Artificial Intelligence
Category: Amazon SageMaker
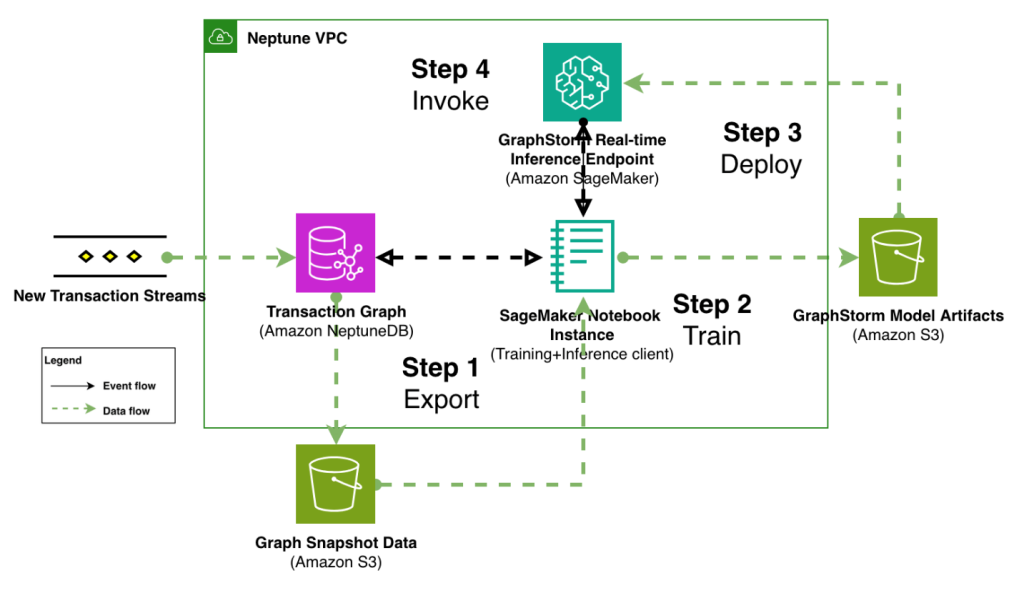
Modernize fraud prevention: GraphStorm v0.5 for real-time inference
In this post, we demonstrate how to implement real-time fraud prevention using GraphStorm v0.5’s new capabilities for deploying graph neural network (GNN) models through Amazon SageMaker. We show how to transition from model training to production-ready inference endpoints with minimal operational overhead, enabling sub-second fraud detection on transaction graphs with billions of nodes and edges.

Rapid ML experimentation for enterprises with Amazon SageMaker AI and Comet
In this post, we showed how to use SageMaker and Comet together to spin up fully managed ML environments with reproducibility and experiment tracking capabilities.

Scale visual production using Stability AI Image Services in Amazon Bedrock
This post was written with Alex Gnibus of Stability AI. Stability AI Image Services are now available in Amazon Bedrock, offering ready-to-use media editing capabilities delivered through the Amazon Bedrock API. These image editing tools expand on the capabilities of Stability AI’s Stable Diffusion 3.5 models (SD3.5) and Stable Image Core and Ultra models, which […]

Prompting for precision with Stability AI Image Services in Amazon Bedrock
Amazon Bedrock now offers Stability AI Image Services: 9 tools that improve how businesses create and modify images. The technology extends Stable Diffusion and Stable Image models to give you precise control over image creation and editing. Clear prompts are critical—they provide art direction to the AI system. Strong prompts control specific elements like tone, […]
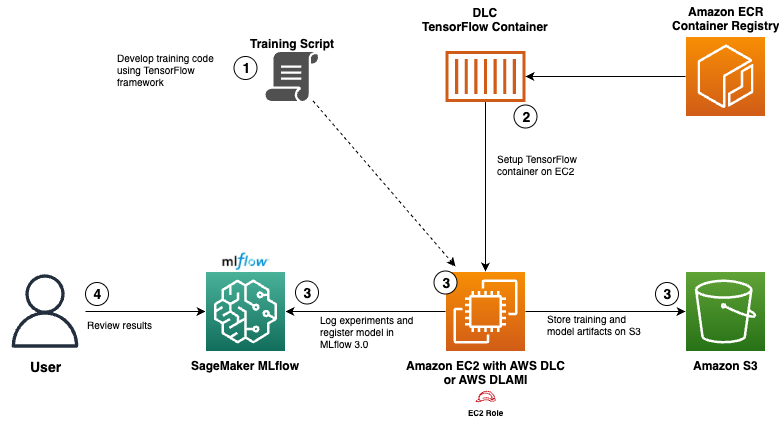
Use AWS Deep Learning Containers with Amazon SageMaker AI managed MLflow
In this post, we show how to integrate AWS DLCs with MLflow to create a solution that balances infrastructure control with robust ML governance. We walk through a functional setup that your team can use to meet your specialized requirements while significantly reducing the time and resources needed for ML lifecycle management.

Build Agentic Workflows with OpenAI GPT OSS on Amazon SageMaker AI and Amazon Bedrock AgentCore
In this post, we show how to deploy gpt-oss-20b model to SageMaker managed endpoints and demonstrate a practical stock analyzer agent assistant example with LangGraph, a powerful graph-based framework that handles state management, coordinated workflows, and persistent memory systems.
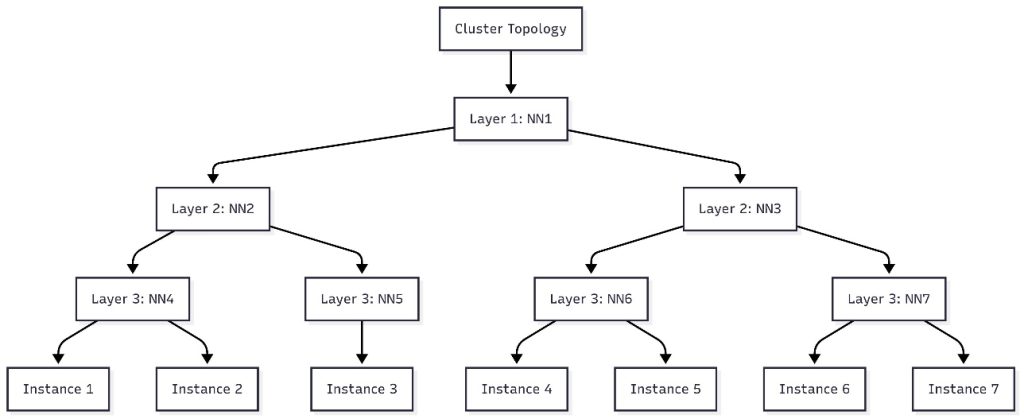
Schedule topology-aware workloads using Amazon SageMaker HyperPod task governance
In this post, we introduce topology-aware scheduling with SageMaker HyperPod task governance by submitting jobs that represent hierarchical network information. We provide details about how to use SageMaker HyperPod task governance to optimize your job efficiency.
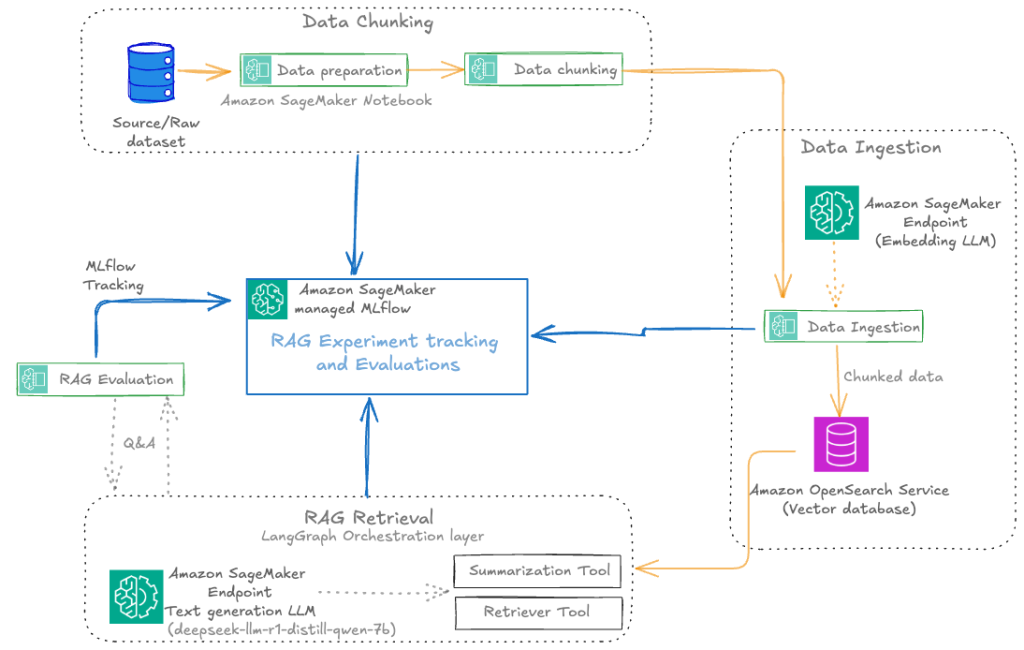
Automate advanced agentic RAG pipeline with Amazon SageMaker AI
In this post, we walk through how to streamline your RAG development lifecycle from experimentation to automation, helping you operationalize your RAG solution for production deployments with Amazon SageMaker AI, helping your team experiment efficiently, collaborate effectively, and drive continuous improvement.
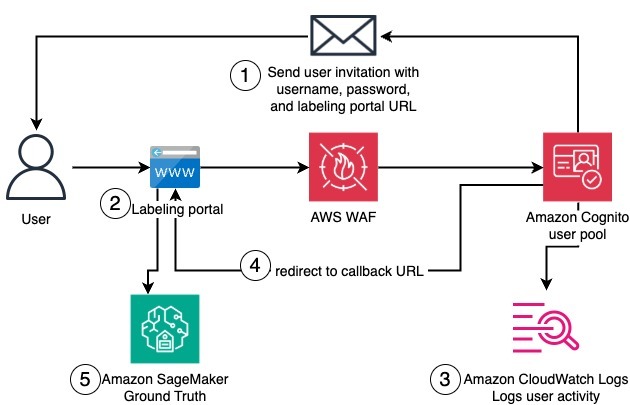
Create a private workforce on Amazon SageMaker Ground Truth with the AWS CDK
In this post, we present a complete solution for programmatically creating private workforces on Amazon SageMaker AI using the AWS Cloud Development Kit (AWS CDK), including the setup of a dedicated, fully configured Amazon Cognito user pool.

Powering innovation at scale: How AWS is tackling AI infrastructure challenges
As generative AI continues to transform how enterprises operate—and develop net new innovations—the infrastructure demands for training and deploying AI models have grown exponentially. Traditional infrastructure approaches are struggling to keep pace with today’s computational requirements, network demands, and resilience needs of modern AI workloads. At AWS, we’re also seeing a transformation across the technology […]