AWS Storage Blog
Bristol Myers Squibb increases performance and cost savings using AWS Storage Gateway
As covered in my previous post on the AWS Storage Blog, Bristol Myers Squibb relies on many AWS storage services to manage its petabyte scale data in various life science workflows. Genomics and clinical data is growing at an exponential pace, and it is important to have reliable, scalable, and secure services handling our data. For that reason, AWS storage services like Amazon Simple Storage Service (Amazon S3), Amazon Elastic Block Store (Amazon EBS), and AWS Storage Gateway play central roles in our organization.
As previously mentioned, one of the key reasons Amazon S3 has become so successful and widely adopted at Bristol Myers Squibb is AWS’s focus on access management and security. That focus helps our organization keep millions of files well protected from unauthorized users, yet we can still share them with multiple legitimate applications and teams. We can maintain data encryption in a transparent fashion for authorized parties along the way.
My goal for this blog is to share some architectural and technical aspects of a couple of AWS storage services. Our knowledge on these services is based on the learnings we gained from playing around with many Amazon S3 and AWS Storage Gateway implementations, researching the cost-reduction opportunities, and exploring different functionalities and architectures. We have deployed Storage Gateways as EC2 instances and as hardware appliances in our environment when we needed low latency access to storage for on-premises applications. In this blog post, I focus on Storage Gateway performance in various EC2 configurations, and I suggest some potential cost optimizations applicable to this great AWS service. We deploy Storage Gateway in EC2 when we are going to have in-cloud applications interacting with Storage Gateway and we know on-premises requirements for access to the data.
Storage Gateway testing environment
For many use cases at Bristol Myers Squibb, we rely on AWS Storage Gateway’s File Gateway as the main engine for raw data transfer from scientific instruments to S3 cloud storage. The data resides and is processed in Amazon S3 where other applications in AWS can be accessed across multiple Regions. Upon testing AWS Storage Gateway in our testing environment, we found ways to be cost-effective and highly performant.
For certain use cases, AWS recommends provisioned Amazon EBS volumes (io1 type) with higher IOPs for virtual Storage Gateway, but we used general-purpose gp2-based storage and saw great savings for datasets with smaller files. For data streams with medium and larger sized files, io1 shows great results.
Before I demonstrate this, let me say a few words about our testing environment. It consists of two identical Storage Gateways: sgw-Alpha and sgw-Beta. Each is organized on top of c5.4xlarge Amazon EC2 instances, as suggested by AWS recommendations. We deploy File Gateways to provide on premises applications with file based, low-latency cached access to S3 storage for our most recently used data. The only difference between these two gateways is storage. While sgw-Alpha is equipped with an 80-GB EBS root disk (io1, 4,000 Provisioned IOPS) and a 512-GiB EBS cache disk (io1, 1,500 IOPS), sgw-Beta features the same size General Purpose SSD disks (gp2) instead.
Once both Storage Gateways become fully configured and launched, our next step is creating NFS file shares. Provide the names for two Amazon S3 buckets for gateways sgw-Alpha and sgw-Beta, to store your files in and retrieve your files to. Let’s call them s3-Alpha and s3-Beta correspondingly. If needed to reflect your organization’s requirements, you can change the configuration settings for your NFS file shares, just make sure that both file shares are identical.
And as the last step in our test preparation, you mount these file shares on your client. In our case, this was a regular (non-dedicated) c5.large Amazon EC2 instance, using a command like the following one (for Linux) or any other as described in the AWS document Mounting Your NFS File Share on Your Client.
sudo mount -t nfs -o nolock,hard [Your gateway VM IP address]:/[S3 bucket name] [mount path on your client]
Following the naming conventions above, we mount these file shares on the testing c5.large EC2 instance as sgw-alpha-io1 and sgw-beta-gp2, which would quickly reveal the main differences between them. Here is what we have so far:

Now we’re fully ready to stress-test our new Storage Gateway playground. As usual, I have to lay out this important disclaimer first: this is not a scientific test. This is the case primarily because we are engaging a shared, not-dedicated, cloud host environment and simulated datasets. Moreover, a few other factors beyond our control might contribute to these results.
Hypothesis on cost savings using Storage Gateway
Our hypothesis states that one can achieve significant savings on Storage Gateway by building it with regular gp2-based EBS storage for datasets primarily consisting of small-sized files. We used the AWS Simple Monthly Calculator to calculate our savings based on the Bristol Myers Squibb environment. Savings may be different for other organizations based on their specific environment and services they deploy. We saw approximately 40% in cost savings based on the calculator (assuming that S3 costs, Storage Gateway costs, and data transfer rates remain the same):
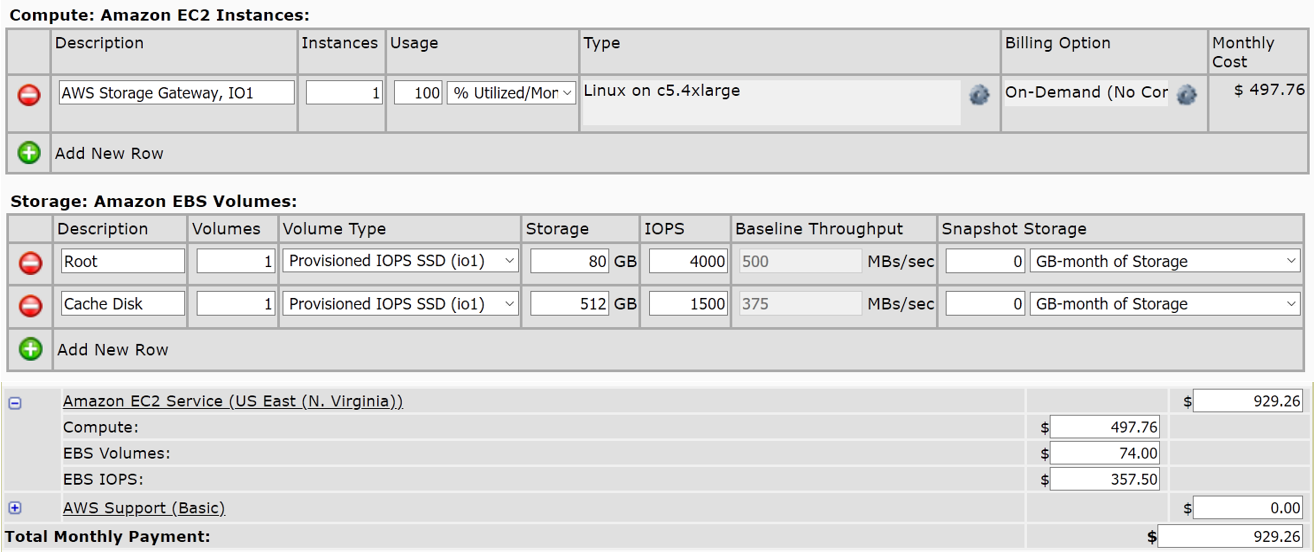
As you can see, the monthly cost of c5.4xlarge io1-storage based AWS Storage Gateway instance alone (EC2 instance only) is around $930. However, the same EC2 instance with gp2-based storage could cost only $557, which translates to nearly 40% in savings:

These savings are significant, especially if you convert these savings to per annum. However, can we be assured that Storage Gateway performance wouldn’t worsen at the same time? Our measurements show no significant performance degradation on small files, in fact it is nearly the same.
Storage Gateway sequential I/O performance
To find out simple sequential I/O performance of Storage Gateway file shares, measuring server latency we used these Linux commands:
dd if=/dev/zero of=/sgw-beta-gp2/test bs=1048576 count=1000 oflag=dsync dd if=/dev/zero of=/sgw-apha-io1/test bs=1048576 count=1000 oflag=dsync
In this example, 1-MB files were written 1000 times to gp2-based and io1-based file shares respectively. Notice we use [oflag=dsync] key to force synchronized I/O and get rid of OS caching to receive good and reliable results. Overall, 12 tests have been conducted for each file share to overcome possible deviations due to the AWS cloud environment (Table 1 and Chart 1):
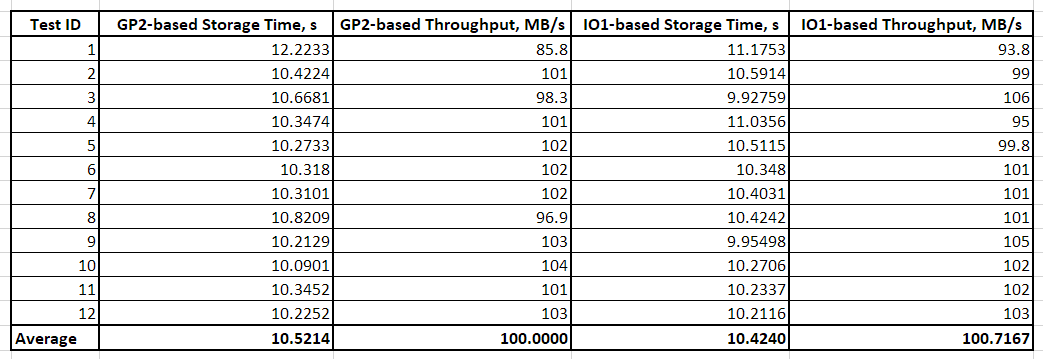
Table 1: Results of AWS Storage Gateway latency tests with sequential I/O on 1-MB files (dd Linux tool)
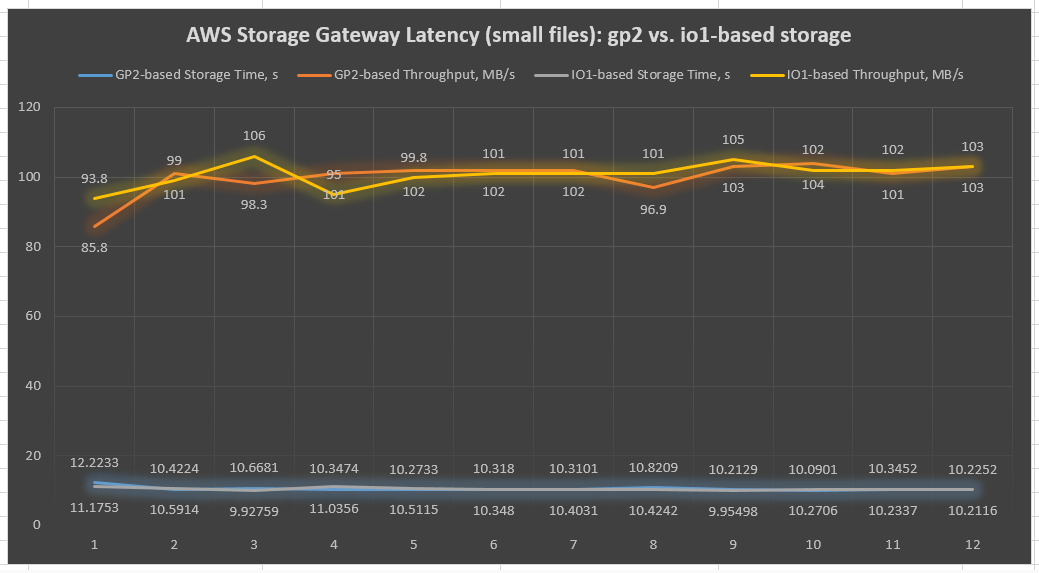
Chart 1: AWS Storage Gateway latency chart of sequential I/O on 1-MB file tests (dd Linux tool)
As you can see in the preceding chart, io1- and gp2-based throughputs of both Storage Gateways remain almost identical. This suggests that for small files, IOPS provisioned storage isn’t that critical. However, keep in mind that a single Storage Gateway may maintain up to 10 different file shares. These can potentially, while working in parallel, lead to significant performance differences in io1- and gp2-based Storage Gateway file shares due to the cache involvement.
The same tests with medium-sized files (1 GB) resulted in a higher surplus of io1-based Storage Gateway file shares (Table 2 and Chart 2). This trend continues on even larger files, 3–5 GB in size, making io1-based Storage Gateway the obvious winner for data streams primarily consisting of large files. This is clearly visible in the following chart:
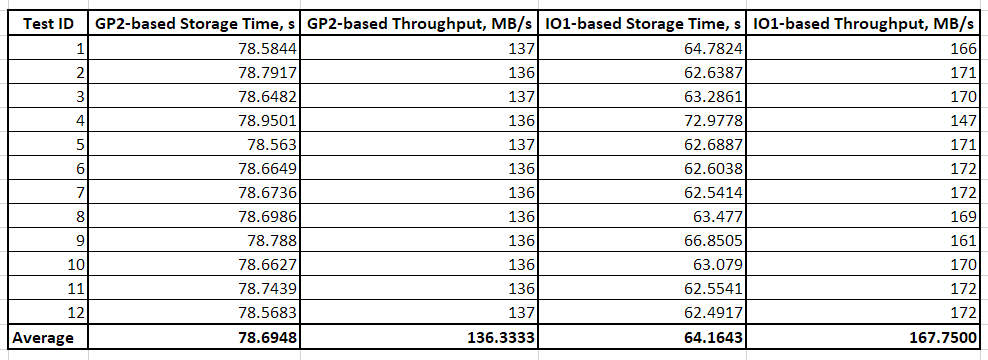
Table 2: Results of AWS Storage Gateway latency tests with sequential I/O on 1-GB files (dd Linux tool)
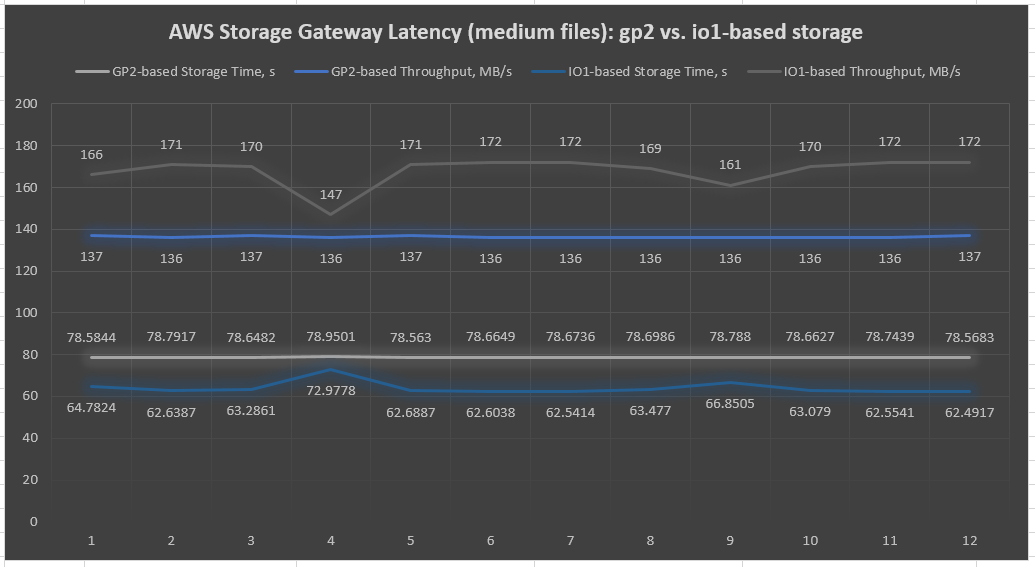
Chart 2: AWS Storage Gateway latency chart of sequential I/O on 1-GB file tests (dd Linux tool)
Another thing to note is that io2 performance stays consistent and does not degrade over time.
Storage Gateway asynchronous I/O performance
Many scientific instruments read/write data asynchronously through multiple threads and it might be essential for us to demonstrate how Storage Gateway performs under such conditions. Before we simulate this activity, the Flexible I/O Tester (Fio) tool must be installed on our testing EC2 instance. Fio spawns a number of threads doing a particular type of I/O action, as specified by the user. It comes with many interesting parameters, allowing us to implement even complex testing scenarios on various I/O patterns. Linux Fio’s installation process is straightforward and can be done with this single command:
sudo yum install fio -y
Now we can mimic scientific instrument behavior by creating four active threads. Each thread is asynchronously writing to or reading from two dedicated 4-GB files placed within our Storage Gateway file shares. Let’s submit these jobs in our test EC2 instance using the following Linux commands:
Job executed against gp2-based Storage Gateway file share:
fio --ioengine=libaio --name=sgw-test-gp2 --directory=/sgw-beta-gp2/ --bs=4k --iodepth=4 --numjobs=4 --size=8G --readwrite=randrw --rwmixread=25 --nrfiles=2
Job executed against iop1-based Storage Gateway file share:
fio --ioengine=libaio --name=sgw-test-io1 --directory=/sgw-alpha-io1/ --bs=4k --iodepth=4 --numjobs=4 --size=8G --readwrite=randrw --rwmixread=25 --nrfiles=2
Here various command line options define the following:
--ioengine– job’s I/O engine (Linux native asynchronous I/O in that particular case);--directory– target file device/directory--bs– block size in bytes used for I/O units (4 KB in our case)--iodepth– number of I/O units to keep in flight against the file (4)--numjobs– number of parallel jobs (4)--size– total size of test files per jobs (8 GB divided by number of files per job –nrfiles=2 gives us 4-GB files)--readwrite– defines random writes--rwmixread– gives percentage of a mixed workload that should be reads (25% for reads, 75% for writes in our case)
It takes around 3 hours to complete each job on our c5.large test Amazon EC2 instance. Interpreting Fio output is not an easy task, as this tool generates a large volume of output. To simplify things, we pay attention to group statistics only, mostly focusing on the [aggrb] result figure, which represents aggregated bandwidth of threads in the entire jobs group. Still, let me briefly highlight Fio’s result group statistics:
io– Number of megabytes I/O performedaggrb– Aggregate bandwidth of threads in the groupminb– Minimum average bandwidth a thread sawmaxb– Maximum average bandwidth a thread sawmint– Shortest runtime of threads in the groupmaxt– Longest runtime of threads in the group
This is what Fio reports upon each job’s completion in our testing environment. Again, your figures might be different due to variations in network, infrastructure configurations, as well as non-dedicated hostage of our cloud testing environment:
Job sgw-test-gp2 (performed against gp2-based Storage Gateway):

Job sgw-test-io1 (performed against io1-based Storage Gateway):

Table 3 and Chart 3 present these results in readable format:

Table 3: Results of AWS Storage Gateway I/O tests with asynchronous random I/O on 4-GB files (Fio Linux tool)

Chart 3: AWS Storage Gateway chart of asynchronous random I/O tests on 4-GB files (Fio Linux tool)
As you can see from this last chart, io1-based Storage Gateway file shares perform roughly 36% better than gp2-based gateway on an asynchronous I/O with large files. This is a considerable increase, but it comes at a cost and it depends on file size and business logic.
Summary
Bristol Myers Squibb has been using Storage Gateway for years, moving terabytes of scientific data from our local premises to the AWS Cloud daily. We’ve demonstrated that General Purpose SSD block storage (gp2 EBS volumes) can be a good option for Storage Gateway. This is especially true on datasets of small-to-medium files sizes (1 MB to 1 GB), with minimum impact on performance. The potential savings can reach up to 40%, because of EBS Provisioned IOPS SSD (io1) exchange with regular gp2 volumes, which can be substantial in many life science applications.
Needless to say, Bristol Myers Squibb has optimized its data transfer to the cloud using Storage Gateway. AWS offers a reliable portfolio of services that we use in tandem to securely manage our large-scale data infrastructure. I look forward to the possibility of sharing more of Bristol Myers Squibb’s journey with AWS on the AWS Storage Blog. Thanks for reading this two-part series on Bristol Myers Squibb’s use of AWS services, and please comment with any questions you may have.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.