Artificial Intelligence
Category: Artificial Intelligence
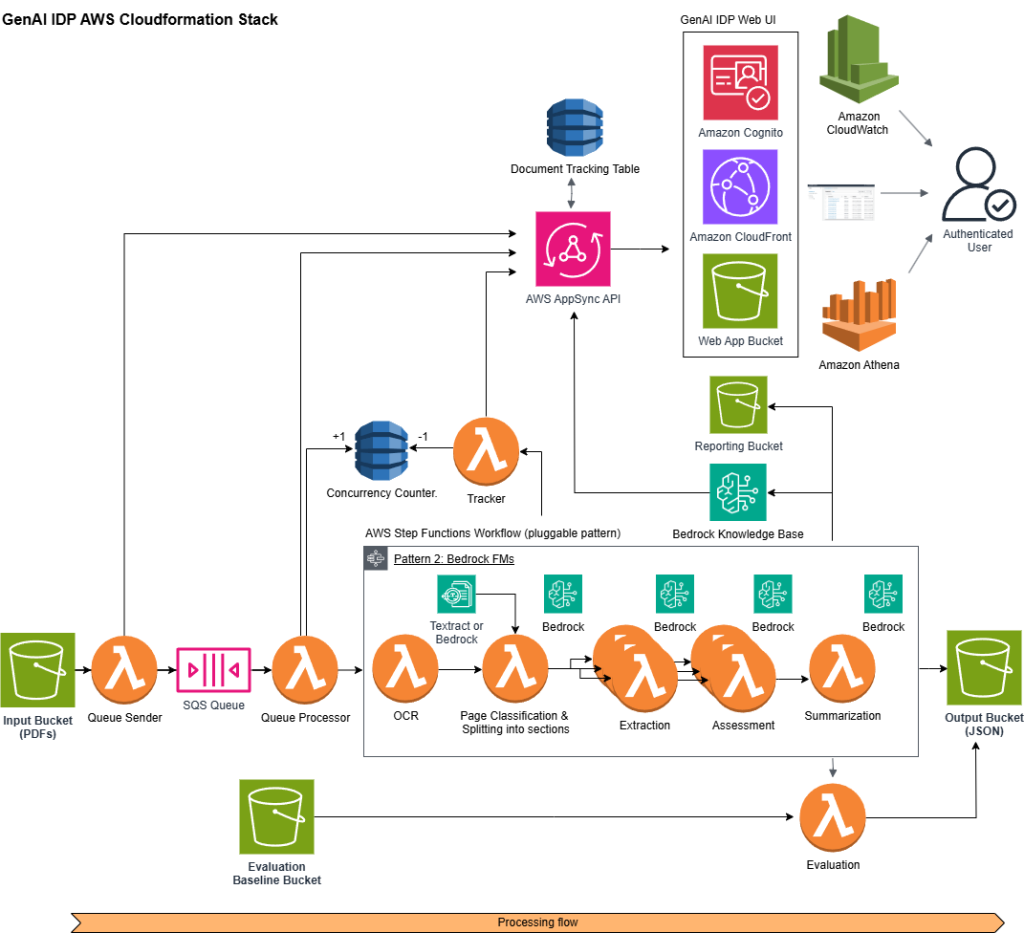
How Myriad Genetics achieved fast, accurate, and cost-efficient document processing using the AWS open-source Generative AI Intelligent Document Processing Accelerator
In this post, we explore how Myriad Genetics partnered with the AWS Generative AI Innovation Center to transform their healthcare document processing pipeline using Amazon Bedrock and Amazon Nova foundation models, achieving 98% classification accuracy while reducing costs by 77% and processing time by 80%. We detail the technical implementation using AWS’s open-source GenAI Intelligent Document Processing Accelerator, the optimization strategies for document classification and key information extraction, and the measurable business impact on Myriad’s prior authorization workflows.
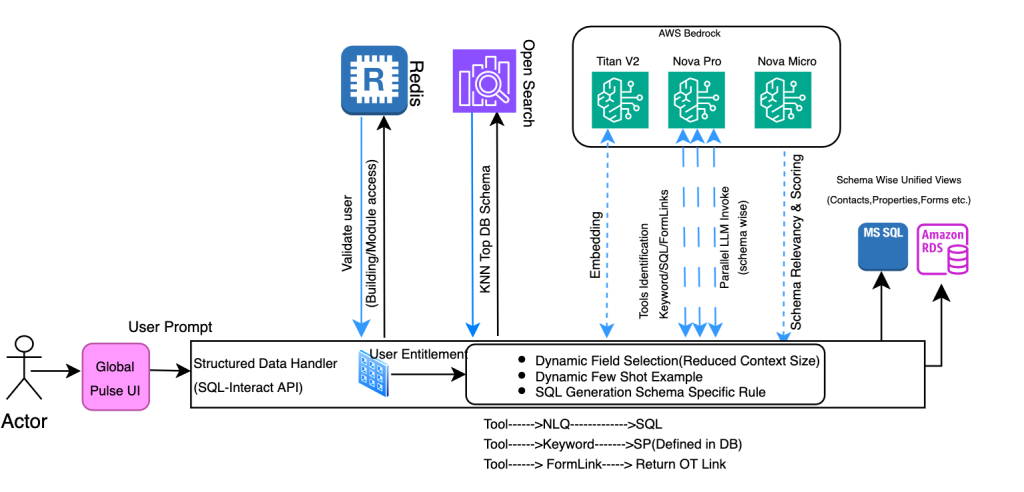
How CBRE powers unified property management search and digital assistant using Amazon Bedrock
In this post, CBRE and AWS demonstrate how they transformed property management by building a unified search and digital assistant using Amazon Bedrock, enabling professionals to access millions of documents and multiple databases through natural language queries. The solution combines Amazon Nova Pro for SQL generation and Claude Haiku for document interactions, achieving a 67% reduction in processing time while maintaining enterprise-grade security across more than eight million documents.
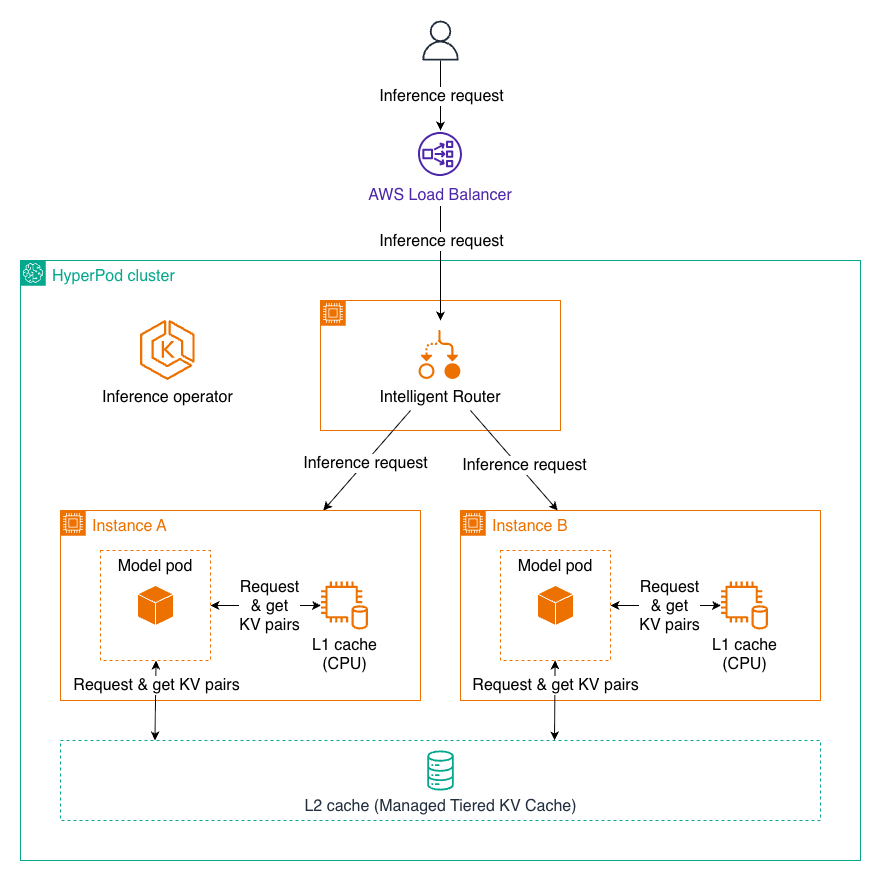
Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPod
In this post, we introduce Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPod, new capabilities that can reduce time to first token by up to 40% and lower compute costs by up to 25% for long context prompts and multi-turn conversations. These features automatically manage distributed KV caching infrastructure and intelligent request routing, making it easier to deploy production-scale LLM inference workloads with enterprise-grade performance while significantly reducing operational overhead.

Apply fine-grained access control with Bedrock AgentCore Gateway interceptors
We are launching a new feature: gateway interceptors for Amazon Bedrock AgentCore Gateway. This powerful new capability provides fine-grained security, dynamic access control, and flexible schema management.

How Condé Nast accelerated contract processing and rights analysis with Amazon Bedrock
In this post, we explore how Condé Nast used Amazon Bedrock and Anthropic’s Claude to accelerate their contract processing and rights analysis workstreams. The company’s extensive portfolio, spanning multiple brands and geographies, required managing an increasingly complex web of contracts, rights, and licensing agreements.

Building AI-Powered Voice Applications: Amazon Nova Sonic Telephony Integration Guide
Available through the Amazon Bedrock bidirectional streaming API, Amazon Nova Sonic can connect to your business data and external tools and can be integrated directly with telephony systems. This post will introduce sample implementations for the most common telephony scenarios.

University of California Los Angeles delivers an immersive theater experience with AWS generative AI services
In this post, we will walk through the performance constraints and design choices by OARC and REMAP teams at UCLA, including how AWS serverless infrastructure, AWS Managed Services, and generative AI services supported the rapid design and deployment of our solution. We will also describe our use of Amazon SageMaker AI and how it can be used reliably in immersive live experiences.

Optimizing Mobileye’s REM™ with AWS Graviton: A focus on ML inference and Triton integration
In this post, we focus on one portion of the REM™ system: the automatic identification of changes to the road structure which we will refer to as Change Detection. We will share our journey of architecting and deploying a solution for Change Detection, the core of which is a deep learning model called CDNet. We will share real-life decisions and tradeoffs when building and deploying a high-scale, highly parallelized algorithmic pipeline based on a Deep Learning (DL) model, with an emphasis on efficiency and throughput.
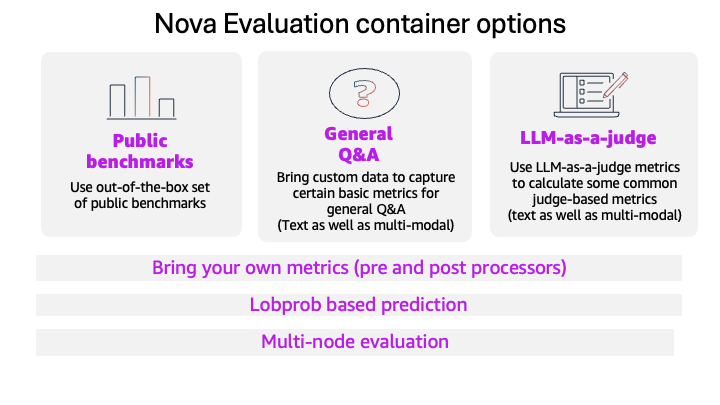
Evaluate models with the Amazon Nova evaluation container using Amazon SageMaker AI
This blog post introduces the new Amazon Nova model evaluation features in Amazon SageMaker AI. This release adds custom metrics support, LLM-based preference testing, log probability capture, metadata analysis, and multi-node scaling for large evaluations.

Beyond the technology: Workforce changes for AI
In this post, we explore three essential strategies for successfully integrating AI into your organization: addressing organizational debt before it compounds, embracing distributed decision-making through the “octopus organization” model, and redefining management roles to align with AI-powered workflows. Organizations must invest in both technology and workforce preparation, focusing on streamlining processes, empowering teams with autonomous decision-making within defined parameters, and evolving each management layer from traditional oversight to mentorship, quality assurance, and strategic vision-setting.