Artificial Intelligence
Build automatic analysis of body language to gauge attention and engagement using Amazon Kinesis Video Streams and Amazon AI Services
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
This is a guest blog post by Ned T. Sahin, PhD (Brain Power LLC and Harvard University), Runpeng Liu (Brain Power LLC and MIT), Joseph Salisbury, PhD (Brain Power LLC), and Lillian Bu (Brain Power LLC and MIT).

Producers of content (from ads to games to teaching materials) usually judge the success of their content by surveys or tests after the fact; or by user actions, such as click-throughs or bounces. These methods are often subjective, delayed, informal, post-hoc, and/or binary proxies for what content producers might want to measure—the perceived value of their content. Such metrics miss continuous and rich data about viewers’ attention, engagement, and enjoyment over time — which can be contained within their ongoing body language. However, there is no systematic way to quantify body language, nor to summarize in a single metric the patterns or key gestures within the often-overwhelming dataset of video.
We invented a method, affectionately called “Fidgetology,” to quantitatively summarize fidgeting and other body motions as a behavioral biomarker. We originally invented fidgetology at Brain Power (www.Brain-Power.com) to analyze clinical trial videos of children with autism and/or ADHD, as a new clinical outcome measure of their improvement in symptoms after using our augmented-reality system. In this blog post, we provide a more generalized architecture and example code that you can immediately try for your purposes. It uses newly-released artificial intelligence products from Amazon to automatically analyze body motions, for instance in video of people viewing your content. The method can apply to a range of content types, such as movies, ads, TV shows, video games, political campaigns, speeches, online courses; or classroom teaching.
Using this method, you can stream or upload video of your audience and immediately get an easy-to-understand mathematical plot and single-image summary of their level and patterns of motions. These motions can help estimate factors such as attention, focus, engagement, anxiety, or enjoyment. We also make suggestions for adding advanced AWS Lambda functions or machine-learning models to confirm and separate these factors, or to customize to your unique use case and/or individual users.
HOW IT WORKS
System architecture diagram
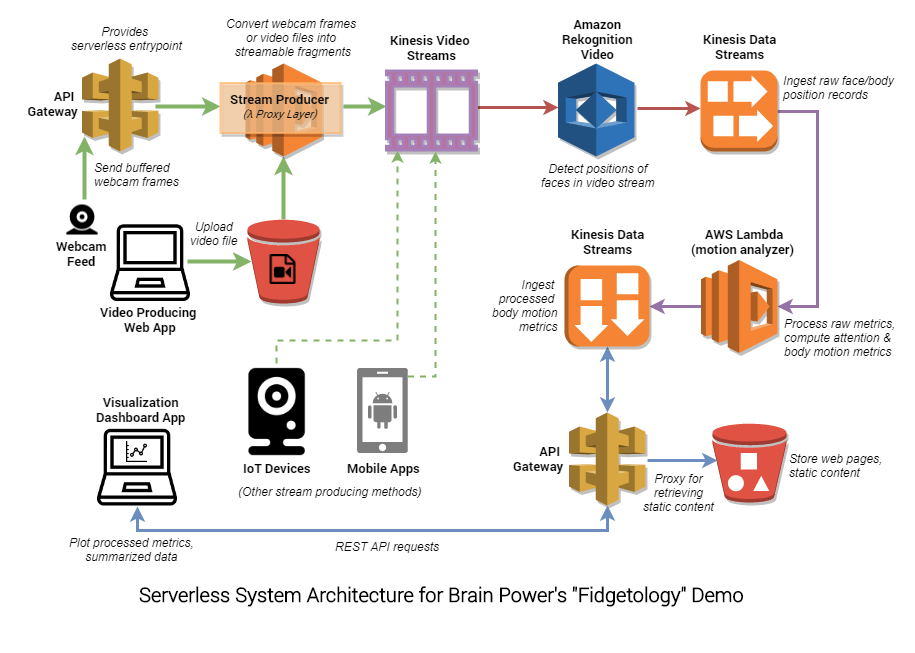
Kinesis Video Streams ingestion
A client video-stream-producing web app allows users to 1) upload pre-recorded video and/or 2) live stream their webcam feed to Amazon Kinesis Video Streams. This webcam streaming functionality is backed by the WebRTC getUserMedia API, and is supported on all major browsers and platforms, with the exception of iOS mobile.
Why a browser app? Of course, it is also possible to stream video from IoT devices such as AWS DeepLens, or build a custom mobile app using the Kinesis Video Streams Producer SDK for Android, but a simple cross-platform web app that can be launched in any browser is much more universally accessible.
When static video (via Amazon S3 upload) or buffered webcam frames (via Amazon API Gateway request) are uploaded by the web app, an AWS Lambda function, serving as a cloud proxy layer to Kinesis Video Streams, converts them to streamable media fragments. These media fragments are then put into a Kinesis Video Stream.
Note that since a Kinesis Video Streams Producer SDK is currently not available for JavaScript/web browser, we explored several workarounds aimed at mimicking streaming functionality in the AWS Cloud, and ultimately opted to pursue a fully serverless solution. You could also consider provisioning a custom Amazon Machine Image (AMI) as a WebRTC server that handles stream conversion. This alternative will probably yield the best performance and lowest latency, but is not in the spirit of the serverless architecture we present here.
Uploading a pre-recorded video:

Streaming from a browser webcam
The following is a side-by-side illustration of webcam streaming to the Amazon Kinesis Video Streams console. The lag between the live webcam app feed (left) and the time these frames are played back on the Kinesis Video Streams console (right) is about 5 seconds.

Amazon Rekognition Video – Stream processor
The next step is to automatically detect people in the full-speed video, and track their motions in real time. We feed the Kinesis Video Stream as input to Amazon Rekognition Video (the AWS new video-capable version of the Amazon Rekognition deep-learning toolset to track objects and people in images), using a Rekognition Stream Processor.
The overall goal is to analyze body motion of several kinds, but for now Amazon Rekognition Video focuses on faces. It provides extensive face data from the video stream, including the position over time of face landmarks such as eye, nose, and mouth corners, and face polygon, plus face rotation. These raw records are published to a Kinesis Data Stream.
Motion analytics
When new records appear in this raw data stream, our Motion Analytics algorithm (implemented as an AWS Lambda function) is triggered. It computes interesting derived metrics on faces in successive video frames, such as rotational/translational motion velocities, which can be used as features to gauge attention and engagement. These processed metrics are then published to another Kinesis Data Stream, for consumption by downstream applications and web dashboards.
Visualizing the metrics
For this project, we provide a dashboard app (in the same interface as the video streaming app) that consumes body motion metrics directly from the processed Kinesis Data Stream and renders them in near real-time as streaming chart visualizations. Of course, you can consider fronting the processed data stream with an Amazon API Gateway endpoint (as illustrated in the system architecture diagram) to allow multiple clients and downstream applications to consume the processed metrics scalably.
TRY IT YOURSELF
Deploy using AWS CloudFormation
This entire project can be deployed using AWS CloudFormation as a Change Set for a New Stack (a serverless application transform must first be applied to the template definition). Explore the GitHub repository for this project for a description of configuration options and AWS resource components, as well as custom command-line deployment options.
First, use this button to launch the stack creation process:
![]()
Step 1. Choose Next, and specify brain-power-fidgetology-demo as both the Stack name and Change set name. Accept all default parameters and choose Next.

Step 2. Choose Next again to get to the final Review page. Under Capabilities, confirm acknowledgement that new IAM resources will be created. Then choose Create change set.

Step 3. On the next page, wait for the stack to finish ‘Computing changes’. Then choose Execute (top-right corner of page) to start the stack deployment. Confirm, and refresh the CloudFormation page to find your newly created stack. Choose it to monitor the deployment process, which should take no more than 3 minutes.


Step 4. After deployment is complete, launch the demo web app by visiting the WebAppSecureURL link listed under Outputs.
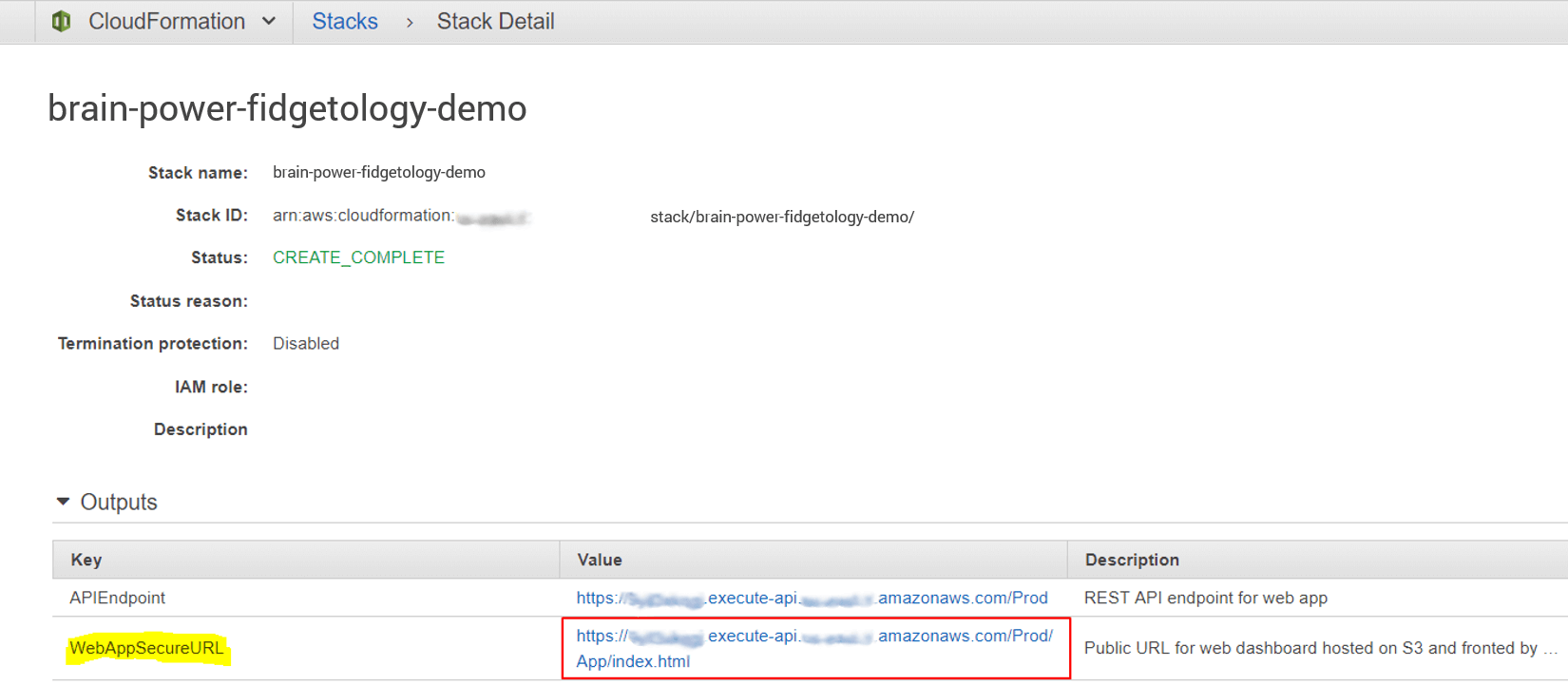
By default, the CloudFormation template creates all necessary AWS resources for this project (Kinesis Video Stream, Amazon Rekognition Stream Processor, Kinesis Data Streams, serverless Lambda functions, and an API Gateway endpoint). It copies the dashboard web application to an Amazon S3 bucket and outputs a secure URL (fronted by API Gateway) for accessing the web app.
Test the live webcam stream
After you open the web app, choose the Stream Webcam button, and give the app permission to access your camera. Then follow the externally linked button to open the Kinesis Video Streams web console in a separate browser window.

To ensure proper syncing on the Kinesis Video Streams console, select Producer time stamps. Within a few seconds delay, you should see your live webcam feed played back on the Kinesis Video Streams console.

We would love to hear how well the live-streaming works for you! Refer to the project GitHub repository for suggestions on how you can improve the playback latency.
Customize the motion analytics Lambda function
We offer for your use a basic motion analytics function. This function estimates the rotational and translational velocities of faces in successive frames. You can use such metrics to build a feature set aimed at gauging attention and engagement based on body motion patterns.
We have experimented with additional and advanced metrics for specific use cases surrounding autism and ADHD, and as a service to support external clinical trials, and these will be published in medical research journals.
brain-power-fidgetology-demo-StreamAnalyzer.js
To customize this stream processing function for your own use case, go to the AWS Lambda console, and find the brain-power-fidgetology-demo-StreamAnalyzer function associated with this project stack.

The function can also be modified before deploy time by cloning the project GitHub repository and following the instructions to re-package the CloudFormation template and update the stack.
AREAS TO EXPAND OR IMPROVE THIS ARCHITECTURE
Integrating Amazon Kinesis Data Analytics (AI) or Amazon SageMaker (ML)
Of potential interest is the possibility of building a Kinesis Data Analytics application that consumes the raw output of the Amazon Rekognition video stream processor, with unsupervised anomaly detection capabilities. In this way, alerts can be created in real time with processing latencies of less than one second, and this immediate feedback provides the potential for immediate response to distress signals. Within the context of a clinical trial, physicians may utilize this feedback functionality when prescribing a new treatment to evaluate the response of the patient and their readiness for it. In the context of a game, ad, or speech, warning signs that predict audience disengagement from content can trigger surprise elements to re-stimulate attention.
Tracking multiple bodies
You can also consider modifying the brain-power-fidgetology-demo-StreamAnalyzer function to allow for tracking of multiple faces/bodies in a video feed. Amazon Rekognition Video detects multiple individuals in a video stream and assigns a unique ID to each (without requiring personal identification of anyone). Taking advantage of this feature, the movement patterns of multiple bodies could be measured in a large group setting, such as in a classroom or movie screening, to gauge the overall engagement within the room.
Teachers, as an example, could use such feedback when assessing the quality or success of their lesson plans, or to help find the students with wandering attention spans who may need more support. Advertisement producers could generate a single snapshot that summarizes the average level of interest in their content or product, and even the consistency of that interest across time, across members of a diverse group, and/or in comparison to other content.
Additionally, unlike analyses based on the detailed facial expressions or micro-expressions of each crowd member, Brain Power’s fidgetology analysis can be carried out based on a camera feed that lacks the extremely fine-grain detail and good lighting required to analyze each face. This makes it much more tractable given plausible constraints of camera hardware and storage/streaming bandwidth.
Privacy
As with single-person analysis, this method can be performed without revealing the personal identity of any face in the crowd, nor even surveying the crowd at the camera resolution required to reveal personal identity. This allows you to preserve the personal privacy of your audience, while estimating their aggregate and individual level of attention, focus, and enjoyment of your content.
Additional improvements
Our ideas for expanding this architecture are described in the Potential Improvements section of the accompanying Github repository.
BRAIN POWER’S USE CASE – BACKGROUND
Above we offer a new method, along with code and general-use examples to inspire broad adoption of that method. Below is an example of its original application: measuring and training behavioral signs of attention in children with autism and/or ADHD.
By way of background, 3.5 million people in America have autism, and a staggering 11 percent of all children have ADHD. Many in these populations struggle with attention and focus. Even when on task, many display behaviors and signs that distract others and suggest inattention, impeding success with school, employment, and romance. We developed a neuroscience-based augmented reality system that gamifies interactions with other people, rewarding points for eye contact, conversation, successful transitions, decoding of emotions, and more.
We previously published clinical studies demonstrating that it was well-tolerated, engaging, and feasible in children and adults with autism and/or ADHD diagnoses; and was safe, and desirable in schools. We also showed that it improved symptoms of autism, and of ADHD, based on established, respected clinical criteria for each.
However, in videos of clinical trial sessions there was a large difference between when participants used and did not use our system — which was visually obvious but which we could not quantify in any other way. This led us to devise the fidgetology method shared here.
BRAIN POWER’S USE CASE – EXAMPLE RESULTS
We extracted two comparable segments from the video recording of one of our clinical trial sessions, and fed them through the fidgetology analysis stream described in this blog post. All experiments were reviewed and approved by Asentral Inc (Institutional Review Board), and parental consent was given for the public display of images and video.
Real-Time Fidgetology analysis: Child using Brain Power’s AR system for autism

Real-Time Fidgetology analysis: Child NOT using Brain Power’s AR system for autism

In both examples above, the clinical participant is having a conversation with his Mom about topics he enjoys, while the camera records over Mom’s shoulder. The fidget index reported here is calculated as the average change in the pitch, yaw, and roll of the face over time.
As the graphs show, this calculated face rotational velocity remains stable and below the first threshold for the entire duration the child is using the Brain Power software (in this case running on a Google Glass headset), but oscillates among numerous threshold intervals while the child is not wearing the headset. These quantitative results agree with the single-image summary (amount of image blur), and the qualitative decrease in movement readily observable in the video, during the “active condition” when the child was using the augmented-reality system.
Such information can be combined with or complement traditional measures of hyperactivity, to evaluate the usefulness of the headset and game content in terms of engaging children and motivating them to increase and exhibit their attention.
We note that with the limitation of being able to track only the face for now (given the current Amazon toolset), we miss the fidgeting of other body aspects and lose some of the most drastic movements when the face is undetectable, thus causing this face-based index to underestimate the total body motion in the control condition. We have already devised other indices, however, each with its own advantages. We encourage further exploration, and would love to hear your observations at Brain-Power.com/research/fidgetology.

Example summary metrics resulting from the version of the fidgetology method described in this blog post. The resulting single-image summary is a small-file size, digestible 2D summary of potentially a very large 4D+ data set. The graphs succinctly depict the range and some patterns of body/face motions over time, space, and rotational position.
SUMMARY
We’ve provided a web application and accompanying serverless architecture for streaming a webcam feed from a browser to Amazon Kinesis Video Streams and Amazon Rekognition Video. Body motion metrics can then be visualized in a web app with minimal delay.
Brain Power thus developed “fidgetology” toward a new biomarker and clinical outcome measure for behavioral health. In this blog post, we share a way for others to quickly and numerically summarize audience body language in reaction to their content. This may apply to a range of business use cases, such as quickly estimating engagement and enjoyment of movies, ads, TV shows, video games, political campaigns, speeches, online courses; or classroom teaching.
ACKNOWLEDGEMENTS
Brain Power earnestly thanks Bob Strahan of the Amazon Web Services professional services team for all his encouragement and assistance.
We warmly thank all the families who have participated in our research in efforts to help other members of their community.
This work was supported in part by the Autism Research Program under the Congressionally Directed Medical Research Program via the Office of the Assistant Secretary of Defense for Health Affairs (award W81XWH-17-1-0449).
ABOUT THE AUTHORS
 Dr. Ned Sahin, PhD is the Founder of Brain Power. He is an award-winning neuroscientist and neurotechnology entrepreneur, trained at Williams College, Oxford, MIT, and Harvard. Among the several hats he wears, Dr. Sahin was the superviser of scientific studies and clinical trials of the wearable technologies we use to empower people with a range of brain-related challenges. He invented the fidgetology concept.
Dr. Ned Sahin, PhD is the Founder of Brain Power. He is an award-winning neuroscientist and neurotechnology entrepreneur, trained at Williams College, Oxford, MIT, and Harvard. Among the several hats he wears, Dr. Sahin was the superviser of scientific studies and clinical trials of the wearable technologies we use to empower people with a range of brain-related challenges. He invented the fidgetology concept.
 Runpeng Liu is Lead Web Systems Engineer at Brain Power. He oversaw Brain Power’s adoption of AWS technologies to scale its Autism wearable apps and analytics software for the cloud. He implemented the fidgetology concept using Amazon’s newest services, and authored all the technical content and visuals of this blog post.
Runpeng Liu is Lead Web Systems Engineer at Brain Power. He oversaw Brain Power’s adoption of AWS technologies to scale its Autism wearable apps and analytics software for the cloud. He implemented the fidgetology concept using Amazon’s newest services, and authored all the technical content and visuals of this blog post.
 Dr. Joseph (Joey) Salisbury is Director of Software Development and a Principal Investigator at Brain Power, and holds a PhD in neuroscience. His research focuses on therapeutic applications for mobile/VR/AR games.
Dr. Joseph (Joey) Salisbury is Director of Software Development and a Principal Investigator at Brain Power, and holds a PhD in neuroscience. His research focuses on therapeutic applications for mobile/VR/AR games.
 Lillian Bu is a Program Manager for the Brain Power—Amazon relationship. She communicates potential use cases of new Amazon technologies with the development team.
Lillian Bu is a Program Manager for the Brain Power—Amazon relationship. She communicates potential use cases of new Amazon technologies with the development team.