Artificial Intelligence
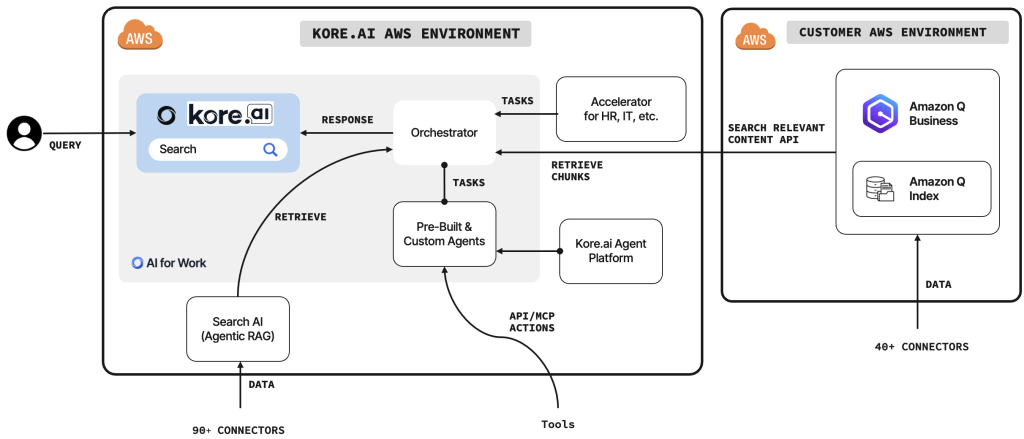
Enhance agentic workflows with enterprise search using Kore.ai and Amazon Q Business
In this post, we demonstrate how organizations can enhance their employee productivity by integrating Kore.ai’s AI for Work platform with Amazon Q Business. We show how to configure AI for Work as a data accessor for Amazon Q index for independent software vendors (ISVs), so employees can search enterprise knowledge and execute end-to-end agentic workflows involving search, reasoning, actions, and content generation.
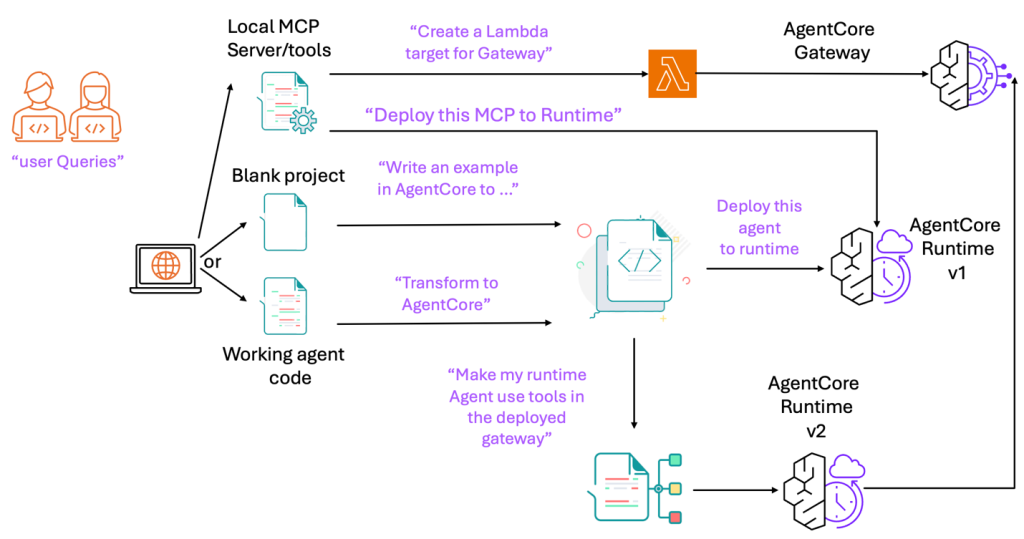
Accelerate development with the Amazon Bedrock AgentCore MCP server
Today, we’re excited to announce the Amazon Bedrock AgentCore Model Context Protocol (MCP) Server. With built-in support for runtime, gateway integration, identity management, and agent memory, the AgentCore MCP Server is purpose-built to speed up creation of components compatible with Bedrock AgentCore. You can use the AgentCore MCP server for rapid prototyping, production AI solutions, […]
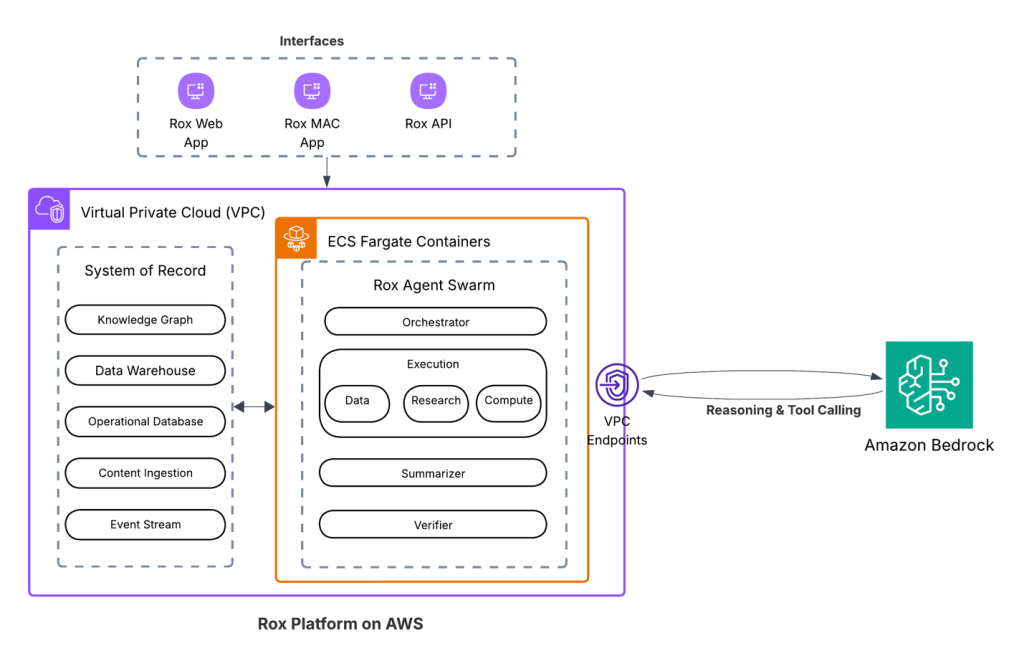
Rox accelerates sales productivity with AI agents powered by Amazon Bedrock
We’re excited to announce that Rox is generally available, with Rox infrastructure built on AWS and delivered across web, Slack, macOS, and iOS. In this post, we share how Rox accelerates sales productivity with AI agents powered by Amazon Bedrock.
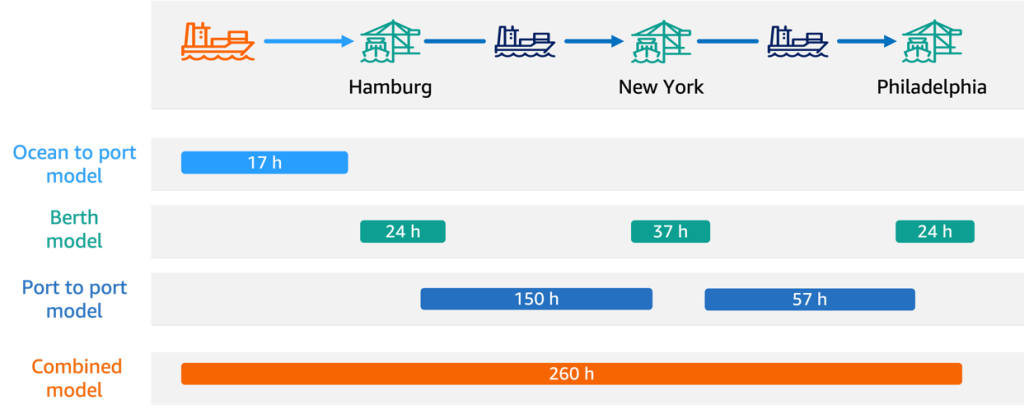
How Hapag-Lloyd improved schedule reliability with ML-powered vessel schedule predictions using Amazon SageMaker
In this post, we share how Hapag-Lloyd developed and implemented a machine learning (ML)-powered assistant predicting vessel arrival and departure times that revolutionizes their schedule planning. By using Amazon SageMaker AI and implementing robust MLOps practices, Hapag-Lloyd has enhanced its schedule reliability—a key performance indicator in the industry and quality promise to their customers.
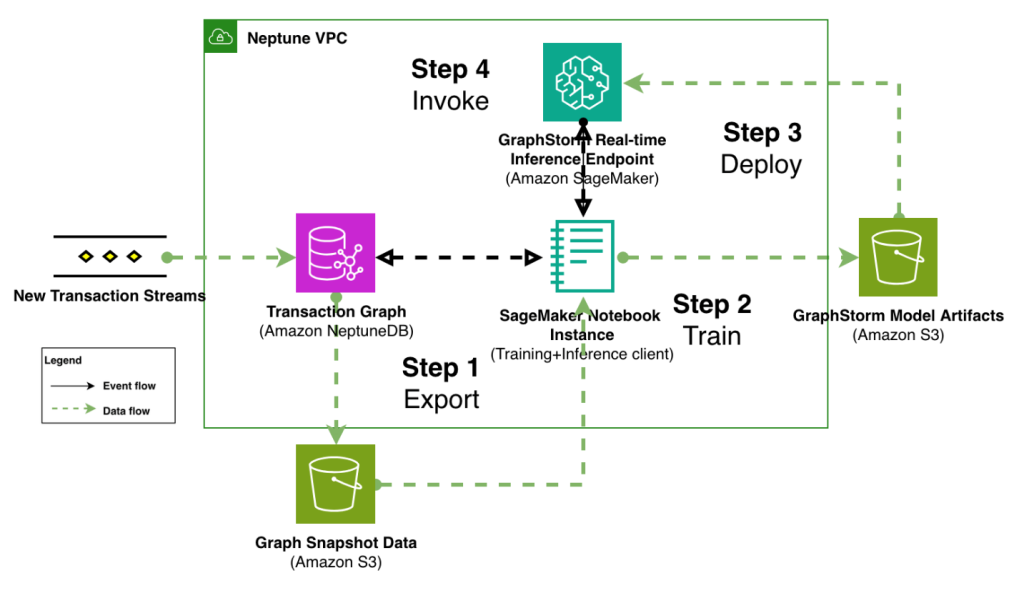
Modernize fraud prevention: GraphStorm v0.5 for real-time inference
In this post, we demonstrate how to implement real-time fraud prevention using GraphStorm v0.5’s new capabilities for deploying graph neural network (GNN) models through Amazon SageMaker. We show how to transition from model training to production-ready inference endpoints with minimal operational overhead, enabling sub-second fraud detection on transaction graphs with billions of nodes and edges.
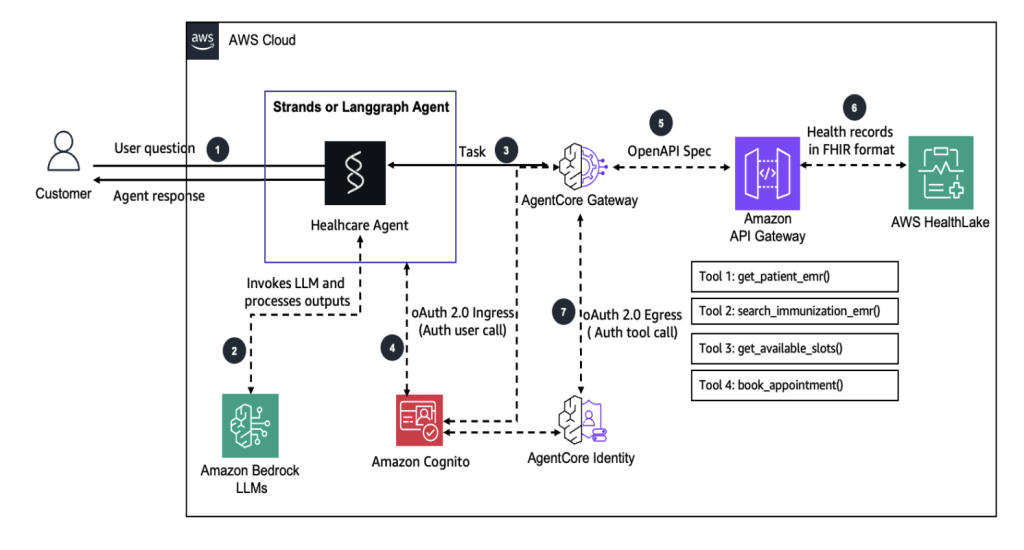
Building health care agents using Amazon Bedrock AgentCore
In this solution, we demonstrate how the user (a parent) can interact with a Strands or LangGraph agent in conversational style and get information about the immunization history and schedule of their child, inquire about the available slots, and book appointments. With some changes, AI agents can be made event-driven so that they can automatically send reminders, book appointments, and so on.
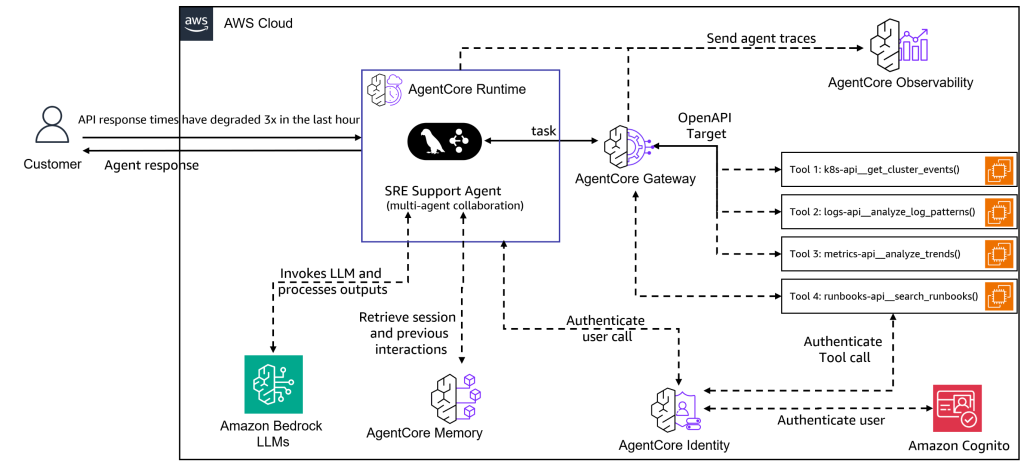
Build multi-agent site reliability engineering assistants with Amazon Bedrock AgentCore
In this post, we demonstrate how to build a multi-agent SRE assistant using Amazon Bedrock AgentCore, LangGraph, and the Model Context Protocol (MCP). This system deploys specialized AI agents that collaborate to provide the deep, contextual intelligence that modern SRE teams need for effective incident response and infrastructure management.

DoWhile loops now supported in Amazon Bedrock Flows
Today, we are excited to announce support for DoWhile loops in Amazon Bedrock Flows. With this powerful new capability, you can create iterative, condition-based workflows directly within your Amazon Bedrock flows, using Prompt nodes, AWS Lambda functions, Amazon Bedrock Agents, Amazon Bedrock Flows inline code, Amazon Bedrock Knowledge Bases, Amazon Simple Storage Service (Amazon S3), […]
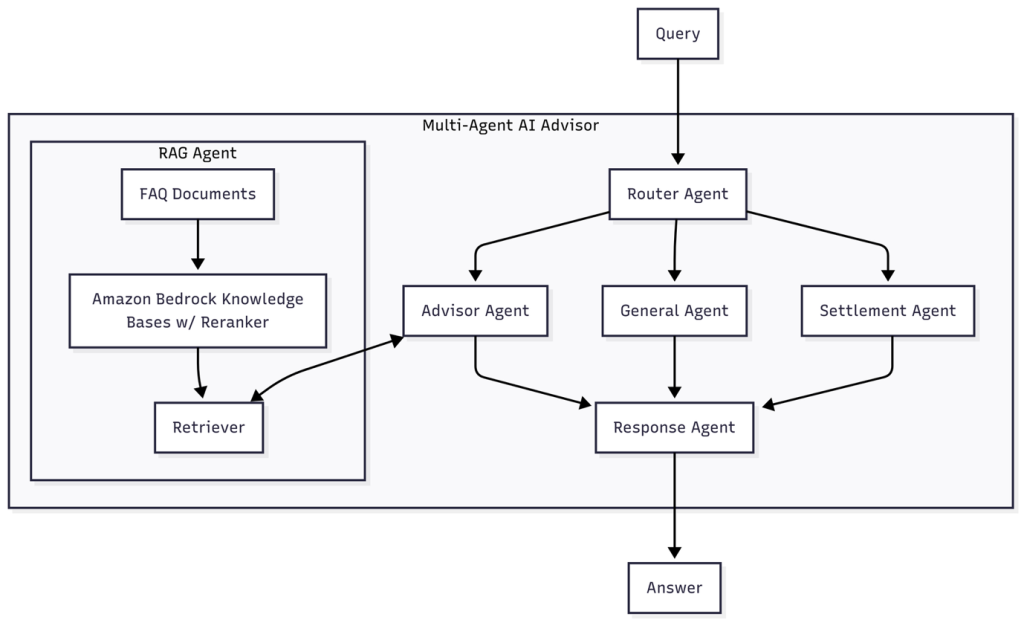
How PropHero built an intelligent property investment advisor with continuous evaluation using Amazon Bedrock
In this post, we explore how we built a multi-agent conversational AI system using Amazon Bedrock that delivers knowledge-grounded property investment advice. We explore the agent architecture, model selection strategy, and comprehensive continuous evaluation system that facilitates quality conversations while facilitating rapid iteration and improvement.
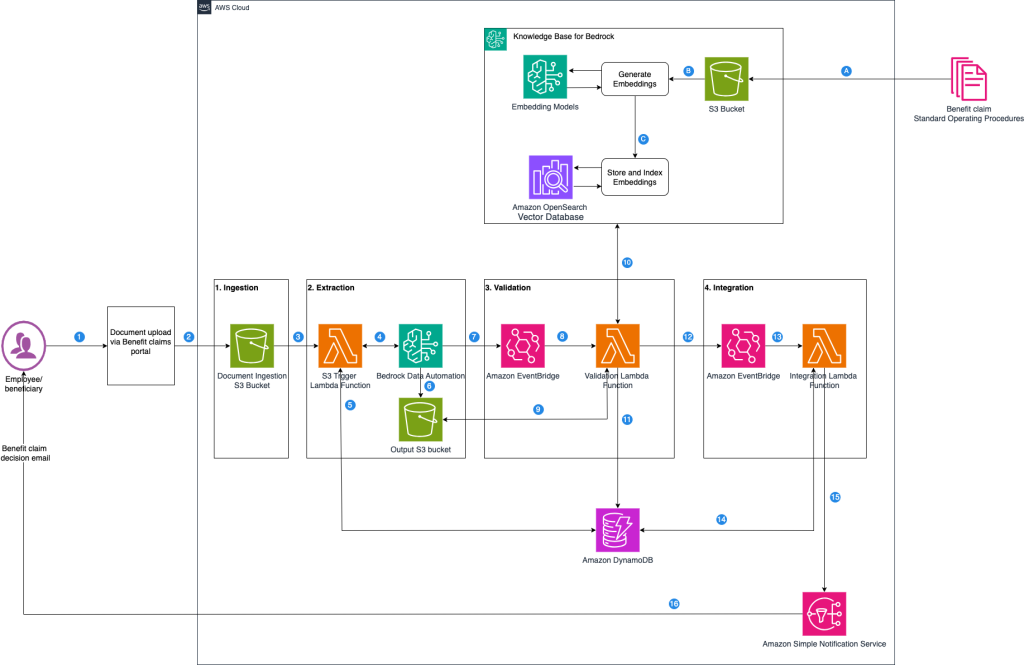
Accelerate benefits claims processing with Amazon Bedrock Data Automation
In the benefits administration industry, claims processing is a vital operational pillar that makes sure employees and beneficiaries receive timely benefits, such as health, dental, or disability payments, while controlling costs and adhering to regulations like HIPAA and ERISA. In this post, we examine the typical benefit claims processing workflow and identify where generative AI-powered automation can deliver the greatest impact.