AWS Compute Blog
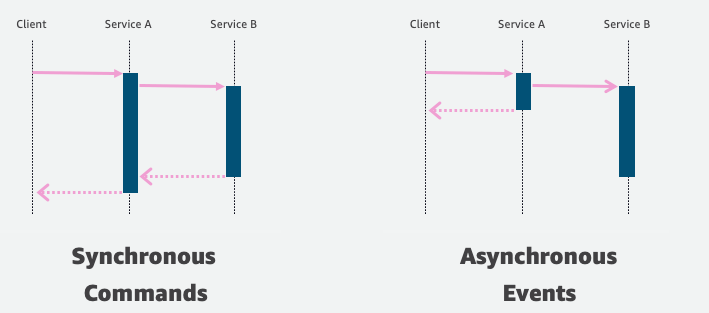
Getting started with event-driven architecture
In modern application development, event-driven architecture is becoming more prominent because it can make building applications in the cloud easier. Event-driven architecture can allow you to decouple your services, which increases developer velocity, and can make it easier for you to debug applications. It also can help remove the bottleneck that occurs when features expand […]
ICYMI: Serverless Q1 2022
Welcome to the 17th edition of the AWS Serverless ICYMI (in case you missed it) quarterly recap. Every quarter, we share all the most recent product launches, feature enhancements, blog posts, webinars, Twitch live streams, and other interesting things that you might have missed! In case you missed our last ICYMI, check out what happened […]
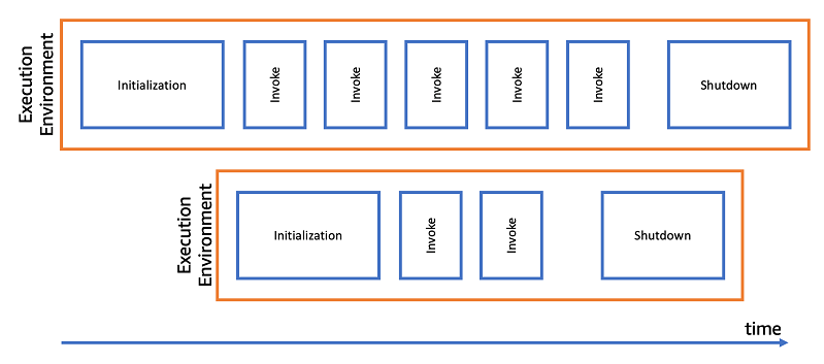
Optimizing AWS Lambda function performance for Java
This post is written by Mark Sailes, Senior Specialist Solutions Architect. This blog post shows how to optimize the performance of AWS Lambda functions written in Java, without altering any of the function code. It shows how Java virtual machine (JVM) settings affect the startup time and performance. You also learn how you can benchmark […]

Using AWS Step Functions and Amazon DynamoDB for business rules orchestration
In this post, you learned how to leverage an orchestration framework using Step Functions, Lambda, DynamoDB, and API Gateway to build an API backed by an open-source Drools rules engine, running on a container. Try this solution for your cloud native business rules orchestration use-case.
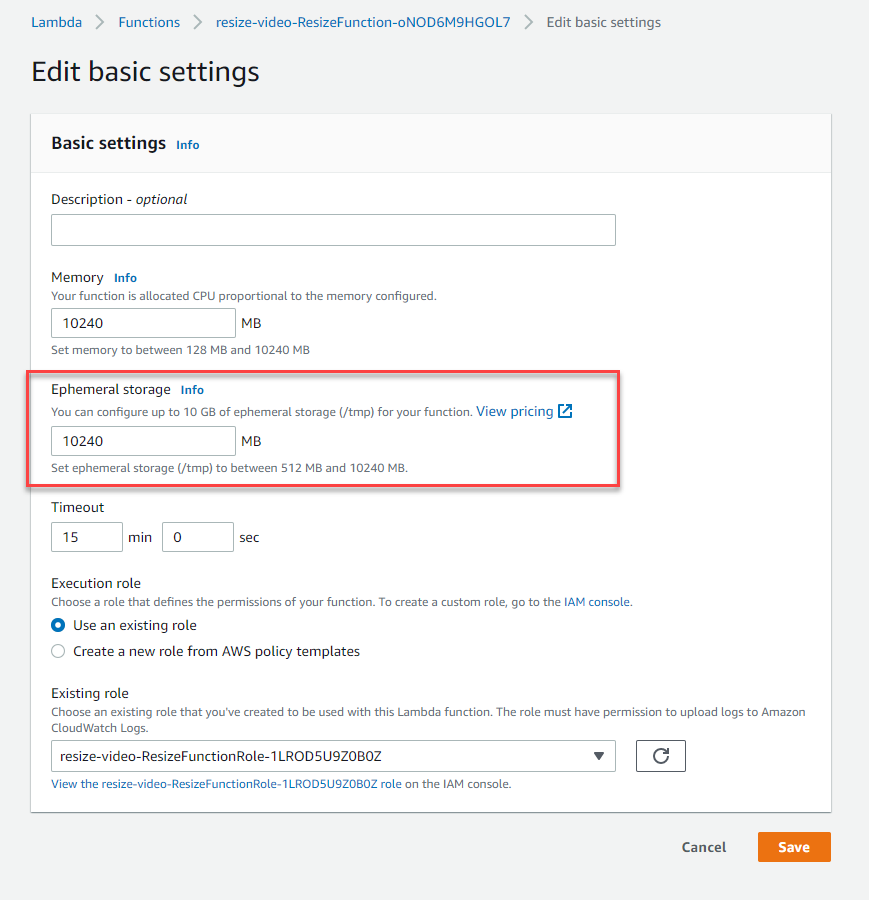
Using larger ephemeral storage for AWS Lambda
Serverless developers can now configure the amount of temporary storage available in AWS Lambda functions. This blog post discusses common use cases and walks through an example application that uses larger temporary storage.

How to re-platform and modernize Java web applications on AWS
This post is written by: Bill Chan, Enterprise Solutions Architect According to a report from Grand View Research, “the global application server market size was valued at USD 15.84 billion in 2020 and is expected to expand at a compound annual growth rate (CAGR) of 13.2% from 2021 to 2028.” The report also suggests that […]

Choosing the right solution for AWS Lambda external parameters
This post is written by Thomas Moore, Solutions Architect, Serverless. When using AWS Lambda to build serverless applications, customers often need to retrieve parameters from an external source at runtime. This allows you to share parameter values across multiple functions or microservices, providing a single source of truth for updates. A common example is retrieving […]
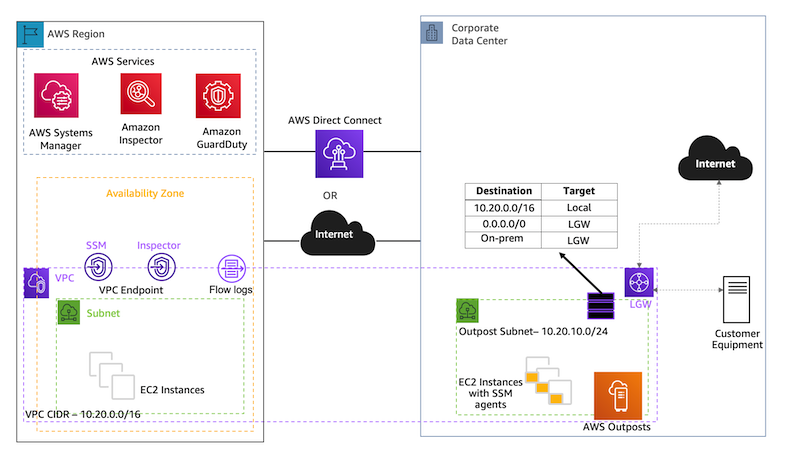
Managing and Securing AWS Outposts Instances using AWS Systems Manager, Amazon Inspector, and Amazon GuardDuty
This post is written by Sumeeth Siriyur, Specialist Solutions Architect. AWS Outposts is a family of fully managed solutions that deliver AWS infrastructure and services to virtually any on-premises or edge location for a truly consistent hybrid experience. Outposts is ideal for workloads that need low latency access to on-premises applications or systems, local data […]

Automate the Creation of On-Demand Capacity Reservations for running EC2 instances
This post is written by Ballu Singh a Principal Solutions Architect at AWS, Neha Joshi a Senior Solutions Architect at AWS, and Naveen Jagathesan a Technical Account Manager at AWS. Customers have asked how they can “create On-Demand Capacity Reservations (ODCRs) for their existing instances during events, such as the holiday season, Black Friday, marketing […]

Sending events to Amazon EventBridge from AWS Organizations accounts
This blog post shows how to use AWS Organizations to organize your application’s accounts by using organization units and how to centralize event management using Amazon EventBridge across accounts in the organization. A fully automated solution is provided to ensure that adding new accounts to the organization unit is efficient.