AWS Machine Learning Blog

Build a custom entity recognizer for PDF documents using Amazon Comprehend
In many industries, it’s critical to extract custom entities from documents in a timely manner. This can be challenging. Insurance claims, for example, often contain dozens of important attributes (such as dates, names, locations, and reports) sprinkled across lengthy and dense documents. Manually scanning and extracting such information can be error-prone and time-consuming. Rule-based software […]

Getting started with the Amazon Kendra Box connector
Amazon Kendra is a highly accurate and easy-to-use intelligent search service powered by machine learning (ML). Amazon Kendra offers a suite of data source connectors to simplify the process of ingesting and indexing your content, wherever it resides. For many organizations, Box Content Cloud is a core part of their content storage and lifecycle management […]
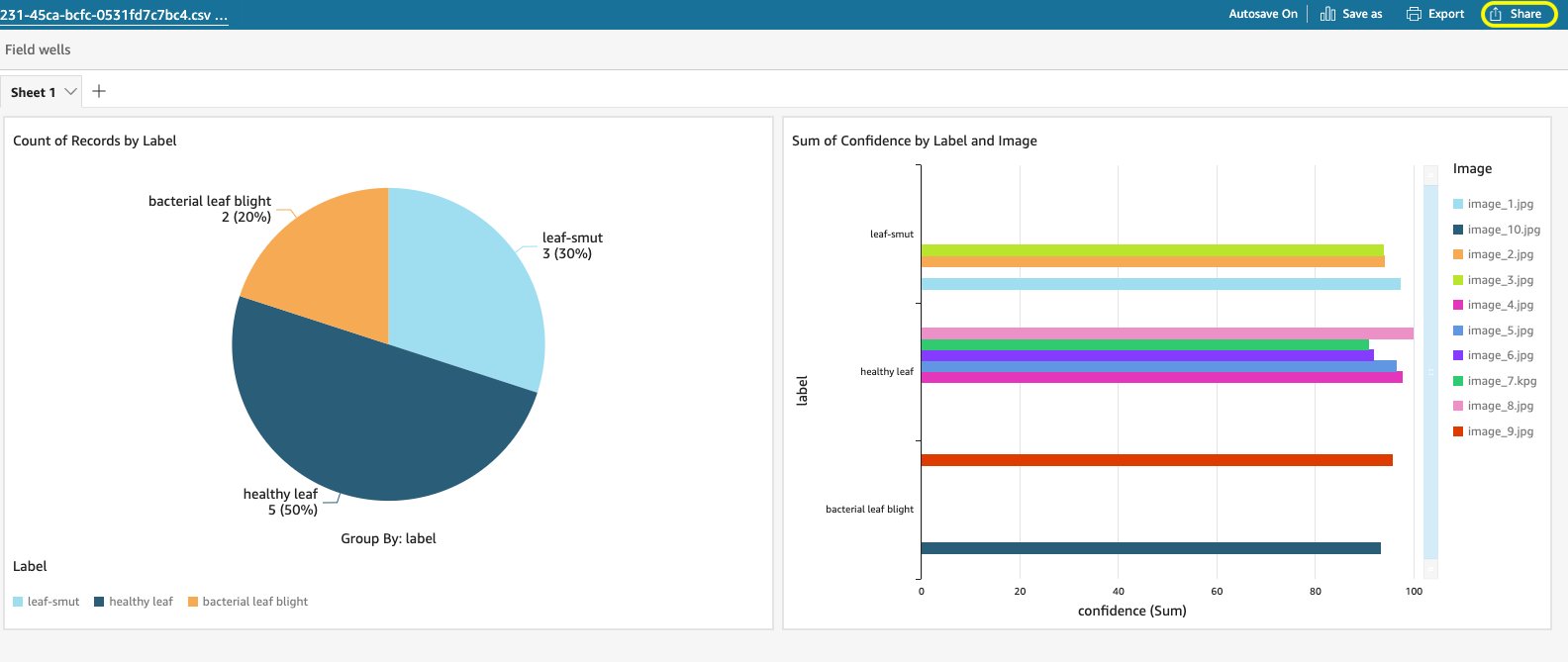
Receive notifications for image analysis with Amazon Rekognition Custom Labels and analyze predictions
Amazon Rekognition Custom Labels is a fully managed computer vision service that allows developers to build custom models to classify and identify objects in images that are specific and unique to your business. Rekognition Custom Labels doesn’t require you to have any prior computer vision expertise. You can get started by simply uploading tens of […]
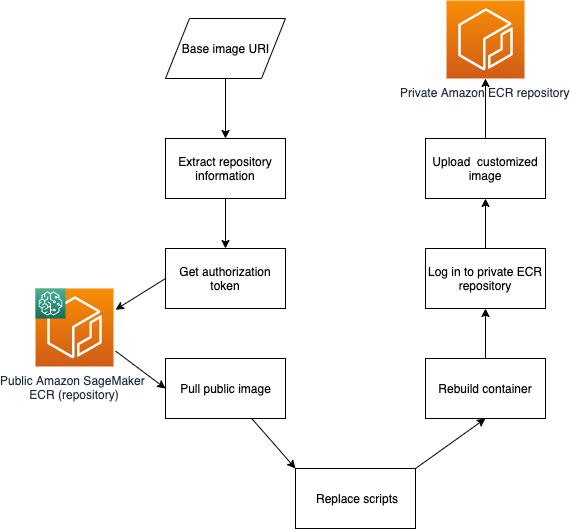
Customize the Amazon SageMaker XGBoost algorithm container
The built-in Amazon SageMaker XGBoost algorithm provides a managed container to run the popular XGBoost machine learning (ML) framework, with added convenience of supporting advanced training or inference features like distributed training, dataset sharding for large-scale datasets, A/B model testing, or multi-model inference endpoints. You can also extend this powerful algorithm to accommodate different requirements. […]
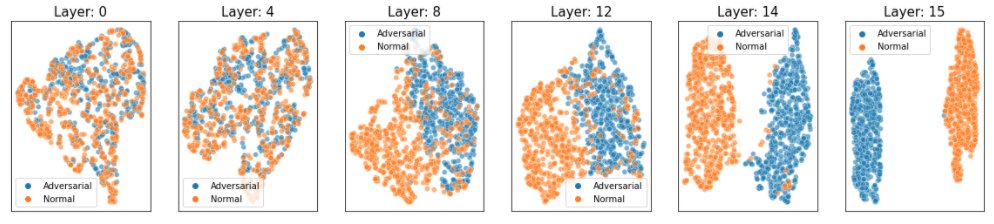
Detect adversarial inputs using Amazon SageMaker Model Monitor and Amazon SageMaker Debugger
Research over the past few years has shown that machine learning (ML) models are vulnerable to adversarial inputs, where an adversary can craft inputs to strategically alter the model’s output (in image classification, speech recognition, or fraud detection). For example, imagine you have deployed a model that identifies your employees based on images of their […]

Build an MLOps sentiment analysis pipeline using Amazon SageMaker Ground Truth and Databricks MLflow
As more organizations move to machine learning (ML) to drive deeper insights, two key stumbling blocks they run into are labeling and lifecycle management. Labeling is the identification of data and adding labels to provide context so an ML model can learn from it. Labels might indicate a phrase in an audio file, a car […]

Enable Amazon Kendra search for a scanned or image-based text document
Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra reimagines search for your websites and applications so your employees and customers can easily find the content they’re looking for, even when it’s scattered across multiple locations and content repositories within your organization. Amazon Kendra supports a variety of document formats, […]
Interpret caller input using grammar slot types in Amazon Lex
Customer service calls require customer agents to have the customer’s account information to process the caller’s request. For example, to provide a status on an insurance claim, the support agent needs policy holder information such as the policy ID and claim number. Such information is often collected in the interactive voice response (IVR) flow at […]
Whitepaper: Machine Learning Best Practices in Healthcare and Life Sciences
For customers looking to implement a GxP-compliant environment on AWS for artificial intelligence (AI) and machine learning (ML) systems, we have released a new whitepaper: Machine Learning Best Practices in Healthcare and Life Sciences. This whitepaper provides an overview of security and good ML compliance practices and guidance on building GxP-regulated AI/ML systems using AWS […]

Prepare data from Databricks for machine learning using Amazon SageMaker Data Wrangler
Data science and data engineering teams spend a significant portion of their time in the data preparation phase of a machine learning (ML) lifecycle performing data selection, cleaning, and transformation steps. It’s a necessary and important step of any ML workflow in order to generate meaningful insights and predictions, because bad or low-quality data greatly […]