AWS Compute Blog
Tag: serverless
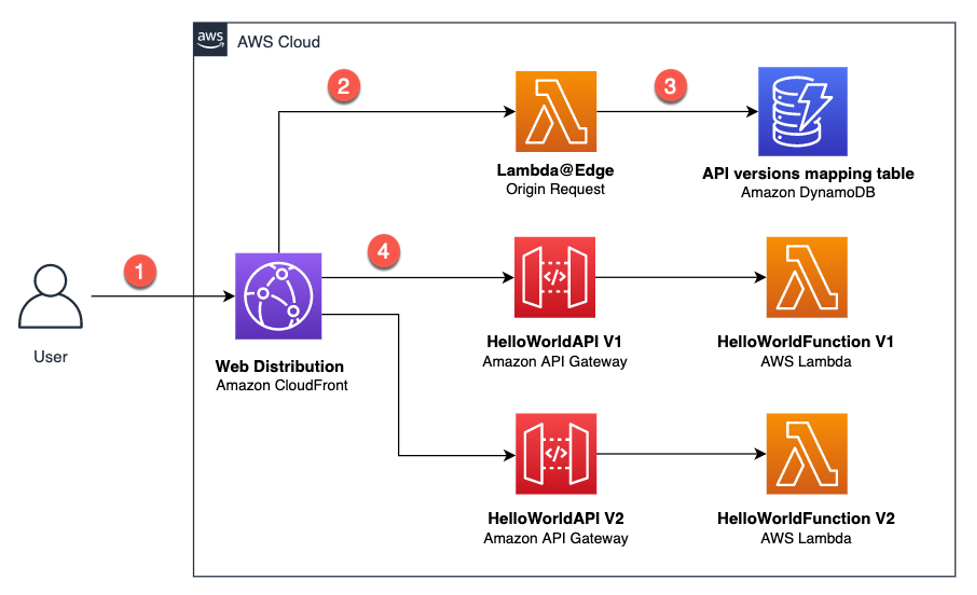
Implementing header-based API Gateway versioning with Amazon CloudFront
This post is written by Amir Khairalomoum, Sr. Solutions Architect. In this blog post, I show you how to use Lambda@Edge feature of Amazon CloudFront to implement a header-based API versioning solution for Amazon API Gateway. Amazon API Gateway is a fully managed service that makes it easier for developers to create, publish, maintain, monitor, […]

Introducing cross-account Amazon ECR access for AWS Lambda
This post is written by Brian Zambrano, Enterprise Solutions Architect and Indranil Banerjee, Senior Solution Architect. In December 2020, AWS announced support for packaging AWS Lambda functions using container images. Customers use the container image packaging format for workloads like machine learning inference made possible by the 10 GB container size increase and familiar container […]
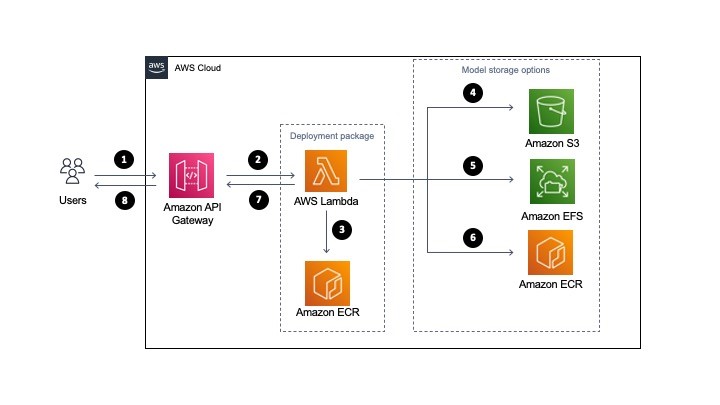
Choosing between storage mechanisms for ML inferencing with AWS Lambda
This post is written by Veda Raman, SA Serverless, Casey Gerena, Sr Lab Engineer, Dan Fox, Principal Serverless SA. For real-time machine learning inferencing, customers often have several machine learning models trained for specific use-cases. For each inference request, the model must be chosen dynamically based on the input parameters. This blog post walks through the architecture […]
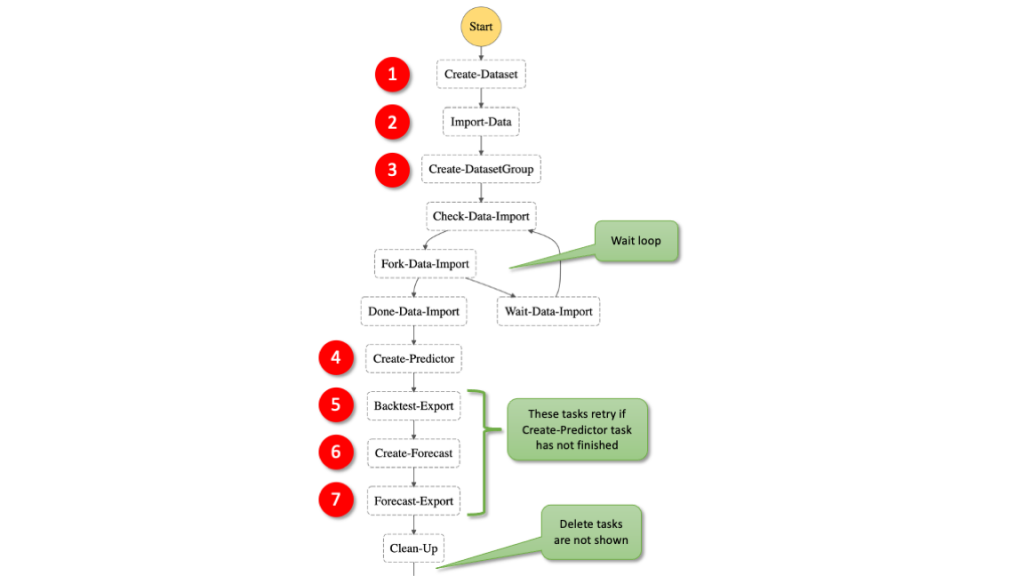
Build workflows for Amazon Forecast with AWS Step Functions
This post shows how to create a Step Functions workflow for Forecast using AWS SDK service integrations, which allows you to use over 200 with AWS API actions. It shows two patterns for handling asynchronous tasks. The first pattern queries the describe-* API repeatedly and the second pattern uses the “Retry” option. This simplifies the development of workflows because in many cases they can replace Lambda functions.
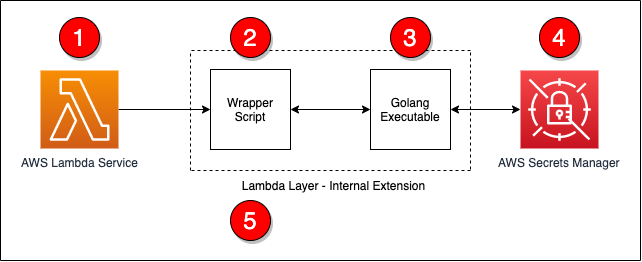
Creating AWS Lambda environment variables from AWS Secrets Manager
This solution provides a way to convert information from Secrets Manager into Lambda environment variables. By following this approach, you can centralize the management of information through Secrets Manager, instead of at the function level.

Accelerating serverless development with AWS SAM Accelerate
Building a serverless application changes the way developers think about testing their code. Previously, developers would emulate the complete infrastructure locally and only commit code ready for testing. However, with serverless, local emulation can be more complex. In this post, I show you how to bypass most local emulation by testing serverless applications in the […]
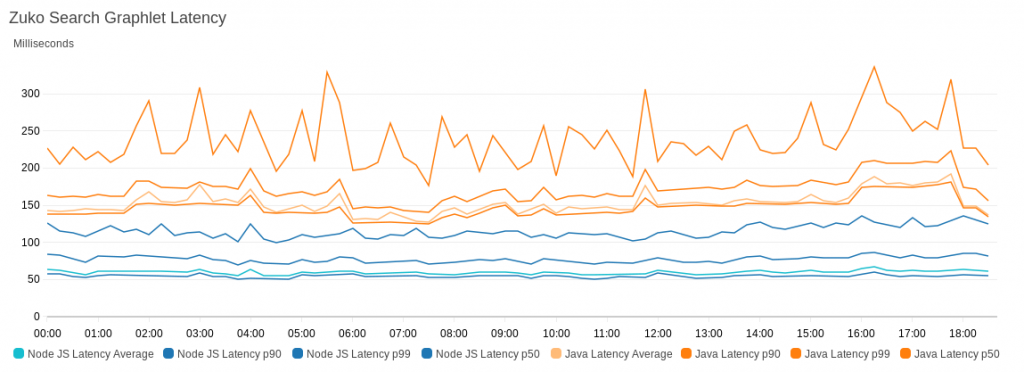
Monitoring and tuning federated GraphQL performance on AWS Lambda
There are multiple factors to consider when tuning a federated GQL system. You must be aware of trade-offs when deciding on factors like the runtime environment of Lambda functions. An extensive testing strategy can help you scale systems and narrow down issues quickly. Well-defined testing can also keep pipelines clean of false-positive blockages.
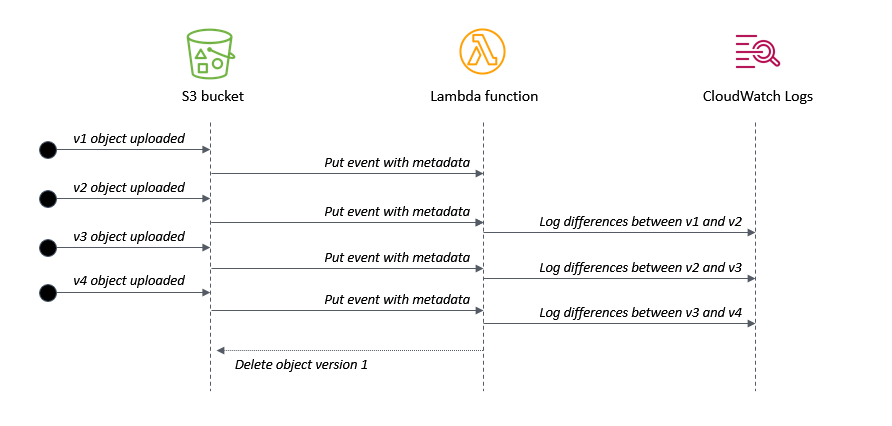
Building a difference checker with Amazon S3 and AWS Lambda
This blog post shows how to create a scalable difference checking tool for objects stored in S3 buckets. The Lambda function is invoked when S3 writes new versions of an object to the bucket. This example also shows how to remove earlier versions of object and define a set number of versions to retain.
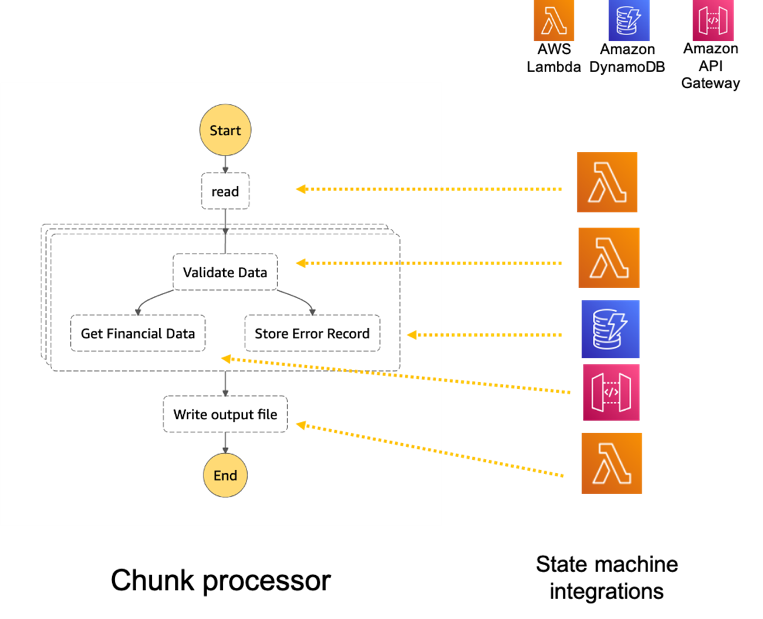
Creating AWS Serverless batch processing architectures
This blog post shows how to use Step Functions’ features and integrations to orchestrate a batch processing solution. You use two Steps Functions workflows to implement batch processing, with one workflow splitting the original file and a second workflow processing each chunk file.
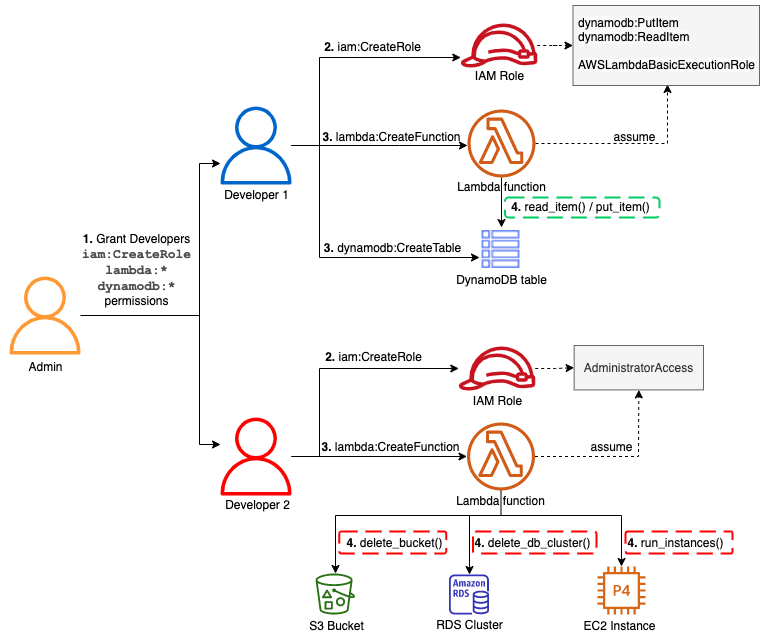
Operating serverless at scale: Keeping control of resources – Part 3
This post describes guardrails that you can set up in your accounts or across the organization to keep control over deployed resources. These guardrails can be more or less restrictive according to your requirements.