AWS Machine Learning Blog

Bundesliga Match Fact Set Piece Threat: Evaluating team performance in set pieces on AWS
The importance of set pieces in football (or soccer in the US) has been on the rise in recent years: now more than one quarter of all goals are scored via set pieces. Free kicks and corners generally create the most promising situations, and some professional teams have even hired specific coaches for those parts […]

Bundesliga Match Fact Skill: Quantifying football player qualities using machine learning on AWS
In football, as in many sports, discussions about individual players have always been part of the fun. “Who is the best scorer?” or “Who is the king of defenders?” are questions perennially debated by fans, and social media amplifies this debate. Just consider that Erling Haaland, Robert Lewandowski, and Thomas Müller alone have a combined […]

Announcing the AWS DeepRacer League 2022
Unleash the power of machine learning (ML) through hands-on learning and compete for prizes and glory. The AWS DeepRacer League is the world’s first global autonomous racing competition driven by reinforcement learning; bringing together students, professionals, and enthusiasts from almost every continent. I’m Tomasz Ptak, a senior software engineer at Duco, an AWS Machine Learning […]

Train 175+ billion parameter NLP models with model parallel additions and Hugging Face on Amazon SageMaker Distributed Training Libraries
The last few years have seen rapid development in the field of natural language processing (NLP). While hardware has improved, such as with the latest generation of accelerators from NVIDIA and Amazon, advanced machine learning (ML) practitioners still regularly run into issues scaling their large language models across multiple GPU’s. In this blog post, we […]

ML inferencing at the edge with Amazon SageMaker Edge and Ambarella CV25
Ambarella builds computer vision SoCs (system on chips) based on a very efficient AI chip architecture and CVflow that provides the Deep Neural Network (DNN) processing required for edge inferencing use cases like intelligent home monitoring and smart surveillance cameras. Developers convert models trained with frameworks (such as TensorFlow or MXNET) to Ambarella CVflow format […]

Anomaly detection with Amazon SageMaker Edge Manager using AWS IoT Greengrass V2
Deploying and managing machine learning (ML) models at the edge requires a different set of tools and skillsets as compared to the cloud. This is primarily due to the hardware, software, and networking restrictions at the edge sites. This makes deploying and managing these models more complex. An increasing number of applications, such as industrial […]

How Kustomer utilizes custom Docker images & Amazon SageMaker to build a text classification pipeline
This is a guest post by Kustomer’s Senior Software & Machine Learning Engineer, Ian Lantzy, and AWS team Umesh Kalaspurkar, Prasad Shetty, and Jonathan Greifenberger. In Kustomer’s own words, “Kustomer is the omnichannel SaaS CRM platform reimagining enterprise customer service to deliver standout experiences. Built with intelligent automation, we scale to meet the needs of […]
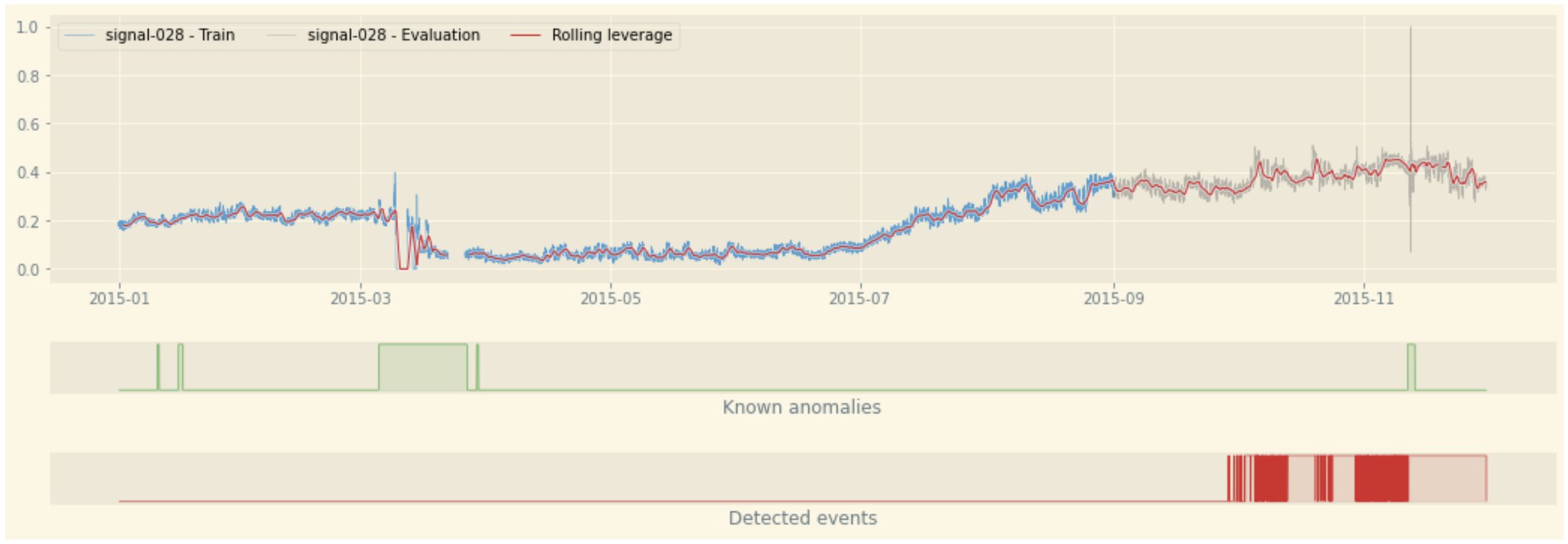
Build, train, and deploy Amazon Lookout for Equipment models using the Python Toolbox
Predictive maintenance can be an effective way to prevent industrial machinery failures and expensive downtime by proactively monitoring the condition of your equipment, so you can be alerted to any anomalies before equipment failures occur. Installing sensors and the necessary infrastructure for data connectivity, storage, analytics, and alerting are the foundational elements for enabling predictive […]
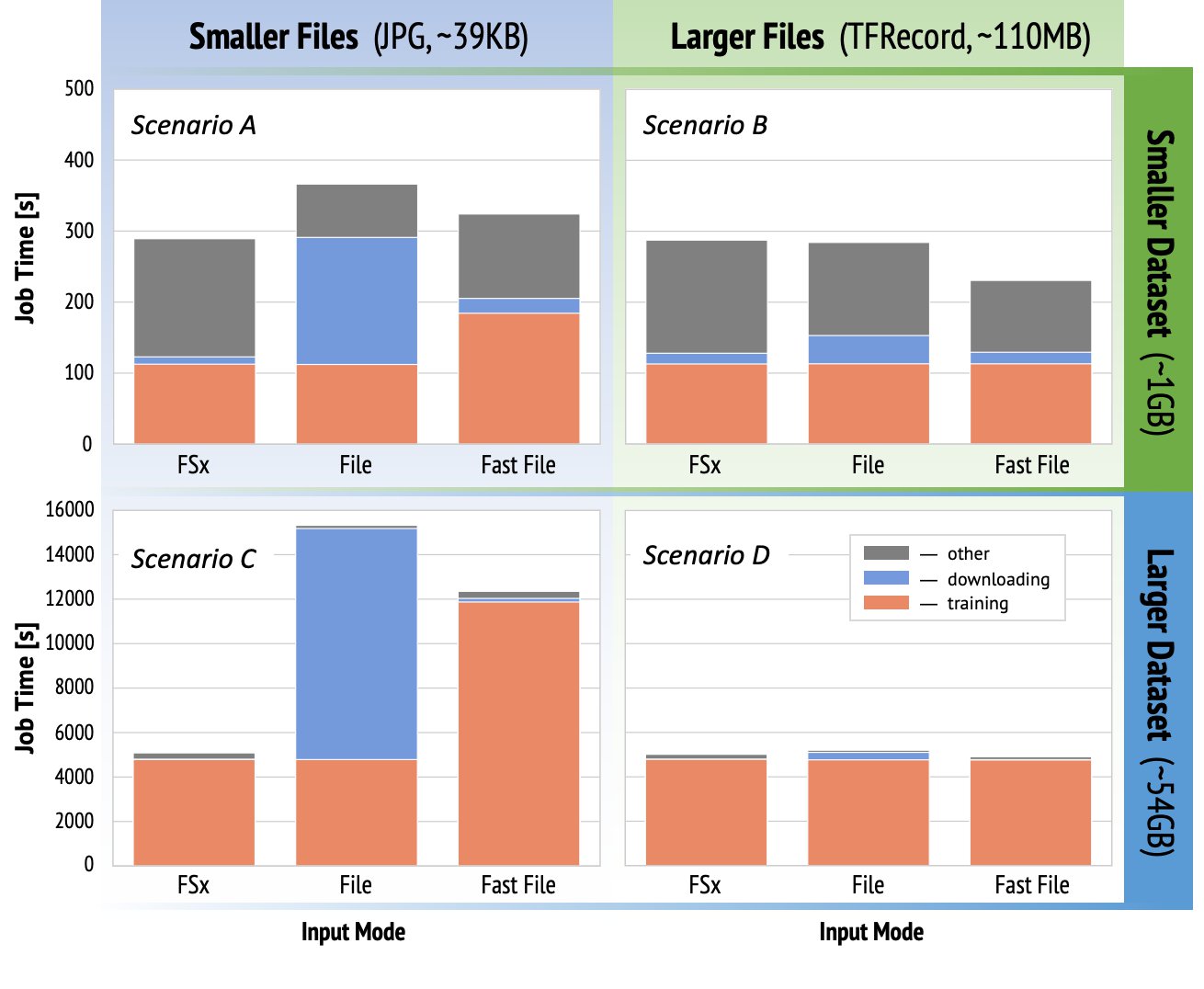
Choose the best data source for your Amazon SageMaker training job
Amazon SageMaker is a managed service that makes it easy to build, train, and deploy machine learning (ML) models. Data scientists use SageMaker training jobs to easily train ML models; you don’t have to worry about managing compute resources, and you pay only for the actual training time. Data ingestion is an integral part of […]
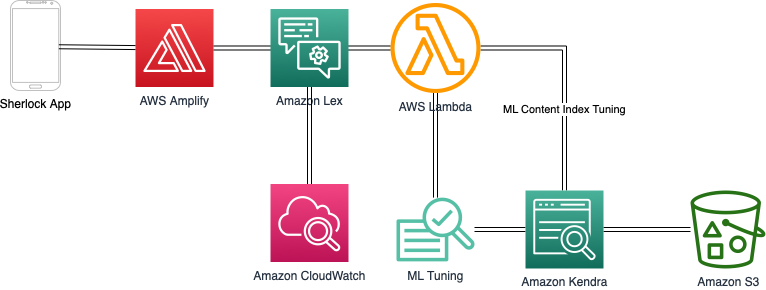
How InpharmD uses Amazon Kendra and Amazon Lex to drive evidence-based patient care
The intersection of DI and AI: Drug information refers to the discovery, use, and management of healthcare and medical information. Healthcare providers have many challenges associated with drug information discovery, such as intensive time involvement, lack of accessibility, and accuracy of reliable data. The average clinical query requires a literature search that takes an average of 18.5 hours. In addition, drug information often lies in disparate information silos, behind pay walls and design walls, and quickly becomes stale.