AWS Machine Learning Blog

Automated, scalable, and cost-effective ML on AWS: Detecting invasive Australian tree ferns in Hawaiian forests
This is blog post is co-written by Theresa Cabrera Menard, an Applied Scientist/Geographic Information Systems Specialist at The Nature Conservancy (TNC) in Hawaii. In recent years, Amazon and AWS have developed a series of sustainability initiatives with the overall goal of helping preserve the natural environment. As part of these efforts, AWS Professional Services establishes […]
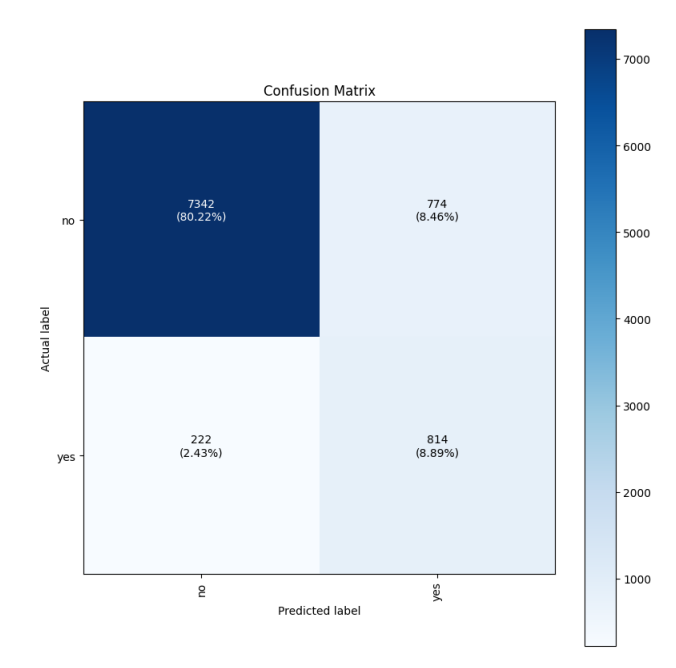
Automatically generate model evaluation metrics using SageMaker Autopilot Model Quality Reports
Amazon SageMaker Autopilot helps you complete an end-to-end machine learning (ML) workflow by automating the steps of feature engineering, training, tuning, and deploying an ML model for inference. You provide SageMaker Autopilot with a tabular data set and a target attribute to predict. Then, SageMaker Autopilot automatically explores your data, trains, tunes, ranks and finds […]

Build a mental health machine learning risk model using Amazon SageMaker Data Wrangler
This post is co-written by Shibangi Saha, Data Scientist, and Graciela Kravtzov, Co-Founder and CTO, of Equilibrium Point. Many individuals are experiencing new symptoms of mental illness, such as stress, anxiety, depression, substance use, and post-traumatic stress disorder (PTSD). According to Kaiser Family Foundation, about half of adults (47%) nationwide have reported negative mental health […]

Improve search accuracy with Spell Checker in Amazon Kendra
Amazon Kendra is an intelligent search service powered by machine learning. You can receive spelling suggestions for misspelled terms in your queries by utilizing the Amazon Kendra Spell Checker. Spell Checker helps reduce the frequency of queries returning irrelevant results by providing spelling suggestions for unrecognized terms. In this post, we explore how to use […]

Set up a text summarization project with Hugging Face Transformers: Part 2
This is the second post in a two-part series in which I propose a practical guide for organizations so you can assess the quality of text summarization models for your domain. For an introduction to text summarization, an overview of this tutorial, and the steps to create a baseline for our project (also referred to […]
Set up a text summarization project with Hugging Face Transformers: Part 1
When OpenAI released the third generation of their machine learning (ML) model that specializes in text generation in July 2020, I knew something was different. This model struck a nerve like no one that came before it. Suddenly I heard friends and colleagues, who might be interested in technology but usually don’t care much about […]

Optimize customer engagement with reinforcement learning
This is a guest post co-authored by Taylor Names, Staff Machine Learning Engineer, Dev Gupta, Machine Learning Manager, and Argie Angeleas, Senior Product Manager at Ibotta. Ibotta is an American technology company that enables users with its desktop and mobile apps to earn cash back on in-store, mobile app, and online purchases with receipt submission, […]
Expedite IVR development with industry grammars on Amazon Lex
Amazon Lex is a service for building conversational interfaces into any application using voice and text. With Amazon Lex, you can easily build sophisticated, natural language, conversational bots (chatbots), virtual agents, and interactive voice response (IVR) systems. You can now use industry grammars to accelerate IVR development on Amazon Lex as part of your IVR […]

Easily migrate your IVR flows to Amazon Lex using the IVR migration tool
This post was co-written by John Heater, SVP of the Contact Center Practice at NeuraFlash. NeuraFlash is an Advanced AWS Partner with over 40 collective years of experience in the voice and automation space. With a dedicated team of conversation designers, data engineers, and AWS developers, NeuraFlash helps customers take advantage of the power of Amazon […]

How Amazon Search achieves low-latency, high-throughput T5 inference with NVIDIA Triton on AWS
Amazon Search’s vision is to enable customers to search effortlessly. Our spelling correction helps you find what you want even if you don’t know the exact spelling of the intended words. In the past, we used classical machine learning (ML) algorithms with manual feature engineering for spelling correction. To make the next generational leap in […]