AWS Machine Learning Blog
Feature engineering at scale for healthcare and life sciences with Amazon SageMaker Data Wrangler
October 2023: This post was reviewed and updated for accuracy.
Machine learning (ML) is disrupting a lot of industries at an unprecedented pace. The healthcare and life sciences (HCLS) industry has been going through a rapid evolution in recent years embracing ML across a multitude of use cases for delivering quality care and improving patient outcomes.
In a typical ML lifecycle, data engineers and scientists spend the majority of their time on the data preparation and feature engineering steps before even getting started with the process of model building and training. Having a tool that can lower the barrier to entry for data preparation, thereby improving productivity, is a highly desirable ask for these personas. Amazon SageMaker Data Wrangler is purpose built by AWS to reduce the learning curve and enable data practitioners to accomplish data preparation, cleaning, and feature engineering tasks in less effort and time. It offers a GUI interface with many built-in functions and integrations with other AWS services such as Amazon Simple Storage Service (Amazon S3) and Amazon SageMaker Feature Store, as well as partner data sources including Snowflake and Databricks.
In this post, we demonstrate how to use Data Wrangler to prepare healthcare data for training a model to predict heart failure, given a patient’s demographics, prior medical conditions, and lab test result history.
Solution overview
The solution consists of the following steps:
- Acquire a healthcare dataset as input to Data Wrangler.
- Use Data Wrangler’s built-in transformation functions to transform the dataset. This includes drop columns, featurize data/time, join datasets, impute missing values, encode categorical variables, scale numeric values, balance the dataset, and more.
- Use Data Wrangler’s custom transform function (Pandas or PySpark code) to supplement additional transformations required beyond the built-in transformations and demonstrate the extensibility of Data Wrangler. This includes filter rows, group data, form new dataframes based on conditions, and more.
- Use Data Wrangler’s built-in visualization functions to perform visual analysis. This includes target leakage, feature correlation, quick model, and more.
- Use Data Wrangler’s built-in export options to export the transformed dataset to Amazon S3.
- Launch a Jupyter notebook to use the transformed dataset in Amazon S3 as input to train a model.
Generate a dataset
Now that we have settled on the ML problem statement, we first set our sights on acquiring the data we need. Research studies such as Heart Failure Prediction may provide data that’s already in good shape. However, we often encounter scenarios where the data is quite messy and requires joining, cleansing, and several other transformations that are very specific to the healthcare domain before it can be used for ML training. We want to find or generate data that is messy enough and walk you through the steps of preparing it using Data Wrangler. With that in mind, we picked Synthea as a tool to generate synthetic data that fits our goal. Synthea is an open-source synthetic patient generator that models the medical history of synthetic patients. To generate your dataset, complete the following steps:
- Follow the instructions as per the quick start documentation to create an Amazon SageMaker Studio domain and launch Studio.
This is a prerequisite step. It is optional if Studio is already set up in your account. - After Studio is launched, click Open Launcher, under Utilities and files, click System terminal. This launches a terminal session that gives you a command line interface to work with.

- To install Synthea and generate the dataset in CSV format, run the following commands in the launched terminal session:
We supply a parameter to generate the datasets with a population size of 10,000. Note the size parameter denotes the number of alive members of the population. Additionally, Synthea also generates data for dead members of the population which might add a few extra data points on top of the specified sample size.
Wait until the data generation is complete. This step usually takes around an hour or less. Synthea generates multiple datasets, including patients, medications, allergies, conditions, and more. For this post, we use three of the resulting datasets:
- patients.csv – This dataset is about 3.2 MB and contains approximately 11,000 rows of patient data (25 columns including patient ID, birthdate, gender, address, and more)
- conditions.csv – This dataset is about 47 MB and contains approximately 370,000 rows of medical condition data (six columns including patient ID, condition start date, condition code, and more)
- observations.csv – This dataset is about 830 MB and contains approximately 5 million rows of observation data (eight columns including patient ID, observation date, observation code, value, and more)
There is a one-to-many relationship between the patients and conditions datasets. There is also a one-to-many relationship between the patients and observations datasets. For a detailed data dictionary, refer to CSV File Data Dictionary.
- To upload the generated datasets to a source bucket in Amazon S3, run the following commands in the terminal session:
Launch Data Wrangler
In the left pane under Data click Data Wrangler. For detailed steps on how to launch Data Wrangler from within Studio, refer to Get Started with Data Wrangler.

Import data
To import your data, complete the following steps:
- Click the Import data button on the top right of the screen. (This will take a few minutes before loading the Create connection screen)
- Choose Amazon S3 and locate the
patients.csvfile in the S3 bucket. - In the Import Settings pane, choose First K for Sampling.
- Enter 1100 for Sample size.
In the preview pane, Data Wrangler pulls the first 100 rows from the dataset and lists them as a preview.
- Choose Import.
Data Wrangler selects the first 1,100 patients from the total patients (11,000 rows) generated by Synthea and imports the data. The sampling approach lets Data Wrangler only process the sample data. It enables us to develop our data flow with a smaller dataset, which results in quicker processing and a shorter feedback loop. After we create the data flow, we can submit the developed recipe to a SageMaker processing job to horizontally scale out the processing for the full or larger dataset in a distributed fashion.

- At the top left click Data flow and then also in the top left select Import and repeat this process for the
conditionsandobservations. - For the conditions dataset, enter 37000 for Sample size, which is 1/10 of the total 370,000 rows generated by Synthea.
- For the observations dataset, enter 500000 for Sample size, which is 1/10 of the total observations 5 million rows generated by Synthea.
You should see three datasets as shown in the following screenshot.

Transform the data
Data transformation is the process of changing the structure, value, or format of one or more columns in the dataset. The process is usually developed by a data engineer and can be challenging for people with a smaller data engineering skillset to decipher the logic proposed for the transformation. Data transformation is part of the broader feature engineering process, and the correct sequence of steps is another important criterion to keep in mind while devising such recipes.
Data Wrangler is designed to be a low-code tool to reduce the barrier of entry for effective data preparation. It comes with over 300 preconfigured data transformations for you to choose from without writing a single line of code. In the following sections, we see how to transform the imported datasets in Data Wrangler.
Drop columns in patients.csv
We first drop some columns from the patients dataset. Dropping redundant columns removes non-relevant information from the dataset and helps us reduce the amount of computing resources required to process the dataset and train a model. In this section, we drop columns such as SSN or passport number based on common sense that these columns have no predictive value. In other words, they don’t help our model predict heart failure. Our study is also not concerned about other columns such as birthplace or healthcare expenses’ influence to a patient’s heart failure, so we drop them as well. Redundant columns can also be identified by running the built-in analyses like target leakage, feature correlation, multicollinearity, and more, which are built into Data Wrangler. For more details on the supported analyses types, refer to Analyze and Visualize. Additionally, you can use the Data Quality and Insights Report to perform automated analyses on the datasets to arrive at a list of redundant columns to eliminate.
- Choose the plus sign next to Data types for the patients.csv dataset and choose Add transform.

- Choose Add step and choose Manage columns.

- For Transform¸ choose Drop column.
- For Columns to drop, choose the following columns:
SSNDRIVERSPASSPORTPREFIXFIRSTLASTSUFFIXMAIDENRACEETHNICITYBIRTHPLACEADDRESSCITYSTATECOUNTYZIPLATLONHEALTHCARE_EXPENSESHEALTHCARE_COVERAGE
- Choose Preview to review the transformed dataset, then choose Add.

You should see the step Drop column in your list of transforms.

Featurize date/time in patients.csv
Now we use the Featurize date/time function to generate the new feature Year from the BIRTHDATE column in the patients dataset. We use the new feature in a subsequent step to calculate a patient’s age at the time of observation takes place.
- In the Transforms pane of your Drop column page for the
patientsdataset, choose Add step. - Choose the Featurize date/time transform.

- Choose Extract columns.
- For Input columns, add the column
BIRTHDATE. - Select Year and deselect Month, Day, Hour, Minute, Second.
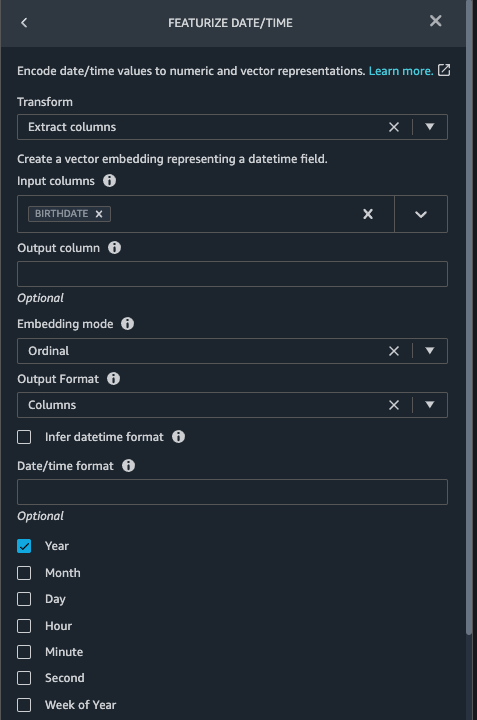
- Choose Preview, then choose Add.
Add transforms in observations.csv
Data Wrangler supports custom transforms using Python (user-defined functions), PySpark, Pandas, or PySpark (SQL). You can choose your transform type based on your familiarity with each option and preference. For the latter three options, Data Wrangler exposes the variable df for you to access the dataframe and apply transformations on it. For a detailed explanation and examples, refer to Custom Transforms. In this section, we add three custom transforms to the observations dataset.
- Add a transform to observations.csv and drop the
DESCRIPTIONcolumn.

- Choose Preview, then choose Add.
- In the Transforms pane, choose Add step and choose Custom transform.
- On the drop-down menu, choose Python (Pandas).

- Enter the following code:
These are LONIC codes that correspond to the following observations we’re interested in using as features for predicting heart failure:
- Choose Preview, then choose Add.
- Add a transform to extract
YearandQuarterfrom theDATEcolumn.
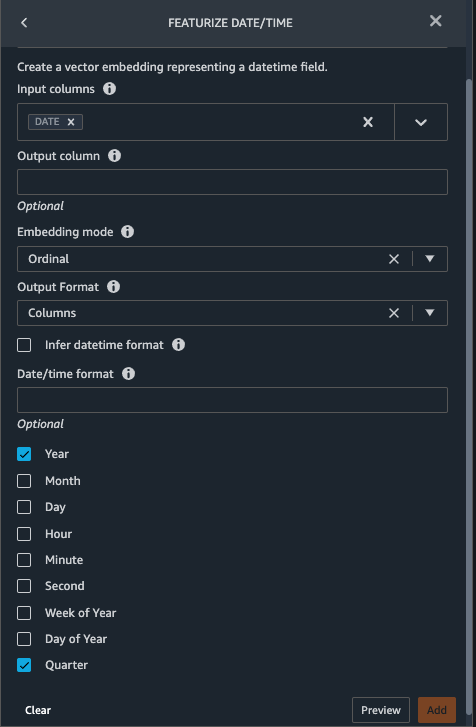
- Choose Preview, then choose Add.
- Choose Add step and choose Custom transform.
- On the drop-down menu, choose Python (PySpark).
The five types of observations may not always be recorded on the same date. For example, a patient may visit their family doctor on January 21 and have their systolic blood pressure, diastolic blood pressure, heart rate, and body mass index measured and recorded. However, a lab test that includes platelets may be done at a later date on February 2. Therefore, it’s not always possible to join dataframes by the observation date. Here we join dataframes on a coarse granularity at the quarter basis. - Enter the following code:
- Choose Preview, then choose Add.
- Choose Add step, then choose Manage rows.
- For Transform, choose Drop duplicates.

- Choose Preview, then choose Add.
- Choose Add step and choose Custom transform.
- On the drop-down menu, choose Python (Pandas).
- Enter the following code to take an average of data points that share the same time value:
- Choose Preview, then choose Add.
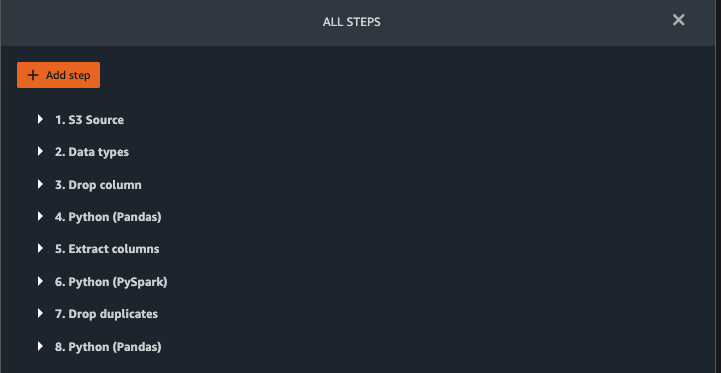
Join patients.csv and observations.csv
In this step, we showcase how to effectively and easily perform complex joins on datasets without writing any code via Data Wrangler’s powerful UI. To learn more about the supported types of joins, refer to Transform Data.
- To the right of Transform: patients.csv, choose the plus sign next to Steps and choose Join.
You can see the transformed patients.csv file listed under Datasets in the left pane.
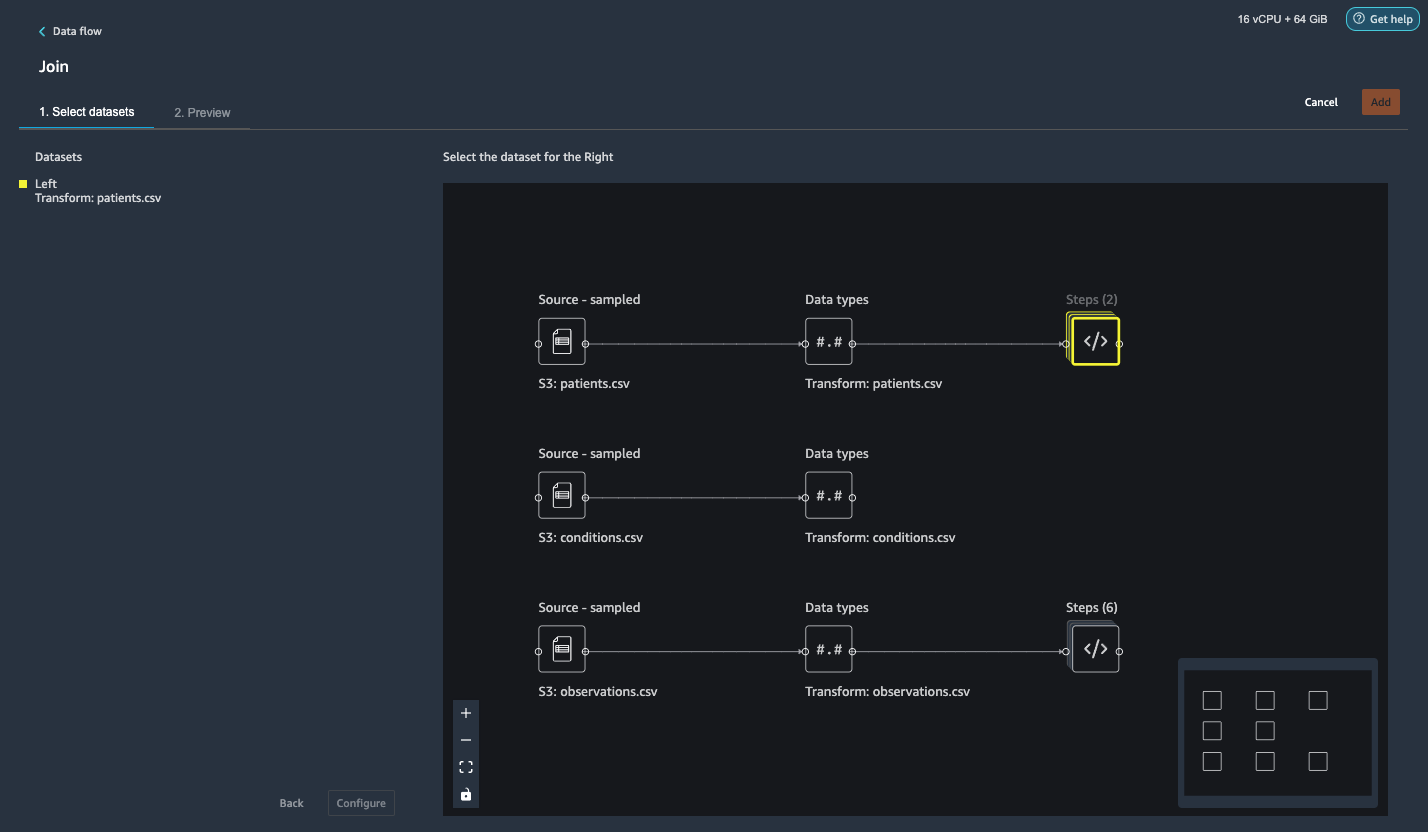
- To the right of Transform: observations.csv, click on the Steps to initiate the join operation.
The transformed observations.csv file is now listed under Datasets in the left pane.

- Choose Configure.
- For Join Type, choose Inner.
- For Left, choose Id.
- For Right, choose patient.
- Choose Preview, then choose Add.

Add a custom transform to the joined datasets
In this step, we calculate a patient’s age at the time of observation. We also drop columns that are no longer needed.
- Choose the plus sign next to 1st Join and choose Add transform.
- Add a custom transform in Pandas:
- Choose Preview, then choose Add.
Add custom transforms to conditions.csv
- Choose the plus sign next to Transform: conditions.csv and choose Add transform.
- Add a custom transform in Pandas:
Note: As we demonstrated earlier, you can drop columns either using custom code or using the built-in transformations provided by Data Wrangler. Custom transformations within Data Wrangler provides the flexibility to bring your own transformation logic in the form of code snippets in the supported frameworks. These snippets can later be searched and applied if needed.
The codes in the preceding transform are SNOMED-CT codes that correspond to the following conditions. The heart failure or chronic congestive heart failure condition becomes the label. We use the remaining conditions as features for predicting heart failure. We also drop a few columns that are no longer needed.
- Next, let’s add a custom transform in PySpark:
We perform a left outer join to keep all entries in the heart failure dataframe. A new column
has_xxxis calculated for each condition other than heart failure based on the condition’s start date. We’re only interested in medical conditions that were recorded prior to the heart failure and use them as features for predicting heart failure. - Add a built-in Manage columns transform to drop the redundant columns that are no longer needed:
hypertensiondiabetescoronarysmokeatrial
- Extract
YearandQuarterfrom theheartfailurecolumn.
This matches the granularity we used earlier in the transformation of theobservationsdataset. - We should have a total of 6 steps for conditions.csv.

Join conditions.csv to the joined dataset
We now perform a new join to join the conditions dataset to the joined patients and observations dataset.
- Choose Transform: 1st Join.
- Choose the plus sign and choose Join.
- Choose Steps next to Transform: conditions.csv.

- Choose Configure.
- For Join Type, choose Left outer.
- For Left, choose Id.
- For Right, choose patient.
- Choose Preview, then choose Add.

Add transforms to the joined datasets
Now that we have all three datasets joined, let’s apply some additional transformations.
- Add the following custom transform in PySpark so
has_heartfailurebecomes our label column: - Add the following custom transformation in PySpark:
- Drop the redundant columns that are no longer needed:
IdDATE_yearDATE_quarterpatientheartfailureheartfailure_yearheartfailure_quarter
- On the Analysis tab, for Analysis type¸ choose Table summary.
A quick scan through the summary shows that theMARITALcolumn has missing data.

- Choose the Data tab and add a step.
- Choose Handle Missing.
- For Transform, choose Fill missing.
- For Input columns, choose MARITAL.
- For Fill value, enter
S.
Our strategy here is to assume the patient is single if the marital status has missing value. You can have a different strategy.

- Choose Preview, then choose Add.
Marital and Gender are categorial variables. Data Wrangler has a built-in function to encode categorial variables.
- Add a step and choose Encode categorial.
- For Transform, choose One-hot encode.
- For Input columns, choose MARITAL.
- For Output style, choose Column.
This output style produces encoded values in separate columns.

- Choose Preview, then choose Add.
- Repeat these steps for the Gender column.
The one-hot encoding splits the Marital column into Marital_M (married) and Marital_S (single), and splits the Gender column into Gender_M (male) and Gender_F (female). Because Marital_M and Marital_S are mutually exclusive (as are Gender_M and Gender_F), we can drop one column to avoid redundant features.
- Drop
Marital_SandGender_F.
Numeric features such as systolic, heart rate, and age have different unit standards. For a linear regression-based model, we need to normalize these numeric features first. Otherwise, some features with higher absolute values may have an unwarranted advantage over other features with lower absolute values and result in poor model performance. Data Wrangler has the built-in transform Min-max scaler to normalize the data. For a decision tree-based classification model, normalization isn’t required. Our study is a classification problem so we don’t need to apply normalization. Imbalanced classes are a common problem in classification. Imbalance happens when the training dataset contains severely skewed class distribution. For example, when our dataset contains disproportionally more patients without heart failure than patients with heart failure, it can cause the model to be biased toward predicting no heart failure and perform poorly. Data Wrangler has a built-in function to tackle the problem.
- Add a custom transform in Pandas to convert data type of columns from “object” type to numeric type:
- Fill the missing value as 0 for
has_hypertension,has_diabetes,has_coronary,has_smoke,has_atrial. - Choose the Analysis tab.
- For Analysis type¸ choose Histogram.
- For X axis, choose has_heartfailure.
- Choose Run.
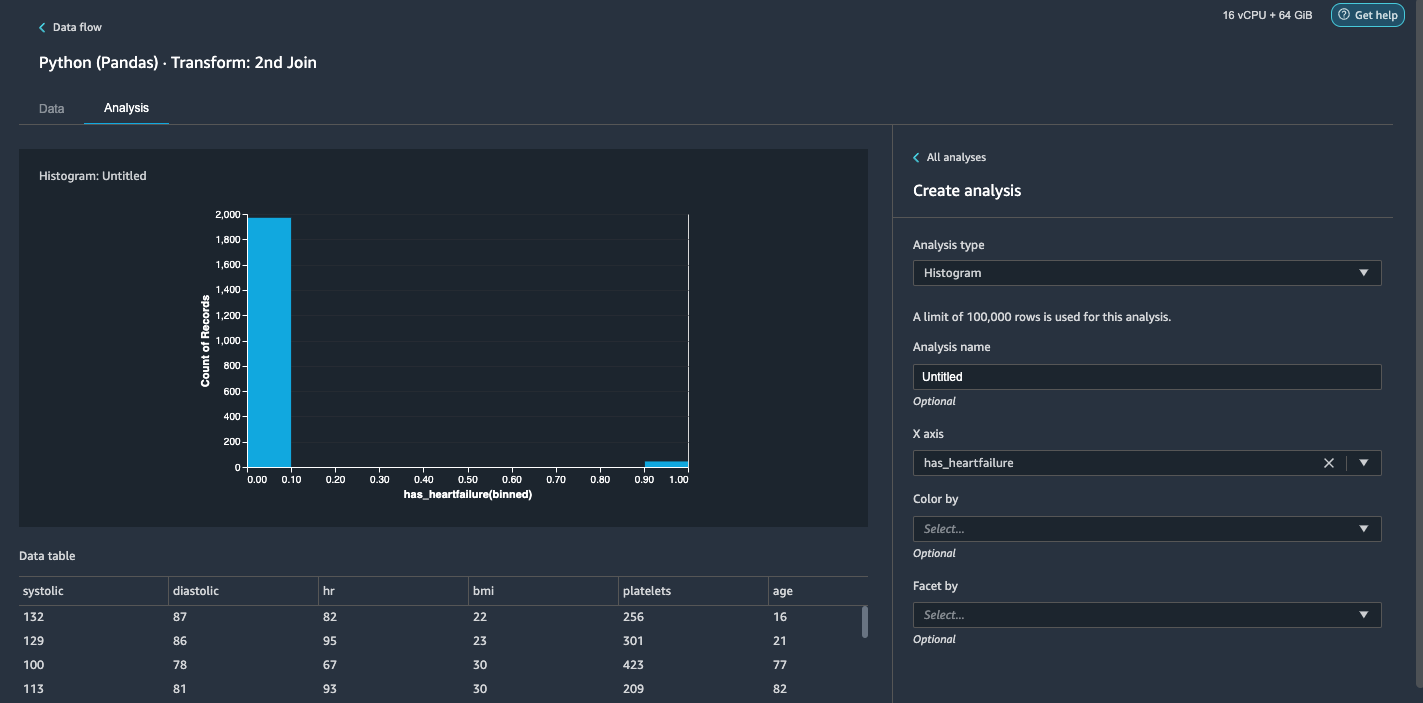
It’s obvious that we have an imbalanced class (more data points labeled as no heart failure than data points labeled as heart failure). - Go back to the Data tab. Choose Add step and choose Balance data.
- For Target column, choose has_heartfailure.
- For Desired ratio, enter
1. - For Transform, choose SMOTE.
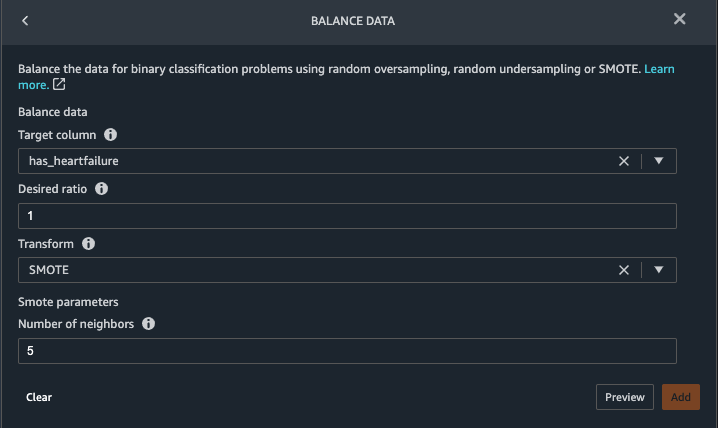
SMOTE stands for Synthetic Minority Over-sampling Technique. It’s a technique to create new minority instances and add to the dataset to reach class balance. For detailed information, refer to SMOTE: Synthetic Minority Over-sampling Technique. - Choose Preview, then choose Add.
- Repeat the histogram analysis in step 20-23. The result is a balanced class.

Visualize target leakage and feature correlation
Next, we’re going to perform a few visual analyses using Data Wrangler’s rich toolset of advanced ML-supported analysis types. First, we look at target leakage. Target leakage occurs when data in the training dataset is strongly correlated with the target label, but isn’t available in real-world data at inference time.
- On the Analysis tab, for Analysis type¸ choose Target Leakage.
- For Problem Type, choose classification.
- For Target, choose has_heartfailure.
- Choose Run.
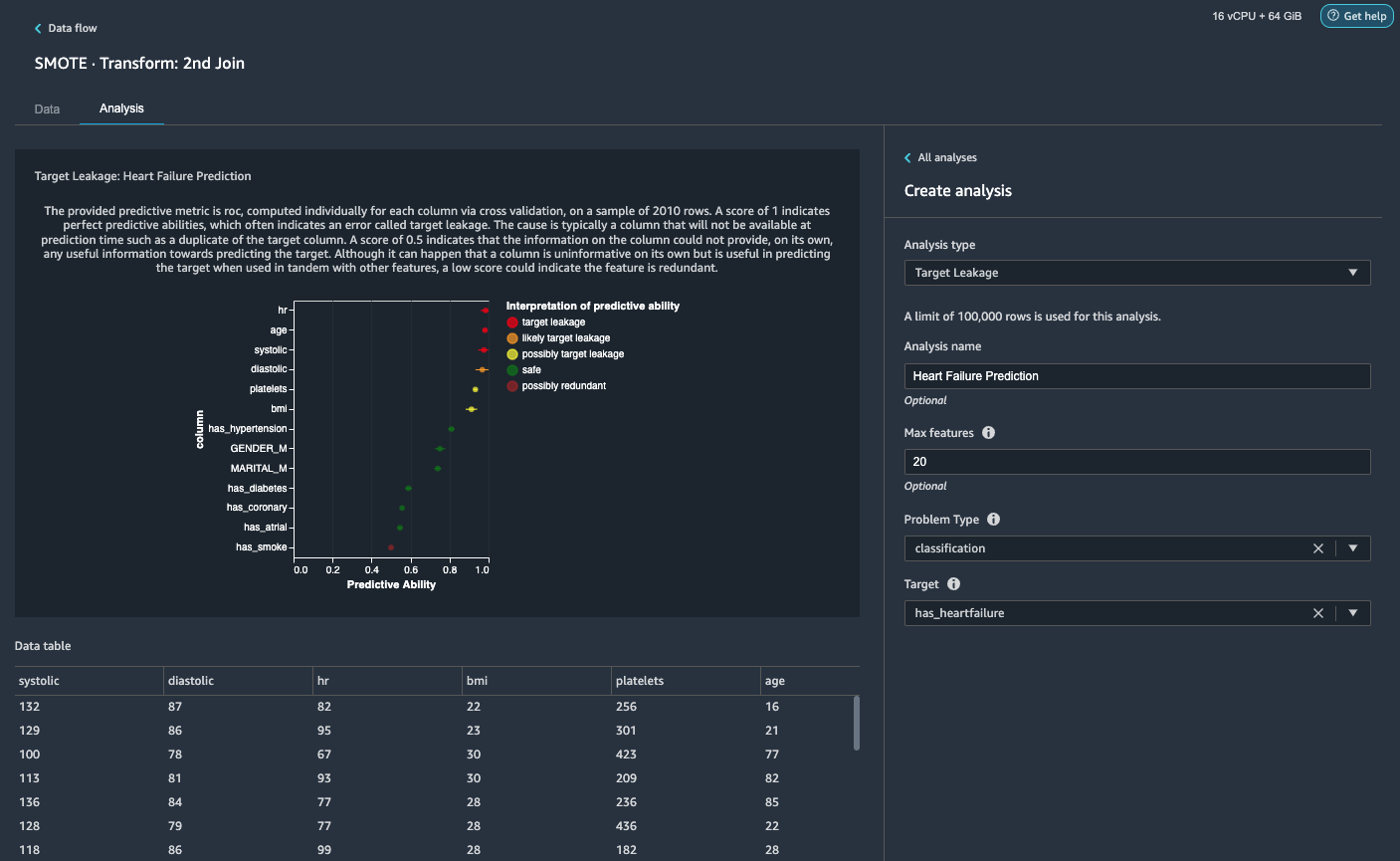
Based on the analysis,hris a target leakage. We’ll drop it in a subsequent step.ageis flagged a target leakage. It’s reasonable to say that a patient’s age will be available during inference time, so we keep age as a feature.Systolicanddiastolicare also flagged as likely target leakage. We expect to have the two measurements during inference time, so we keep them as features.
Then, we look at feature correlation. We want to select features that are correlated with the target but are uncorrelated among themselves.
- On the Analysis tab, for Analysis type¸ choose Feature Correlation.
- For Correlation Type¸ choose linear.
- Choose Run.
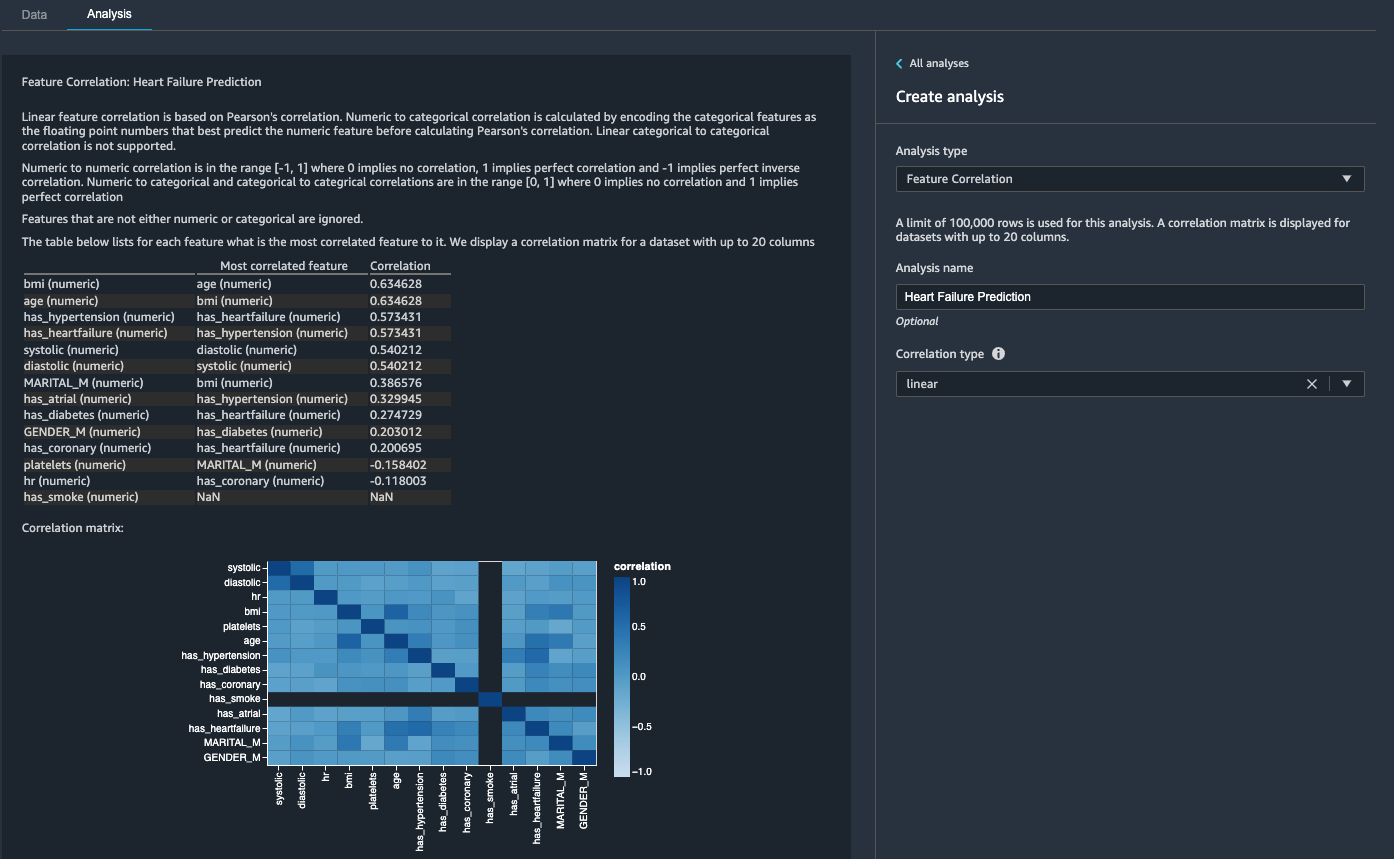
The coefficient scores indicate strong correlations between the following pairs:
systolicanddiastolicbmiandagehas_hypertensionandhas_heartfailure(label)
For features that are strongly correlated, matrices are computationally difficult to invert, which can lead to numerically unstable estimates. To mitigate the correlation, we can simply remove one from the pair. We drop diastolic and bmi and keep systolic and age in a subsequent step.
Drop diastolic and bmi columns
Add additional transform steps to drop the hr, diastolic and bmi columns using the built-in transform.
Generate the Data Quality and Insights Report
AWS recently announced the new Data Quality and Insights Report feature in Data Wrangler. This report automatically verifies data quality and detects abnormalities in your data. This will also create a Quick model, which provides an estimate of the expected predicted quality of a model that you training on your data. Data scientists and data engineers can use this tool to efficiently and quickly apply domain knowledge to process datasets for ML model training. This step is optional. To generate this report on our datasets, complete the following steps:
- On the Analysis tab, for Analysis type, choose Data Quality and Insights Report.
- For Target column, choose has_heartfailure.
- For Problem type, select Classification.
- Choose Create.

In a few minutes, it generates a report with a summary, visuals, and recommendations.

As per our FEATURE SUMMARY, we can see the features age and systolic have the highest feature importance scores among all features.
Export the data and train the model
Now let’s export the transformed ML-ready features to a destination S3 bucket and scale the entire feature engineering pipeline we have created so far using the samples into the entire dataset in a distributed fashion.
Choose the plus sign next to the last box in the data flow and choose Add destination.
Choose Amazon S3.

Enter a Dataset name. For Amazon S3 location, choose a S3 bucket, then choose Add Destination.
Choose Create job to launch a distributed PySpark processing job to perform the transformation and output the data to the destination S3 bucket.
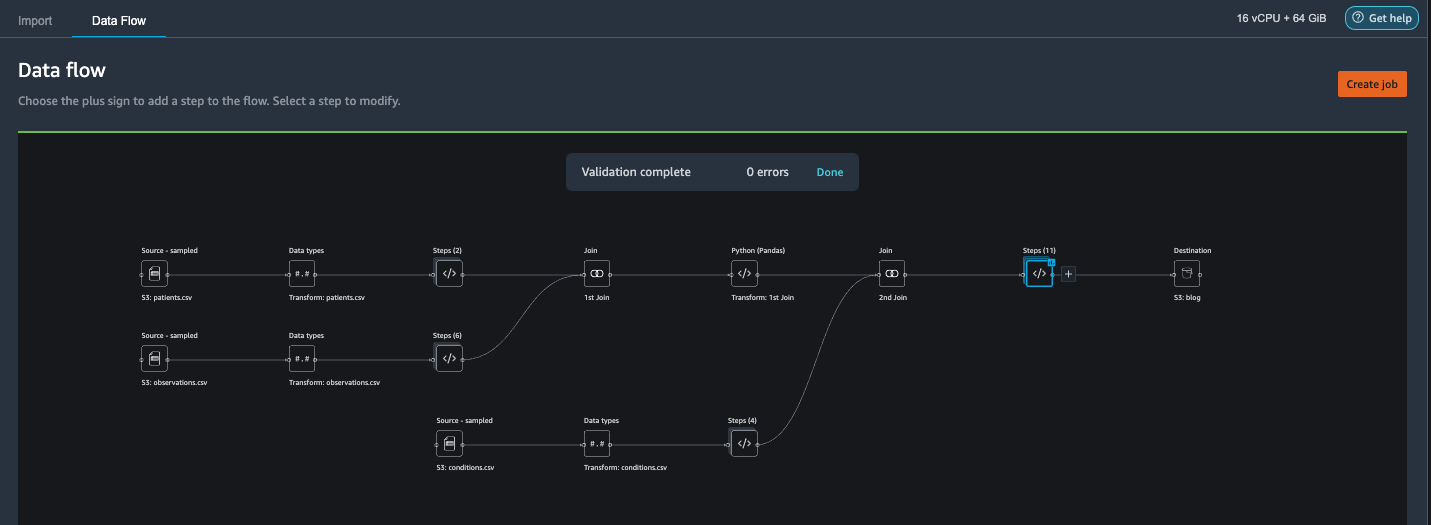
Depending on the size of the datasets, this option lets us easily configure the cluster and horizontally scale in a no-code fashion. We don’t have to worry about partitioning the datasets or managing the cluster and Spark internals. All of this is automatically taken care for us by Data Wrangler.
On the left pane, choose Next, 2. Configure job.
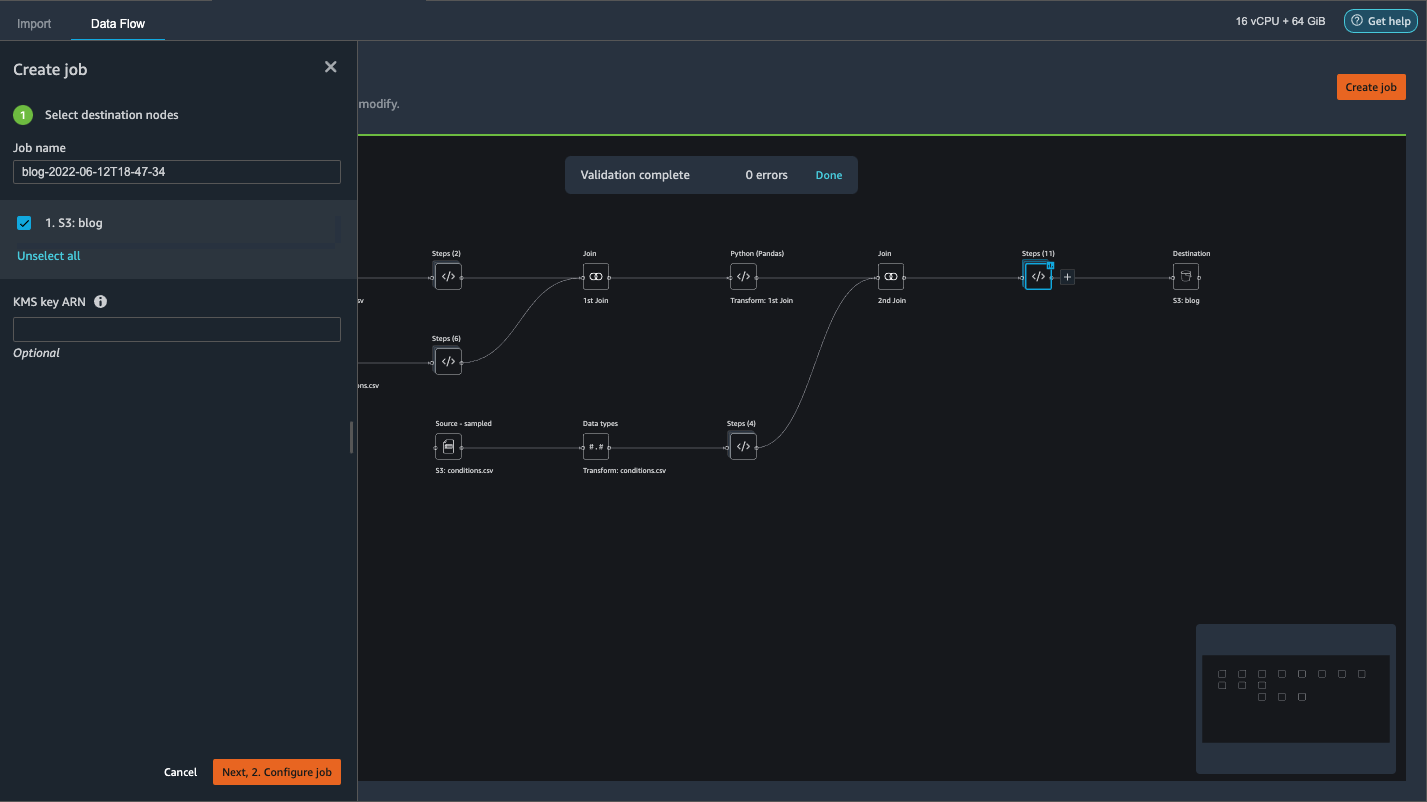
Then choose Run.

Alternatively, we can also export the transformed output to S3 via a Jupyter Notebook. With this approach, Data Wrangler automatically generates a Jupyter notebook with all the code needed to kick-off a processing job to apply the data flow steps (created using a sample) on the larger full dataset and use the transformed dataset as features to kick-off a training job later. The notebook code can be readily run with or without making changes. Let’s now walk through the steps on how to get this done via Data Wrangler’s UI.
Choose the plus sign next to the last step in the data flow and choose Export to.
Choose Amazon S3 (via Jupyter Notebook).
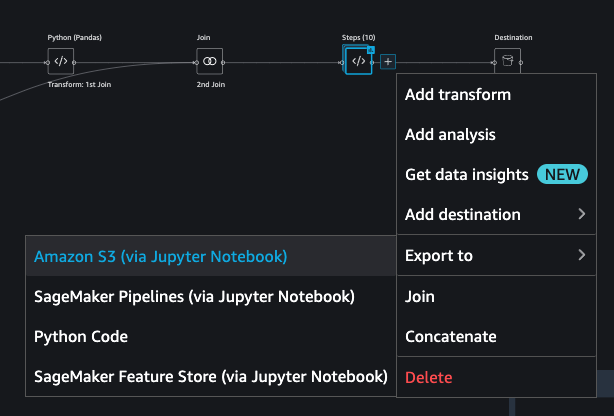
It automatically opens a new tab with a Jupyter notebook.
In the Jupyter notebook, locate the cell in the (Optional) Next Steps section and change run_optional_steps from False to True.
The enabled optional steps in the notebook perform the following:
Train a model using XGBoost

Go back to the top of the notebook and on the Run menu, choose Run All Cells.
If you use the generated notebook as is, it launches a SageMaker processing job that scales out the processing across two m5.4xlarge instances to processes the full dataset on the S3 bucket. You can adjust the number of instances and instance types based on the dataset size and time you need to complete the job.
Wait until the training job from the last cell is complete. It generates a model in the SageMaker default S3 bucket.
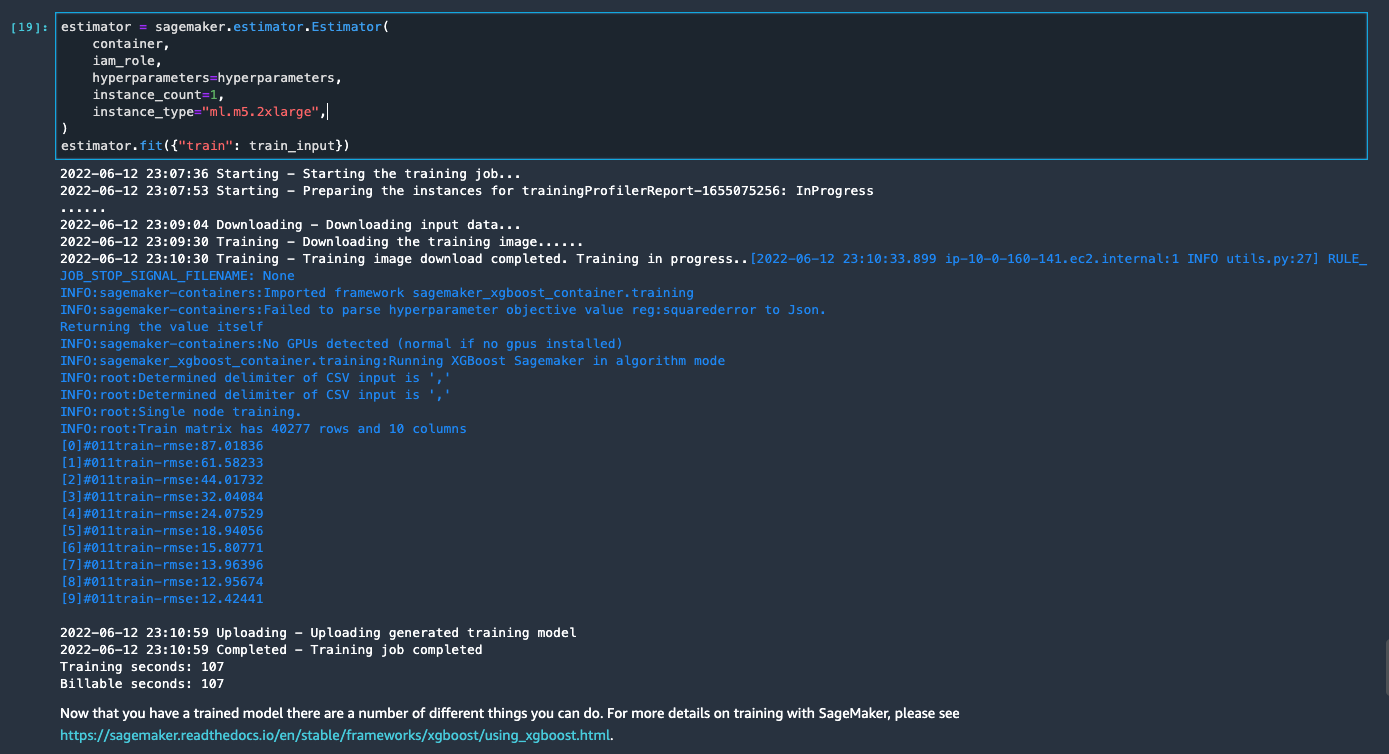
The trained model is ready for deployment for either real-time inference or batch transformation. Note that we used synthetic data to demonstrate functionalities in Data Wrangler and used processed data for training model. Given that the data we used is synthetic, the inference result from the trained model is not meant for real-world medical condition diagnosis or substitution of judgment from medical practitioners.
You can also directly export your transformed dataset into Amazon S3 by choosing Export on top of the transform preview page. The direct export option only exports the transformed sample if sampling was enabled during the import. This option is best suited if you’re dealing with smaller datasets. The transformed data can also be ingested directly into a feature store. For more information, refer to Amazon SageMaker Feature Store. The data flow can also be exported as a SageMaker pipeline that can be orchestrated and scheduled as per your requirements. For more information, see Amazon SageMaker Pipelines.
Conclusion
In this post, we showed how to use Data Wrangler to process healthcare data and perform scalable feature engineering in a tool-driven, low-code fashion. We learned how to apply the built-in transformations and analyses aptly wherever needed, combining it with custom transformations to add even more flexibility to our data preparation workflow. We also walked through the different options for scaling out the data flow recipe via distributed processing jobs. We also learned how the transformed data can be easily used for training a model to predict heart failure.
There are many other features in Data Wrangler we haven’t covered in this post. Explore what’s possible in Prepare ML Data with Amazon SageMaker Data Wrangler and learn how to leverage Data Wrangler for your next data science or machine learning project.
About the Authors
 Forrest Sun is a Senior Solution Architect with the AWS Public Sector team in Toronto, Canada. He has worked in the healthcare and finance industries for the past two decades. Outside of work, he enjoys camping with his family.
Forrest Sun is a Senior Solution Architect with the AWS Public Sector team in Toronto, Canada. He has worked in the healthcare and finance industries for the past two decades. Outside of work, he enjoys camping with his family.
 Arunprasath Shankar is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
Arunprasath Shankar is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
 Thaddeus Worsnop is a solutions architect at Amazon Web Services (AWS). He has over 20 years of experience in information technology. At AWS, Thaddeus helps large enterprise organizations develop, implement, and optimize cloud services and strategy. Thaddeus is currently focusing on low-code and no-code technologies that help democratize machine learning.
Thaddeus Worsnop is a solutions architect at Amazon Web Services (AWS). He has over 20 years of experience in information technology. At AWS, Thaddeus helps large enterprise organizations develop, implement, and optimize cloud services and strategy. Thaddeus is currently focusing on low-code and no-code technologies that help democratize machine learning.