AWS Compute Blog
Creating a serverless Apache Kafka publisher using AWS Lambda
This post is written by Philipp Klose, Global Solution Architect, and Daniel Wessendorf, Global Solution Architect.
Streaming data and event-driven architectures are becoming more popular for many modern systems. The range of use cases includes web tracking and other logs, industrial IoT, in-game player activity, and the ingestion of data for modern analytics architecture.
One of the most popular technologies in this space is Apache Kafka. This is an open-source distributed event streaming platform used by many customers for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Kafka is based on a simple but powerful pattern. The Kafka cluster itself is a highly available broker that receives messages from various producers. The received messages are stored in topics, which are the primary storage abstraction.
Various consumers can subscribe to a Kafka topic and consume messages. In contrast to classic queuing systems, the consumers do not remove the message from the topic but store the individual reading position on the topic. This allows for multiple different patterns for consumption (for example, fan-out or consumer-groups).

Producer and consumer libraries for Kafka are available in various programming languages and technologies. This blog post focuses on using serverless and cloud-native technologies for the producer side.
Overview
This example walks you through how to build a serverless real-time stream producer application using Amazon API Gateway and AWS Lambda.
For testing, this blog includes a sample AWS Cloud Development Kit (CDK) application. This creates a demo environment, including an Amazon Managed Streaming for Apache Kafka (MSK) cluster and a bastion host for observing the produced messages on the cluster.
The following diagram shows the architecture of an application that pushes API requests to a Kafka topic in real time, which you build in this blog post:
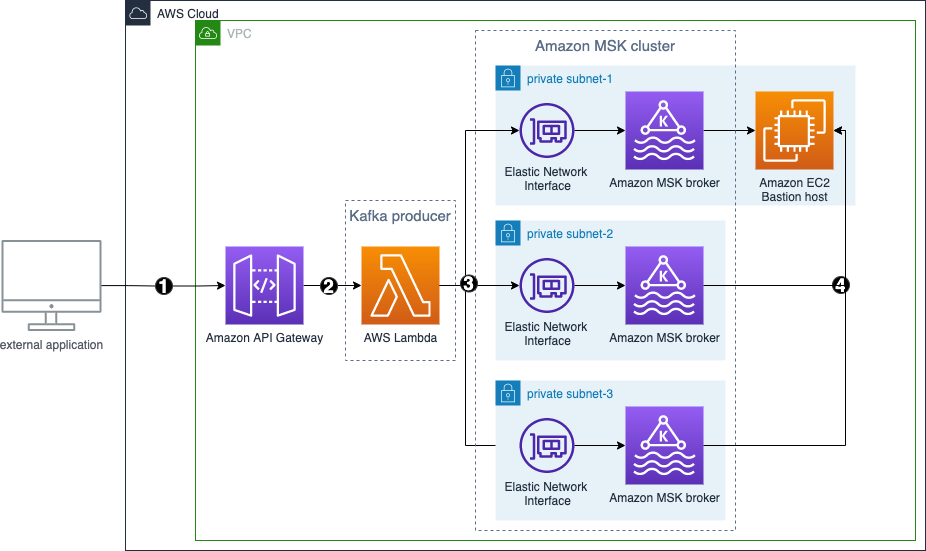
- An external application calls an Amazon API Gateway endpoint
- Amazon API Gateway forwards the request to a Lambda function
- AWS Lambda function behaves as a Kafka producer and pushes the message to a Kafka topic
- A Kafka “console consumer” on the bastion host then reads the message
The demo shows how to use Lambda Powertools for Java to streamline logging and tracing, and an IAM authenticator to simplify the cluster authentication process. The following sections take you through the steps to deploy, test, and observe the example application.
Prerequisites
The example has the following prerequisites:
- An AWS account. To sign up:
- Create an account. For instructions, see Sign Up For AWS.
- Create an AWS Identity and Access Management (IAM) user. For instructions, see Create IAM User.
- The following software installed on your development machine, or use an AWS Cloud9 environment, which comes with all requirements preinstalled:
- Java Development Kit 11 or higher (for example, Amazon Corretto 11, OpenJDK 11)
- Python version 3.7 or higher
- Apache Maven version 3.8.4 or higher
- Docker version 20.10.12 or higher
- Postman or similar tool to test your API
- Node.js 16.x or higher
- AWS CLI 2.4.27 or higher
- AWS CDK 2.28.1 or higher
- Session Manager CLI plugin
- Ensure that you have appropriate AWS credentials for interacting with resources in your AWS account
Example walkthrough
- Clone the project GitHub repository. Change directory to subfolder
serverless-kafka-iac:git clone https://github.com/aws-samples/serverless-kafka-producer cd serverless-kafka-iac - Configure environment variables:
export CDK_DEFAULT_ACCOUNT=$(aws sts get-caller-identity --query 'Account' --output text) export CDK_DEFAULT_REGION=$(aws configure get region) - Prepare the virtual Python environment:
python3 -m venv .venv source .venv/bin/activate pip3 install -r requirements.txt - Bootstrap your account for CDK usage:
cdk bootstrap aws://$CDK_DEFAULT_ACCOUNT/$CDK_DEFAULT_REGION - Run ‘cdk synth’ to build the code and test the requirements:
cdk synth - Run ‘cdk deploy’ to deploy the code to your AWS account:
cdk deploy --all
Testing the example
To test the example, log into the bastion host and start a consumer console to observe the messages being added to the topic. You generate messages for the Kafka topics by sending calls via API Gateway from your development machine or AWS Cloud9 environment.
- Use AWS System Manager to log into the bastion host. Use the
KafkaDemoBackendStack.bastionhostbastion Output-Parameterto connect or via the system manager console.aws ssm start-session --target <Bastion Host Instance Id> sudo su ec2-user cd /home/ec2-user/kafka_2.13-2.6.3/bin/ - Create a topic named messages on the MSK cluster:
./kafka-topics.sh --bootstrap-server $ZK --command-config client.properties --create --replication-factor 3 --partitions 3 --topic messages - Open a Kafka consumer console on the bastion host to observe incoming messages:
./kafka-console-consumer.sh --bootstrap-server $ZK --topic messages --consumer.config client.properties - Open another terminal on your development machine to create test requests using the “ServerlessKafkaProducerStack.kafkaproxyapiEndpoint” output parameter of the CDK stack. Append “/event” for the final URL. Use curl to send the API request:
curl -X POST -d "Hello World" <ServerlessKafkaProducerStack.messagesapiendpointEndpoint> - For load testing the application, it is important to calibrate the parameters. You can use a tool like Artillery to simulate workloads. You can find a sample artillery script in the
/load-testingfolder from step 1. - Observe the incoming request in the bastion host terminal.
All components in this example integrate with AWS X-Ray. With AWS X-Ray, you can trace the entire application, which is useful to identify bottlenecks when load testing. You can also trace method execution at the Java method level.
Lambda Powertools for java allows you to accelerate this process by adding the @Trace annotation to see traces on method level in X-Ray.
To trace a request end to end:
- Navigate to the CloudWatch console.
- Open the Service map.
- Select a component to investigate (for example, the Lambda function where you deployed the Kafka producer). Choose View traces.

- Select a single Lambda method invocation and investigate further at the Java method level.



Cleaning up
In the subdirectory “serverless-kafka-iac”, delete the test infrastructure:
cdk destroy –allImplementation of a Kafka producer in Lambda
Kafka natively supports Java. To stay open, cloud native, and without third-party dependencies, the producer is written in that language. Currently, the IAM authenticator is only available to Java. In this example, the Lambda handler receives a message from an Amazon API Gateway source and pushes this message to an MSK topic called “messages”.
Typically, Kafka producers are long-living and pushing a message to a Kafka topic is an asynchronous process. As Lambda is ephemeral, you must enforce a full flush of a submitted message until the Lambda function ends, by calling producer.flush().
@Override
@Tracing
@Logging(logEvent = true)
public APIGatewayProxyResponseEvent
handleRequest(APIGatewayProxyRequestEvent input, Context context) {
APIGatewayProxyResponseEvent response = createEmptyResponse();
try {
String message = getMessageBody(input);
KafkaProducer<String, String> producer = createProducer();
ProducerRecord<String, String> record = new ProducerRecord<String, String>(TOPIC_NAME, context.getAwsRequestId(), message);
Future<RecordMetadata> send = producer.send(record);
producer.flush();
RecordMetadata metadata = send.get();
log.info(String.format(“Send message was send to partition %s”, metadata.partition()));
log.info(String.format(“Message was send to partition %s”, metadata.partition()));
return response.withStatusCode(200).withBody(“Message successfully pushed to kafka”);
} catch (Exception e) {
log.error(e.getMessage(), e);
return response.withBody(e.getMessage()).withStatusCode(500);
}
}
@Tracing
private KafkaProducer<String, String> createProducer() {
if (producer == null) {
log.info(“Connecting to kafka cluster”);
producer = new KafkaProducer<String, String>(kafkaProducerProperties.getProducerProperties());
}
return producer;
}
Connect to Amazon MSK using IAM Auth
This example uses IAM authentication to connect to the respective Kafka cluster. See the documentation here, which shows how to configure the producer for connectivity.
Since you configure the cluster via IAM, grant “Connect” and “WriteData” permissions to the producer, so that it can push messages to Kafka.
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Effect”: “Allow”,
“Action”: [
“kafka-cluster:Connect”
],
“Resource”: “arn:aws:kafka:region:account-id:cluster/cluster-name/cluster-uuid “
}
]
}
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Effect”: “Allow”,
“Action”: [
“kafka-cluster:Connect”,
“kafka-cluster: DescribeTopic”,
],
“Resource”: “arn:aws:kafka:region:account-id:topic/cluster-name/cluster-uuid/topic-name“
}
]
}
This shows the Kafka excerpt of the IAM policy, which must be applied to the Kafka producer.
When using IAM authentication, be aware of the current limits of IAM Kafka authentication, which affect the number of concurrent connections and IAM requests for a producer. Read https://docs.thinkwithwp.com/msk/latest/developerguide/limits.html and follow the recommendation for authentication backoff in the producer client:
Map<String, String> configuration = Map.of(
“key.serializer”, “org.apache.kafka.common.serialization.StringSerializer”,
“value.serializer”, “org.apache.kafka.common.serialization.StringSerializer”,
“bootstrap.servers”, getBootstrapServer(),
“security.protocol”, “SASL_SSL”,
“sasl.mechanism”, “AWS_MSK_IAM”,
“sasl.jaas.config”, “software.amazon.msk.auth.iam.IAMLoginModule required;”,
“sasl.client.callback.handler.class”, “software.amazon.msk.auth.iam.IAMClientCallbackHandler”,
“connections.max.idle.ms”, “60”,
“reconnect.backoff.ms”, “1000”
);
Elaboration on implementation
Each Kafka broker node can handle a maximum of 20 IAM authentication requests per second. The demo setup has three brokers, which result in 60 requests per second. Therefore, the broker setup limits the number of concurrent Lambda functions to 60.
To reduce IAM authentication requests from the Kafka producer, place it outside of the handler. For frequent calls, there is a chance that Lambda reuses the previously created class instance and only re-executes the handler.
For bursting workloads with a high number of concurrent API Gateway requests, this can lead to dropped messages. While for some workloads, this might be tolerable, for others this might not be the case.
In these cases, you can extend the architecture with a buffering technology like Amazon SQS or Amazon Kinesis Data Streams between API Gateway and Lambda.
To reduce latency, you can reduce cold start times for Java by changing the tiered compilation level to “1” as described in this blog post. Provisioned Concurrency ensures that polling Lambda functions are ready before requests arrive.
Conclusion
In this post, you learn how to create a serverless integration Lambda function between API Gateway and Apache Managed Streaming for Apache Kafka (MSK). We show how to deploy such an integration with the CDK.
The general pattern is suitable for many use cases that need an integration between API Gateway and Apache Kafka. It may have cost benefits over containerized implementations in use cases with sparse, low-volume input streams, and unpredictable or spiky workloads.
For more serverless learning resources, visit Serverless Land. To learn more, read the guide: Using Lambda to process Apache Kafka streams.