AWS Database Blog
Introducing Amazon Elasticsearch Service as a target in AWS Database Migration Service
We’re excited to announce the addition of a new target in AWS Database Migration Service (AWS DMS)—Amazon Elasticsearch Service. You can now migrate data to Amazon Elasticsearch Service from all AWS DMS–supported sources. With support for this new target, you can use DMS in your data integration pipelines to replicate data in near-real time into Amazon Elasticsearch Service.
Amazon Elasticsearch Service is a fully managed service that makes it easy for you to deploy, secure, and operate Elasticsearch at scale. The service offers open-source Elasticsearch API operations, managed Kibana, and integrations with Logstash and other AWS services. These features enable you to search, analyze, and visualize your data in real time for log analytics, full-text search, application monitoring, and security analytics use cases.
Although searches using Amazon Elasticsearch Service are powerful, we wanted to make it easier for you to get data from multiple data stores to Amazon Elasticsearch Service. We wanted to make sure that you can load bulk data from a point in time. We also wanted to make sure that change data is replicated in near-real time with complete support for combining and mapping data in transit as required. AWS DMS helps you migrate data from any of its supported sources today. Using DMS, you can migrate the data that you need in a faster and more secure manner.
Many large enterprises and tech startups who are doing data analytics and processing or are in the business of e-commerce or search services are all about data. With huge databases, most common problems faced are related to latency in retrieving product information. This latency leads to poor user experience and in turn turns off potential customers. It becomes increasingly difficult to provide great webpage response times as the amount of data grows. Use cases grow more complex, and organizations find themselves trying to provide subsecond page load times while managing millions, and at times billions, of database records. This problem is exacerbated by searching and filtering large datasets. It takes a lot of expertise to scale relational databases (such as Oracle, SQL Server, and so on) to page through billions of records while using complex and dynamic filters.
Businesses nowadays are looking for alternatives for where the data is stored to promote quick retrieval. This can be achieved by adopting NoSQL rather than relational databases for storing data. Amazon Elasticsearch is a full-text, distributed NoSQL database. In other words, it uses documents rather than schema or tables, which allows for real-time search and analysis of your data. People appreciate this system because it allows you to run metrics on your data immediately, so you can understand it right away, on an ongoing basis.
The following are some use cases where Elasticsearch is well-suited for performance:
- Indexing all rows and providing fielded search with Boolean combinations of those fields
- Native handling of natural language text to provide relevant free-text search
- Providing relevant results
- Providing autocomplete and search suggestions
- Supporting faceting and faceted drill-down
- Supporting dates and GEO locations for local search
Amazon Elasticsearch Service is generally fantastic at providing scored, sorted results based on the best information in the search engine. Finding approximate answers is a property that separates Amazon ES from more traditional databases.
In summary, at AWS our aim is to help you rearchitect your applications and databases to suit your use case and requirements. By adding support for migrating and replicating data to Amazon ES using AWS DMS, we provide more flexibility. We also provide a less complex approach when coming to moving data from RDBMS to Amazon ES.
Some of the features that we now support for Amazon Elasticsearch Service as a target are these:
- All versions of Amazon Elasticsearch Service are supported. You can find more details in this documentation.
- Migrating data from all AWS DMS supported sources
- Migrating data with SSL connectivity support
- Replicating ongoing changes
Using AWS DMS to migrate your data
AWS DMS can do a one-time data migration, or it can do a continuous replication of the data from any of our supported sources to an Amazon ES target. These sources include relational databases (such as Oracle and Amazon Aurora), a NoSQL database (MongoDB), or an Amazon S3 bucket.
How to add an Amazon ES cluster as a target
Follow these steps to add an Amazon Elasticsearch Service Database Target to AWS DMS:
- Sign in to the AWS Management Console, and choose Database Migration Service.
- In the navigation pane, choose Endpoints, and then choose Create Endpoint.
- Choose the following:
- Endpoint type: Target
- Target engine: elasticsearch
- Service access role ARN: You need to provide the appropriate IAM role that has access to the Amazon ES cluster.
- Following are the minimum level of permissions required for migration using AWS DMS.
Role Trust Policy:
Role Permissions:
- Endpoint URI: This value is the Amazon ES cluster endpoint.
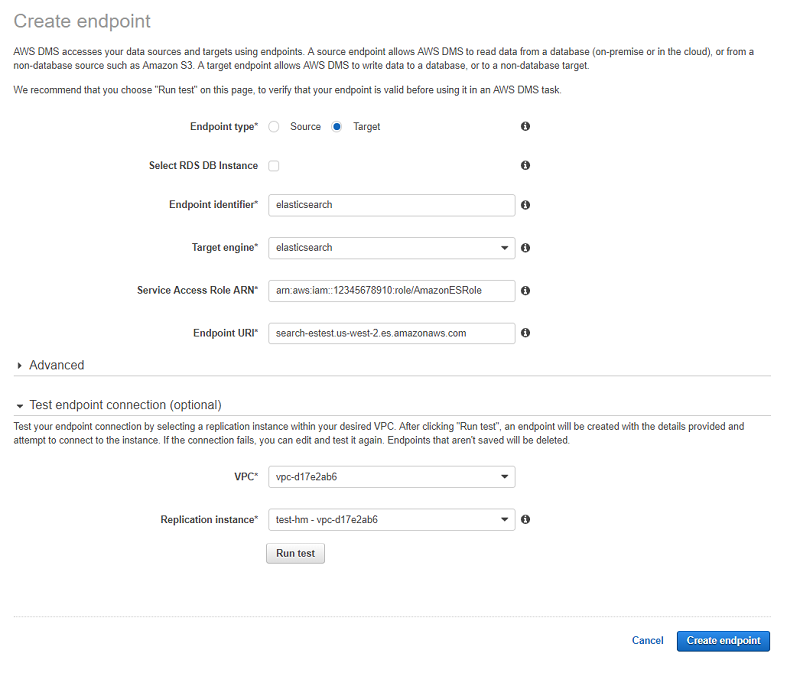
You can also create the endpoint for Amazon Elasticsearch Service in AWS DMS by using the following AWS CLI command:
Table mappings
When you create a migration task, you tell AWS DMS exactly how you want your data migrated. Within a task, you define which tables you want migrated, where you want them migrated, and how you want them migrated.
Table mappings tell AWS DMS which tables a task should migrate from source to target. Table mappings are expressed in JSON, though you can make some settings by using the AWS Management Console. Table mappings can also include transformations such as changing table names from uppercase to lowercase.
AWS DMS generates default table mappings for each (nonsystem) schema in the source database. In most cases, you want to customize your table mapping. Amazon Elasticsearch Service is a NoSQL document database. Thus, for efficient searches and data retrieval, schema design when going from a relational database to Amazon ES is really important.
Following is an example how AWS DMS can move the data to an Amazon ES cluster.
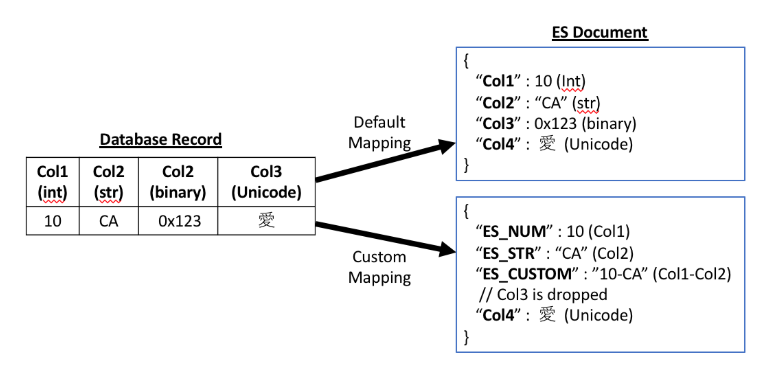
The default mapping means that if you have table mappings, JSON sets them in AWS DMS like this.
The way you can achieve custom mapping migration in DMS is by using object-mapping. An example to achieve the preceding table design in Amazon ES is by using the following mapping.
Conclusion
Overall, by using AWS DMS, it’s now simple to migrate and replicate data to Amazon Elasticsearch Service from any supported OLTP and OLAP database. AWS DMS replication helps reduce the downtime during the migration, which is important for databases supporting mission-critical applications. Feel free to take this new target support for a spin, and let us know what you think in the comments below.
Learn more
We recently crossed 98,000 migrations and celebrating the same by writing a blog post that summarizes our latest release.
For more information about AWS Database Migration Service and the AWS Schema Conversion Tool, see the AWS website.
About the Author
 Abhinav Singh is a database engineer in Database Migration Service at Amazon Web Services. He works with our customers to provide guidance and technical assistance on database migration projects, helping them improve the value of their solutions when using AWS.
Abhinav Singh is a database engineer in Database Migration Service at Amazon Web Services. He works with our customers to provide guidance and technical assistance on database migration projects, helping them improve the value of their solutions when using AWS.