Artificial Intelligence
Category: Amazon SageMaker
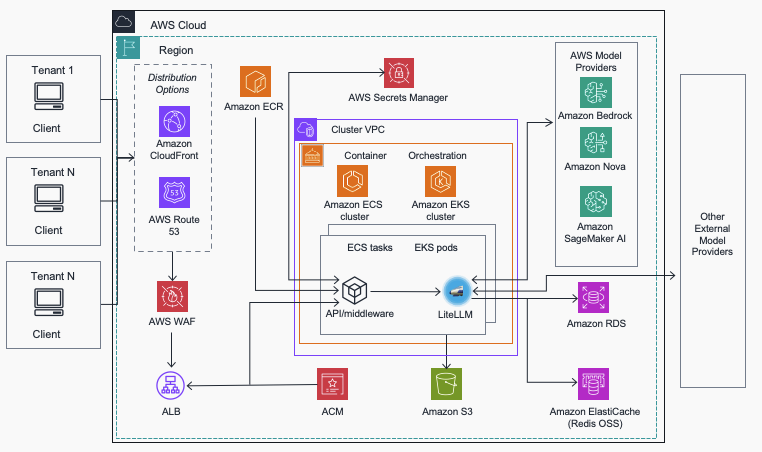
Streamline AI operations with the Multi-Provider Generative AI Gateway reference architecture
In this post, we introduce the Multi-Provider Generative AI Gateway reference architecture, which provides guidance for deploying LiteLLM into an AWS environment to streamline the management and governance of production generative AI workloads across multiple model providers. This centralized gateway solution addresses common enterprise challenges including provider fragmentation, decentralized governance, operational complexity, and cost management by offering a unified interface that supports Amazon Bedrock, Amazon SageMaker AI, and external providers while maintaining comprehensive security, monitoring, and control capabilities.

Deploy geospatial agents with Foursquare Spatial H3 Hub and Amazon SageMaker AI
In this post, you’ll learn how to deploy geospatial AI agents that can answer complex spatial questions in minutes instead of months. By combining Foursquare Spatial H3 Hub’s analysis-ready geospatial data with reasoning models deployed on Amazon SageMaker AI, you can build agents that enable nontechnical domain experts to perform sophisticated spatial analysis through natural language queries—without requiring geographic information system (GIS) expertise or custom data engineering pipelines.
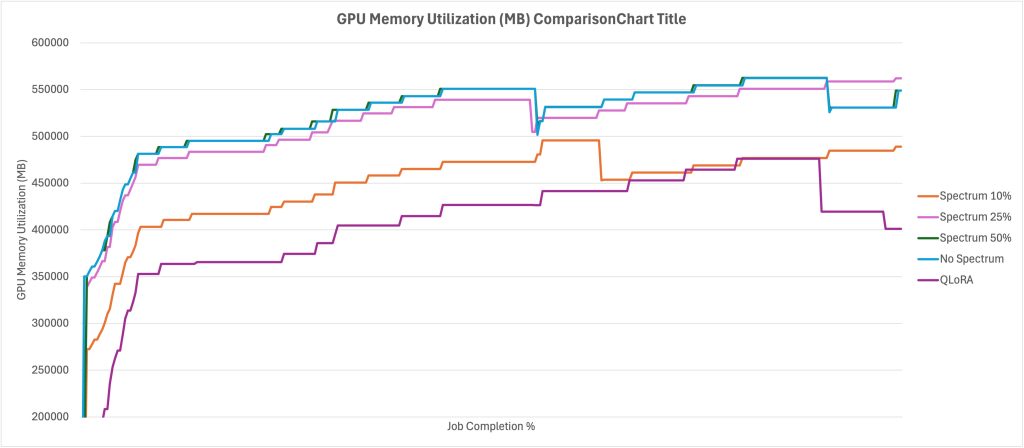
Using Spectrum fine-tuning to improve FM training efficiency on Amazon SageMaker AI
In this post you will learn how to use Spectrum to optimize resource use and shorten training times without sacrificing quality, as well as how to implement Spectrum fine-tuning with Amazon SageMaker AI training jobs. We will also discuss the tradeoff between QLoRA and Spectrum fine-tuning, showing that while QLoRA is more resource efficient, Spectrum results in higher performance overall.

Bringing tic-tac-toe to life with AWS AI services
RoboTic-Tac-Toe is an interactive game where two physical robots move around a tic-tac-toe board, with both the gameplay and robots’ movements orchestrated by LLMs. Players can control the robots using natural language commands, directing them to place their markers on the game board. In this post, we explore the architecture and prompt engineering techniques used to reason about a tic-tac-toe game and decide the next best game strategy and movement plan for the current player.

HyperPod enhances ML infrastructure with security and storage
This blog post introduces two major enhancements to Amazon SageMaker HyperPod that strengthen security and storage capabilities for large-scale machine learning infrastructure. The new features include customer managed key (CMK) support for encrypting EBS volumes with organization-controlled encryption keys, and Amazon EBS CSI driver integration that enables dynamic storage management for Kubernetes volumes in AI workloads.
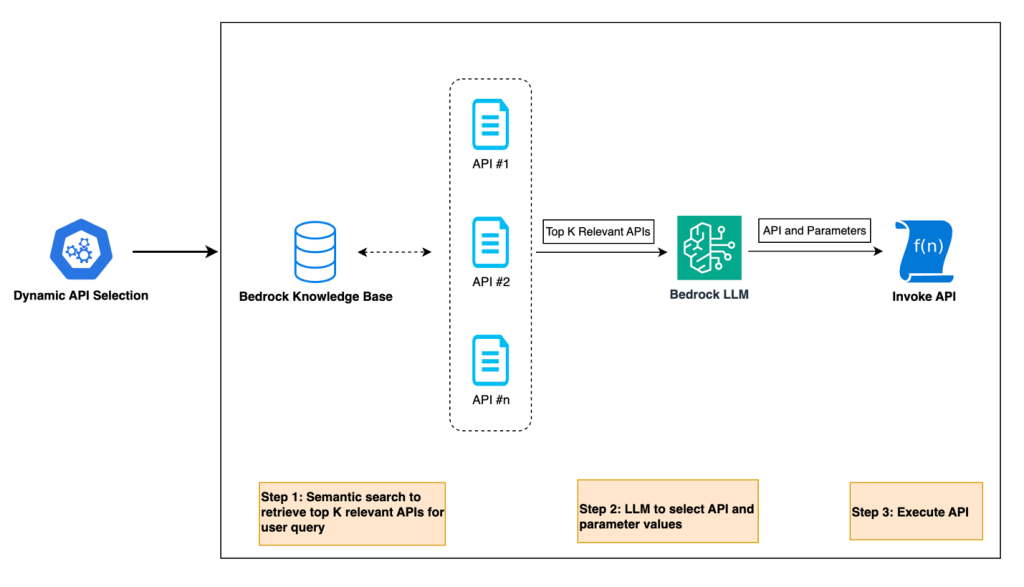
Harnessing the power of generative AI: Druva’s multi-agent copilot for streamlined data protection
Generative AI is transforming the way businesses interact with their customers and revolutionizing conversational interfaces for complex IT operations. Druva, a leading provider of data security solutions, is at the forefront of this transformation. In collaboration with Amazon Web Services (AWS), Druva is developing a cutting-edge generative AI-powered multi-agent copilot that aims to redefine the customer experience in data security and cyber resilience.
Fine-tune VLMs for multipage document-to-JSON with SageMaker AI and SWIFT
In this post, we demonstrate that fine-tuning VLMs provides a powerful and flexible approach to automate and significantly enhance document understanding capabilities. We also demonstrate that using focused fine-tuning allows smaller, multi-modal models to compete effectively with much larger counterparts (98% accuracy with Qwen2.5 VL 3B).
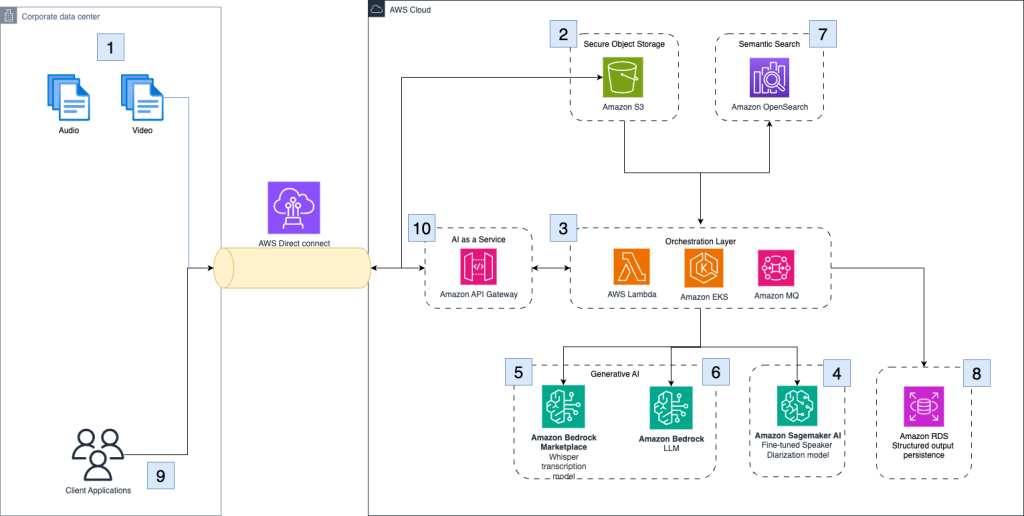
How Clario automates clinical research analysis using generative AI on AWS
In this post, we demonstrate how Clario has used Amazon Bedrock and other AWS services to build an AI-powered solution that automates and improves the analysis of COA interviews.
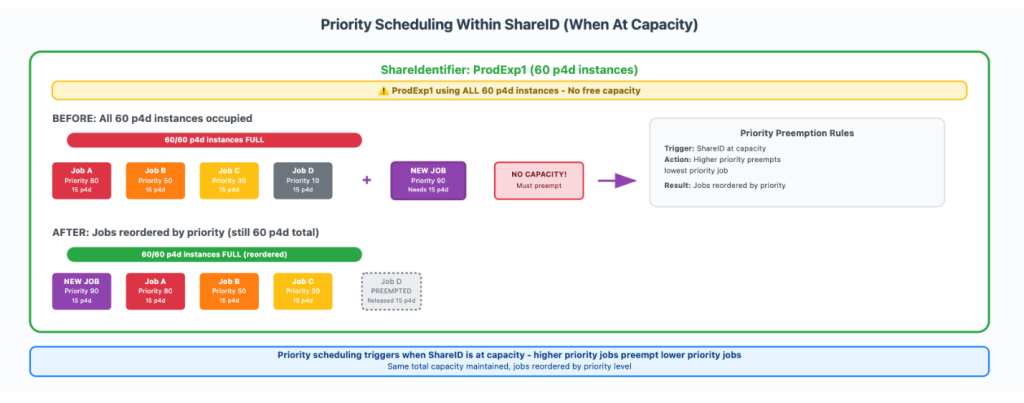
How Amazon Search increased ML training twofold using AWS Batch for Amazon SageMaker Training jobs
In this post, we show you how Amazon Search optimized GPU instance utilization by leveraging AWS Batch for SageMaker Training jobs. This managed solution enabled us to orchestrate machine learning (ML) training workloads on GPU-accelerated instance families like P5, P4, and others. We will also provide a step-by-step walkthrough of the use case implementation.
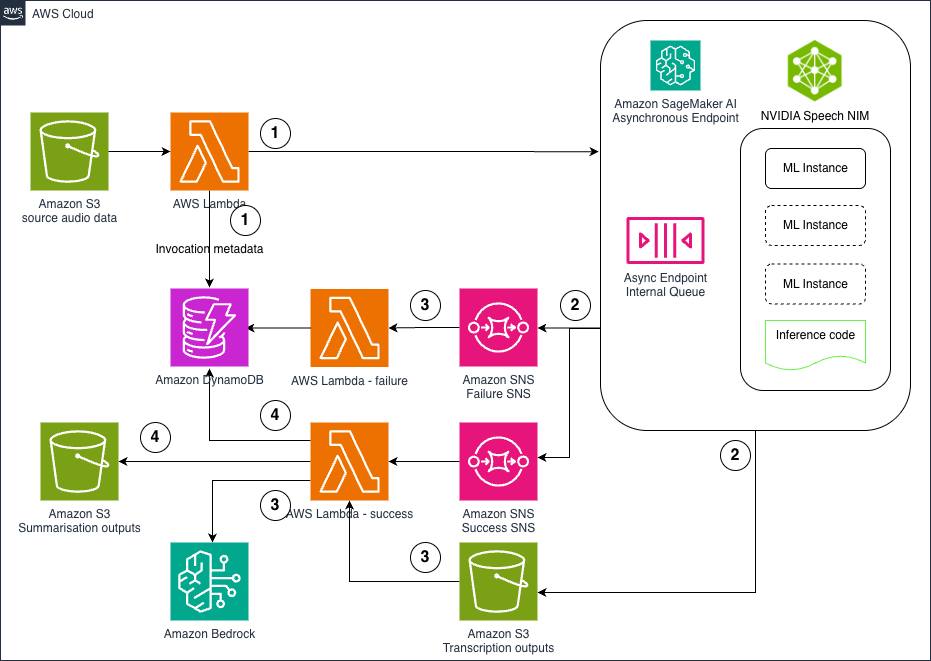
Hosting NVIDIA speech NIM models on Amazon SageMaker AI: Parakeet ASR
In this post, we explore how to deploy NVIDIA’s Parakeet ASR model on Amazon SageMaker AI using asynchronous inference endpoints to create a scalable, cost-effective pipeline for processing large volumes of audio data. The solution combines state-of-the-art speech recognition capabilities with AWS managed services like Lambda, S3, and Bedrock to automatically transcribe audio files and generate intelligent summaries, enabling organizations to unlock valuable insights from customer calls, meeting recordings, and other audio content at scale .