Artificial Intelligence
Category: Amazon SageMaker Autopilot
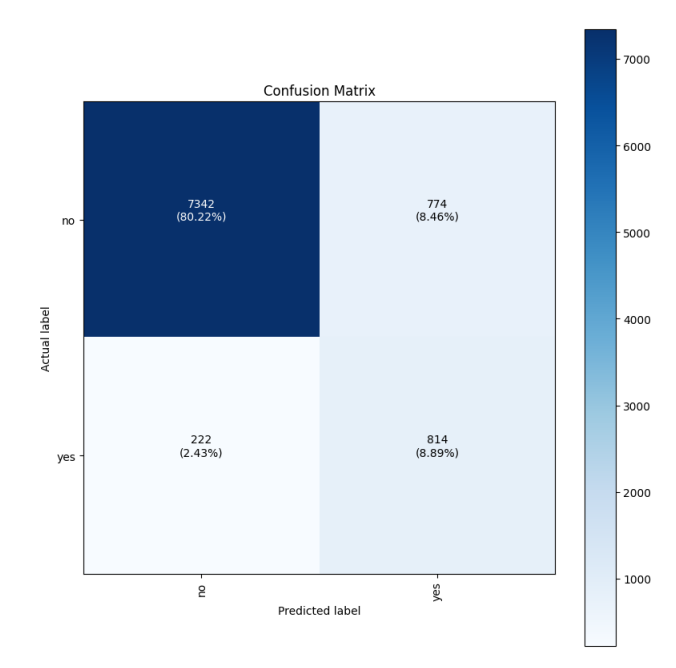
Automatically generate model evaluation metrics using SageMaker Autopilot Model Quality Reports
Amazon SageMaker Autopilot helps you complete an end-to-end machine learning (ML) workflow by automating the steps of feature engineering, training, tuning, and deploying an ML model for inference. You provide SageMaker Autopilot with a tabular data set and a target attribute to predict. Then, SageMaker Autopilot automatically explores your data, trains, tunes, ranks and finds […]

Make batch predictions with Amazon SageMaker Autopilot
March 2025: This post was reviewed and updated for accuracy. Amazon SageMaker Autopilot is an automated machine learning (AutoML) solution that performs all the tasks you need to complete an end-to-end machine learning (ML) workflow. It explores and prepares your data, applies different algorithms to generate a model, and transparently provides model insights and explainability […]

Amazon SageMaker Autopilot now supports time series data
Amazon SageMaker Autopilot automatically builds, trains, and tunes the best machine learning (ML) models based on your data, while allowing you to maintain full control and visibility. We have recently announced support for time series data in Autopilot. You can use Autopilot to tackle regression and classification tasks on time series data, or sequence data […]

Automate a shared bikes and scooters classification model with Amazon SageMaker Autopilot
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Amazon SageMaker Autopilot makes it possible for organizations to quickly build and deploy an end-to-end machine learning (ML) model and inference pipeline with just a few lines of code or even without […]

Run AutoML experiments with large parquet datasets using Amazon SageMaker Autopilot
Starting today, you can use Amazon SageMaker Autopilot to tackle regression and classification tasks on large datasets up to 100 GB. Additionally, you can now provide your datasets in either CSV or Apache Parquet content types. Businesses are generating more data than ever. A corresponding demand is growing for generating insights from these large datasets […]

Add AutoML functionality with Amazon SageMaker Autopilot across accounts
AutoML is a powerful capability, provided by Amazon SageMaker Autopilot, that allows non-experts to create machine learning (ML) models to invoke in their applications. The problem that we want to solve arises when, due to governance constraints, Amazon SageMaker resources can’t be deployed in the same AWS account where they are used. Examples of such […]

Use integrated explainability tools and improve model quality using Amazon SageMaker Autopilot
Whether you are developing a machine learning (ML) model for reducing operating cost, improving efficiency, or improving customer satisfaction, there are no perfect solutions when it comes to producing an effective model. From an ML development perspective, data scientists typically go through stages of data exploration, feature engineering, model development, and model training and tuning […]

Develop and deploy ML models using Amazon SageMaker Data Wrangler and Amazon SageMaker Autopilot
Data generates new value to businesses through insights and building predictive models. However, although data is plentiful, available data scientists are far and few. Despite our attempts in recent years to produce data scientists from academia and elsewhere, we still see a huge shortage that will continue into the near future. To accelerate model building, […]

Creating high-quality machine learning models for financial services using Amazon SageMaker Autopilot
Machine learning (ML) is used throughout the financial services industry to perform a wide variety of tasks, such as fraud detection, market surveillance, portfolio optimization, loan solvency prediction, direct marketing, and many others. This breadth of use cases has created a need for lines of business to quickly generate high-quality and performant models that can […]
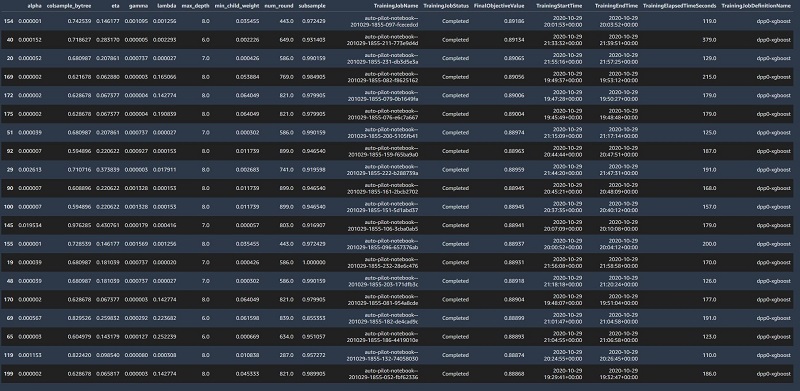
Customizing and reusing models generated by Amazon SageMaker Autopilot
Amazon SageMaker Autopilot automatically trains and tunes the best machine learning (ML) models for classification or regression problems while allowing you to maintain full control and visibility. This not only allows data analysts, developers, and data scientists to train, tune, and deploy models with little to no code, but you can also review a generated […]