AWS Machine Learning Blog
Tag: Amazon SageMaker

Using Pipe input mode for Amazon SageMaker algorithms
Today, we are introducing Pipe input mode support for the Amazon SageMaker built-in algorithms. With Pipe input mode, your dataset is streamed directly to your training instances instead of being downloaded first. This means that your training jobs start sooner, finish quicker, and need less disk space. Amazon SageMaker algorithms have been engineered to be […]
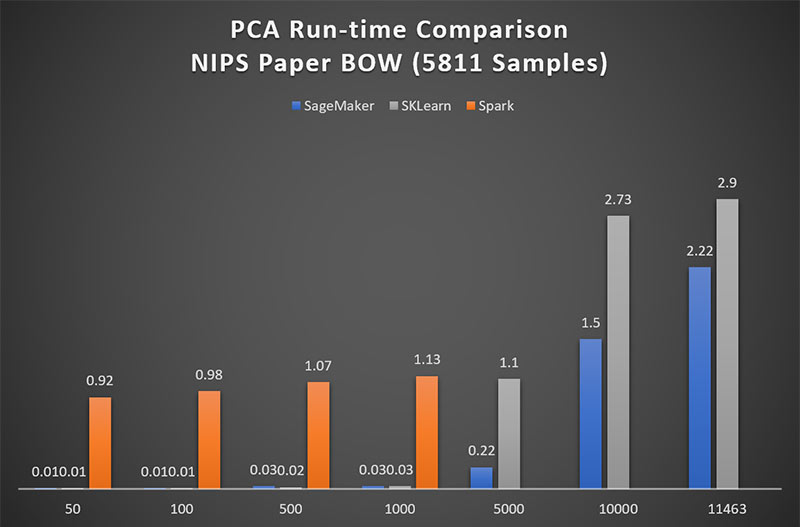
Perform a large-scale principal component analysis faster using Amazon SageMaker
In this blog post, we conduct a performance comparison for PCA using Amazon SageMaker, Spark ML, and Scikit-Learn on high-dimensional datasets. SageMaker consistently showed faster computational performance. Refer Figures (1) and (2) at the bottom to see the speed improvements. Principal Component Analysis Principal Component Analysis (PCA) is an unsupervised learning algorithm that attempts to […]

Running fast.ai notebooks with Amazon SageMaker
Update 25 JAN 2019: fast.ai has released a new version of their library and MOOC making the following blog post outdated. For the latest instructions on setting up the library and course on a SageMaker Notebook instance please refer to the instructions outlined here: https://course.fast.ai/start_sagemaker.html fast.ai is an organization dedicated to making the power of deep learning accessible […]

Build a March Madness predictor application supported by Amazon SageMaker
What an opening round of March Madness basketball tournament games! We had a buzzer beater, some historic upsets, and exciting games throughout. The model built in our first blog post (Part 1) pointed out a few likely upset candidates (Loyola IL, Butler), but did not see some coming (Marshall, UMBC). I’m sure there will be […]

Create a Word-Pronunciation sequence-to-sequence model using Amazon SageMaker
Amazon SageMaker seq2seq offers you a very simple way to make use of the state-of-the-art encoder-decoder architecture (including the attention mechanism) for your sequence to sequence tasks. You just need to prepare your sequence data in recordio-protobuf format and your vocabulary mapping files in JSON format. Then you need to upload them to Amazon Simple […]

Customize your Amazon SageMaker notebook instances with lifecycle configurations and the option to disable internet access
Amazon SageMaker provides fully managed instances running Jupyter Notebooks for data exploration and preprocessing. Customers really appreciate how easy it is to launch a pre-configured notebook instance with just one click. Today, we are making them more customizable by providing two new options: lifecycle configuration that helps automate the process of customizing your notebook instance, […]
Predict March Madness using Amazon Sagemaker
It’s mid-March and in the United States that can mean only one thing – it’s time for March Madness! Every year countless people fill out a bracket trying to pick which college basketball team will take it all. Do you have a favorite team to win in 2018? In this blog post, we’ll show you […]
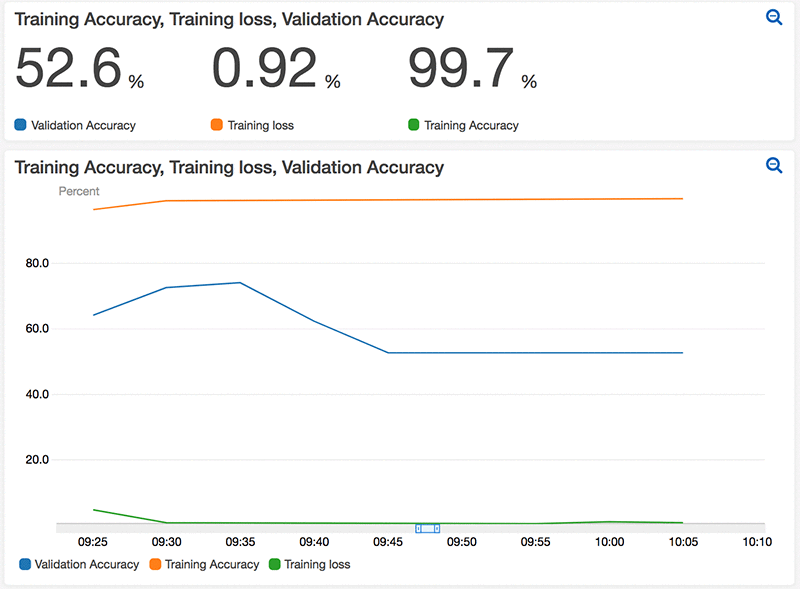
Use Amazon CloudWatch custom metrics for real-time monitoring of Amazon Sagemaker model performance
The training and learning process of deep learning (DL) models can be expensive and time consuming. It’s important for data scientists to monitor the model metrics, such as the training accuracy, training loss, validation accuracy, and validation loss, and make informed decisions based on those metrics. In this blog post, I’ll show you how to […]

Deploy Gluon models to AWS DeepLens using a simple Python API
April 2023 Update: Starting January 31, 2024, you will no longer be able to access AWS DeepLens through the AWS management console, manage DeepLens devices, or access any projects you have created. To learn more, refer to these frequently asked questions about AWS DeepLens end of life. Today we are excited to announce that you can […]

Train and host Scikit-Learn models in Amazon SageMaker by building a Scikit Docker container
Introduced at re:Invent 2017, Amazon SageMaker provides a serverless data science environment to build, train, and deploy machine learning models at scale. Customers also have the ability to work with frameworks they find most familiar, such as Scikit learn. In this blog post, we’ll accomplish two goals: First, we’ll give you a high-level overview of […]