AWS Developer Tools Blog
Centralize Amazon CloudWatch Logs using AWS CDK
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
One of the most common use cases that customers try to implement is to centralize various types of logs in their AWS infrastructure so that these logs can be utilized for security, monitoring or analytics purposes. Centralizing AWS services logs means pushing all the logs generated by the various AWS services used to one single location. With a central location, customers can easily manage logs generated across all the accounts in their organization and enforce restrictions and security for this data. Centralizing logs also allows to setup a process to backup this data and setup life-cycle policies for data retention.
Amazon CloudWatch is a monitoring and observability service built for DevOps engineers, developers, site reliability engineers (SREs), and IT managers. CloudWatch provides data and actionable insights to monitor your applications, respond to system-wide performance changes, optimize resource utilization, and get a unified view of operational health. It integrates with more than 70 AWS services such as Amazon EC2, Amazon DynamoDB, Amazon S3, Amazon ECS, Amazon EKS, and AWS Lambda, and automatically publishes detailed 1-minute metrics and custom metrics with up to 1-second granularity so you can dive deep into your logs for additional context. Amazon CloudWatch Logs enables you to centralize the logs from all of your systems, applications, and AWS services that you use, in a single, highly scalable service. You can then easily view them, search them for specific error codes or patterns, filter them based on specific fields, or archive them securely for future analysis. This opens up the ability to design and setup a common pattern to pick up these logs from CloudWatch log groups and push them to a centralized location like Amazon S3. All logs are from S3 can be queried using Amazon Athena, or pushed to a data warehouse like Amazon Redshift for big data processing etc.
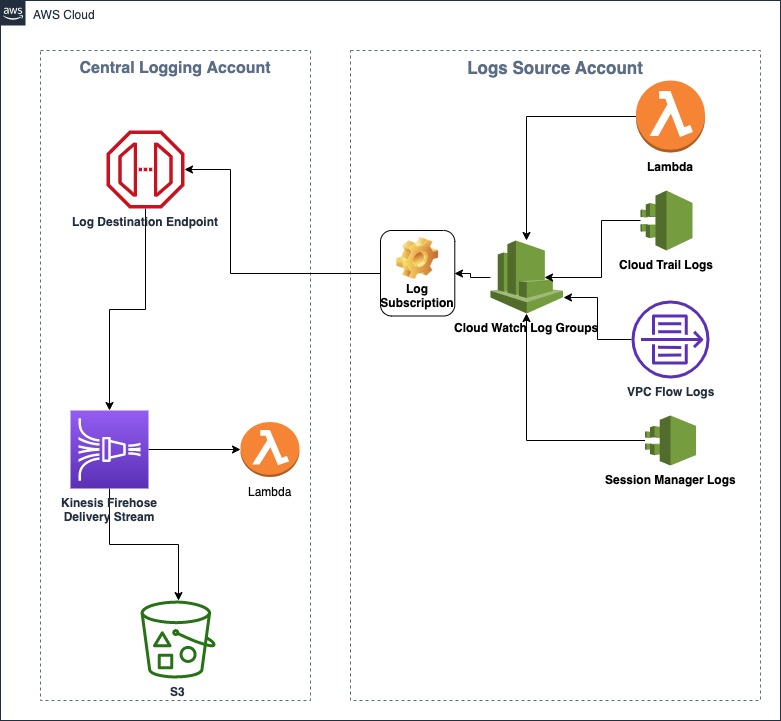
Solution Overview
This solution mainly utilizes the power of Amazon Kinesis Data Firehose which provides the ability to process data in real-time; allowing critical use cases to be implemented based on this data. The centralized logging account will expose a Log Destination endpoint which in turn is connected to a Kinesis Firehose. Amazon Kinesis Firehose is configured to push all the data to an Amazon S3 Bucket. Firehose also invokes an AWS Lambda function to decompress and format the data before it is pushed to an S3 bucket. Kinesis Firehose configuration allows to transform the data using AWS Glue before pushing it to the destination. Along with S3 as a destination Firehose also supports other destinations like Amazon Redshift, Amazon Elasticsearch Service and Splunk. This solution does not provide data transformation using Glue but it would be something that can be easily integrated into this solution if needed.
AWS services used in this solution
- Amazon Kinesis Data Firehose – is the easiest way to reliably load streaming data into data lakes, data stores and analytics tools.
- AWS Lambda – lets you run code without provisioning or managing servers. You pay only for the compute time you consume.
- Amazon Simple Storage Service (Amazon S3) – an object storage service that offers industry-leading scalability, data availability, security, and performance.
- AWS Cloud Development Kit (AWS CDK) is an open source software development framework to model and provision your cloud application resources using familiar programming languages.
Deployment Steps
Pre-Requisites:
- AWS Account with AWS CLI access.
- CloudWatch Log Group which can be used as the source for the logs data. If not available create a blueprint hello-world lambda and test it once to automatically create a corresponding CloudWatch log group.
Commands to Deploy the Solution to AWS:
Clone the solution code from GitHub
$ git clone https://github.com/aws-samples/aws-centralize-logs-using-cdk.git Once code is downloaded run the below commands to compile the solution on your computer.
$ cd central-logs-cdk
$ dotnet build srcIf deploying the solution to a single AWS account:
Step 1: Run the below command which will prepare the environment with resources that will be required for the deployment.
$ cdk bootstrapStep 2: Run the below command (Replace AWS-ACCOUNT-ID with your AWS Account number before executing the command.) to deploy the resources needed to receive, process and push the logs to S3.
$ cdk deploy LogDestinationStack --parameters LogDestinationStack:SourceAccountNumber="*AWS-ACCOUNT-ID*"Note: Verify the output of the command. If it successful your command line will display an Output with the LogDestinationARN as shown below. You can also verify the same in AWS console as show below. Copy the value of the LogDestinationARN from the output before proceeding to Step 2.

Step 3: Copy the value of LogDestinationArn from the output of the LogDestinationStack deployment above (or can get it from the AWS Console; It will be in the outputs tab.) and replace LOG-DESTINATION-ARN with that. Also, replace CLOUDWATCH-LOGGROUP with the name of CloudWatch Log group before executing the below command.
$ cdk deploy LogSourceStack --parameters LogSourceStack:LogGroupName="*CLOUDWATCH-LOGGROUP*" --parameters LogDestinationArn="*LOG-DESTINATION-ARN*"If deploying the solution to separate source and destination AWS accounts:
Step 1: Run the below command(s) against the Logs Destination AWS Account where the Logs will be stored in S3 bucket (Replace SOURCE-AWS-ACCOUNT-ID with the account number of the source AWS account before executing the command.)
$ cdk deploy LogDestinationStack --parameters LogDestinationStack:SourceAccountNumber="*SOURCE-AWS-ACCOUNT-ID*"
Step 2: Run the below command(s) against the Logs Source AWS Account which has the CloudWatch Logs. Copy the value of LogDestinationArn from the output of the LogDestinationStack deployment above and replace LOG-DESTINATION-ARN with that. Also, replace CLOUDWATCH-LOGGROUP with the name of CloudWatch Log group before executing the command.
$ cdk bootstrap
$ cdk deploy LogSourceStack --parameters LogSourceStack:LogGroupName="*CLOUDWATCH-LOGGROUP*" --parameters LogDestinationArn="*LOG-DESTINATION-ARN*"Testing/Validating the Solution
Once the commands are executed successfully, all the required AWS services are deployed in your Account(s). The CloudWatch Log group you used while deploying the LogSourceStack is now subscribed to push all Logs it receives over to the Kinesis Data Firehose which in-turn pushes them to the S3 bucket (central-logs-ACCOUNT-ID). Below diagram shows the S3 bucket where the logs will be stored.

Clean Up
- Delete the S3 Bucket which was created to store the Logs (Run against the AWS Account where the LogDestination Stack was deployed). Replace AWS-ACCOUNT-ID with the AWS account number before executing the command.
$ aws s3 rb s3://central-logs-*AWS-ACCOUNT-ID* --force- Run the below command to clean up resources deployed with LogSource Stack.
$ cdk destroy LogSourceStack
- Run the below command to clean up resources deployed with LogDestination Stack.
$ cdk destroy LogDestinationStackConclusion
This blog highlights the criticality of log data and how CloudWatch Logs are a great source for organizations to leverage this for business critical use cases. The solution provided here will allow customers to quickly configure and deploy this solution to their existing infrastructure and start the process of centralizing AWS logs. The article also showcases the advantages of using AWS CDK to build and deploy your Infrastructure as Code. AWS CDK’s support of various programming languages allows developers in the organization to code infrastructure with the programming language they are most comfortable with.
Please do share any feedback/comments you have about this blog in the comments section. In case you plan to deploy this solution and have any questions, do reach out to me here using the comments section or on GitHub.
References
About The Author

Naveen Balaraman is a Cloud Application Architect at Amazon Web Services. He is passionate about Containers, Serverless Applications, Architecting Microservices and helping customers leverage the power of AWS cloud.