AWS HPC Blog
Building highly-available HPC infrastructure on AWS
AWS provides an elastic and scalable cloud infrastructure to run high performance computing (HPC) applications, so that engineers are no longer constrained to run their job on limited on-premises infrastructure. Every workload can run on its own on-demand cluster with access to virtually unlimited capacity, and HPC can focus in services to meet the infrastructure requirements of almost any application. This mitigates the risk of on-premises HPC clusters becoming obsolete or poorly utilized as needs change over time.
In this blog post, we will explain how to launch HPC clusters across two Availability Zones. The solution is deployed using the AWS Cloud Developer Kit (AWS CDK), a software development framework for defining cloud infrastructure in code and provisioning it through AWS CloudFormation, hiding the complexity of integration between the components.
The following includes the main components of the solution:
- Amazon Aurora is a fully managed relational database engine that’s compatible with MySQL and PostgreSQL. Aurora can deliver up to five times the throughput of MySQL and up to three times the throughput of PostgreSQL without requiring changes to most of your existing applications. Aurora is used, in this solution, as the backend database for EnginFrame, in Serverless configuration.
- AWS ParallelCluster is an AWS-supported open source cluster management tool that makes it easy for you to deploy and manage HPC clusters on AWS. AWS ParallelCluster uses a simple text file to model and provision all the resources needed for your HPC applications in an automated and secure manner. It also supports a variety of job schedulers such as AWS Batch, SGE, Torque, and Slurm for easy job submissions.
- EnginFrame is a leading grid-enabled application portal for user-friendly submission, control, and monitoring of HPC jobs and interactive remote sessions. It includes sophisticated data management for all stages of HPC job lifetime and is integrated with most popular job schedulers and middle-ware tools to submit, monitor, and manage jobs. EnginFrame provides a modular system where new functionalities (e.g. application integrations, authentication sources, license monitoring, etc.) can be easily added. It also features a sophisticated web services interface, which can be leveraged to enhance existing applications in addition to developing custom solutions for your own environment.
- Amazon Elastic File System (Amazon EFS) provides a simple, serverless, set-and-forget, elastic file system that lets you share file data without provisioning or managing storage. It can be used with AWS Cloud services and on-premises resources, and is built to scale on-demand to petabytes without disrupting applications. With Amazon EFS, you can grow and shrink your file systems automatically as you add and remove files, eliminating the need to provision and manage capacity to accommodate growth.
- Amazon FSx for Lustre is a fully managed service that provides cost-effective, high-performance, scalable storage for compute workloads. Many workloads, such as HPC, depend on compute instances accessing the same set of data through high-performance shared storage.
The two clusters are created using AWS ParallelCluster and, the main front end used to access the environment, is managed by EnginFrame in the Enterprise configuration. Amazon Aurora is used by EnginFrame as RDBMS to manage Triggers, Job-Cache, and Applications and Views users’ groups. Amazon Elastic File System is used as shared file system between the two clusters environments. Two Amazon FSx file systems, one per each Availability Zone (AZ), are used as high-performance file system for the HPC jobs.
The configuration covers two different Availability Zones to maintain a fully operational system in case a specific AZ fails. In addition, you can use both Availability Zones for your jobs in case a specific instance type is not available in one of the two Availability Zones.
Figure 1 shows the different components of the HPC solution. The architecture shows how a user interacts with EnginFrame to start an HPC job in the two clusters created by AWS ParallelCluster.
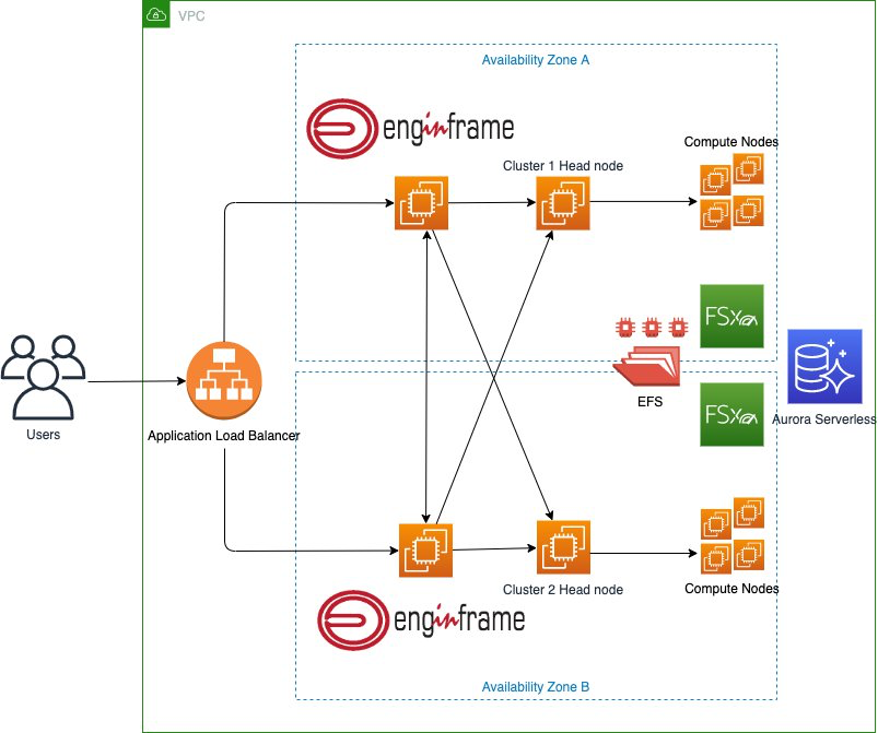
Figure 1. Architecture diagram for the highly-available HPC solution
We will now walk through setting up the HPC environment in your AWS account.
Creation of the default account password
The EnginFrame default administrator account, named ec2-user, requires a password. To improve the security of the solution, the password must be created by the user and saved in AWS Secrets Manager. The AWS Secrets Manager tutorial explains how to create your secret; the password must have letters, numbers, and one special character; the ARN of the created secret will be required in the next section. Next, deploy the solution with AWS CDK.
The code used for this solution can be downloaded from this git repository. Once you download or clone the repository to your local development machine, navigate to the root repository directory. There you will find the following:
app.pycontains the configuration variables used to deploy the environment. Before the deployment, you must customize it with the required configurations.<key_name>is your Amazon EC2 key pair.<arn_secret>is the ARN of the secret created in the previous step.- The following additional parameters can also be configured accordingly to your requirements:
ec2_type_enginframe: The EnginFrame instance typeebs_engingframe_size: The Amazon Elastic Block Store (EBS) size for the EnginFrame instancefsx_size: The size of the FSx for Lustre volumejdbc_driver_link: The link used to download the MySQL JDBC driver. The MySQL Community Downloads contains the latest version. The required version is the TAR Archive Platform independent one.pcluster_version: the AWS ParallelCluster version installed in the environment. The solution has been tested with the 2.10.3 version.
- The
enginframe_aurora_serverlessdirectory contains the files of the classes used to deploy the required resources. lambda/cert.pyis the Lambda function used to create the Application Load Balancer certificate.lambda_destroy_pcluster/destroy.pyis the Lambda function used to destroy the AWS ParallelCluster clusters during the deletion of the stacks.- The
user datadirectory contains the script used to configure the HPC environment. scripts/pcluster.configis the AWS ParallelCluster configuration file.scripts/post_install.shis the AWS ParallelCluster post installation script.
The following commands can be used for the deployment:
python3 -m venv .venv
source .venv/bin/activate
python3 -m pip install -r requirements.txt
cdk bootstrap aws://<account>/<region>
cdk deploy VPC AuroraServerless EFS FSX ALB EnginFrame
The deployment creates, using the default configuration, the following components:
- Two EnginFrame instances, one per AZ
- Two Cluster Head Nodes instances, one per AZ
- One Amazon EFS file system
- Two FSx for Lustre file systems, one per AZ
- One Aurora Serverless database
- One Application Load Balancer
After the deployment, note the Application Load Balancer URL address. Here is an example of the output:
Outputs:
EnginFrame.EnginFramePortalURL = https://ALB-EFLB1F2-Z3O8UAW7P443-1634659638.eu-west-1.elb.amazonaws.comThis address will be used to access the EnginFrame portal.
File system structure
The solution contains the following shared file systems:
/efsis the file system shared between the two clusters and can be used to install your applications;/fsx_cluster1and/fsx_cluster2are the high-performance file systems of the related clusters and can be used to contain your scratch and input and output files.
Install an application
The created environment doesn’t contain any installed applications. You can proceed to the installation of the desired applications accessing to one of the EnginFrame instances from AWS Systems Manager Session Manager. The connection is possible using the Amazon EC2 Console.
Accessing the EnginFrame portal
When you access to the URL provided at the end of the previous step, the following webpage is displayed.
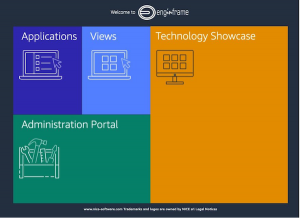
Figure 2. The EnginFrame welcome page.
The Applications section is used to start your batch jobs.
The User, required for the access, is named ec2-user. The Password of this user is the one saved in Secret Manager.
Start your first job
The service on the left side of the portal, named Job Submission, can be used to submit your jobs in the cluster.
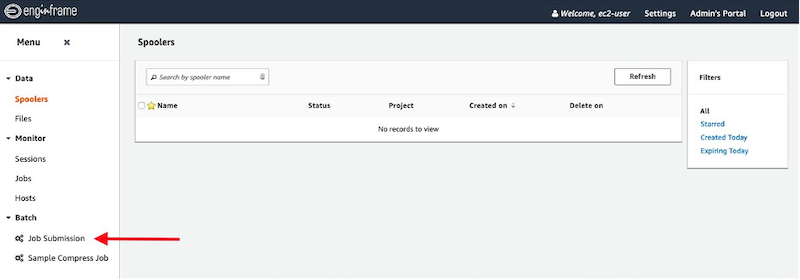
Figure 3. Job Submission link.
The new page contains different parameters that you can use to personalize your job.
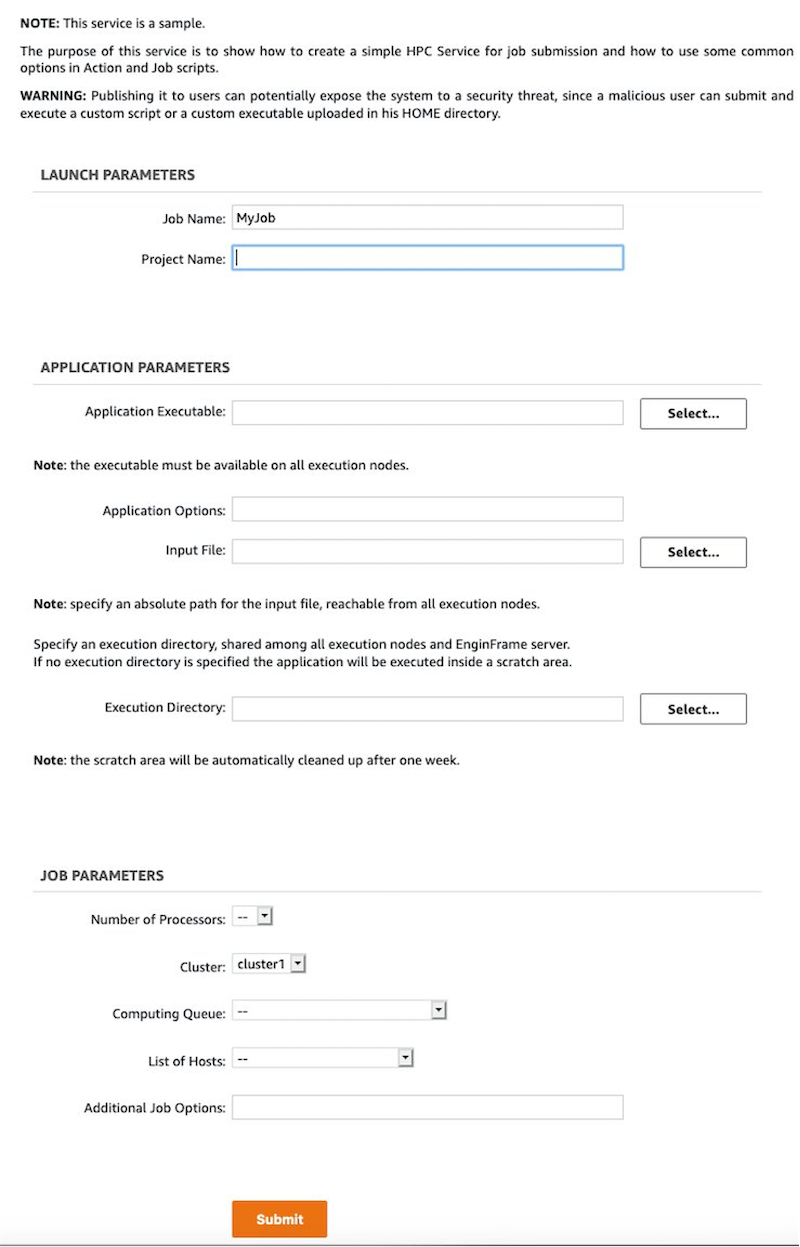
Figure 4. The job submission page.
The following parameters can be personalized in the interface:
- Job Name: The name of the job
- Project Name: The Project associated with the job
- Application Executable: The full path of the application executable to use in the job. For a custom application, it should be installed under the /efs path
- Application Options: If necessary, the application parameters can be added here;
- Input File: If the application requires an input file, you can use this parameter. The files can be uploaded from the Filessection of the portal. If you need a parallel file system, you can use /fsx_cluster1 or /fsx_cluster2, depending on the used cluster
- Execution Directory: This parameter can be used to specify the execution directory
- Number of Processors: The number of cores used by the job;
- Cluster: The value can be cluster1 or cluster2
- Computing Queue: The queue used to submit the job
- List of Hosts: The parameter used to specify the host for the job(usually not required)
- Additional Job Options: This section can be used to add additional parameters to the Slurm submission line
After the submission form is completed, you can click on the Submit button.
The new screen shows the status of the job in pending until AWS ParallelCluster starts the required resources.
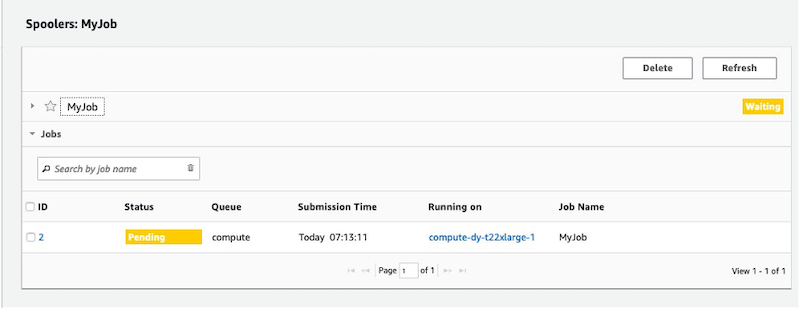
Figure 5. The job information view, showing Pending status for the job.
After the job is completed, you can retrieve the generated output files.
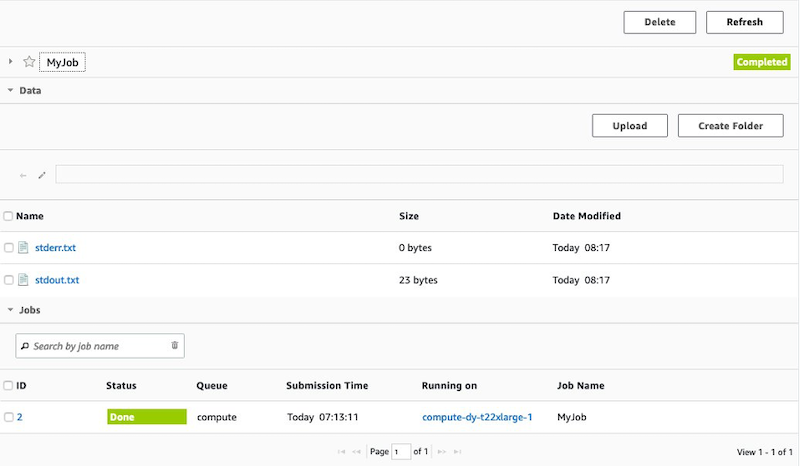
Figure 6. The job information page, showing Completed status and links to download outputs.
You can access the output of your earlier jobs from the Spoolers section of the portal.
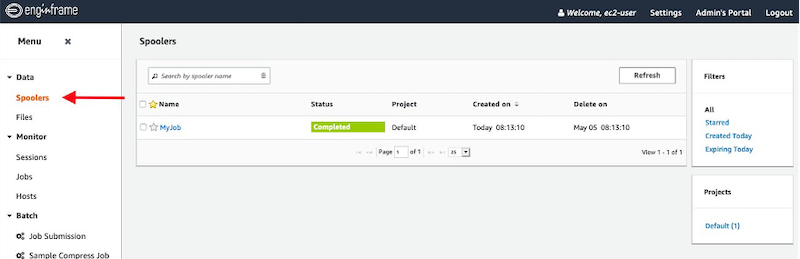
Figure 7. The EnginFrame portal, showing the Spoolers view.
The default configuration uses the c5.xlarge instance type for the compute nodes. Amazon EC2 c5 instances deliver cost-effective high performance at a low price per compute ratio for running advanced compute-intensive workloads.
You can increase the size of the instance type modifying the AWS ParallelCluster configuration file and re-deploying a new stack. The same configuration file can also be used to customize the AWS ParallelCluster environment as described in the User Guide.
Clean up and teardown
In order to avoid additional charges, you can destroy the created resources by running the cdk destroy VPC AuroraServerless EFS FSX ALB EnginFrame command from the enginframe-aurora-serverless repository’s root directory.
Conclusions
In this post, we show how to deploy a complete highly available Linux HPC environment spread across two Availability Zones using AWS CDK. The solution uses EnginFrame as central point of access to the two HPC clusters, one per AZ, built using AWS ParallelCluster.
The selection of two different Availability Zones is used to maintain full operations in case of failure of a specific AZ, and allows the utilization of an instance type not available in a specific AZ.
The solution takes advantages of the AWS elastic and scalable cloud infrastructure to run your HPC applications. The configuration is also optimized to pay the capacity you use. Every workload, with its own configuration, can use optimal set of services for their unique application. The main benefits of the described solutions are lowering costs by paying only for what you use, and reducing the time spent managing infrastructure through AWS managed services.