AWS Storage Blog
How AppsFlyer reduced its data lake cost with Amazon S3 Intelligent-Tiering
Many customers use Amazon S3 as the storage foundation of their data lake solution. A data lake is a centralized repository for raw and transformed data for real-time analytics, machine learning, business intelligence, and more. As new data is continuously generated and stored for long periods of time, data lakes on Amazon S3 enable you to securely migrate, store, manage, and analyze all structured and unstructured data at unlimited scale. At the same time, cost control and cost optimization are essential. To control storage cost, customers define data retention policies aimed to archive or discard unused data.
A common practice is transitioning data that is less frequently accessed (“colder” data) to a more cost-effective storage class. An example of such storage class is S3 Standard-Infrequent Access (S3 Standard-IA). S3 Standard-IA is for data that is accessed less frequently, but requires rapid access when needed. S3 Standard-IA offers the high durability, high throughput, and low latency of S3 Standard, with a low per GB storage price and per GB retrieval fee. S3 Standard-IA is a great option when data access patterns are predictable. It enables customers to use S3 Lifecycle policies to automatically transition objects between storage classes without any application changes, and benefit from reduced storage costs. However, customers often have long-lived data with access patterns that are unknown or unpredictable, and this is the challenge that AppsFlyer faced with their data lake built on Amazon S3.
In this blog post, I outline the tools and methods that AppsFlyer used to analyze storage costs and data access patterns. I also review how AppsFlyer decided to leverage Amazon S3 Intelligent-Tiering to achieve 18% cost per GB reduction in their storage costs.
About AppsFlyer
AppsFlyer is a leading mobile advertising attribution and marketing analytics platform. AppsFlyer empowers marketers to grow their mobile business and innovate with a suite of comprehensive measurement and analytics solutions. Today, 12,000 brands across the globe measure and optimize their marketing campaigns and trust AppsFlyer to guide their most strategic business and marketing decisions. AppsFlyer delivers the highest reliability at scale based on 9.7 billion devices cataloged, achieving 99.9% platform uptime. Over 100 billion events are ingested every day. All events are processed in real time to create mobile attribution, and stored persistently in a petabyte scale data lake in Apache Parquet format. The data is batch processed on an hourly and daily cadence. AppsFlyer uses Apache Spark clusters running daily on over 12,000 Amazon EC2 Spot Instances. The clusters are used to create customer attribution reports, run machine learning models to detect fraudulent activity, and process General Data Protection Regulation (GDPR) and California Consumer Privacy Act (CCPA) requests.
AppsFlyer was founded in 2011 and has been using Amazon S3 since 2012. The AppsFlyer data lake size is 15 petabytes, with 25 terabytes of new data added daily (more about AppsFlyer’s data lake in AWS re:Invent 2019: Implementing a data lake on Amazon S3 ft. AppsFlyer).
What is the GDPR?
The GDPR is a regulation in EU law on data protection and privacy in the European Union (EU) and the European Economic Area (EEA). The GDPR aims primarily to give control to individuals over their personal data and to simplify the regulatory environment for international business by unifying the regulation within the EU. In the GDPR there are three types of personas:
- Data Subjects: mobile end users in this case.
- Data Controllers: mobile apps owners or advertisers.
- Data Processors: AppsFlyer and their sub-processors that have to implement the policies promised to the Data Subjects by Data Controllers.
Every month AppsFlyer receives hundreds of thousands of GDPR requests from Data Controllers to remove user’s personal data. This is also known as “the right to be forgotten.”
Gilad Katz, AppsFlyer’s VP of R&D: “We were very eager on supporting GDPR in a very good manner. We did not know what to expect, as we are a processor and not a controller, and we figured out it’s going to be hundreds of requests per month for deletion of user’s data. Eventually it was hundreds of thousands, and still growing.”
Analyzing storage cost
To manage Amazon S3 objects so that they are stored cost effectively throughout their lifecycle, AppsFlyer used S3 Lifecycle to transition data from S3 Standard to S3 Standard-IA after 30 days. After the GDPR laws went into place, AppsFlyer experienced an increase in storage costs. To identify the root cause of the cost increase, AppsFlyer used AWS Cost Explorer, a tool that lets you visualize, understand, and manage your AWS costs and usage over time. The first step AppsFlyer took was to filter the data by Service (S3) and Group by (Usage Type) – as shown in the following screenshot. This view helped them identify an increase in the Retrieval-SIA usage type.

The second step was to associate the Retrieval-SIA cost with the resource that generated it. Amazon S3 support tagging S3 buckets with cost allocation tags. AppsFlyer, which follows a rigorous tagging strategy, leveraged this capability and tagged each S3 bucket with a ‘Component’ tag that had the bucket name as its value. As of today, AWS Cost Explorer does not show S3 resource IDs (bucket names). Instead, by using the ‘Component’ tag, AppsFlyer is able to see the actual cost per bucket in AWS Cost Explorer. Without these tags, AppsFlyer would need to run an additional processes and query an AWS Cost & Usage Report, perhaps using Amazon Athena, to achieve the same granularity. AppsFlyer filtered the data by Usage Type: Retrieval-SIA and Group by: Tag=component, and got the answer they were looking for: the data lake bucket was the resource.
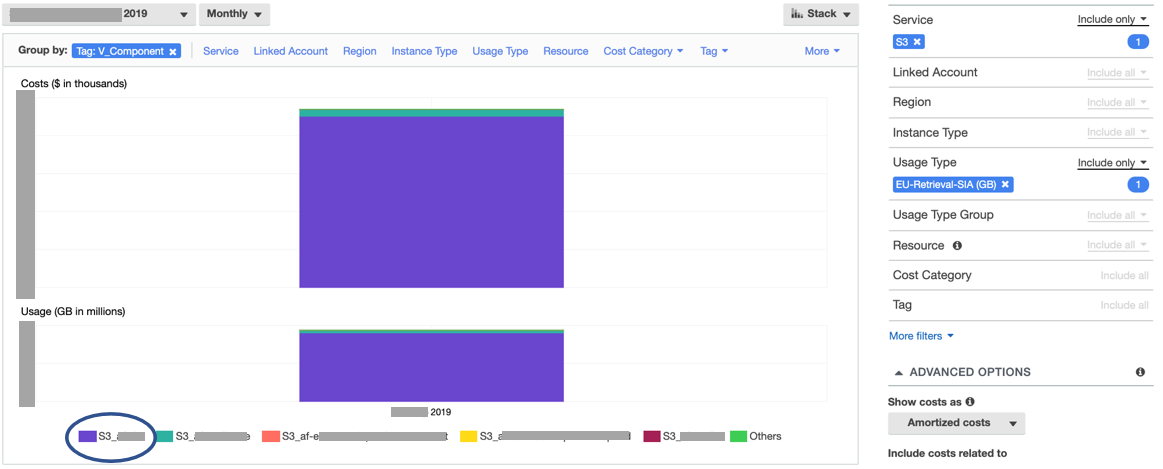
Next, AppsFlyer wanted to analyze the access pattern in the data lake and find ways to optimize storage costs.
Analyzing access patterns
To process users’ requests “to be forgotten,” AppsFlyer must first locate the relevant Parquet object, which includes the personal data of that specific user. Then AppsFlyer deletes it using Apache Spark and writes the ‘clean’ artifacts back to the data lake.
Users’ personal data can reside in Parquet objects of any age. This means that all of the objects in the data lake can now be part of the GDPR process. The good old predictable access pattern, where objects get ‘colder’ after 30 days, became unpredictable and no longer efficient. ‘Colder’ data, stored in S3 Standard-IA and rarely accessed, suddenly became ‘hotter,’ and incurred retrieval fees when accessed. Since every retrieval (even of the same object) is charged a retrieval fee, there is no price capping, and the more objects are accessed the higher the cost gets.
AppsFlyer used Amazon S3 storage class analysis to analyze and visualize storage class access patterns. S3 storage class analysis is a feature that can be quickly enabled on any group of objects (based on prefix or object tagging) to automatically analyze storage access patterns. It helps make the decision of when to transition the right data to the right storage class.
The following is a screenshot of AppsFlyer’s data lake’s storage analytics dashboard:

There were two important insights in AppsFlyer’s analytics dashboard:
- Many petabytes of data are retrieved from S3 Standard-IA (the areas in purple).
- The Observed usage pattern (circled) that “most objects older than 365 days are infrequently accessed” confirmed that objects were being accessed more frequently, for longer than previously assumed 30 days.
Optimizing data lake cost with S3 Intelligent-Tiering
After reviewing the Amazon S3 storage class analysis results, AppsFlyer considered next steps to optimize their storage to lower costs. First, AppsFlyer considered updating the existing S3 Lifecycle rule to transition data to S3 Standard-IA after 365 days, instead of 30 days. Then they decided that doing so would not be efficient because storage cost would increase significantly. AppsFlyer had little insight when it came to whether objects older than 365 days would be accessed frequently again in the future, and thereby incur unexpected retrieval fees. AppsFlyer needed a different solution and found it in S3 Intelligent-Tiering.
S3 Intelligent-Tiering storage class gives customers a way to save money even under changing access patterns, with no performance impact, no operational overhead, and no retrieval fees. It works by storing objects in two access tiers: one tier that is optimized for frequent access and another lower-cost tier that is optimized for infrequent access. For a small monthly monitoring and automation fee per object, Amazon S3 monitors access patterns of the objects in S3 Intelligent-Tiering. S3 Intelligent-Tiering moves objects that have not been accessed for 30 consecutive days to the infrequent access tier. If an object in the infrequent access tier is accessed, it is automatically moved back to the frequent access tier for 30 days.
As there is no retrieval fee in S3 Intelligent-Tiering, this storage class limits the cost. No matter how frequently objects are accessed, the maximum cost for a customer is for the data stored in the frequent access storage tier. In comparison, in S3 Standard-IA, there is an object retrieval cost.
Other considerations
Before transitioning the data to S3 Intelligent-Tiering, AppsFlyer considered the following:
- Monitoring and automation fee
S3 Intelligent-Tiering has a small monthly monitoring and automation fee per object. This means that S3 Intelligent-Tiering becomes more economical as object size grow. AppsFlyer calculated the expected charge by looking for the number of objects in the data lake bucket using the NumberOfObjects CloudWatch metric and multiplying it by the monitoring and automation fee. For example, the monthly monitoring and automation fee for 1000 objects is $0.0025, so for a data lake with 50 million objects, the monthly charge is $125 (refer to Amazon S3 pricing page for up-to-date pricing).
- Object size
Objects smaller than 128 KB are not eligible for auto-tiering and are always stored at frequent access tier rates. AppsFlyer verified using Amazon S3 Inventory that objects in their data lake are bigger than 128 KB. Amazon S3 Inventory provides comma-separated values (CSV), Apache optimized row columnar (ORC), or Apache Parquet (Parquet) output files. These files list objects and their corresponding metadata on a daily or weekly basis for an S3 bucket or a shared prefix.
- Return on investment
All objects uploaded or transitioned to S3 Intelligent-Tiering are automatically stored in the frequent access tier and monitored for 30 days. Objects that have not been accessed for 30 consecutive days are moved to the cheaper infrequent access tier. Since AppsFlyer transitioned a few petabytes from S3 Standard-IA to S3 Intelligent-Tiering, AppsFlyer expected a temporary cost increase for 30 days. As AppsFlyer planned for long-term savings by transitioning their data lake to S3 Intelligent-Tiering, they estimated that the temporary cost increase would be balanced after 2-3 months by the expected savings they would achieve through the elimination of the retrieval fees.
- One-time transition fee
Lifecycle transition requests come with a small fee. AppsFlyer calculated the expected transition cost by multiplying the number of objects in the bucket with the lifecycle transition rate. For example, the cost for lifecycle transition requests is $0.01 per 1000 requests, so the cost to transition 50 million objects from S3 Standard-IA to S3 Intelligent-Tiering is $500 (refer to Amazon S3 pricing page for up-to-date pricing).
- Minimum storage duration
S3 Intelligent-Tiering has a minimum storage duration of 30 days. This was an important factor to consider, because new objects written to AppsFlyer’s data lake can be modified (they can be deleted and re-written) in the first few days after creation. So, to avoid early delete fees, AppsFlyer chose to use an S3 Lifecycle rule to transition new data to S3 Intelligent-Tiering after 8 days, instead of writing new data directly to S3 Intelligent-Tiering or transitioning it earlier.
- Bucket versioning
AppsFlyer’s data lake bucket is using versioning. AppsFlyer took this into consideration and defined different behaviors for ‘current’ and ‘noncurrent’ object versions. As mentioned previously, the current version transitioned after 8 days. In addition, the previous versions were not transitioned at all because AppsFlyer’s policy was to expired previous versions after a few days.
- Service level agreement (SLA)
SLAs are important for AppsFlyer. S3 Intelligent-Tiering objects are backed by the Amazon S3 service level agreement. S3 Intelligent-Tiering and S3 Standard-IA storage class are designed for 99.9% availability and 99.999999999% durability, with an SLA that provides for 99.0% availability. S3 Standard storage class is designed for 99.99% availability and 99.999999999% durability, with an SLA that provides for 99.9% availability.
- Monitoring S3 Intelligent-Tiering objects
AppsFlyer wanted to verify that they are able to analyze their S3 Intelligent-Tiering patterns. For this purpose, AppsFlyer planned to use Amazon S3 Inventory to view the access tier of their S3 Intelligent-Tiering objects.
Conclusion
In this blog post, I discussed how AppsFlyer adopted a new storage cost optimization strategy after data access patterns changed and became unpredictable. AppsFlyer used tools like AWS Cost Explorer, Amazon S3 storage class analysis, and Amazon S3 Inventory reports to dive deep into their storage cost and access patterns. AppsFlyer was able to take an informed decision to transition data to S3 Intelligent-Tiering that yielded a cost reduction of 18% per GB stored. Reducing cost is important for AppsFlyer as it helps increase revenue and allows AppsFlyer to invest in new workloads.
In their own words:
• Reshef Mann, AppsFlyer’s CTO and Co-Founder: “S3 Intelligent-Tiering allows us to make better use and be more cost efficient whenever we have to go to historical data and make changes on top of it.”
• Gilad Katz, AppsFlyer’s VP of R&D: “Amazon S3 enable us to grow fast and assure that we serve our clients in the best manner possible.”
Thanks for reading about AppsFlyer’s AWS Cloud journey, if you have any comments or questions, please leave them in the comments section.