Artificial Intelligence

Enhanced performance for Amazon Bedrock Custom Model Import
You can now achieve significant performance improvements when using Amazon Bedrock Custom Model Import, with reduced end-to-end latency, faster time-to-first-token, and improved throughput through advanced PyTorch compilation and CUDA graph optimizations. With Amazon Bedrock Custom Model Import you can to bring your own foundation models to Amazon Bedrock for deployment and inference at scale. In this post, we introduce how to use the improvements in Amazon Bedrock Custom Model Import.
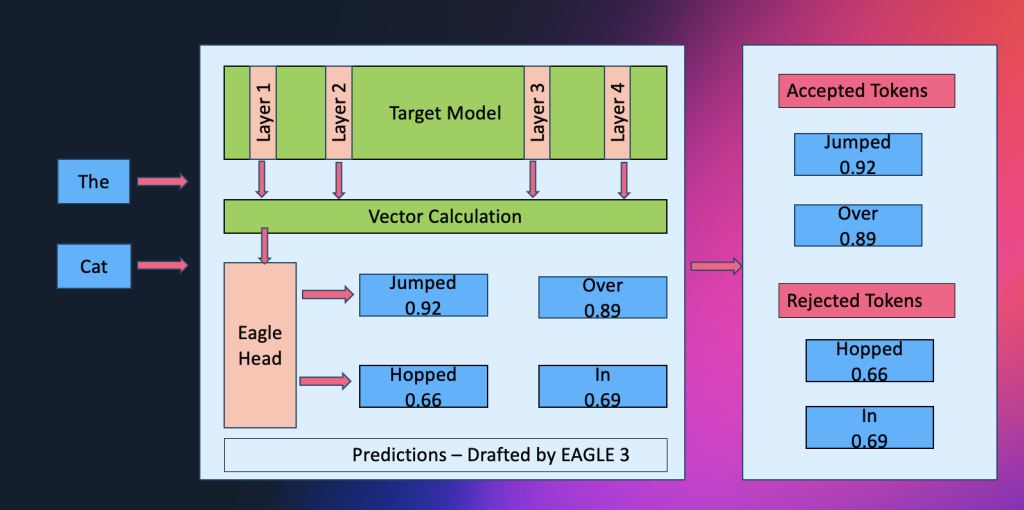
Amazon SageMaker AI introduces EAGLE based adaptive speculative decoding to accelerate generative AI inference
Amazon SageMaker AI now supports EAGLE-based adaptive speculative decoding, a technique that accelerates large language model inference by up to 2.5x while maintaining output quality. In this post, we explain how to use EAGLE 2 and EAGLE 3 speculative decoding in Amazon SageMaker AI, covering the solution architecture, optimization workflows using your own datasets or SageMaker’s built-in data, and benchmark results demonstrating significant improvements in throughput and latency.
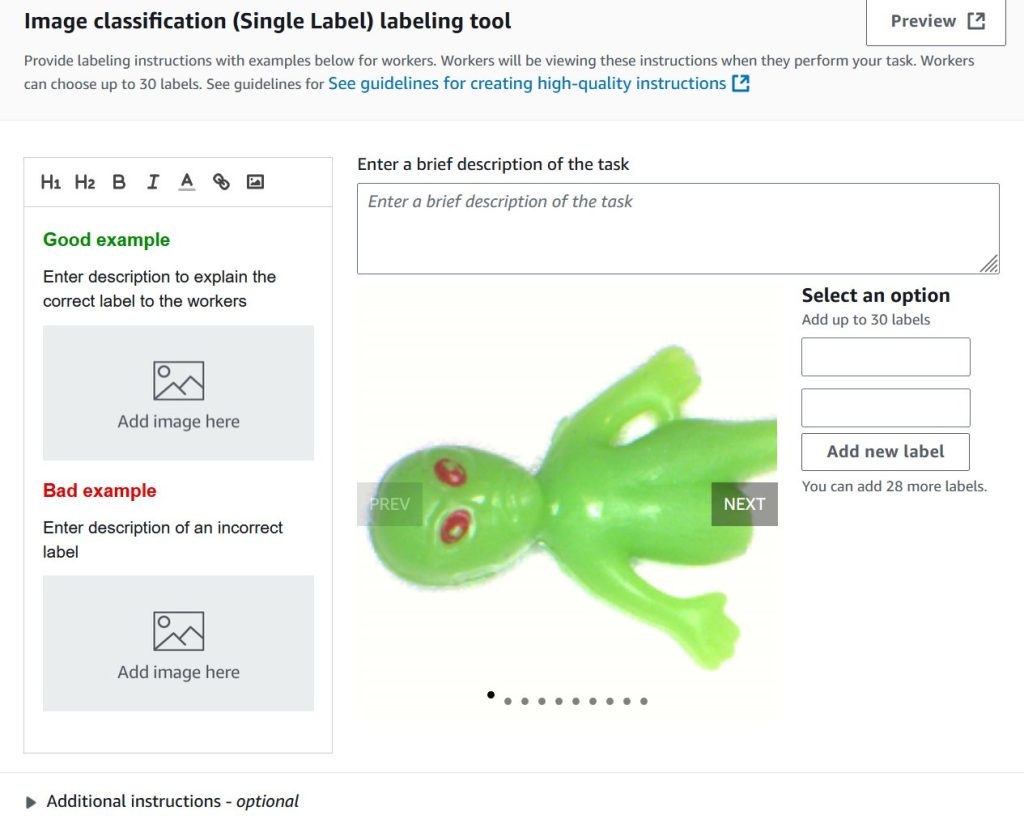
Train custom computer vision defect detection model using Amazon SageMaker
In this post, we demonstrate how to migrate computer vision workloads from Amazon Lookout for Vision to Amazon SageMaker AI by training custom defect detection models using pre-trained models available on AWS Marketplace. We provide step-by-step guidance on labeling datasets with SageMaker Ground Truth, training models with flexible hyperparameter configurations, and deploying them for real-time or batch inference—giving you greater control and flexibility for automated quality inspection use cases.
Practical implementation considerations to close the AI value gap
The AWS Customer Success Center of Excellence (CS COE) helps customers get tangible value from their AWS investments. We’ve seen a pattern: customers who build AI strategies that address people, process, and technology together succeed more often. In this post, we share practical considerations that can help close the AI value gap.

Introducing bidirectional streaming for real-time inference on Amazon SageMaker AI
We’re introducing bidirectional streaming for Amazon SageMaker AI Inference, which transforms inference from a transactional exchange into a continuous conversation. This post shows you how to build and deploy a container with bidirectional streaming capability to a SageMaker AI endpoint. We also demonstrate how you can bring your own container or use our partner Deepgram’s pre-built models and containers on SageMaker AI to enable bi-directional streaming feature for real-time inference.

Physical AI in practice: Technical foundations that fuel human-machine interactions
In this post, we explore the complete development lifecycle of physical AI—from data collection and model training to edge deployment—and examine how these intelligent systems learn to understand, reason, and interact with the physical world through continuous feedback loops. We illustrate this workflow through Diligent Robotics’ Moxi, a mobile manipulation robot that has completed over 1.2 million deliveries in hospitals, saving nearly 600,000 hours for clinical staff while transforming healthcare logistics and returning valuable time to patient care.
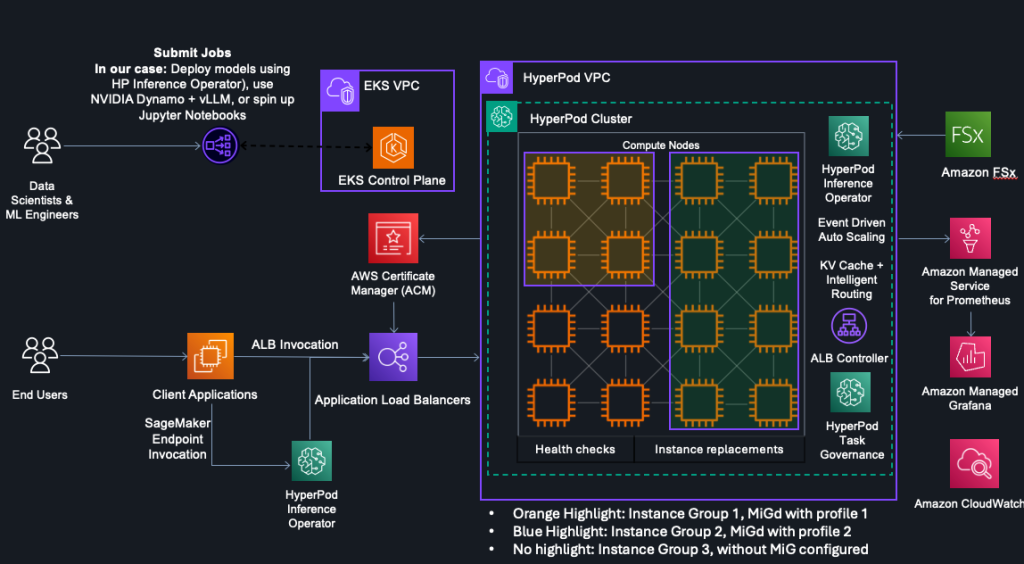
HyperPod now supports Multi-Instance GPU to maximize GPU utilization for generative AI tasks
In this post, we explore how Amazon SageMaker HyperPod now supports NVIDIA Multi-Instance GPU (MIG) technology, enabling you to partition powerful GPUs into multiple isolated instances for running concurrent workloads like inference, research, and interactive development. By maximizing GPU utilization and reducing wasted resources, MIG helps organizations optimize costs while maintaining performance isolation and predictable quality of service across diverse machine learning tasks.

Accelerate generative AI innovation in Canada with Amazon Bedrock cross-Region inference
We are excited to announce that customers in Canada can now access advanced foundation models including Anthropic’s Claude Sonnet 4.5 and Claude Haiku 4.5 on Amazon Bedrock through cross-Region inference (CRIS). This post explores how Canadian organizations can use cross-Region inference profiles from the Canada (Central) Region to access the latest foundation models to accelerate AI initiatives. We will demonstrate how to get started with these new capabilities, provide guidance for migrating from older models, and share recommended practices for quota management.

Power up your ML workflows with interactive IDEs on SageMaker HyperPod
Amazon SageMaker HyperPod clusters with Amazon Elastic Kubernetes Service (EKS) orchestration now support creating and managing interactive development environments such as JupyterLab and open source Visual Studio Code, streamlining the ML development lifecycle by providing managed environments for familiar tools to data scientists. This post shows how HyperPod administrators can configure Spaces for their clusters, and how data scientists can create and connect to these Spaces.

Claude Opus 4.5 now in Amazon Bedrock
Anthropic’s newest foundation model, Claude Opus 4.5, is now available in Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models from leading AI companies. In this post, I’ll show you what makes this model different, walk through key business applications, and demonstrate how to use Opus 4.5’s new tool use capabilities on Amazon Bedrock.