Artificial Intelligence
Discover insights from Zendesk with Amazon Kendra intelligent search
Customer relationship management (CRM) is a critical tool that organizations maintain to manage customer interactions and build business relationships. Zendesk is a CRM tool that makes it easy for customers and businesses to keep in sync. Zendesk captures a wealth of customer data, such as support tickets created and updated by customers and service agents, community discussions, and helpful guides. With such a wealth of complex data, simple keyword searches don’t suffice when it comes to discovering meaningful, accurate customer information.
Now you can use the Amazon Kendra Zendesk connector to index your Zendesk service tickets, help guides, and community posts, and perform intelligent search powered by machine learning (ML). Amazon Kendra smartly and efficiently answers natural language-based queries using advanced natural language processing (NLP) techniques. It can learn effectively from your Zendesk data, extracting meaning and context.
This post shows how to configure the Amazon Kendra Zendesk connector to index your Zendesk domain and take advantage of Amazon Kendra intelligent search. We use an example of an illustrative Zendesk domain to discuss technical topics related to AWS services.
Overview of solution
Amazon Kendra was built for intelligent search using NLP. You can use Amazon Kendra to ask factoid questions, descriptive questions, and perform keyword searches. You can use the Amazon Kendra connector for Zendesk to crawl your Zendesk domain and index service tickets, guides, and community posts to discover answers for your questions faster.
In this post, we show how to use the Amazon Kendra connector for Zendesk to index data from your Zendesk domain for intelligent search.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account
- Administrator level access to your Zendesk domain
- Privileges to create an Amazon Kendra index, AWS resources, and AWS Identity and Access Management (IAM) roles and policies
- Basic knowledge of AWS services and working knowledge of Zendesk
Configure your Zendesk domain
Your Zendesk domain has a domain owner or administrator, service group administrators, and a customer. Sample service tickets, community posts, and guides have been created for the purpose of this walkthrough. A Zendesk API client with the unique identifier amazon_kendra is registered to create an OAuth token for accessing your Zendesk domain from Amazon Kendra for crawling and indexing. The following screenshot shows the details of the OAuth configuration for the Zendesk API client.

Configure the data source using the Amazon Kendra connector for Zendesk
You can add the Zendesk connector data source to an existing Amazon Kendra index or create a new index. Then complete the following steps to configure the Zendesk connector:
- On the Amazon Kendra console, open the index and choose Data sources in the navigation pane.
- Under Zendesk, choose Add connector.
- Choose Add connector.
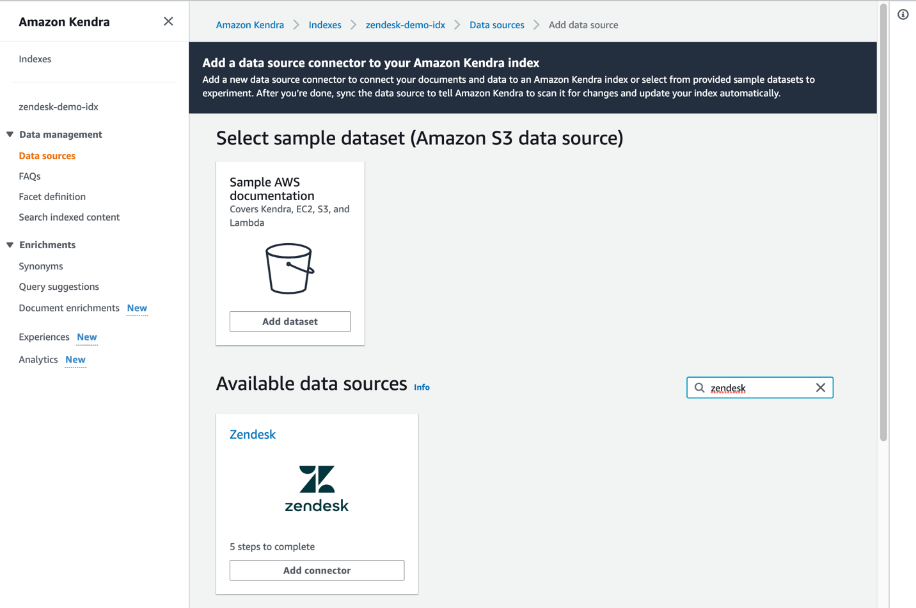
- In the Specify data source details section, enter the name and description of your data source and choose Next.
- In the Define access and security section, for Zendesk URL, enter the URL to your Zendesk domain. Use the URL format
https://<domain>.zendesk.com/. - Under Authentication, you can either choose Create to add a new secret using the user OAuth token created for the
amazon_kendra, or use an existing AWS Secrets Manager secret that has the user OAuth token for the Zendesk domain that you want the connector to access. - Optionally, configure a new AWS secret for Zendesk API access.

- For IAM role, you can choose Create a new role or choose an existing IAM role configured with appropriate IAM policies to access the Secrets Manager secret, Amazon Kendra index, and data source.
- Choose Next.

- In the Configure sync settings section, provide information regarding your sync scope and run schedule.
- Choose Next.

- In the Set field mappings section, you can optionally configure the field mappings, or how the Zendesk field names are mapped to Amazon Kendra attributes or facets.
- Choose Next.
- Review your settings and confirm to add the data source.
- After the data source is created, select the data source and choose Sync Now.
- Choose Facet definition in the navigation pane.
- Select the check box in the
Facetablecolumn for the facet_category.
Run queries with the Amazon Kendra search console
Now that the data is synced, we can run a few search queries on the Amazon Kendra search console by navigating to the Search indexed content page.
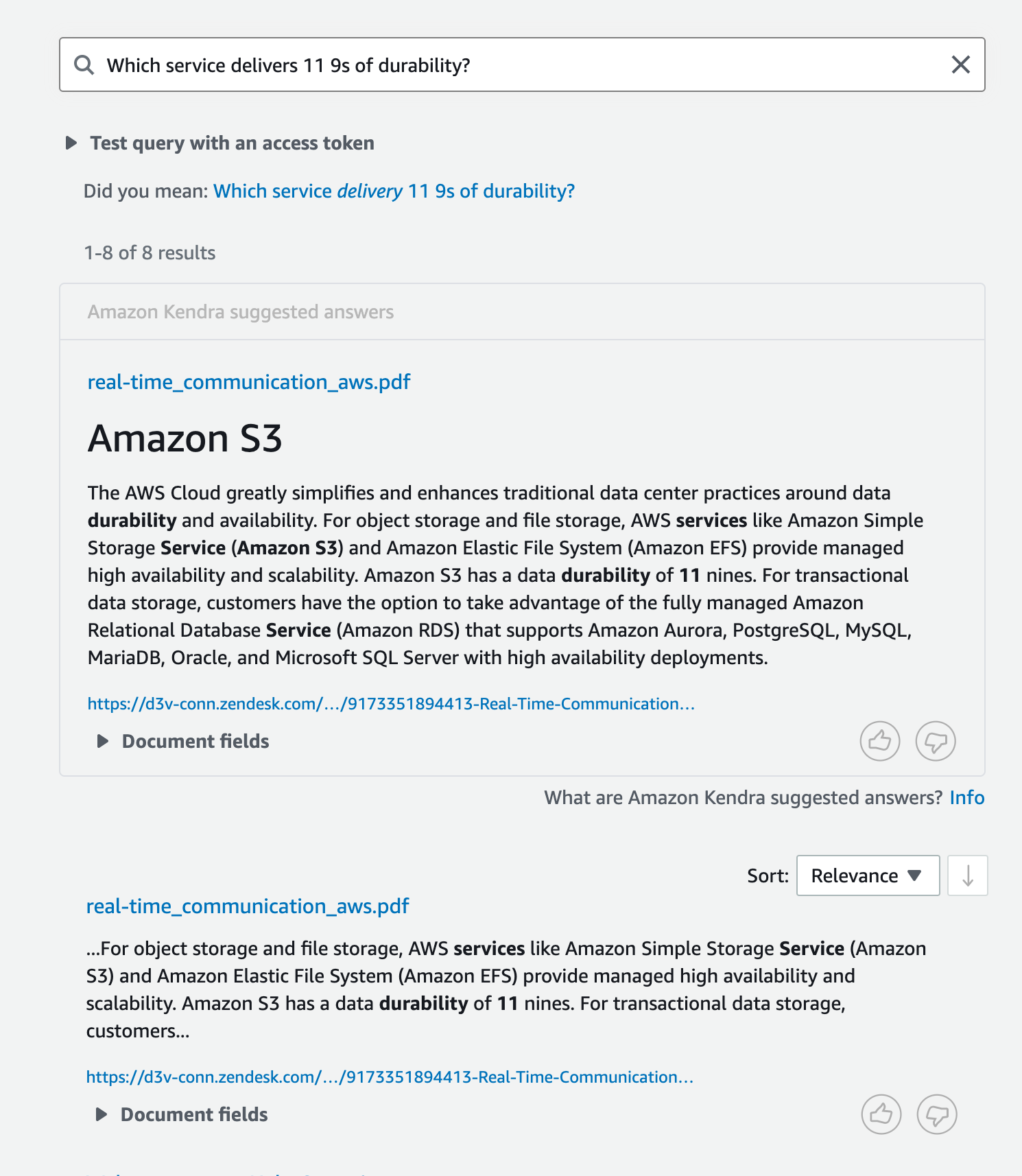
For the first query, we ask Amazon Kendra a general question related to AWS service durability. The following screenshot shows the response. The suggested answer provides the correct answer to the query by applying natural language comprehension.
For our second query, let’s query Amazon Kendra to search for product issues from Zendesk service tickets. The following screenshot shows the response for the search, along with facets showing various categories of documents included in the result.
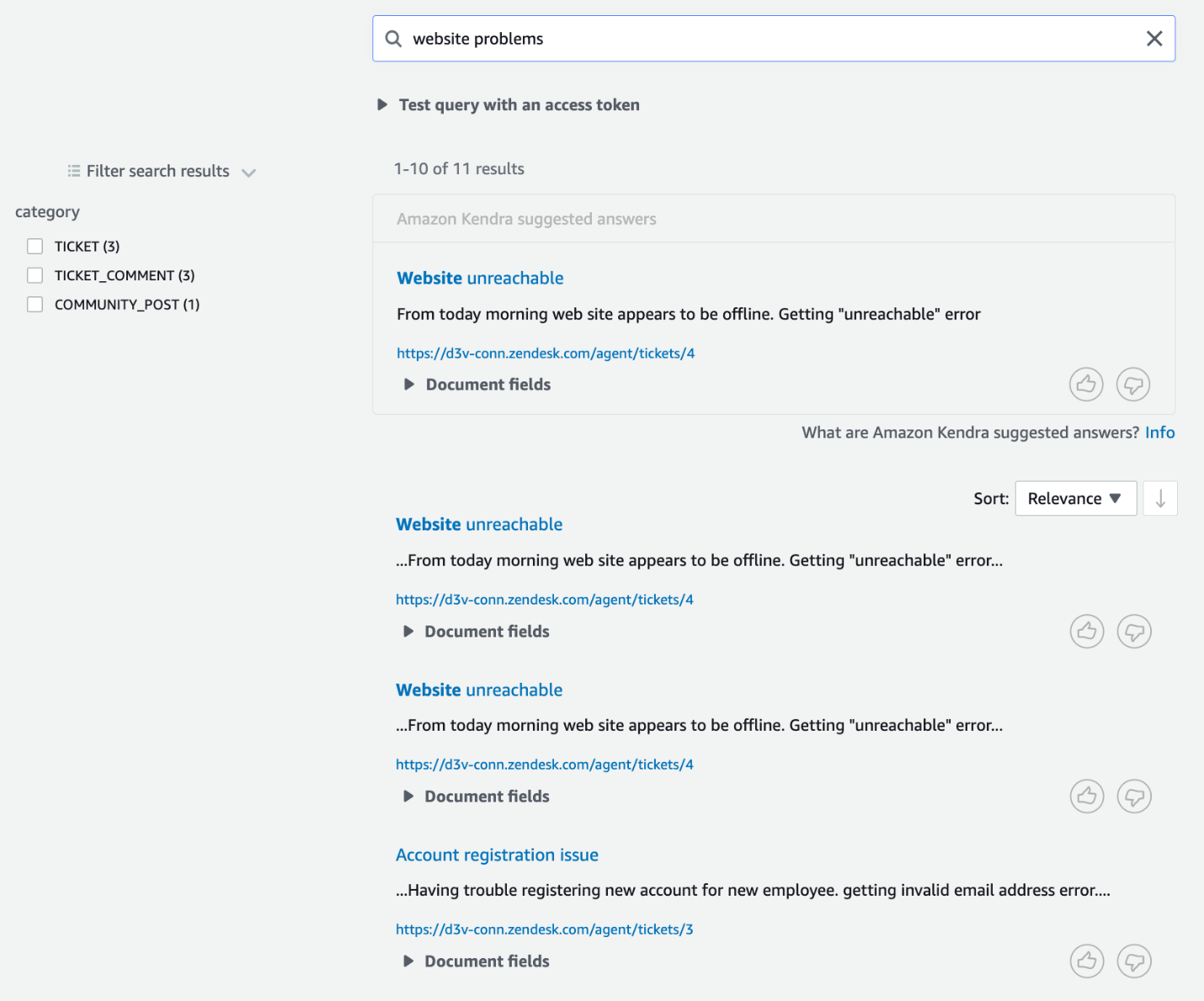
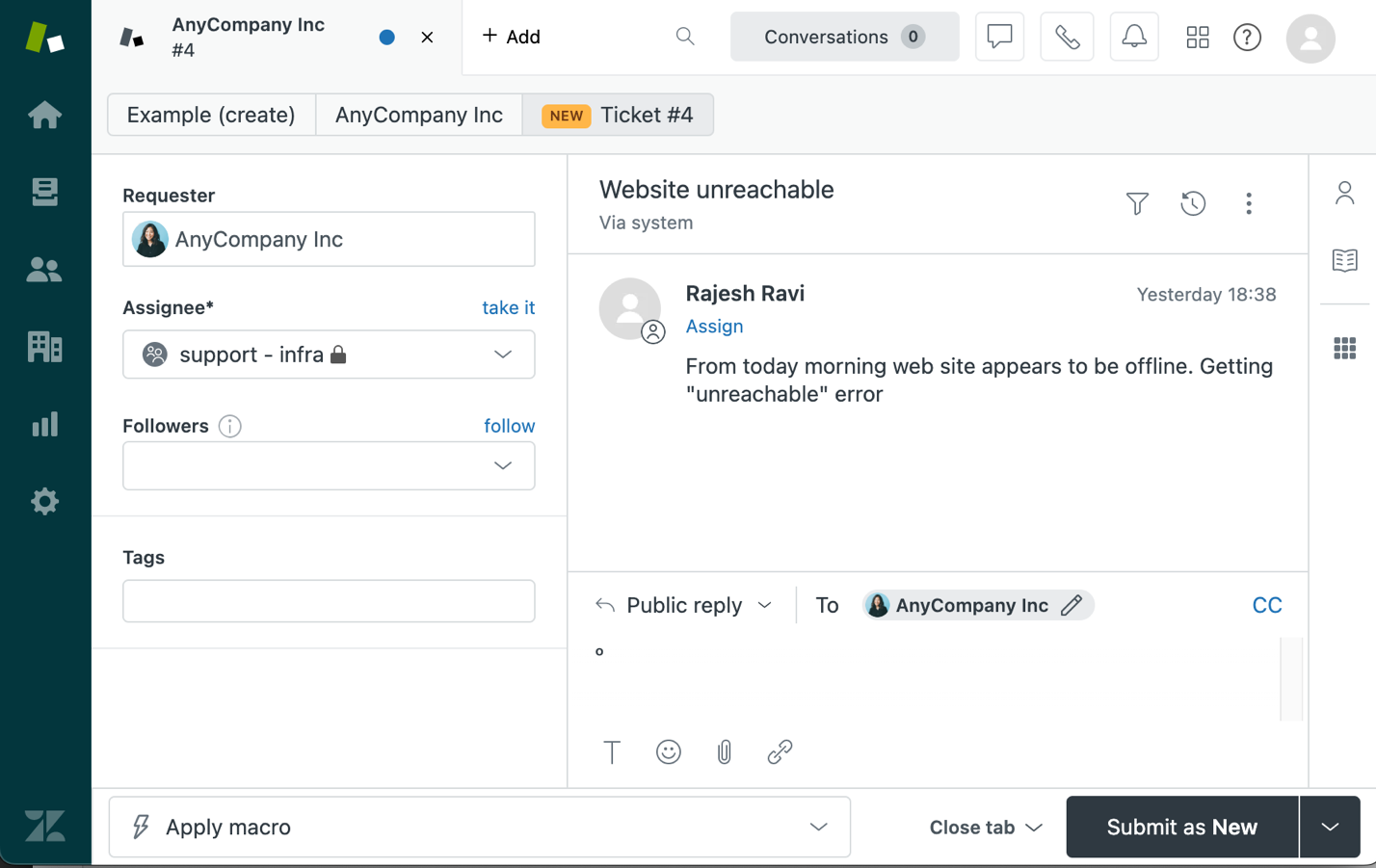
Notice the search result includes the URL to the source document as well. Choosing the URL takes us directly to the Zendesk service ticket page, as shown in the following screenshot.
Clean up
To avoid incurring future charges, clean up any resources created as part of this solution. Delete the Zendesk connector data source so any data indexed from the source is removed from the index. If you created a new Amazon Kendra index, delete the index as well.
Conclusion
In this post, we discussed how to configure the Amazon Kendra connector for Zendesk to crawl and index service tickets, community posts, and help guides. We showed how Amazon Kendra ML-based search enables your business leaders and agents to discover insights from your Zendesk content quicker and respond to customer needs faster.
To learn more about the Amazon Kendra connector for Zendesk, refer to the Amazon Kendra Developer Guide.
About the author
 Rajesh Kumar Ravi is a Senior AI Services Solution Architect at Amazon Web Services specializing in intelligent document search with Amazon Kendra. He is a builder and problem solver, and contributes to the development of new ideas. He enjoys walking and loves to go on short hiking trips outside of work.
Rajesh Kumar Ravi is a Senior AI Services Solution Architect at Amazon Web Services specializing in intelligent document search with Amazon Kendra. He is a builder and problem solver, and contributes to the development of new ideas. He enjoys walking and loves to go on short hiking trips outside of work.