AWS DevOps & Developer Productivity Blog
Using AWS Step Functions State Machines to Handle Workflow-Driven AWS CodePipeline Actions
AWS CodePipeline is a continuous integration and continuous delivery service for fast and reliable application and infrastructure updates. It offers powerful integration with other AWS services, such as AWS CodeBuild, AWS CodeDeploy, AWS CodeCommit, AWS CloudFormation and with third-party tools such as Jenkins and GitHub. These services make it possible for AWS customers to successfully automate various tasks, including infrastructure provisioning, blue/green deployments, serverless deployments, AMI baking, database provisioning, and release management.
Developers have been able to use CodePipeline to build sophisticated automation pipelines that often require a single CodePipeline action to perform multiple tasks, fork into different execution paths, and deal with asynchronous behavior. For example, to deploy a Lambda function, a CodePipeline action might first inspect the changes pushed to the code repository. If only the Lambda code has changed, the action can simply update the Lambda code package, create a new version, and point the Lambda alias to the new version. If the changes also affect infrastructure resources managed by AWS CloudFormation, the pipeline action might have to create a stack or update an existing one through the use of a change set. In addition, if an update is required, the pipeline action might enforce a safety policy to infrastructure resources that prevents the deletion and replacement of resources. You can do this by creating a change set and having the pipeline action inspect its changes before updating the stack. Change sets that do not conform to the policy are deleted.
This use case is a good illustration of workflow-driven pipeline actions. These are actions that run multiple tasks, deal with async behavior and loops, need to maintain and propagate state, and fork into different execution paths. Implementing workflow-driven actions directly in CodePipeline can lead to complex pipelines that are hard for developers to understand and maintain. Ideally, a pipeline action should perform a single task and delegate the complexity of dealing with workflow-driven behavior associated with that task to a state machine engine. This would make it possible for developers to build simpler, more intuitive pipelines and allow them to use state machine execution logs to visualize and troubleshoot their pipeline actions.
In this blog post, we discuss how AWS Step Functions state machines can be used to handle workflow-driven actions. We show how a CodePipeline action can trigger a Step Functions state machine and how the pipeline and the state machine are kept decoupled through a Lambda function. The advantages of using state machines include:
- Simplified logic (complex tasks are broken into multiple smaller tasks).
- Ease of handling asynchronous behavior (through state machine wait states).
- Built-in support for choices and processing different execution paths (through state machine choices).
- Built-in visualization and logging of the state machine execution.
The source code for the sample pipeline, pipeline actions, and state machine used in this post is available at https://github.com/awslabs/aws-codepipeline-stepfunctions.
Overview
This figure shows the components in the CodePipeline-Step Functions integration that will be described in this post. The pipeline contains two stages: a Source stage represented by a CodeCommit Git repository and a Prod stage with a single Deploy action that represents the workflow-driven action.
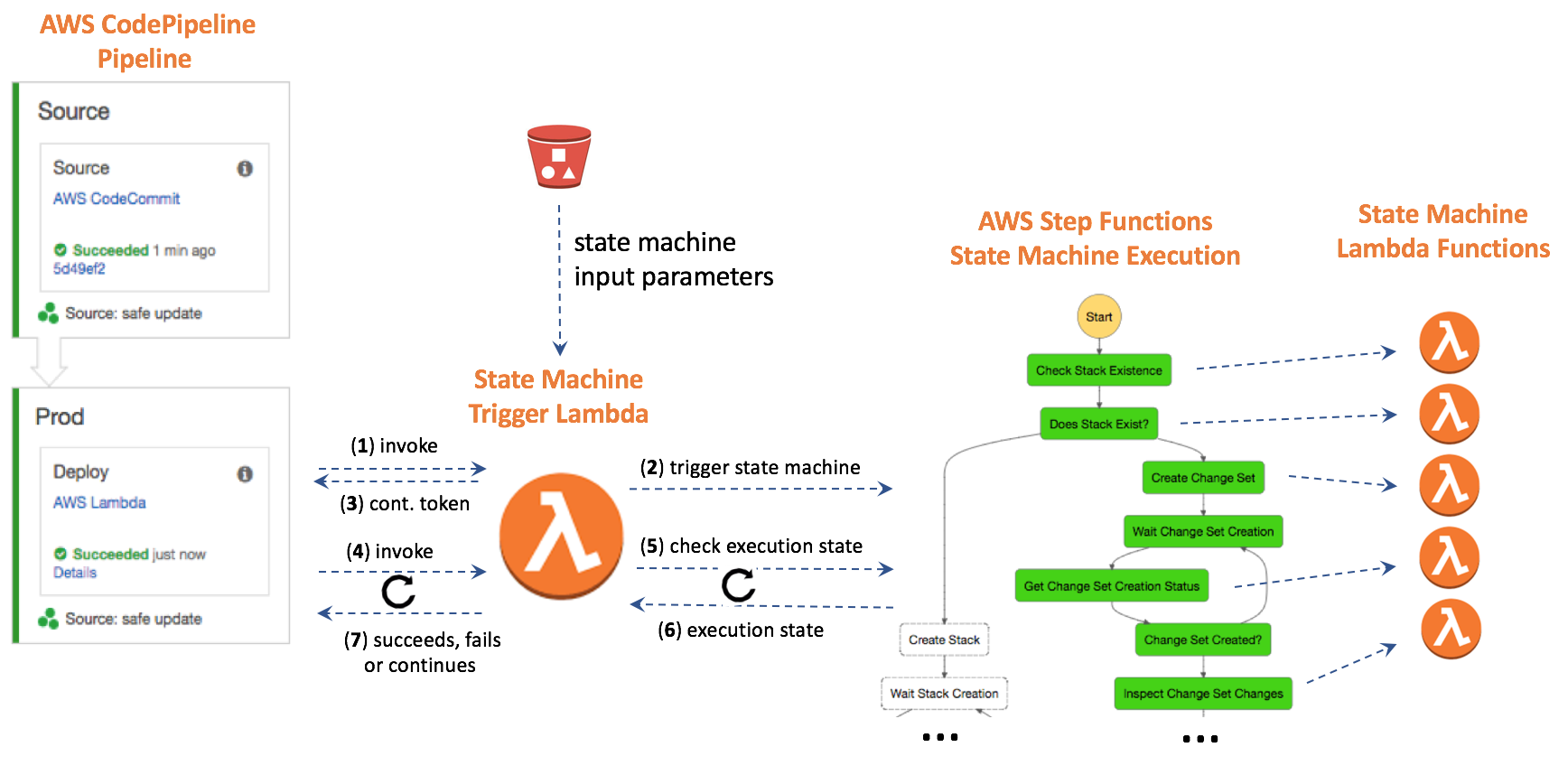
This action invokes a Lambda function (1) called the State Machine Trigger Lambda, which, in turn, triggers a Step Functions State Machine to process the request (2). The Lambda function sends a continuation token back to the pipeline (3) to continue its execution later and terminates. Seconds later, the pipeline invokes the Lambda function again (4), passing the continuation token received. The Lambda function checks the execution state of the state machine (5,6) and communicates the status to the pipeline. The process is repeated until the state machine execution is complete. Then the Lambda function notifies the pipeline that the corresponding pipeline action is complete (7). If the state machine has failed, the Lambda function will then fail the pipeline action and stop its execution (7). While running, the state machine triggers various Lambda functions to perform different tasks. The state machine and the pipeline are fully decoupled. Their interaction is handled by the Lambda function.
The Deploy State Machine
The sample state machine used in this post is a simplified version of the use case, with emphasis on infrastructure deployment. The state machine will follow distinct execution paths and thus have different outcomes, depending on:
- The current state of the AWS CloudFormation stack.
- The nature of the code changes made to the AWS CloudFormation template and pushed into the pipeline.
If the stack does not exist, it will be created. If the stack exists, a change set will be created and its resources inspected by the state machine. The inspection consists of parsing the change set results and detecting whether any resources will be deleted or replaced. If no resources are being deleted or replaced, the change set is allowed to be executed and the state machine completes successfully. Otherwise, the change set is deleted and the state machine completes execution with a failure as the terminal state.
Let’s dive into each of these execution paths.
Path 1: Create a Stack and Succeed Deployment
The Deploy state machine is shown here. It is triggered by the Lambda function using the following input parameters stored in an S3 bucket.

{
"environmentName": "prod",
"stackName": "sample-lambda-app",
"templatePath": "infra/Lambda-template.yaml",
"revisionS3Bucket": "codepipeline-us-east-1-418586629775",
"revisionS3Key": "StepFunctionsDrivenD/CodeCommit/sjcmExZ"
}Note that some values used here are for the use case example only. Account-specific parameters like revisionS3Bucket and revisionS3Key will be different when you deploy this use case in your account.
These input parameters are used by various states in the state machine and passed to the corresponding Lambda functions to perform different tasks. For example, stackName is used to create a stack, check the status of stack creation, and create a change set. The environmentName represents the environment (for example, dev, test, prod) to which the code is being deployed. It is used to prefix the name of stacks and change sets.
With the exception of built-in states such as wait and choice, each state in the state machine invokes a specific Lambda function. The results received from the Lambda invocations are appended to the state machine’s original input. When the state machine finishes its execution, several parameters will have been added to its original input.
The first stage in the state machine is “Check Stack Existence”. It checks whether a stack with the input name specified in the stackName input parameter already exists. The output of the state adds a Boolean value called doesStackExist to the original state machine input as follows:
{
"doesStackExist": true,
"environmentName": "prod",
"stackName": "sample-lambda-app",
"templatePath": "infra/lambda-template.yaml",
"revisionS3Bucket": "codepipeline-us-east-1-418586629775",
"revisionS3Key": "StepFunctionsDrivenD/CodeCommit/sjcmExZ",
}The following stage, “Does Stack Exist?”, is represented by Step Functions built-in choice state. It checks the value of doesStackExist to determine whether a new stack needs to be created (doesStackExist=true) or a change set needs to be created and inspected (doesStackExist=false).
If the stack does not exist, the states illustrated in green in the preceding figure are executed. This execution path creates the stack, waits until the stack is created, checks the status of the stack’s creation, and marks the deployment successful after the stack has been created. Except for “Stack Created?” and “Wait Stack Creation,” each of these stages invokes a Lambda function. “Stack Created?” and “Wait Stack Creation” are implemented by using the built-in choice state (to decide which path to follow) and the wait state (to wait a few seconds before proceeding), respectively. Each stage adds the results of their Lambda function executions to the initial input of the state machine, allowing future stages to process them.
Path 2: Safely Update a Stack and Mark Deployment as Successful

If the stack indicated by the stackName parameter already exists, a different path is executed. (See the green states in the figure.) This path will create a change set and use wait and choice states to wait until the change set is created. Afterwards, a stage in the execution path will inspect the resources affected before the change set is executed.
The inspection procedure represented by the “Inspect Change Set Changes” stage consists of parsing the resources affected by the change set and checking whether any of the existing resources are being deleted or replaced. The following is an excerpt of the algorithm, where changeSetChanges.Changes is the object representing the change set changes:
...
var RESOURCES_BEING_DELETED_OR_REPLACED = "RESOURCES-BEING-DELETED-OR-REPLACED";
var CAN_SAFELY_UPDATE_EXISTING_STACK = "CAN-SAFELY-UPDATE-EXISTING-STACK";
for (var i = 0; i < changeSetChanges.Changes.length; i++) {
var change = changeSetChanges.Changes[i];
if (change.Type == "Resource") {
if (change.ResourceChange.Action == "Delete") {
return RESOURCES_BEING_DELETED_OR_REPLACED;
}
if (change.ResourceChange.Action == "Modify") {
if (change.ResourceChange.Replacement == "True") {
return RESOURCES_BEING_DELETED_OR_REPLACED;
}
}
}
}
return CAN_SAFELY_UPDATE_EXISTING_STACK;The algorithm returns different values to indicate whether the change set can be safely executed (CAN_SAFELY_UPDATE_EXISTING_STACK or RESOURCES_BEING_DELETED_OR_REPLACED). This value is used later by the state machine to decide whether to execute the change set and update the stack or interrupt the deployment.
The output of the “Inspect Change Set” stage is shown here.
{
"environmentName": "prod",
"stackName": "sample-lambda-app",
"templatePath": "infra/lambda-template.yaml",
"revisionS3Bucket": "codepipeline-us-east-1-418586629775",
"revisionS3Key": "StepFunctionsDrivenD/CodeCommit/sjcmExZ",
"doesStackExist": true,
"changeSetName": "prod-sample-lambda-app-change-set-545",
"changeSetCreationStatus": "complete",
"changeSetAction": "CAN-SAFELY-UPDATE-EXISTING-STACK"
}At this point, these parameters have been added to the state machine’s original input:
- changeSetName, which is added by the “Create Change Set” state.
- changeSetCreationStatus, which is added by the “Get Change Set Creation Status” state.
- changeSetAction, which is added by the “Inspect Change Set Changes” state.
The “Safe to Update Infra?” step is a choice state (its JSON spec follows) that simply checks the value of the changeSetAction parameter. If the value is equal to “CAN-SAFELY-UPDATE-EXISTING-STACK“, meaning that no resources will be deleted or replaced, the step will execute the change set by proceeding to the “Execute Change Set” state. The deployment is successful (the state machine completes its execution successfully).
"Safe to Update Infra?": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.taskParams.changeSetAction",
"StringEquals": "CAN-SAFELY-UPDATE-EXISTING-STACK",
"Next": "Execute Change Set"
}
],
"Default": "Deployment Failed"
}Path 3: Reject Stack Update and Fail Deployment

If the changeSetAction parameter is different from “CAN-SAFELY-UPDATE-EXISTING-STACK“, the state machine will interrupt the deployment by deleting the change set and proceeding to the “Deployment Fail” step, which is a built-in Fail state. (Its JSON spec follows.) This state causes the state machine to stop in a failed state and serves to indicate to the Lambda function that the pipeline deployment should be interrupted in a fail state as well.
"Deployment Failed": {
"Type": "Fail",
"Cause": "Deployment Failed",
"Error": "Deployment Failed"
}In all three scenarios, there’s a state machine’s visual representation available in the AWS Step Functions console that makes it very easy for developers to identify what tasks have been executed or why a deployment has failed. Developers can also inspect the inputs and outputs of each state and look at the state machine Lambda function’s logs for details. Meanwhile, the corresponding CodePipeline action remains very simple and intuitive for developers who only need to know whether the deployment was successful or failed.
The State Machine Trigger Lambda Function
The Trigger Lambda function is invoked directly by the Deploy action in CodePipeline. The CodePipeline action must pass a JSON structure to the trigger function through the UserParameters attribute, as follows:
{
"s3Bucket": "codepipeline-StepFunctions-sample",
"stateMachineFile": "state_machine_input.json"
}The s3Bucket parameter specifies the S3 bucket location for the state machine input parameters file. The stateMachineFile parameter specifies the file holding the input parameters. By being able to specify different input parameters to the state machine, we make the Trigger Lambda function and the state machine reusable across environments. For example, the same state machine could be called from a test and prod pipeline action by specifying a different S3 bucket or state machine input file for each environment.
The Trigger Lambda function performs two main tasks: triggering the state machine and checking the execution state of the state machine. Its core logic is shown here:
exports.index = function (event, context, callback) {
try {
console.log("Event: " + JSON.stringify(event));
console.log("Context: " + JSON.stringify(context));
console.log("Environment Variables: " + JSON.stringify(process.env));
if (Util.isContinuingPipelineTask(event)) {
monitorStateMachineExecution(event, context, callback);
}
else {
triggerStateMachine(event, context, callback);
}
}
catch (err) {
failure(Util.jobId(event), callback, context.invokeid, err.message);
}
}Util.isContinuingPipelineTask(event) is a utility function that checks if the Trigger Lambda function is being called for the first time (that is, no continuation token is passed by CodePipeline) or as a continuation of a previous call. In its first execution, the Lambda function will trigger the state machine and send a continuation token to CodePipeline that contains the state machine execution ARN. The state machine ARN is exposed to the Lambda function through a Lambda environment variable called stateMachineArn. Here is the code that triggers the state machine:
function triggerStateMachine(event, context, callback) {
var stateMachineArn = process.env.stateMachineArn;
var s3Bucket = Util.actionUserParameter(event, "s3Bucket");
var stateMachineFile = Util.actionUserParameter(event, "stateMachineFile");
getStateMachineInputData(s3Bucket, stateMachineFile)
.then(function (data) {
var initialParameters = data.Body.toString();
var stateMachineInputJSON = createStateMachineInitialInput(initialParameters, event);
console.log("State machine input JSON: " + JSON.stringify(stateMachineInputJSON));
return stateMachineInputJSON;
})
.then(function (stateMachineInputJSON) {
return triggerStateMachineExecution(stateMachineArn, stateMachineInputJSON);
})
.then(function (triggerStateMachineOutput) {
var continuationToken = { "stateMachineExecutionArn": triggerStateMachineOutput.executionArn };
var message = "State machine has been triggered: " + JSON.stringify(triggerStateMachineOutput) + ", continuationToken: " + JSON.stringify(continuationToken);
return continueExecution(Util.jobId(event), continuationToken, callback, message);
})
.catch(function (err) {
console.log("Error triggering state machine: " + stateMachineArn + ", Error: " + err.message);
failure(Util.jobId(event), callback, context.invokeid, err.message);
})
}The Trigger Lambda function fetches the state machine input parameters from an S3 file, triggers the execution of the state machine using the input parameters and the stateMachineArn environment variable, and signals to CodePipeline that the execution should continue later by passing a continuation token that contains the state machine execution ARN. In case any of these operations fail and an exception is thrown, the Trigger Lambda function will fail the pipeline immediately by signaling a pipeline failure through the putJobFailureResult CodePipeline API.
If the Lambda function is continuing a previous execution, it will extract the state machine execution ARN from the continuation token and check the status of the state machine, as shown here.
function monitorStateMachineExecution(event, context, callback) {
var stateMachineArn = process.env.stateMachineArn;
var continuationToken = JSON.parse(Util.continuationToken(event));
var stateMachineExecutionArn = continuationToken.stateMachineExecutionArn;
getStateMachineExecutionStatus(stateMachineExecutionArn)
.then(function (response) {
if (response.status === "RUNNING") {
var message = "Execution: " + stateMachineExecutionArn + " of state machine: " + stateMachineArn + " is still " + response.status;
return continueExecution(Util.jobId(event), continuationToken, callback, message);
}
if (response.status === "SUCCEEDED") {
var message = "Execution: " + stateMachineExecutionArn + " of state machine: " + stateMachineArn + " has: " + response.status;
return success(Util.jobId(event), callback, message);
}
// FAILED, TIMED_OUT, ABORTED
var message = "Execution: " + stateMachineExecutionArn + " of state machine: " + stateMachineArn + " has: " + response.status;
return failure(Util.jobId(event), callback, context.invokeid, message);
})
.catch(function (err) {
var message = "Error monitoring execution: " + stateMachineExecutionArn + " of state machine: " + stateMachineArn + ", Error: " + err.message;
failure(Util.jobId(event), callback, context.invokeid, message);
});
}If the state machine is in the RUNNING state, the Lambda function will send the continuation token back to the CodePipeline action. This will cause CodePipeline to call the Lambda function again a few seconds later. If the state machine has SUCCEEDED, then the Lambda function will notify the CodePipeline action that the action has succeeded. In any other case (FAILURE, TIMED-OUT, or ABORT), the Lambda function will fail the pipeline action.
This behavior is especially useful for developers who are building and debugging a new state machine because a bug in the state machine can potentially leave the pipeline action hanging for long periods of time until it times out. The Trigger Lambda function prevents this.
Also, by having the Trigger Lambda function as a means to decouple the pipeline and state machine, we make the state machine more reusable. It can be triggered from anywhere, not just from a CodePipeline action.
The Pipeline in CodePipeline
Our sample pipeline contains two simple stages: the Source stage represented by a CodeCommit Git repository and the Prod stage, which contains the Deploy action that invokes the Trigger Lambda function. When the state machine decides that the change set created must be rejected (because it replaces or deletes some the existing production resources), it fails the pipeline without performing any updates to the existing infrastructure. (See the failed Deploy action in red.) Otherwise, the pipeline action succeeds, indicating that the existing provisioned infrastructure was either created (first run) or updated without impacting any resources. (See the green Deploy stage in the pipeline on the left.)

The JSON spec for the pipeline’s Prod stage is shown here. We use the UserParameters attribute to pass the S3 bucket and state machine input file to the Lambda function. These parameters are action-specific, which means that we can reuse the state machine in another pipeline action.
{
"name": "Prod",
"actions": [
{
"inputArtifacts": [
{
"name": "CodeCommitOutput"
}
],
"name": "Deploy",
"actionTypeId": {
"category": "Invoke",
"owner": "AWS",
"version": "1",
"provider": "Lambda"
},
"outputArtifacts": [],
"configuration": {
"FunctionName": "StateMachineTriggerLambda",
"UserParameters": "{\"s3Bucket\": \"codepipeline-StepFunctions-sample\", \"stateMachineFile\": \"state_machine_input.json\"}"
},
"runOrder": 1
}
]
}Conclusion
In this blog post, we discussed how state machines in AWS Step Functions can be used to handle workflow-driven actions. We showed how a Lambda function can be used to fully decouple the pipeline and the state machine and manage their interaction. The use of a state machine greatly simplified the associated CodePipeline action, allowing us to build a much simpler and cleaner pipeline while drilling down into the state machine’s execution for troubleshooting or debugging.
Here are two exercises you can complete by using the source code.
Exercise #1: Do not fail the state machine and pipeline action after inspecting a change set that deletes or replaces resources. Instead, create a stack with a different name (think of blue/green deployments). You can do this by creating a state machine transition between the “Safe to Update Infra?” and “Create Stack” stages and passing a new stack name as input to the “Create Stack” stage.
Exercise #2: Add wait logic to the state machine to wait until the change set completes its execution before allowing the state machine to proceed to the “Deployment Succeeded” stage. Use the stack creation case as an example. You’ll have to create a Lambda function (similar to the Lambda function that checks the creation status of a stack) to get the creation status of the change set.
Have fun and share your thoughts!
About the Author

Marcilio Mendonca is a Sr. Consultant in the Canadian Professional Services Team at Amazon Web Services. He has helped AWS customers design, build, and deploy best-in-class, cloud-native AWS applications using VMs, containers, and serverless architectures. Before he joined AWS, Marcilio was a Software Development Engineer at Amazon. Marcilio also holds a Ph.D. in Computer Science. In his spare time, he enjoys playing drums, riding his motorcycle in the Toronto GTA area, and spending quality time with his family.