AWS Open Source Blog
Category: Learning Levels

Virtual GPU device plugin for inference workloads in Kubernetes
Machine learning (ML) has become a centerpiece for enterprise transformation. AWS provides a broad and deep set of ML capabilities for builders with all levels of expertise. Developers with no prior ML experience can seamlessly build sophisticated AI-driven applications using AWS AI services. Developers and data scientists can use Amazon SageMaker, a managed machine learning […]

Getting started with the open source data science tool Metaflow on AWS
Data science is hard. Customers face business challenges today at a scale larger and more complex than ever before, and data scientists bring unique skills to the table to help solve some of those problems. The concept is simple: Data scientists use large amounts of data to break a problem down into pieces that machines […]

Using multiple queues and instance types in AWS ParallelCluster 2.9
Since its release as an officially supported AWS tool and open source project in November 2018, AWS ParallelCluster has made it simple for high performance computing (HPC) customers to set up easy-to-use environments with compute, storage, job scheduling, and networking in the cloud in one cohesive package. These clusters can cater to a wide variety […]

Using the K3s Kubernetes distribution in an Amazon EKS CI/CD pipeline
Modern microservices application stack, CI/CD pipeline, Kubernetes as orchestrator, hundreds or thousands of deployments per day—this all sounds good, until you realize that your Kubernetes development or staging environments are messed up by these deployments, and changes done by one developer team are affecting your developer team’s Kubernetes environment. In this post, we will walk […]

Multi-environment CI/CD pipelines with AWS CodePipeline and open source tools
A common scenario AWS customers face is how to automate their infrastructure deployments on AWS. Customers must create a secure, agile workflow that deploys to the cloud and uses their preferred AWS services. Customers also need a reliable, supportable deployment pattern driven by automated workflows that are not overly complex and difficult to manage. Customer […]

Improving HA and long-term storage for Prometheus using Thanos on EKS with S3
Prometheus is an open source systems monitoring and alerting toolkit that is widely adopted as a standard monitoring tool with self-managed and provider-managed Kubernetes. Prometheus provides many useful features, such as dynamic service discovery, powerful queries, and seamless alert notification integration. Beyond certain scale, however, problems arise when basic Prometheus capabilities do not meet requirements […]

Getting started with Travis-CI.com on AWS Graviton2
AWS Graviton2 processors deliver a major leap in performance and capabilities over first-generation AWS Graviton processors. They power Amazon Elastic Compute Cloud (Amazon EC2) M6g, C6g, and R6g instances, and their variants with local disk storage. Graviton2-based EC2 instances provide up to 40% better price/performance over comparable current generation x86-based instances for a wide variety […]

Dgraph on AWS: Setting up a horizontally scalable graph database
This article is a guest post from Joaquin Menchaca, an SRE at Dgraph. Dgraph is an open source, distributed graph database, built for production environments, and written entirely in Go. Dgraph is fast, transactional, sharded, and distributed (joins, filters, sorts), consistently replicated with Raft, and provides fault tolerance with synchronous replication and horizontal scalability. The […]
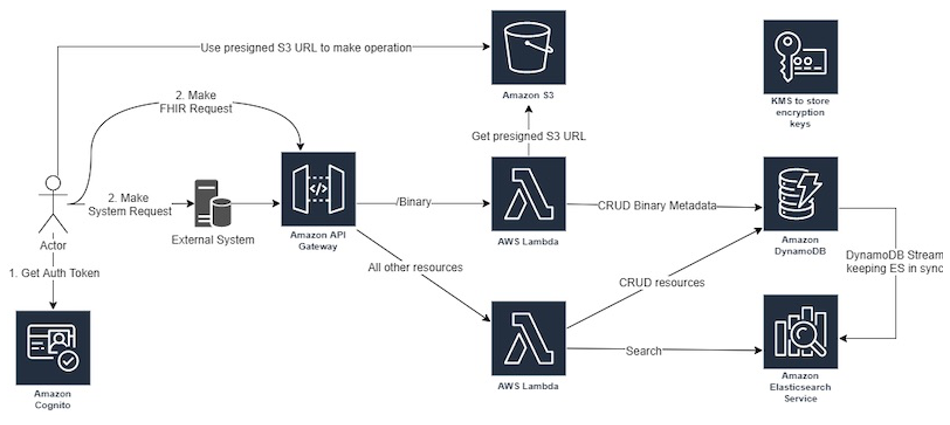
Using open source FHIR APIs with FHIR Works on AWS
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. Visit the website to learn more. In September 2019, we published a blog post, Building a Serverless FHIR Interface on AWS, which explained why customers might want to use FHIR (Fast Healthcare interoperability Resources) as a healthcare interface, and why serverless technology […]
Managing AWS ParallelCluster SSH users with OpenLDAP
A common request from AWS ParallelCluster users is to have the ability to deploy multiple POSIX user accounts. The wiki on the project GitHub page documents a simple mechanism for achieving this, and a previous blog post, “AWS ParallelCluster with AWS Directory Services Authentication,” documents how to integrate AWS ParallelCluster with AWS Directory Service. However, […]