AWS HPC Blog
Category: Artificial Intelligence

Whisper audio transcription powered by AWS Batch and AWS Inferentia
Transcribe audio files at scale for really low cost using Whisper and AWS Batch with Inferentia. Check out this post to deploy a cost-effective solution in minutes!

Deploying generative AI applications with NVIDIA NIMs on Amazon EKS
Learn how to deploy AI models at scale with @AWS using NVIDIA’s NIM and Amazon EKS! This step-by-step guide shows you how to create a GPU cluster for inference. Don’t miss part 1 of this 2-part blog series!

Gang scheduling pods on Amazon EKS using AWS Batch multi-node processing jobs
AWS Batch multi-node parallel jobs can now run on Amazon EKS to provide gang scheduling of pods across nodes for large scale distributed computing like ML model training. More details here.

Large scale training with NVIDIA NeMo Megatron on AWS ParallelCluster using P5 instances
Launching distributed GPT training? See how AWS ParallelCluster sets up a fast shared filesystem, SSH keys, host files, and more between nodes. Our guide has the details for creating a Slurm-managed cluster to train NeMo Megatron at scale.

Enhancing ML workflows with AWS ParallelCluster and Amazon EC2 Capacity Blocks for ML
No more guessing if GPU capacity will be available when you launch ML jobs! EC2 Capacity Blocks for ML let you lock in GPU reservations so you can start tasks on time. Learn how to integrate Caacity Blocks into AWS ParallelCluster to optimize your workflow in our latest technical blog post.

How computer vision is enabling a circular economy
In this post, we show how Reezocar uses computer vision to change the way they detect damage and price used vehicles for re-sale in secondary markets. This reduces landfill and helps achieve the goals of the circular economy.

Improving NFL player health using machine learning with AWS Batch
In this post we’ll show you how the NFL used AWS to scale their ML workloads and produce the first comprehensive dataset of helmet impacts across multiple NFL seasons. They were able to reduce manual labor by 90% and the results beats human labelers in accuracy by 12%!

How Evolvere Biosciences performs macromolecule design on AWS
In this blog post, we catch a glimpse into drug discovery to see how Evolvere Biosciences has deployed a customized architecture w/ AWS Batch and Nextflow to quickly and easily run its macromolecule design pipeline.
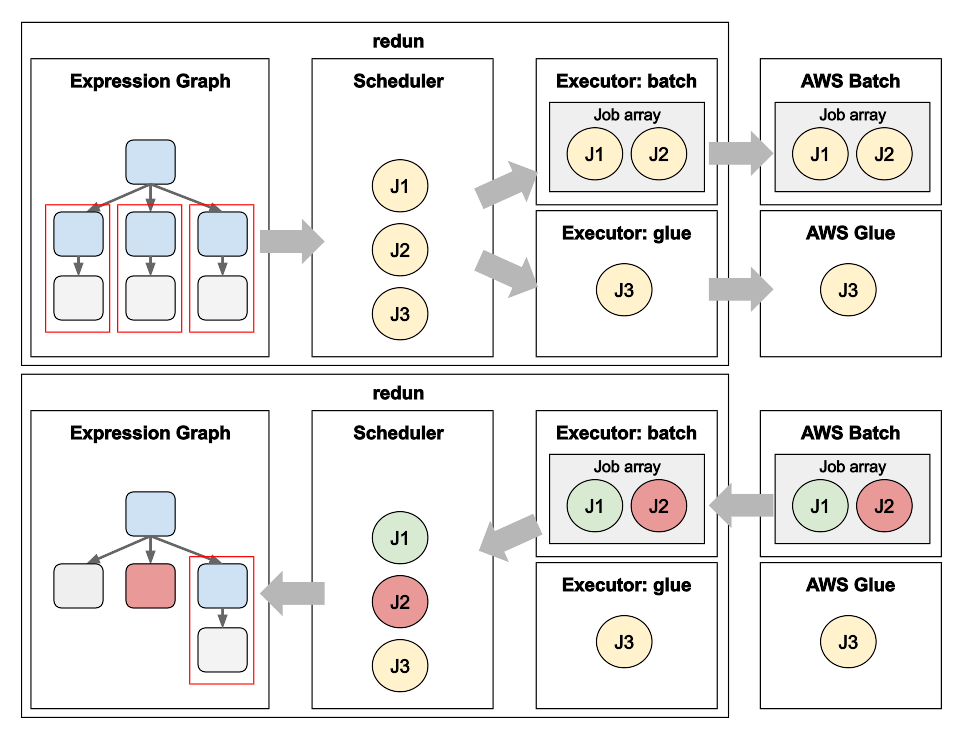
Data Science workflows at insitro: how redun uses the advanced service features from AWS Batch and AWS Glue
Matt Rasmussen, VP of Software Engineering at insitro, expands on his first post on redun, insitro’s data science tool for bioinformatics, to describe how redun makes use of advanced AWS features. Specifically, Matt describes how AWS Batch’s Array Jobs is used to support workflows with large fan-out, and how AWS Glue’s DynamicFrame is used to run computationally heterogenous workflows with different back-end needs such as Spark, all in the same workflow definition.

Data Science workflows at insitro: using redun on AWS Batch
Matt Rasmussen, VP of Software Engineering at insitro describes their recently released, open-source data science framework, redun, which allows data scientists to define complex scientific workflows that scale from their laptop to large-scale distributed runs on serverless platforms like AWS Batch and AWS Glue. I this post, Matt shows how redun lends itself to Bioinformatics workflows which typically involve wrapping Unix-based programs that require file staging to and from object storage. In the next blog post, Matt describes how redun scales to large and heterogenous workflows by leveraging AWS Batch features such as Array Jobs and AWS Glue features such as Glue DynamicFrame.