Artificial Intelligence
Category: Generative AI
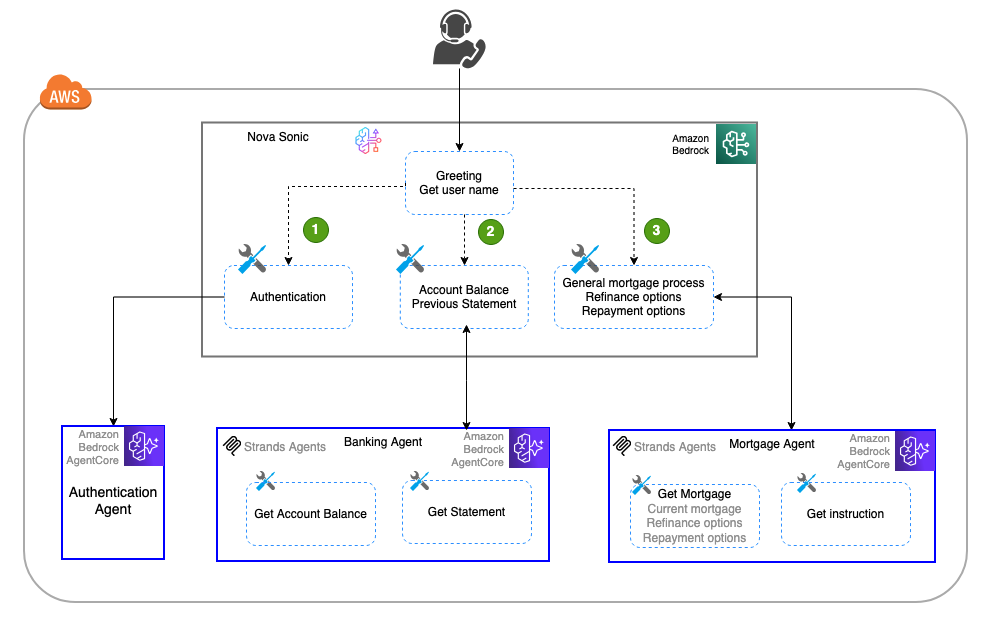
Building a multi-agent voice assistant with Amazon Nova Sonic and Amazon Bedrock AgentCore
In this post, we explore how Amazon Nova Sonic’s speech-to-speech capabilities can be combined with Amazon Bedrock AgentCore to create sophisticated multi-agent voice assistants that break complex tasks into specialized, manageable components. The approach demonstrates how to build modular, scalable voice applications using a banking assistant example with dedicated sub-agents for authentication, banking inquiries, and mortgage services, offering a more maintainable alternative to monolithic voice assistant designs.
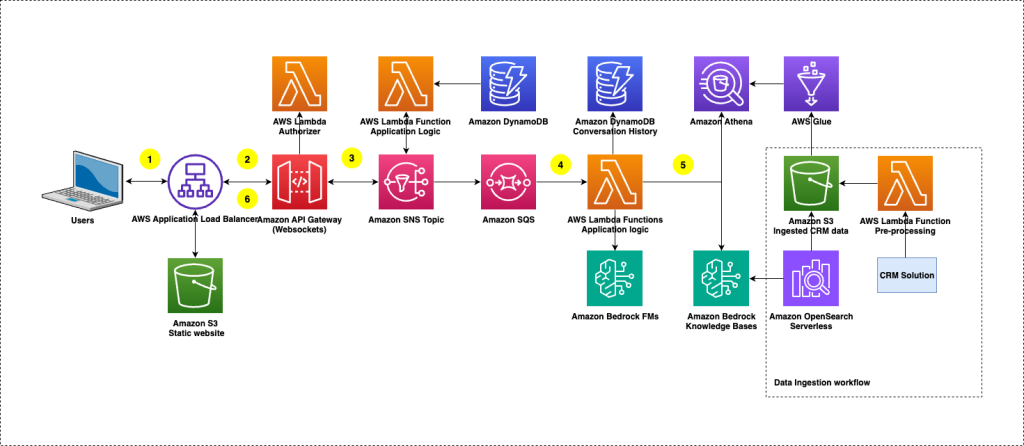
How TP ICAP transformed CRM data into real-time insights with Amazon Bedrock
This post shows how TP ICAP used Amazon Bedrock Knowledge Bases and Amazon Bedrock Evaluations to build ClientIQ, an enterprise-grade solution with enhanced security features for extracting CRM insights using AI, delivering immediate business value.
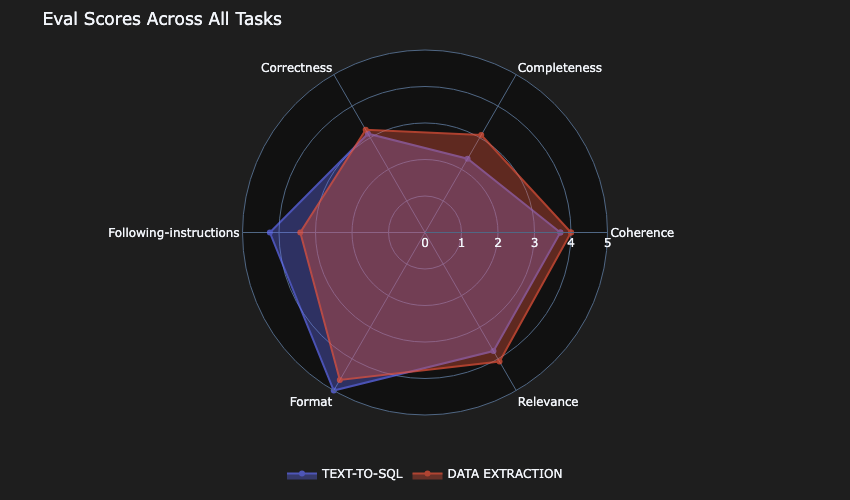
Beyond vibes: How to properly select the right LLM for the right task
In this post, we discuss an approach that can guide you to build comprehensive and empirically driven evaluations that can help you make better decisions when selecting the right model for your task.

Voice AI-powered drive-thru ordering with Amazon Nova Sonic and dynamic menu displays
In this post, we’ll demonstrate how to implement a Quick Service Restaurants (QSRs) drive-thru solution using Amazon Nova Sonic and AWS services. We’ll walk through building an intelligent system that combines voice AI with interactive menu displays, providing technical insights and implementation guidance to help restaurants modernize their drive-thru operations.
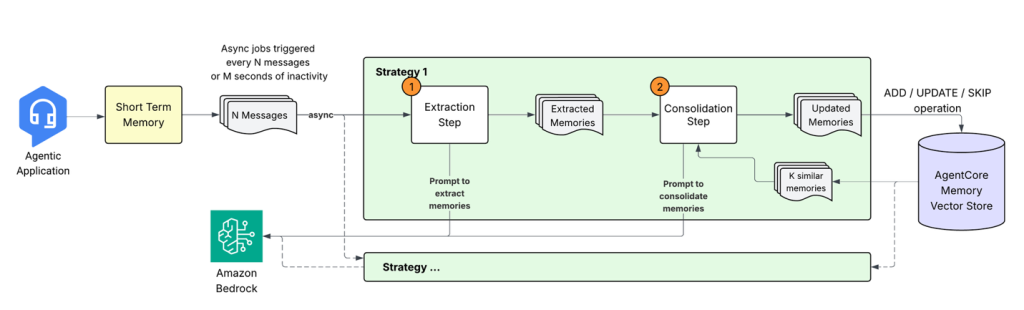
Building smarter AI agents: AgentCore long-term memory deep dive
In this post, we explore how Amazon Bedrock AgentCore Memory transforms raw conversational data into persistent, actionable knowledge through sophisticated extraction, consolidation, and retrieval mechanisms that mirror human cognitive processes. The system tackles the complex challenge of building AI agents that don’t just store conversations but extract meaningful insights, merge related information across time, and maintain coherent memory stores that enable truly context-aware interactions.
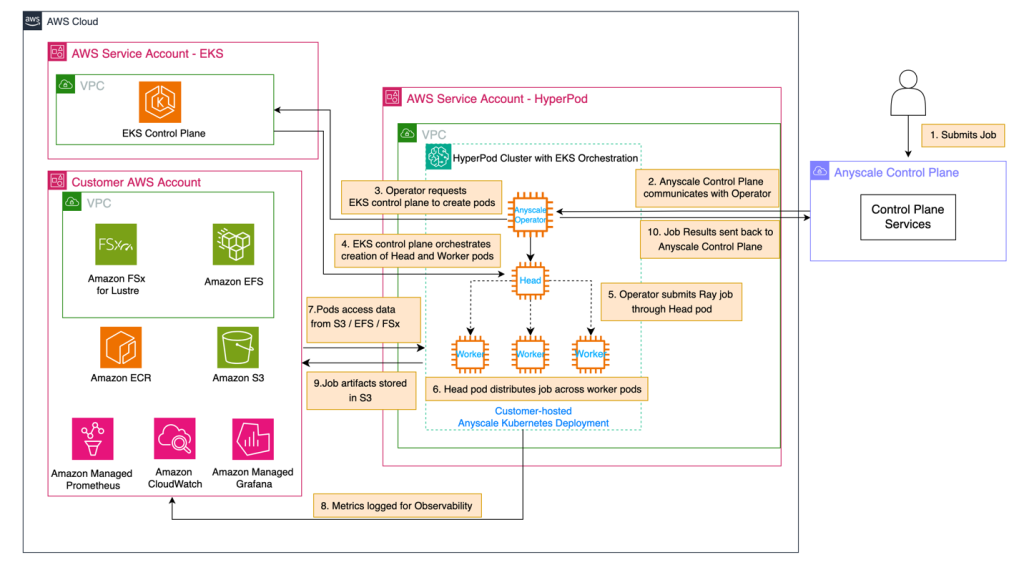
Use Amazon SageMaker HyperPod and Anyscale for next-generation distributed computing
In this post, we demonstrate how to integrate Amazon SageMaker HyperPod with Anyscale platform to address critical infrastructure challenges in building and deploying large-scale AI models. The combined solution provides robust infrastructure for distributed AI workloads with high-performance hardware, continuous monitoring, and seamless integration with Ray, the leading AI compute engine, enabling organizations to reduce time-to-market and lower total cost of ownership.

Implement automated monitoring for Amazon Bedrock batch inference
In this post, we demonstrated how a financial services company can use an FM to process large volumes of customer records and get specific data-driven product recommendations. We also showed how to implement an automated monitoring solution for Amazon Bedrock batch inference jobs. By using EventBridge, Lambda, and DynamoDB, you can gain real-time visibility into batch processing operations, so you can efficiently generate personalized product recommendations based on customer credit data.
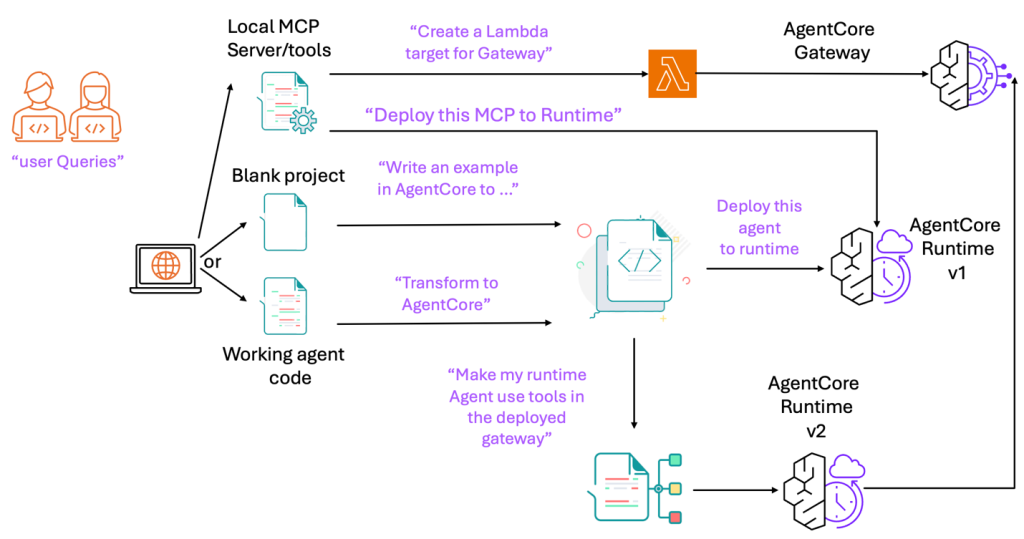
Accelerate development with the Amazon Bedrock AgentCore MCP server
Today, we’re excited to announce the Amazon Bedrock AgentCore Model Context Protocol (MCP) Server. With built-in support for runtime, gateway integration, identity management, and agent memory, the AgentCore MCP Server is purpose-built to speed up creation of components compatible with Bedrock AgentCore. You can use the AgentCore MCP server for rapid prototyping, production AI solutions, […]
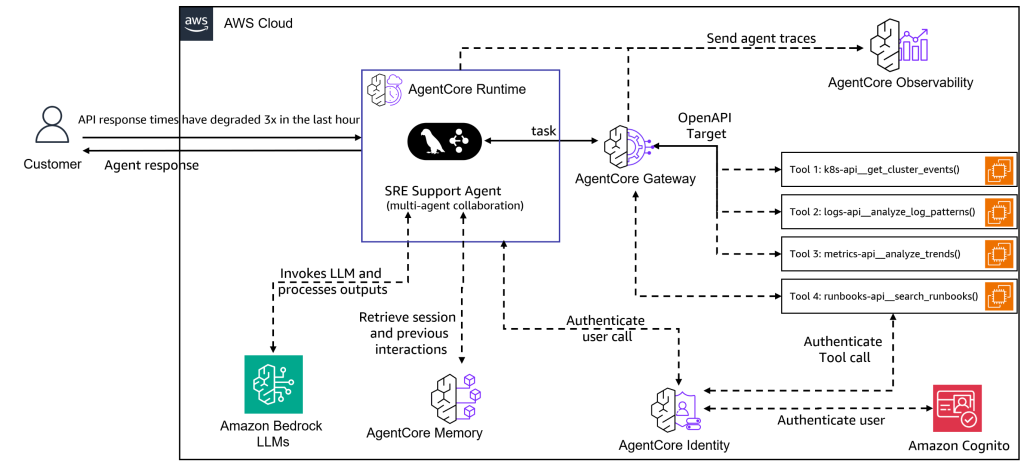
Build multi-agent site reliability engineering assistants with Amazon Bedrock AgentCore
In this post, we demonstrate how to build a multi-agent SRE assistant using Amazon Bedrock AgentCore, LangGraph, and the Model Context Protocol (MCP). This system deploys specialized AI agents that collaborate to provide the deep, contextual intelligence that modern SRE teams need for effective incident response and infrastructure management.
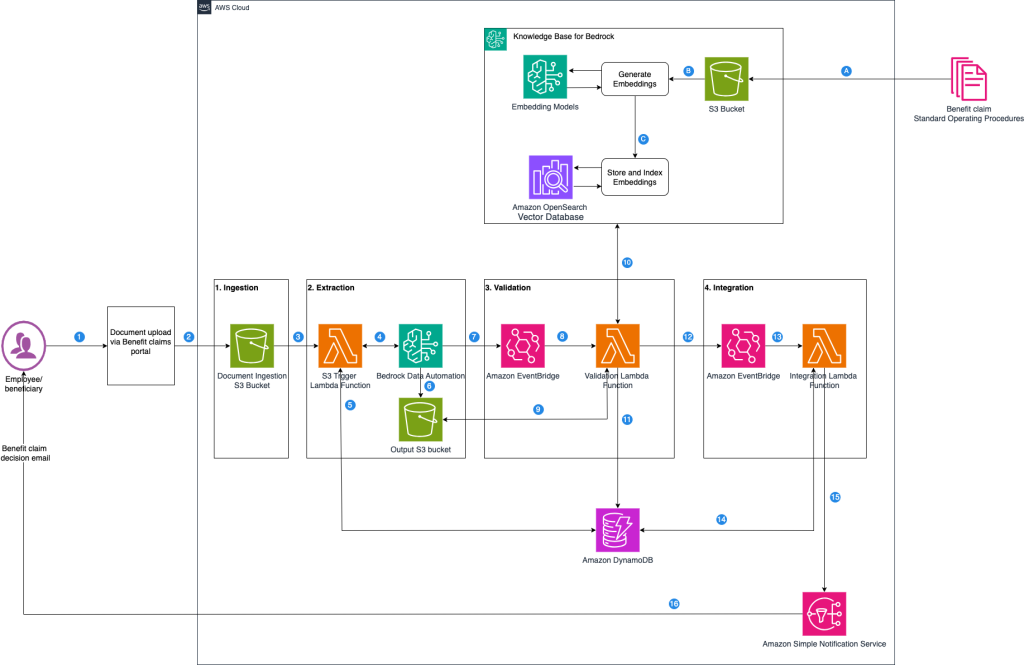
Accelerate benefits claims processing with Amazon Bedrock Data Automation
In the benefits administration industry, claims processing is a vital operational pillar that makes sure employees and beneficiaries receive timely benefits, such as health, dental, or disability payments, while controlling costs and adhering to regulations like HIPAA and ERISA. In this post, we examine the typical benefit claims processing workflow and identify where generative AI-powered automation can deliver the greatest impact.