring started
Teespring connects creators to their fans through commerce. The creators design traditional merchandise, custom limited edition items, and digital goods on the Teespring platform. Their fans buy those goods through partners or directly on our website. The following image shows our homepage, inviting creators to get started on our platform.
A natural part of this process is the generation of merchandise designs and images, and the storage of these digital assets. We need high-resolution previews of the apparel, stickers, coffee mugs, and other goods we manufacture. Moreover, we need even higher-resolution customization assets, which we feed into printers, embroidery machines, die-cutters, and other machinery. This process is outlined in the following diagram, with creators providing designs stored and transmitted through Amazon S3 throughout manufacturing and production.

For any given listing on Teespring, it’s common to need 500+ unique images to enable a great shopping experience for the buyer. These are also needed to deliver precise product customization specifications to a network of internal and external manufacturers.
In the early days of the company, our focus was 100% on developing a working first version of our product – as it should be at any startup. The focus was not on scalability, maintainability, or operational efficiency. Fortunately for Teespring, we saw exponential growth in the number of listings and the number of sales, which came with rising storage costs that had not been optimized. Our engineering team was too busy keeping up with the meteoric increase in the business to revisit our object storage. This led to a situation where we had several petabyte-scale buckets that had little discernable structure, no lifecycle rules, and a seemingly unstoppable monthly increase in our storage costs.
At Teespring, we pride ourselves on allowing anyone, anywhere to launch a new product – with no upfront cost and zero risk. That has made it easy for hundreds of thousands of people to make a profit by launching a product on Teespring. It also means that we had billions of objects sitting in our S3 buckets for products that have never made a sale – and never will. We were wasting vast sums of money every month in retaining those files.
The challenge we faced was two-fold:
- We needed a way to reduce our storage costs across the board.
- We needed a way to retroactively overlay structure onto the objects in our buckets, to aid in their management moving forward.
For challenge No. 1, S3 Intelligent-Tiering was a fantastic solution to help us easily reduce our storage costs across the board without sacrificing performance or availability.
Reducing storage costs with Amazon S3 Intelligent-Tiering
As previously described, the challenge we faced was that we had petabyte-scale buckets containing billions of objects being used at drastically different frequencies. There was no naming scheme or tagging to help us efficiently look through our data and find what we needed (more to come on the topic of tagging later).
S3 Intelligent-Tiering was an incredibly easy solution to be able to realize significant savings on those problematic buckets. Its premise is simple. For a small monitoring and automation fee, S3 Intelligent-Tiering monitors access to each of your objects for you. When your object hasn’t been accessed for 30 consecutive days, it will automatically move it to the lower-cost Infrequent Access Tier, helping you reduce your Amazon S3 bill. If the object gets accessed again, S3 Intelligent-Tiering automatically moves it back to the Frequent Access Tier. There is no performance difference between S3 Intelligent-Tiering’s two access tiers, and there are no retrieval charges when you access your data.
We learned that objects smaller than 128 KB can be stored in S3 Intelligent-Tiering, but they’re not eligible for auto-tiering to the Infrequent Access tier. I’d recommend trying to leave those objects in S3 Standard, because with S3 Intelligent-Tiering you pay an additional monitoring and automation fee on all objects, regardless of size.
The 30-day window I previously mentioned isn’t configurable, and more nuanced functionality like moving objects to Amazon S3 Glacier after a longer dormant period isn’t yet available. Maybe this could come in the future; consider this a feature request, S3 team! However, in exchange for rigidity you receive jaw-dropping simplicity and ease of implementation. For us, it was as simple as creating a S3 Lifecycle rule for an entire bucket that transitioned all the existing objects to S3 Intelligent-Tiering. This was a feasible solution for us because only a very small percentage of our objects are smaller than 128 KB, so we found it easier to move our entire bucket to S3 Intelligent-Tiering.

After a day or two, we could see all the objects move into the S3 Intelligent-Tiering storage class. Then, 30 days later, we began to realize savings of over 40% on the less-accessed objects, and we could even see which objects were in what Access Tier in the S3 Inventory report.
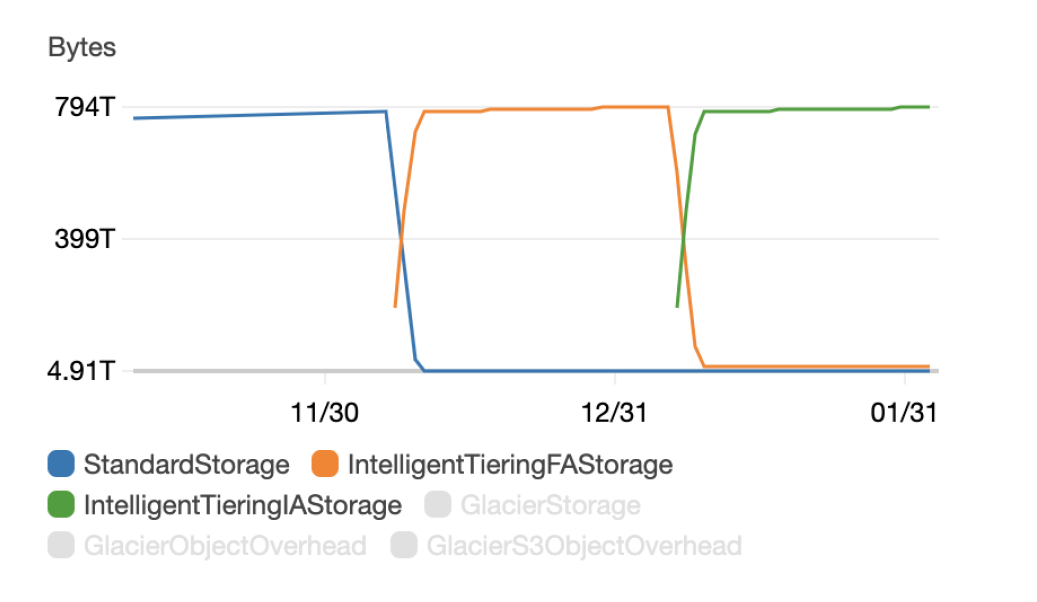
The chart above shows what happened after we moved our objects from the S3 Standard storage class to the S3 Intelligent-Tiering storage class:
- The blue StandardStorage line shows that after creating this lifecycle rule, no objects were left in that default storage class.
- The orange IntelligentTieringFAStorage line is our storage in the S3 Intelligent-Tiering Frequent Access Tier. As you can see, all newly managed objects were placed in this tier initially, then most objects were automatically moved to the Infrequent Access class after not being accessed for 30 days.
- Finally, the green IntelligentTieringIAStorage line shows that after 30 days, 98% of the objects in this particular bucket hadn’t been accessed. Those objects were moved to the S3 Intelligent-Tiering Infrequent Access Tier.
For objects that ended up in the Infrequent Access tier – the majority in our case – we welcomed savings of over 40% in storage costs, with no additional retrieval costs.
My recommendation would be to consider S3 Intelligent-Tiering if:
- You have a workload with unknown or changing access patterns
- You want an easy and automatic way to save on your Amazon S3 bill
- You need the same low latency and high throughput performance as S3 Standard
If all of the above are true, you should use S3 Intelligent-Tiering!
| “We began to realize savings of over 40% on the less-accessed objects, and we could even see which objects were in what Access Tier in the S3 Inventory report” |
For challenge No. 2, S3 Batch Operations was perfect to help us add structure to our objects and manage them going forward.
Further reducing costs with Amazon S3 Batch Operations
The main appeal of S3 Intelligent-Tiering for us was the ease of implementation. Once you have confirmed that it fits your particular use case, it takes just a few minutes to set up a lifecycle rule. Thirty days later, you are saving money. However, although the objects were costing us less now, they were still almost impossible to manage. We had a jumble of old and new objects sitting next to each other with no way to determine their utility, and no way to archive them effectively. In order to truly regain control of our legacy data, we needed a way to attach metadata to the various objects as tags.
S3 Batch Operations: Bring your business domain into your buckets
One example of where we wanted to attach metadata to our assets in S3 was in the case that an asset violated our terms of service.
As Teespring is a platform for user-generated content, we unfortunately sometimes have bad actors who try to use copyrighted content – or even hate speech – in their products. We have many overlapping systems in place to scan for unacceptable content (the Swiss cheese model is something we refer back to often). However, when we remove infringing content from our platform, rather than deleting the assets we want to preserve them for two reasons:
- If a legal claim is later made, it’s key that we have access to the specific images shown on our site.
- We are experimenting with the Amazon Machine Learning (Amazon ML) products to train a model for spotting infringing content – another slice of Swiss cheese to add to our technology stack. Having a training set of problematic images to feed into the model greatly improves its accuracy for our domain.
Therefore, in plain English we want to do something like this:
- If a listing has been suspended for content violations, then:
- Delete all the manufacturing customization assets for that listing (these aren’t public, so we don’t need to preserve them for legal reasons).
- Transition the primary thumbnail for the listing to the S3 One Zone-Infrequent Access (S3 One Zone-IA) storage class. We show this preview internally in our admin system so we want to preserve it.
- Transition all the other assets to the S3 Glacier storage class.
It’s not too complex to implement these rules for content going forward, but how can we retroactively apply them for 8 years of historical content?
We needed a way to act within S3 at a massive scale, based on logic and data that only exists in our codebases and databases. We needed to bring our business domain into our S3 buckets – this is where S3 Batch Operations came in. S3 Batch Operations makes it simple to manage billions of objects stored in Amazon S3 with a single API request or a few clicks in the S3 Management Console.
Using S3 Batch Operations to tag objects
They key insight for us was that all the necessary information to decide to delete, archive, or preserve assets was already present in our Amazon Redshift data warehouse.
The data warehouse knew which listings had been suspended, and it knew about the assets associated with those listings. Therefore, with a few simple SQL scripts, we could generate manifest CSVs indicating “these are the manufacturing assets for suspended listings,” and so on. With these manifest files, we could use the Object Tagging operation to attach metadata to the assets in S3. We decided to use tags that spoke to the attributes of the object, rather than the action we wanted to take. For example, we added tags like created: 2018_jan, purpose: preview, and listing_status: suspended, rather than action: archive. Taking this approach allows you to be more precise when writing lifecycle rules, and gives you useful structure for other operations in the future.
During the preview period for S3 Batch Operations, we used command line tools and hand-written payloads to create S3 Batch Operations Jobs. Now, there are tools in the AWS Management Console. The following screenshot shows us selecting our Region and filling out our Manifest.

In the next screenshot of the AWS Management Console, we choose our Operation type and fill out our Replace all object tag settings.

Deleting and transitioning objects with S3 Batch Operations
S3 Batch Operations actually doesn’t allow for deleting or transitioning objects between storage classes as a native operation. However, this is no problem – combining the object tagging described above with lifecycle rules was plenty powerful for us. If you really do need completely custom actions to be taken on the objects, you do have the option of invoking a Lambda function.
This chart shows the result of one of these S3 Batch Operations:
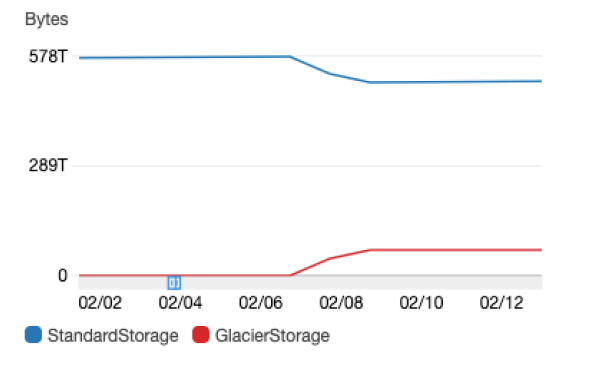
For this bucket, about 12% of the storage (and consequently, our cost) went towards these assets, which are only useful as a training set for an ML model.
Conclusion
Legacy data is hard to deal with. Harder than legacy code and tech debt, in my experience. It’s also something that every successful company has to deal with in one way or another. Countless books have been written about refactoring approaches for tech debt, but there’s no playbook for re-asserting control over terabytes and petabytes of unstructured files. Unfortunately, I don’t think such a playbook exists because the approaches you must take to manage legacy data are intimately tied to the specifics of your business.
In this blog post, I gave an overview and some examples of how easy-to-implement solutions like S3 Intelligent-Tiering can have an outsized impact. In addition, I showed how S3 Batch Operations was a shining beacon of hope when we were tackling our legacy data. It enables you to overlay logic and data from your business domain onto your files sitting in S3. It therefore represents an invaluable general-purpose tool to structure, understand, and ultimately manage those objects.
For more information, see S3’s Intelligent-Tiering storage class and the Batch Operations user guide. If you’d like a complementary take on this topic, watch our re:Invent session. In that session I explain that “data debt,” like tech debt, is something early-stage companies should be comfortable taking on. This is especially true as more tools become available to pay it down later on.
Thanks for reading about Teespring and how we use AWS services to optimize our business. Please leave a comment if you have any questions, and the AWS team will make sure they get to us!
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.